はじめに
Databricksビジネス推進室の井能です。現在サンフランシスコで現地参加しているDatabricksの年次カンファレンス『Data+AI Summit 2025』にて、フルマネージドのPostgresデータベースをホストする機能である『Lakebase』が発表されました。

2025年3月にはサーバレスPostgresを提供する『Neon』をDatabricksが買収したことでも話題になりましたが、LakebaseはNeonが持つテクノロジーがベースとなっており、データベースのBranchingなど開発者の体験(DevEx)を向上する特色を多数引き継いでいます。
本記事では、Lakebaseの概要を紹介するとともに、既にPublic Previewが開始している一部機能のハンズオンを通じて使用感をお伝えしたいと思います。
概要
コンセプト
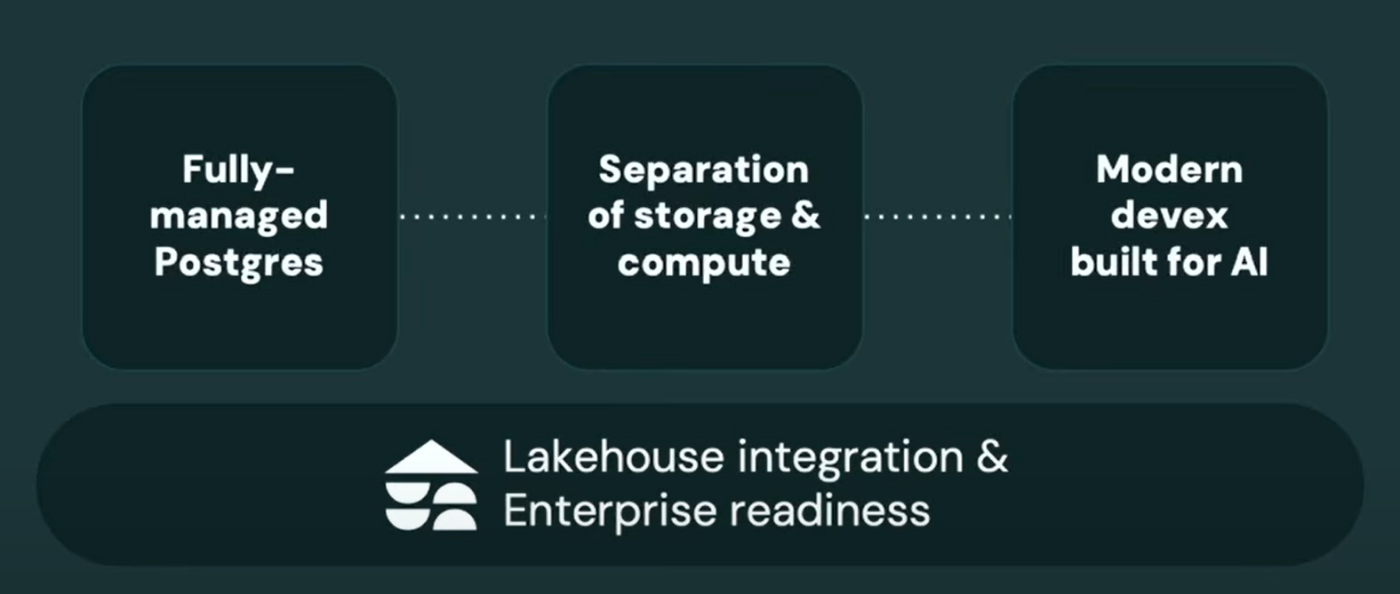
Lakebaseは以下コンセプトのもとに構成されています。
Data + AI Summit Keynote Day 1
1. Fully-managed Postgres
LakebaseはフルマネージドのPostgresデータベースです。
Databricksはこれまでも、Apache SparkやDelta Lake、MLflowなどOSS開発の主導・貢献と、OSSをプラットフォームに組み込むことによる製品のアップデートを両輪で実施する方針で成長を続けてきました。

