ECS on GPUでJupyter環境を構築したらSageMakerの方が楽だった話
ECSで先に構築したのですが、同じことをSageMakerで実現したら一瞬だったので記事にして供養します 🙏
これは何?
- Google Colab上でLLMのFine-tuningを実行するときに、VRAMが足りなくなることが頻発したので、自前インスタンスでJupyterを立てたい人の記事
- 普段ECS立てる時はFargate一択なのですが、GPUが必要なのでEC2で構築
- インフラは基本Terraformで構築しており、モジュール利用は最小限にして個別でresourceを定義
tl;dr
- 起動タイプをFargateからEC2にしただけでハマりどころが頻発しました
- 直面したトラブルシュートをまとめてあります
- 自前のJupyter環境が欲しい時はSageMakerを使おう(真顔)
Jupyter実行までの流れ
- Dockerfileを作成
- Terraformでリソースを作成
- ECSタスクを実行
Dockerfileを作成
JupyterLabだけ起動したかったので、パッケージマネージャなどは使わずシンプルにpipを使ってインストールしています。
ログインするときのNotebookApp.tokenはよしなに変更してください。
# `python-base` sets up all our shared environment variables
FROM python:3.11-slim-buster AS python-base
ENV \
# python
PYTHONUNBUFFERED=1 \
# prevents python creating .pyc files
PYTHONDONTWRITEBYTECODE=1 \
\
# pip
PIP_NO_CACHE_DIR=off \
PIP_DISABLE_PIP_VERSION_CHECK=on \
PIP_DEFAULT_TIMEOUT=100 \
\
# paths
# this is where our requirements + virtual environment will live
PYSETUP_PATH="/opt/pysetup" \
VENV_PATH="/opt/pysetup/.venv"
# `builder-base` stage is used to build deps + create our virtual environment
FROM python-base AS builder-base
RUN apt-get update \
&& apt-get install --no-install-recommends -y \
# deps for building python deps
build-essential
WORKDIR /app
# install runtime deps
RUN pip install -U \
pip \
