Javaの強みを徹底解説③:ガベージコレクション
こんにちは NSS の江口と申します。前回の記事(JITコンパイラ)に引き続きJavaの話となります。
今回は ガベージコレクション について話していこうと思います。前回と同様に今回記載している内容はJava21に準拠しています。
ガベージコレクションとは

Heap領域内に確保されたメモリを自動的に解放する仕組みです。誰からも参照されなくなったメモリを対象にします。
現在の多くのプログラミング言語では当たり前にサポートされていることが多いです。(贅沢ですね。)
ガベージコレクションの種類
では具体的にどうやってメモリを片付けるのかという話ですが、これという一つに決まっているわけではなく、Javaの歴史の中でいくつかの種類が生まれました。
-
シリアル・コレクタ
- 単一のスレッドにより、ガベージコレクションを実行する
- GCが発生しない限りは最も高速に動作(そんなことはあり得ないが)
- いわゆる Stop The World が最も発生する
-
パラレル・コレクタ
- 複数のスレッドにより、GCを実行し、停止時間を縮める
-
CMS(Concurrent Mark Sweep)・コレクタ- マーキングを用いて、極力メモリをロックせず、複数スレッドでGC
- 根強い人気(多分世代別コレクタが浸透しているため)( Java21 では廃止されていました。残念。)
-
G1GC(ガベージファースト・ガベージコレクタ)
- ヒープを複数のリージョンに分割し、こまめに解放していくことによりGCによる最大停止時間を少なくしようという方式
- 近年のJavaのデフォルト
-
ZGC(Zガベージ・コレクタ)(Zの意味が未だにわかっていません。。。)
- 極力停止時間が発生しないように、GCスレッドをスケーリングさせるという方式
- 世代別と非世代別が選択可能
数年前に CMS-GC のチューニングを楽しくやっていたのですが、最近のメインは G1GC になってきているので、技術の移り変わりの速さを感じます。
Heap内の構成(シリアル・パラレル・CMS)

- オブジェクトはまず、 Eden に格納される
- Eden がたまったら、利用中のものは Survivor0 に退避し、それ以外を片付ける
- 再び Eden がたまったら、 Survivor0 を含めて利用中のものは Survivor1 に退避し、それ以外を片付ける
- 何回やっても生き残ったオブジェクトは Old へ移動
- Old がたまったら、Old の利用していないものを片付ける
といった感じでオブジェクトの移動と解放を繰り返します。このケースでは領域ごとのサイズが固定で、デフォルトだと Old 領域に対して、 New 領域のサイズが小さく、 Eden 領域に対して、 Survivor 領域のサイズが小さいので、ちょっとした弊害があったりしました。
例えば、一時的に非常に大きなオブジェクトを作成するような性質のアプリケーションでは、すぐに New 領域に入りきらなくなり、それほど古くないにも関わらず Old 領域に退避されてしまい、なかなか解放されずにオンラインの後半に行くにつれて利用メモリが大きくなるという課題があったりもしました。
Heap内の構成(G1GC)
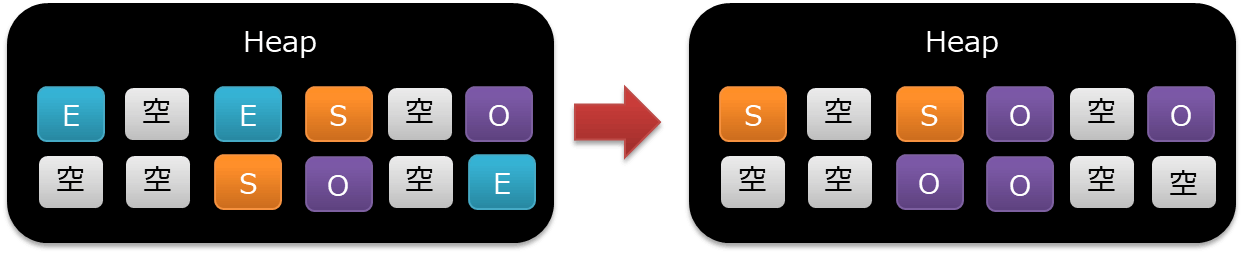
- Eden / Suvivor / Old の考え方は前述のシリアルと一緒
- 領域ごとに連続した空間になっておらず、細かい リージョン に分割し、それ毎に GC を実行
- GC の対象が大きくないので、1回の GC にかかる時間が短縮できるという考え方
- オーバーヘッド はそれなりにかかるので、そこまで万能ではない
理論上はよさそうなんですが、実際のところは次の章で確認していきたいと思います。
ガベージコレクション毎の性能
ではどのガベージコレクションがより高速に動作するのかという実験をこれからやりたいと思います。
大体のサーバアプリケーションは複数のスレッドを使いながら動作し、
テンポラリな大量のオブジェクトを生成し、たまにメモリ内にキャッシュとして保持する
という仮説に基づいて以下のようなプログラミングを行いました。
public class GCSample {
private static class SampleObject {
@SuppressWarnings("unused")
private String strValue;
@SuppressWarnings("unused")
private Integer intValue;
@SuppressWarnings("unused")
private long longValue;
@SuppressWarnings("removal")
public SampleObject() {
strValue = JITCompilerSample.execute(1000);
intValue = new Integer(100);
longValue = new Long(100L);
}
}
public static void main(String[] args) throws InterruptedException {
// 大量にオブジェクトを生成する
// たまに永続化する