Data + AI Summit Keynote Day 1
今回OLTPデータベースを実現するにあたってもOSSをベースとする方針は違わず、その中でOLTPデータベースエンジンの中でも人気があり、コミュニティが活発で、レイテンシやクエリ性能などの性能も高く、PostGISやpgvectorなどの拡張やドライバ、クライアントツールなどのエコシステムが豊富であることから、Postgresをベースにしています。
今後OSSのPostgresで新機能が登場すれば、それはLakebaseにおいても基本的には利用できるようになるため、ユーザーとしても独自のエンジンをベースにする場合と比較して世間のトレンドから取り残される可能性を限りなく小さくできる恩恵があります。
2. Separation of storage & compute
ストレージとコンピュートは分離されており、ストレージはオブジェクトストレージを活用したデータレイク、コンピュートはサーバレスコンピュートが利用され、それぞれ独立してスケーリングが可能です。これによって、ユーザーは必要十分なリソースを利用し、性能とコスト最適化の両立を実現することが可能です。

Data + AI Summit Keynote Day 1
コンピュートはサーバレスコンピュートが稼働します。必要に応じて瞬時に起動、負荷に応じて自動的にスケールアップ/ダウンを実施します。利用がないタイミングでは0までスケールダウンされることに加え、プロビジョニングの一時停止/再開も可能です。コンピュートは利用中のみ課金が発生するため、コスト最適化をしながらの運用が可能になります。
ストレージは、Databricks社が管理するクラウドサービスのアカウントに作られるデータレイクがベースとなります。そこに、中間層のストレージ(ソフトステートとして機能するライトスルーキャッシュ)を被せることで、OLTPワークロードが必要とする10ミリ秒レベルの低レイテンシーと10kQPS超えの高い同時実行性QPS(Queries Per Second)をサポートしています。
3. Modern DevEx built for AI
Neonのテクノロジーをベースとした開発体験の向上をもたらします。
代表的な機能は、スキーマとデータを含むデータベース全体のインスタントブランチングとフォークが可能になり、さながらコードをGitで管理するようにデータベースを管理することが可能になります。
この機能によって、テスト用にブランチを隔離して大元のテーブルに影響を与えないように試験をすることが可能になる、過去の任意の地点からブランチを作成してデータのリカバリや履歴の分析に利用可能になるなどの恩恵があります。イメージとしては、Delta Lakeにおけるタイムトラベル機能に相当する機能になるでしょうか。
2025年6月のPublicPreview開始時点では利用できるDevEx関連機能は最低限となっており、今後随時追加予定とのことです。
4. Lakehouse Integration & Enterprise readiness
LakehouseやUnity Catalogなど他機能との連携機能も充実しているため、シームレスに連携しながら活用することが可能になります。そのため、従来から実施しているユースケースのうち、OLTPデータベースに適した取り組みだけLakebaseを活用するよう置き換えても、多くの場合はこれまでと同じような使用感で業務を推進することが可能です。
Lakehouseとのフルマネージドでのデータ同期
- Lakehouse ⇔ Postgres 間での双方向同期
- 複数テーブルを含む同期パイプラインを定義可能
- Snapshot/Triggered/Continuousの3つの同期方式に対応
| 方式 | 概要 |
|---|---|
| Snapshot | ソーステーブルの全レコードを同期 |
| Triggered | 最後に同期したポイントからのすべての増分変更を同期 |
| Continues | 初回実行からChangeDataFeedを追跡して同期 |
AIユースケースとの連携
- 高速な特徴量検索とリアルタイム推論向けのOnline Feature Storeとしての利用
- オフライン学習データはLakehouseに保存可能
Unity Catalogとの統合
- Postgresテーブルをデータカタログに登録可能
- Unity Catalogによるガバナンス管理
- Lakehouse Federationにも対応
クエリエディター & スキーマブラウザー
- Postgres用のネイティブクエリエディター
- Postgresスキーマをブラウズ可能
非機能関連の特色
本機能は本番アプリケーションなどでの利用を想定された機能であるため、セキュリティや可用性などの要件が合致するかは非常に重要です。マルチAZフェイルオーバーやリカバリ、スケーリング、アクセス制御機能など、基本的にはエンタープライズでも利用可能な設計となっていますが、企業の細かな要件との整合性は個別に確認ください。
可用性
- マルチAZでのフェイルオーバー
- リード専用セカンダリDB
- 最大35日間のポイント・イン・タイム・リカバリ
※SLAは各Databricksサービスの内容を確認
性能拡張性
- 自動スケーリング(Auto scaling)
運用・保守性
- 内部モニタリング機能搭載
- Databricks Appsリソース管理
- Terraformや課金タグ(Billing Tags)による運用支援
セキュリティ
- DatabricksユーザーによるOAuth
- PrivateLink/IPアクセス制御
- ストレージ暗号化
- TLSによる通信暗号化
ユーザビリティ
- インスタントプロビジョニング
- フルブランチ機能
- Neonベースの開発体験
課金体系
コンピュート、ストレージともにDatabricks社が管理する領域で立ち上がるため、それぞれ利用に際して従量課金で請求が発生します。
また、LakebaseとDelta Lakeのテーブル同期にはサーバレスDelta Live Tableが利用されるため
、同期設定を実施している場合は請求が発生します。更新頻度が高いほど請求は高くなることが想定されます。DLTのパイプラインの実行頻度は、必要な同期頻度に応じて方式の設計をすることがコスト最適化の観点で好ましいです。