jupyterlab
EXPOSE 8888
CMD ["python3", "-m", "jupyter", "lab", "--allow-root", "--ip=0.0.0.0", "--port=8888", "--no-browser", "--NotebookApp.token='xxx'"]
Terraformでリソースを作成
AWSのインフラ構成は以下の通りです。
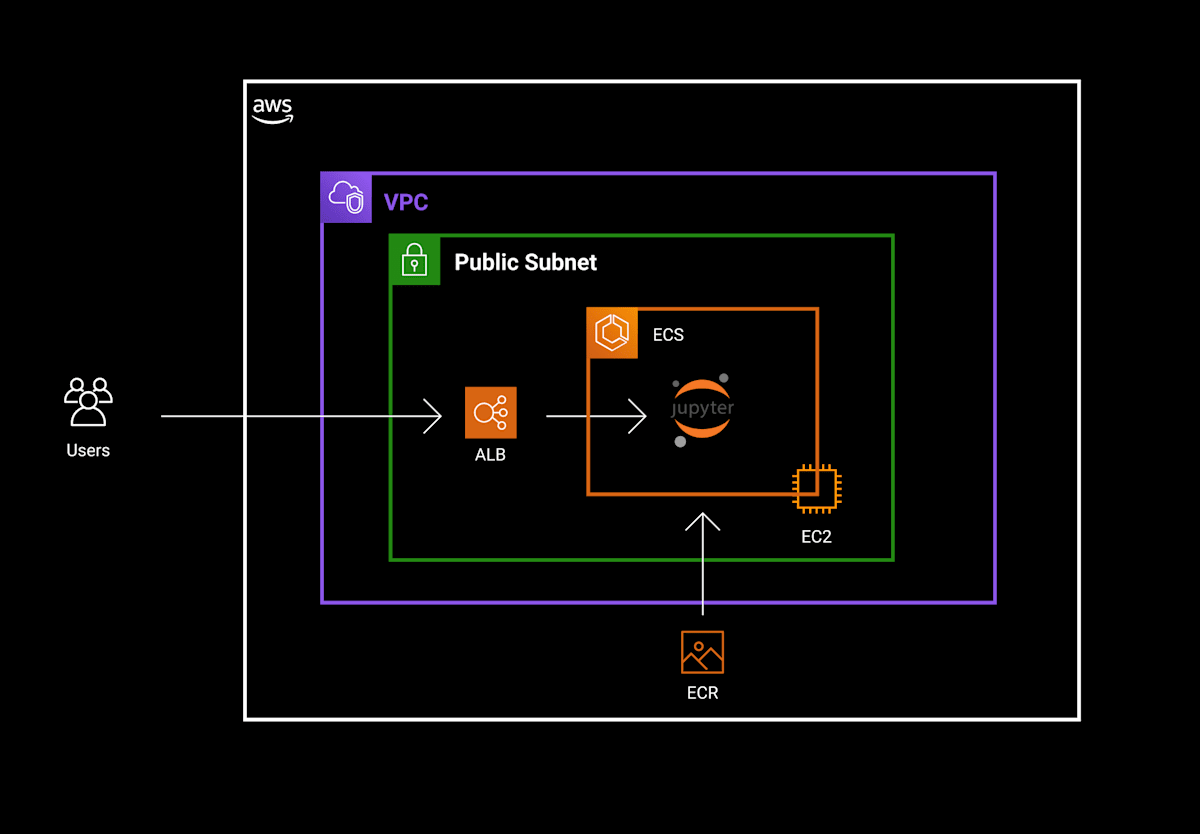
それぞれのリソースについて、Terraformファイルとハマりどころを記載していきます。デプロイするために必要な周辺リソースはトグル内に入れておきました。
EC2
起動するインスタンスとセキュリティグループを定義しています。インスタンスタイプは自身で必要なスペックを調べて選択してください。
resource "aws_instance" "jupyter" {
ami = "ami-0127e15943c157142"
associate_public_ip_address = true
instance_type = "g3s.xlarge"
vpc_security_group_ids = [aws_security_group.jupyter_ec2.id]
subnet_id = module.vpc.public_subnets[1]
key_name = data.aws_key_pair.jupyter_ec2.key_name
iam_instance_profile = "jupyter-ec2-profile"
ebs_block_device {
device_name = "/dev/xvda"
volume_size = 200
}
user_data = <<-EOF
#!/bin/bash
sudo mkdir -p /etc/ecs/
sudo touch /etc/ecs/ecs.config
echo ECS_ENABLE_GPU_SUPPORT=true | sudo tee -a /etc/ecs/ecs.config
echo ECS_CLUSTER=${aws_ecs_cluster.jupyter.name} | sudo tee -a /etc/ecs/ecs.config
sudo amazon-linux-extras disable docker
sudo amazon-linux-extras install -y ecs; sudo systemctl enable --now --no-block ecs
# Run ECS container agent
sudo systemctl start --no-block ecs
EOF
}
resource "aws_security_group" "jupyter_ec2" {
name = "jupyter-ec2-sg"
description = "Allow https inbound traffic."