// 複数のスレッドで実行
// 実行時間・スループット・レイテンシ
List<SampleObject> cachedList = Collections.synchronizedList(new ArrayList<>());
// 処理スレッドの生成
Thread th1 = new Thread(() -> execute(cachedList));
th1.start();
Thread th2 = new Thread(() -> execute(cachedList));
th2.start();
Thread th3 = new Thread(() -> execute(cachedList));
th3.start();
// 計測開始
long startNanosec = System.nanoTime();
// 終了待機
th1.join();
th2.join();
th3.join();
// 計測終了
long elapsedNano = System.nanoTime() - startNanosec;
long elapsedMicro = elapsedNano / 1_000_000;
System.out.println("経過時間:" + String.format("%,d", elapsedMicro) + " ms");
long totalMem = Runtime.getRuntime().totalMemory();
System.out.println("最終メモリ:" + String.format("%,d", totalMem) + " Bytes");
}
/** 処理を行います */
private static void execute(List<SampleObject> cachedList) {
for (int i = 0; i < 100_000; i++) {
// オブジェクトの生成
var obj = new SampleObject();
// たまにキャッシュ化
if (i % JITCompilerSample.SPLIT_TERM == 0) {
cachedList.add(obj);
}
}
}
}
このアプリを実行したところ、以下の結果になりました。
なお、私のPCは(CPU:コア = 4・プロセッサ = 8、メモリ:8GB)となっております。
太字Italicがベスト、Italicがワーストとなります。
| GC | 処理完了時間 | 利用メモリ | 合計GC時間 | 最大GC時間 |
|---|---|---|---|---|
| シリアルGC | 4,244ms | 128MB | 4,353ms | 3ms |
| パラレルGC | 5,306ms | 230MB | 5,374ms | 2ms |
| G1GC | 4,924ms | 289MB | 5,021ms | 3ms |
| ZGC | 11,002ms | 1,793MB | 10,625ms | 204ms |
単純な性能で言えば、シリアルGC と パラレルGC が良い結果が出ており、 ZGC はあまりいい結果ではなく、 G1GC が中間的な結果を出していると言えます。
ただ、Stop The World の発生は絶対に防ぎたいと考えると、 シリアルGC がまず ノックアウト となるので、よほど省メモリにしたいということでなければ、 G1GC が一番良い結果であると言えると思います。
もっとリッチなマシンを利用するのであれば、 ZGC はもっと良い結果になるかもしれないのですが、私のPCではこのような結果となりました。
近年は全体的にGCにかかる時間を短くしようというよりも、1回にかかるGC時間ができるだけ致命的にならないようにするという方向に進んでいるものと考えています。
ガベージコレクションのチューニングオプション(G1GC)
| オプション | 説明 | デフォルト |
|---|---|---|
| -Xmx | ヒープメモリの最大サイズ | (環境依存) |
| -Xms | ヒープメモリの初期サイズ | (環境依存) |
| -XX:MaxGCPauseMillis=n | 最大一時停止時間の目標 | 200 |
| -XX:GCPauseTimeInterval=n | 最大一時停止時間間隔の目標 | (環境依存) |
| -XX:ParallelGCThreads=n | GCを実行するスレッド数 | (環境依存) |
| -XX:G1NewSizePercent=n | ヒープにおけるNew領域の割合(%) | 5 |
| -XX:G1MaxNewSizePercent=n | ヒープにおけるNew領域の最大割合(%) | 60 |
これらのオプションを利用することによって、GCによる停止時間を小さめにしたり、潤沢なスペックのPCであれば、GCスレッドを増加することにより、GCにかかる時間を短縮することができたりします。
まとめ
今回Javaにおけるガベージコレクションについて記載してきました。
ZGCに関する情報がまだ思ったように収集できないので、今後ZGCが世間的に浸透したらもっと情報が出てくるのではないかと思います。
今後もJavaが発展していってくれることを願いたいと思います。
Discussion