Lakebase: Fully Managed Postgres for the Lakehouse (アーカイブ公開次第追記予定)
ユースケース
一般的なOLTPと同様に、リアルタイムのトランザクション処理や直近のトランザクションデータを活用したレポート・アクションに活用することがメインになります。大規模なデータ分析や長期的なデータを活用した集計・統計はDelta Lakeのテーブルを利用したほうが性能が出るケースが多いと思われるため、すべてをLakebaseにするのではなく、適切な使い分けを検討することが重要です。
Lakebaseに適したユースケースの例を以下に示します。
アプリケーションのバックエンドデータベース
- 注文処理
- インタラクティブなワークフローの承認
- エージェント用の状態管理
レイクハウス上のデータ/特徴量のオンラインサービング
- パーソナライズドレコメンデーション
- 顧客セグメンテーション
ハンズオン
データベースインスタンスの作成
こちらの手順に従いLakebaseのテーブルを作成します。
Postgresデータベースの作成画面です。こちらではインスタンス名、サイズ、データの過去断面の保持期間、可用性に関する設定などを実施します。

インスタンスの作成は手元では5分ほどかかりました。完了すると、作成したインスタンスに対してクエリを実行できるようになるため、「New Query」ボタンからSQLエディタに移動します。

SQLエディタではクエリの実行や、サイドパネルにおいてカタログやスキーマの一覧も参照することが可能です。ただし、リソースにPostgresインスタンスを指定している場合、サイドパネルのカタログに表示されるのはPostgresのテーブルのみです。

Catalog Explorerの画面から参照した場合も、この時点ではUnity Catalog上でPostgresのリソースは確認できるようにはなっていませんでした。

というのも、Postgresのリソースは明示的にUnity Catalogに登録する操作が必要となるようなので、そちらの手順を実施します。
Unity Catalogへのカタログ作成
こちらの手順に従いUnity CatalogへPostgresのデータベースを登録します。
まずはPostgresデータベースインスタンスの詳細画面の「Catalogs」タブから、データベースを指定してUnity Catalogに登録します。ここでPostgresデータベースを新規作成&登録をすることもできるようですが、今回はデフォルトのデータベース「databricks_postgres」を指定します。余談ですが、「Postgres」データベースは指定できませんでした。