vpc_id = module.vpc.vpc_id
ingress {
description = "Allow ingress traffic from ALB on HTTP on ephemeral ports"
from_port = 1024
to_port = 65535
protocol = "tcp"
security_groups = [aws_security_group.jupyter_alb.id]
}
ingress {
description = "Allow ingress traffic from ALB on HTTP"
from_port = 80
to_port = 80
protocol = "tcp"
security_groups = [aws_security_group.jupyter_alb.id]
}
egress {
from_port = 0
to_port = 0
protocol = "all"
cidr_blocks = ["0.0.0.0/0"]
ipv6_cidr_blocks = ["::/0"]
}
}
EC2関連のリソース(IAM、キーペアなど)
resource "aws_iam_instance_profile" "jupyter" {
name = "jupyter-ec2-profile"
role = aws_iam_role.jupyter_ec2.name
}
resource "aws_iam_role_policy_attachment" "jupyter_ec2" {
for_each = toset([
"arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy",
"arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly",
"arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role"
])
role = aws_iam_role.jupyter_ec2.name
policy_arn = each.value
}
resource "aws_iam_role" "jupyter_ec2" {
name = "jupyter-ecs-ec2"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "ec2.amazonaws.com"
}
}
]
})
}
data "aws_key_pair" "jupyter_ec2" {
key_name = "jupyter-ec2"
}
AMI選定
GPUマシンで動作させたいのでCUDA 11.5が載っているAMIを選択しました。フレームワークはPyTorchがインストールされています。 上記ページには直接AMI-IDが記載されていないので、AWS CLIから取得します。
aws ec2 describe-images --region us-east-1 --owners amazon --filters 'Name=name,Values=Deep Learning AMI GPU CUDA 11.5.? (Amazon Linux 2) ????????' 'Name=state,Values=available' --query 'reverse(sort_by(Images, &CreationDate))[:1].ImageId' --output text
AMIによってサポートされているインスタンスタイプが異なるので、選定したAMIのページを確認してください。
ECS用の設定ファイルを配置 + ECSコンテナエージェントのインストール
ECSタスクが実行されるEC2インスタンスは自動でアタッチされるのではなく、設定ファイルをEC2インスタンスに配置した上でECSコンテナエージェントを起動する必要があります。
(ECSコンテナエージェントがプリインストールされたAMIもあるのですが、今回は無かったのでは自前でインストールしています)
EC2の起動時に実行されるユーザーデータにスクリプトを渡して実現しています。
sudo mkdir -p /etc/ecs/
sudo touch /etc/ecs/ecs.config
# GPUを利用するための設定
echo ECS_ENABLE_GPU_SUPPORT=true | sudo tee -a /etc/ecs/ecs.config
# ECSクラスター名を指定
echo ECS_CLUSTER=${aws_ecs_cluster.jupyter.name} | sudo tee -a /etc/ecs/ecs.config
sudo amazon-linux-extras disable docker
sudo amazon-linux-extras install -y ecs; sudo systemctl enable --now --no-block ecs
# Run ECS container agent
sudo systemctl start --no-block ecs
vCPU上限解放リクエスト
vCPUの大きなインスタンスを作成しようとすると以下のような警告が出ました。
You have requested more vCPU capacity than your current vCPU limit of 64
allows for the instance bucket that the specified instance type belongs to.
Please visit http://aws.amazon.com/contact-us/ec2-request to request an
adjustment to this limit.
