"ベイズ統計の理論と方法" を読んでいく
概要
ベイズ統計の理論と方法 を読んでいきます。
著作権上問題もあるのでテキストの要約というよりは、テキストを持っている前提で、行間を埋めていく形でメモしていきます。重要ではないことでも、個人的に気になった点に関しては掘り下げて書いているのでその点はご了承ください。重要なことでもテキストに明確に書いてあるものは省いています。個人的にテキストと一緒に読み返せるような読書メモのような位置付けです。
1 はじめに
2 基礎概念
3 正則理論
4 一般理論
5 事後分布の実現
6 ベイズ統計学の諸問題
7 ベイズ統計の基礎
8 初等確率論の基礎
私が持っているのは初版6刷のものです。ページ数などは刷数の関係で多少前後しているかもしれません。
正誤表について
私が持っている本は初版の6刷ですが、筆者のホームページにあるミスプリント情報は2刷目までのものしか反映されていません[1]でした。ですので、本を読む際には以下のミスプリント情報をすべて適用していくことを強くお勧めします。定義式の間違いなどで気づきにくく混乱しにくいものも多数含まれているので、特に私のように慣れていない方は注意が必要です。
3刷ミスプリント
4刷ミスプリント
5~7刷ミスプリント Part1
5~7刷ミスプリント Part2
追加分ミスプリント
コロナ社の正誤表はこちら
そのほかに関してはこちらのスクラップで整理しています。
※ コロナ社の正誤表と筆者ホームページの正誤表は大体一緒だが一部は片方にしかないようなものがそれぞれ存在するので注意が必要です。全部見るしかなさそうです。
-
厳密には4刷ミスプリントの一部は反映されていました。途中で一部変更が巻き戻ったりしている可能性が高いと考えます。状況が整理できれば出版社にも連絡する予定です。 ↩︎
1 はじめに
ベイズ統計における統計的推測の考え方や基本的な概念の定義などが行われている。
定義(最低限)
テキストにならって、記号などの概念の定義をここで整理しておく。ちらっとみたときになんとか意味がわかる程度にしておく。基本的にはテキスト通りなので、詳細はそちらを参照する。
の集合をサンプルと呼び、
と書く[2]。このサンプルそれぞれは 真の分布
つまり、
また、
とする。
パラメータ
また、
をパラメータ
と定義される。さらに、
とする。また、これを自由エネルギーと呼ぶ。
埋めたい「行間」
逆温度
p.3 で突然に(逆)温度という物理的な量が出てくる。これは数学的構造が熱力学や統計力学と似ているためにアナラジーとして名付けたと推測できるが真意はわかっていない。
物理学においては、逆温度というのは温度の逆数を表す物理量である。統計力学では、ミクロな状態(粒子のエネルギーなど)は分布をもっており、それらとマクロな状態(温度、圧力など)の関係性を調べることが一つの目的になっている。実際、温度が一定の系においては、その分布(カノニカル分布と呼ぶ)がミクロな状態(
と表される。
章末問題 【1】 の証明において、 L_n(w)
章末問題【1】は次のような問題である。
次の等式が成り立つことを示せ。
\inf_\beta F_n(\beta) = \inf_{w \in W} \{ - \sum^n_{i=1} \log p(X_i|w) \}