こちらの手順が完了すると、Catalog Explorerからも該当のリソースを確認することができるようになります。


このとき、Postgresへのコネクションも自動で作成されており、Unity Catalogの挙動としては外部データベースの接続情報を利用して外部テーブルとして登録するような動きになっているようです。

次に、Delta Lakeのテーブル/ビューをPostgres上に同期してみたいと思います。
同期テーブルの作成
こちらの手順に従い同期テーブルを作成します。

今回のケースではDatabricks公式のサンプルデータセットを利用したため、Delta Sharingで参照しているテーブルを共有していますが、その場合は同期方式はSnapshot一択になるようです。

同期テーブルの定義が完了すると、ほとんど時間をおかずPostgres上にテーブルが作成されていました。
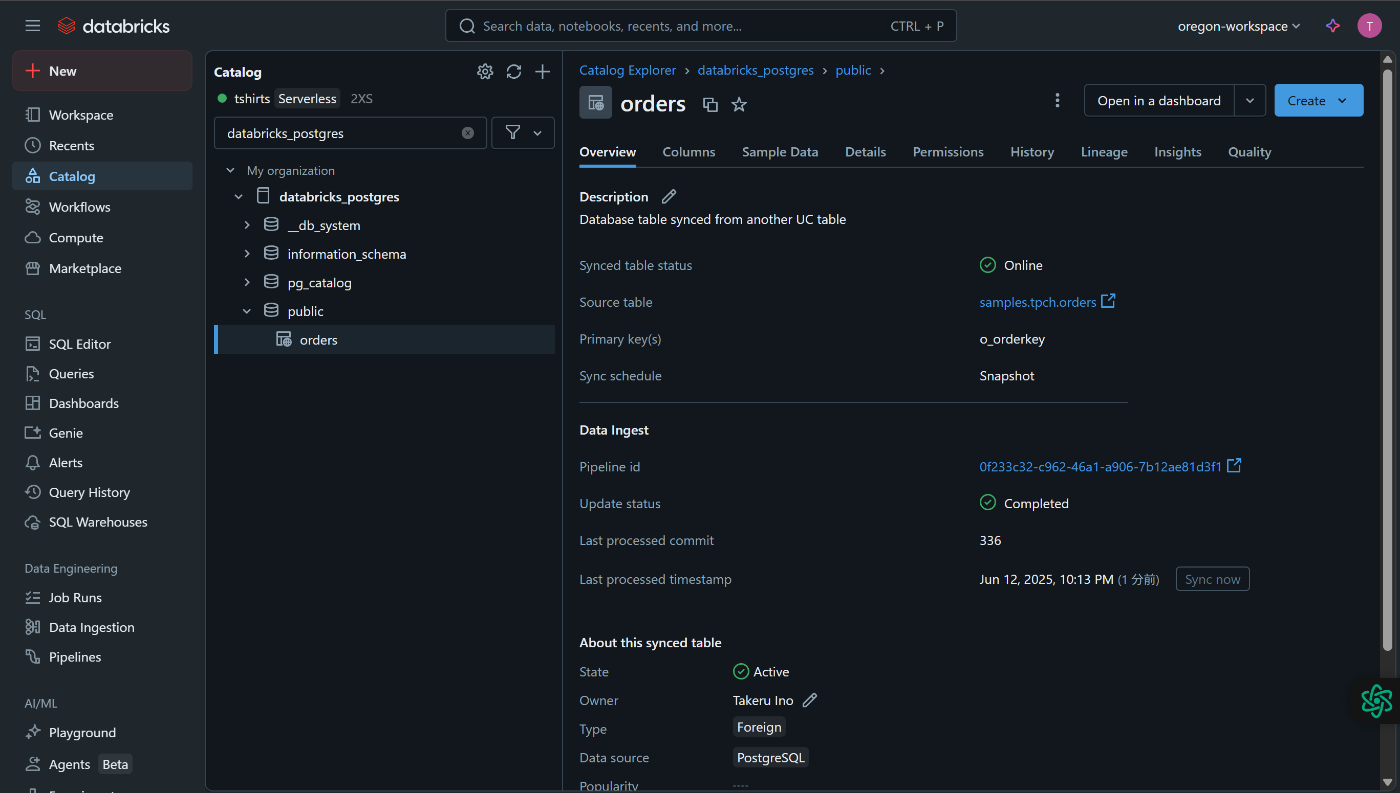
同期に使用されるDelta Live Tableのパイプラインも自動で作成されています。