起動できるインスタンスにはデフォルトでvCPUの上限(私の場合は64)が設定されているようなので、警告内のリンクを通してリクエストを出して上限値を引き上げてもらいました。
リクエストから1時間弱で反映されたと思います。
エフェメラルポートからのingressをALBに許可
エフェメラルポートは、特定の用途やプロトコルによって使用されることが想定されていないポート番号です。
EC2で起動する場合は、タスク定義のcontainerPortを指定する時にhostPortを省略(または0に設定)できます。このときEC2インスタンス内のポートが動的に割り当てられるので、ある程度広めのIPレンジに対してALBからのアクセスを許可するセキュリティグループを作成しておきます。
ingress {
description = "Allow ingress traffic from ALB on HTTP on ephemeral ports"
from_port = 1024
to_port = 65535
protocol = "tcp"
security_groups = [aws_security_group.jupyter_alb.id]
}
ここを忘れるとECSクラスターがインスタンスを認識してくれないので注意してください。
インターネットにアクセスできる場所に置く
EC2は外向きにインターネットアクセスできる場所に配置しないと、ECSクラスターがインスタンスを認識してくれませんでした。
上記ではパブリックサブネットに配置することで対応していますが、プライベートサブネットに置いてNATゲートウェイを経由することでも対応できます。
パブリックサブネット内にあるのでセキュリティグループの設定は注意する必要があります。上記では念のためSSHアクセス用のポートも閉じています。
ECS
Jupyterの常駐タスクを1つだけ起動するだけなので、AutoScalingは使わずシンプルにクラスター・サービス・タスク定義を作成します。
resource "aws_ecs_cluster" "jupyter" {
name = "jupyter-cluster"
}
resource "aws_ecs_service" "jupyter" {
name = "jupyter-service"
cluster = aws_ecs_cluster.jupyter.id
launch_type = "EC2"
task_definition = aws_ecs_task_definition.jupyter.arn
load_balancer {
target_group_arn = aws_lb_target_group.jupyter.arn
container_name = "jupyter-container"
container_port = "8888"
}
lifecycle {
ignore_changes = [task_definition]
}
depends_on = [aws_lb_listener.http]
}
resource "aws_ecs_task_definition" "jupyter" {
family = "jupyter"
requires_compatibilities = ["EC2"]
network_mode = "bridge"
execution_role_arn = aws_iam_role.jupyter_ecs_task.arn
container_definitions = jsonencode([
{
name = "jupyter-container"
image = aws_ecr_repository.jupyter.repository_url
essential = true
cpu = 4
memory = 30000
portMappings = [
{
containerPort = 8888
hostPort = 8888
protocol = "tcp"
}
]
logConfiguration = {
logDriver = "awslogs"
options = {
awslogs-region = var.region
awslogs-group = aws_cloudwatch_log_group.ecs_task_log.name
awslogs-stream-prefix = "jupyter"
}
}
resourceRequirements = [
{
type = "GPU",
value = "1"
}
]
}
])
}
ECS関連のリソース(ECR、CloudWatchなど)
resource "aws_ecr_repository" "jupyter" {
name = "jupyter"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
}
resource "aws_cloudwatch_log_group" "ecs_task_log" {
name = "/aws/ecs-task/jupyter"
retention_in_days = 14
}