同期テーブルへのクエリの実行も確認できました。同期テーブルも作成はほとんど手間なく実施可能なようです。

別インスタンスからのクエリ実行
Lakebaseはコンピュートとストレージが分離しているため、新規インスタンスを作成する際に親インスタンスを指定することで、親インスタンスで定義したデータベースも参照することができます。


まとめ
本記事では、Databricksから新しくリリースされたLakebaseの概要説明とハンズオンを実施しました。
これまではトランザクション処理をDatabricksで効率的に実施するためには、外部のOLTPデータベースに接続しなければ実現できなかったところがDatabricks内で完結できるようになる、そしてOLAPとの連携も非常に簡単に設定できるため同じデータでもユースケースに合わせてOLAP/OLTPを切り替えて利用できるようになるなど、より効果的なデータ・AI活用につなげることができるアップデートだと感じています。ぜひLakebaseを活用してみてください!
仲間募集
NTTデータ ソリューション事業本部 では、以下の職種を募集しています。
Databricks、生成AIを活用したデータ基盤構築/活用支援(Databricks Championとの協働)
Snowflake、生成AIを活用したデータ基盤構築/活用支援(Snowflake Data Superheroesとの協働)
プロジェクトマネージャー(データ分析プラットフォームソリューションの企画~開発~導入/生成AI活用)
クラウドを活用したデータ分析プラットフォームの開発(ITアーキテクト/PM/クラウドエンジニア)
ソリューション紹介
Trusted Data Foundationについて
~データ資産を分析活用するための環境をオールインワンで提供するソリューション~
最新のクラウド技術を採用して弊社が独自に設計したリファレンスアーキテクチャ(Datalake+DWH+AI/BI)を顧客要件に合わせてカスタマイズして提供します。
可視化、機械学習、DeepLearningなどデータ資産を分析活用するための環境がオールインワンで用意されており、これまでとは別次元の量と質のデータを用いてアジリティ高くDX推進を実現できます。
NTTデータとDatabricksについて
NTTデータは、お客様企業のデジタル変革・DXの成功に向けて、「databricks」のソリューションの提供に加え、情報活用戦略の立案から、AI技術の活用も含めたアナリティクス、分析基盤構築・運用、分析業務のアウトソースまで、ワンストップの支援を提供いたします。
NTTデータとSnowflakeについて
NTTデータとSnowflakeについて
NTTデータでは、Snowflake Inc.とソリューションパートナー契約を締結し、クラウド・データプラットフォーム「Snowflake」の導入・構築、および活用支援を開始しています。
NTTデータではこれまでも、独自ノウハウに基づき、ビッグデータ・AIなど領域に係る市場競争力のあるさまざまなソリューションパートナーとともにエコシステムを形成し、お客さまのビジネス変革を導いてきました。
Snowflakeは、これら先端テクノロジーとのエコシステムの形成に強みがあり、NTTデータはこれらを組み合わせることでお客さまに最適なインテグレーションをご提供いたします。
NTTデータとInformaticaについて
NTTデータとInformaticaについて
データ連携や処理方式を専門領域として10年以上取り組んできたプロ集団であるNTTデータは、データマネジメント領域でグローバルでの高い評価を得ているInformatica社とパートナーシップを結び、サービス強化を推進しています。

NTT DATA公式アカウントです。 技術を愛するNTT DATAの技術者が、気軽に楽しく発信していきます。 当社のサービスなどについてのお問い合わせは、 お問い合わせフォーム nttdata.com/jp/ja/contact-us/ へお願いします。