コンテナから利用できるGPU数の指定
タスク定義の中で、コンテナが利用するGPUの数を指定します。
もちろんCUDAは指定した数までしかGPUを認識しないので、GPUマシマシなインスタンスタイプに変更した場合は忘れずに更新してください。(cpuやmemoryも同様ですね)
resourceRequirements = [
{
type = "GPU",
value = "8"
}
]
その他のリソース
記事の主旨とは関係ないですが、上記で定義したリソースを作成する時には必要になるリソースをまとめて記載しました。
その他のリソース(VPC、ALBなど)
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = "vpc"
cidr = "10.0.0.0/16"
azs = ["${var.region}a", "${var.region}c", "${var.region}d"]
public_subnets = ["10.0.0.0/20", "10.0.16.0/20", "10.0.32.0/20"]
private_subnets = ["10.0.48.0/20", "10.0.64.0/20", "10.0.80.0/20"]
}
resource "aws_lb" "jupyter" {
name = "jupyter"
internal = false
load_balancer_type = "application"
security_groups = [aws_security_group.jupyter_alb.id]
subnets = module.vpc.public_subnets
}
resource "aws_lb_target_group" "jupyter" {
name = "jupyter"
vpc_id = module.vpc.vpc_id
port = 80
protocol = "HTTP"
health_check {
healthy_threshold = 3
interval = 30
matcher = "200"
port = "traffic-port"
path = "/api"
protocol = "HTTP"
timeout = 6
unhealthy_threshold = 3
}
depends_on = [aws_lb.jupyter]
}
resource "aws_lb_listener" "http" {
load_balancer_arn = aws_lb.jupyter.arn
port = 80
protocol = "HTTP"
default_action {
type = "forward"
target_group_arn = aws_lb_target_group.jupyter.arn
}
}
ECSタスクを実行
この辺りの手順はマニュアルですが、複数回実行することは無いので許容してます。
最初に定義したDockerfileをビルドして、上記で作成したECRにpushします。AWSコンソールからECRリポジトリを開くと右上に「プッシュコマンドを表示」ボタンがあるので、記載された手順に沿って操作すれば問題ないです。
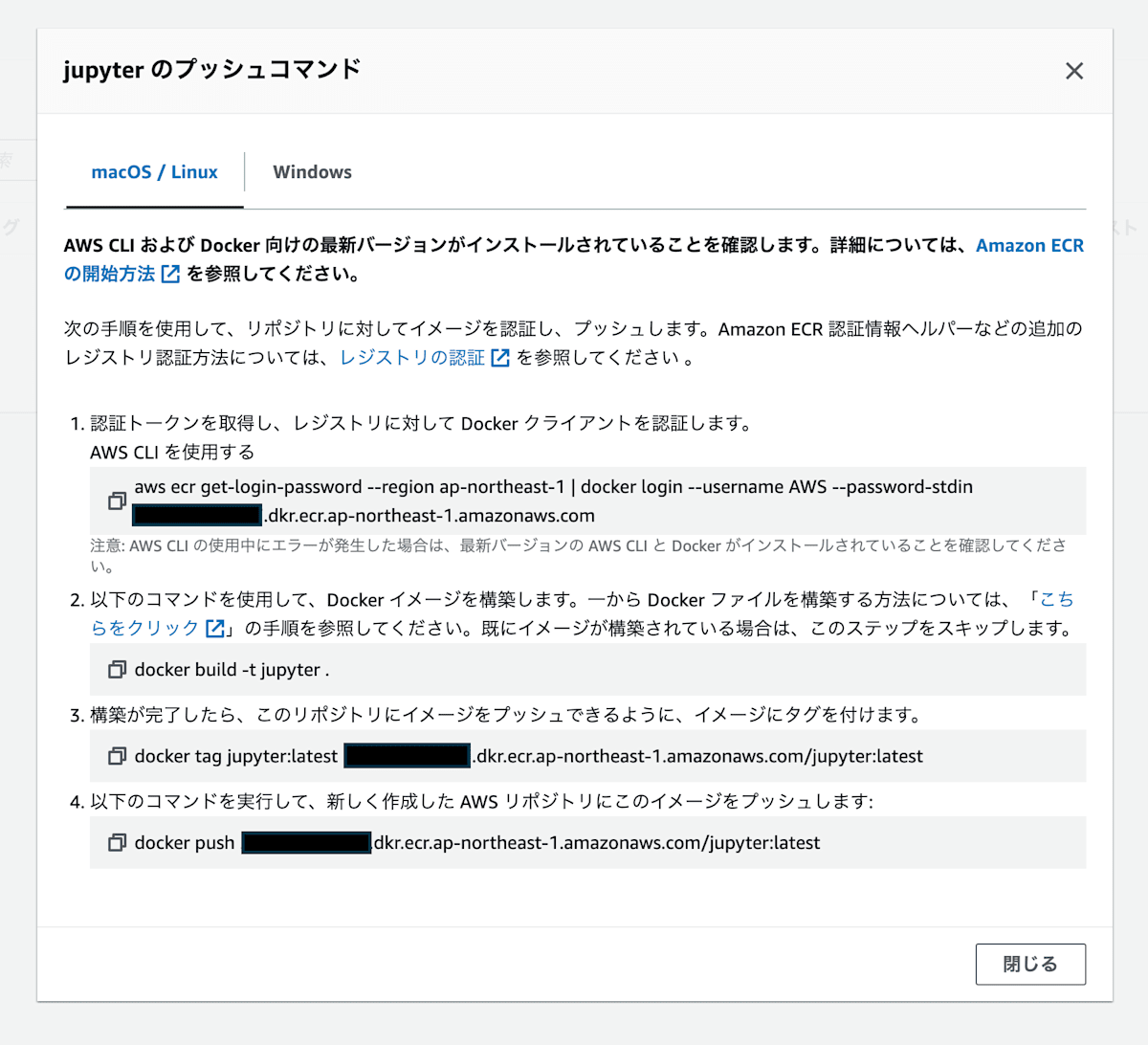
ECRにDockerイメージをプッシュ
ECSクラスターのコンソールからタスクを実行します。起動タイプに「EC2」を選択して、先ほど作成したタスク定義を指定してあげればOKです。
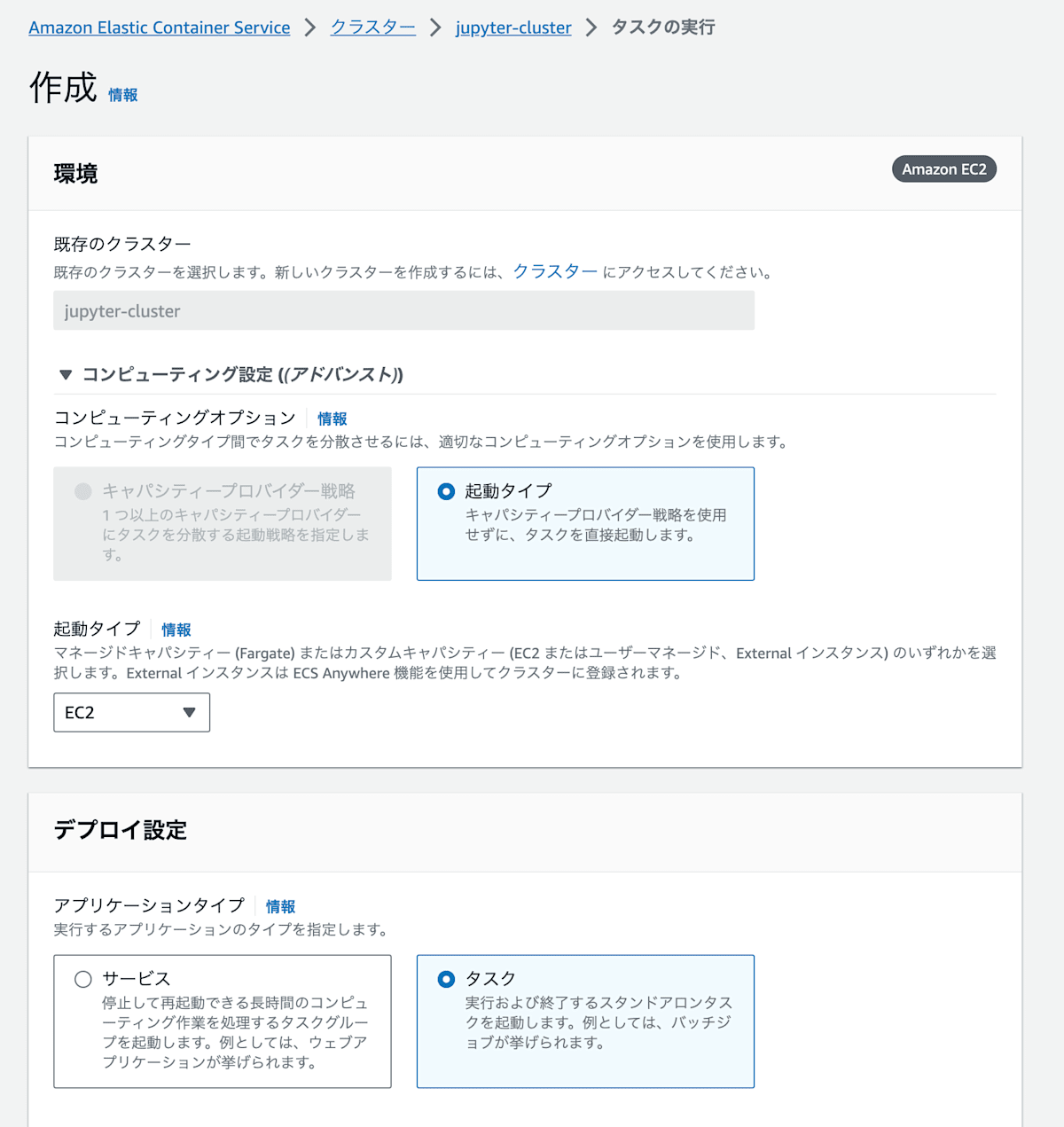
ECSタスクの実行
最後に、EC2のターゲットグループにインスタンスを登録します。ここで指定するポートは、タスク定義のhostPortと同じにしてください。
もしhostPortに0を指定した場合は動的にポートが割り当てられているので、EC2インスタンスにsshで入りdocker psで確認できます。
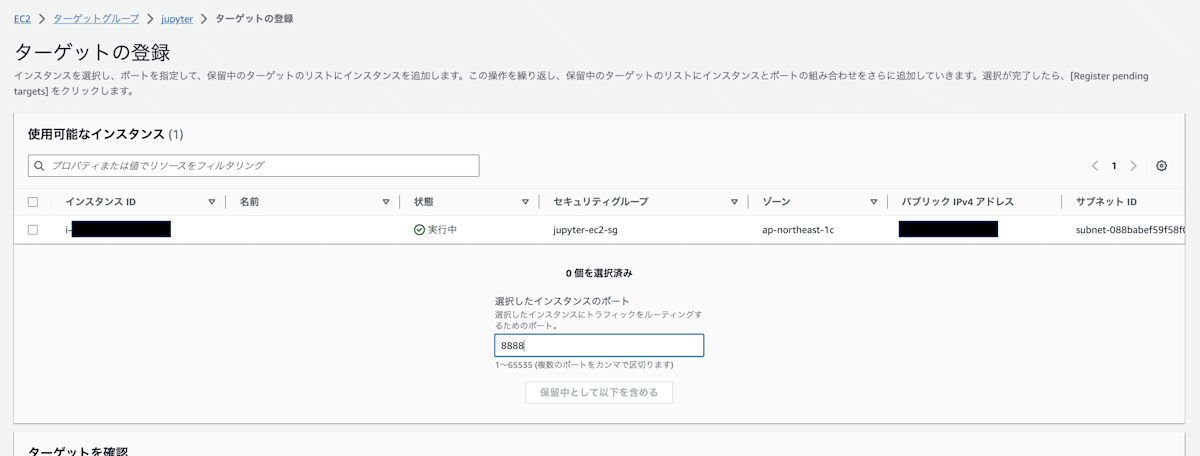
ターゲットグループにインスタンスを登録
以上でECSタスクが起動したので、ALBのDNS名にアクセスすればJupyterLabが起動しているはずです。
Jupyter起動!
まとめ
初めてEC2起動タイプでECSを立ち上げてみました。構築する中で相当な数のエラーに遭遇したのですが、断片的に散らばっているトラブルシュートを1記事にまとめられたかなと思います。私はこんなエラーがあったよ、という方はぜひ教えていただければと思います。
LLMが注目される昨今で、Fine-tuningや既存モデルを実行する機会は増えるかと思います。最初の選択肢としてColabは最適なのですが、モデルサイズが大きくなりGPUリソースが不足すると自身のクラウド環境で実行する必要があるかもしれません。
Jupyterのプロセスを常駐させたいだけであればSageMakerがおすすめなのですが、短時間のタスクをGPU環境で実行したい方がいれば本記事が一助になれば幸いです。私はSageMakerで十分でした(泣)
それではまたお会いしましょう!
Discussion