テキストの解答では、最初に
を定義し、
テキストでは
そこまでわかると気になることは次の2点。
-
W -
W
1. について
確率モデルのパラメータ
例えば、テストの点数について推論をしたいとき、平均
実在するものと対応しないようなパラメータの場合は、人為的なものなのでどちらでも取ることができる。ただ、計算機で計算する都合上、有界閉集合に取ることが多くなると思われる。
どちらにせよ、
2. について
実は「
具体的には、次のようにする。
を定義する。(ここまではテキストと同じ)
ここで、
である。この
-
テキストでも「自然科学や情報科学において現れる確率分布は
P(x) \propto \exp(-E(x)) -
一般に有限次元のユークリッド空間においては、「コンパクト
\iff W \subset \mathbb{R}^d W \iff W d = 1 [0, 100] -
おそらく、筆者はこれも分かった上で簡略化した証明を解答として載せていると思われる。実践的にはコンパクトなことがほとんどでかつ、証明方法自体も実質的には変わらないので、「だいたいわかるでしょ」という部分なのかもしれない。 ↩︎
1 基礎概念
ベイズ統計理論の構築に向けて、真の分布と確率モデルの関係の分類や各種概念の定義がなされている。
定義(最低限)
思い出すように記載。基本的にはテキストを確認する。
平均対数損失関数
経験対数損失関数
実現可能なパラメータの集合
最適なパラメータの集合
汎化損失
経験損失
対数尤度比関数
平均誤差関数
経験誤差関数
汎化損失のキュムラント母関数
経験損失のキュムラント母関数
埋めたい「行間」
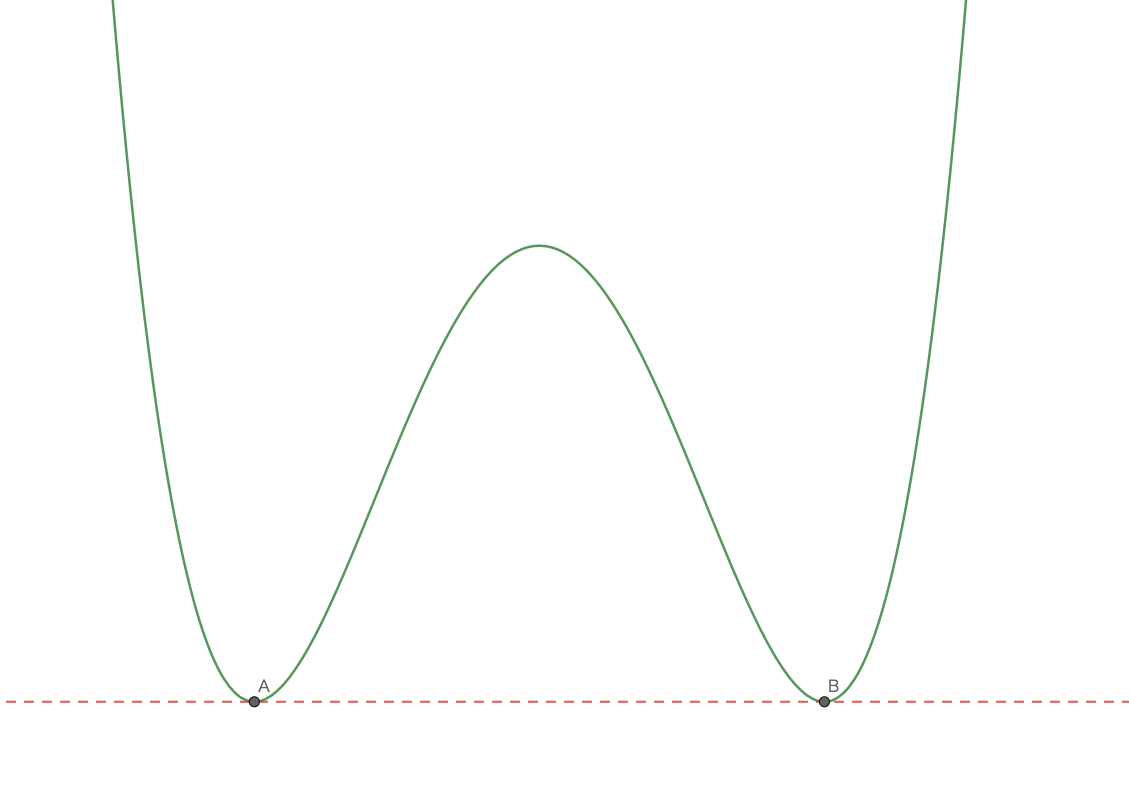
p.31 注意11 の具体例の確認
の元が複数個あるとき、 W_{00} は p(x|w) に依存しないが、微分の値は w \in W_{00} に依存して異なる。真の分布が確率モデルで実現可能な場合であっても、統計的に推測されるパラメータは真のパラメータとぴったりとは一致せず、... 微分構造を考慮する必要がある w
とあるが、この点を例を挙げて確認しておく。
という確率モデルを考える。このとき、真の分布が
であるとすると、
である。ここで、
であるので、
となる。ちょうど符号が反転しており、
p.32 正則の定義の注意点
の要素 W_0 が一つだけであり、 w_0 を含む開集合で w_0 に含まれるものが存在していてかつ、 W でのヘッセ行列 w_0 ... が正則(固有値がすべて正の値であること)であるとき、 \nabla^2 L(w_0) は q(x) に対して正則であるという p(x | w)
とある。ヘッセ行列が正則というのは、固有値がすべて正の値であることと等しいということなので、一般には正定値行列と呼ばれるものである。[1]
ヘッセ行列が正定値行列であること以外の重要な条件として
-
ヘッセ行列が正則、という表現を他で使われているかどうかの確認は出来なかった。正則の言葉がダブっていることを踏まえると誤植の可能性もあるかもしれない。 ↩︎
わかりやすくいうと、正則というのは、損失関数を最小にするパラメータが一通りに決まり、かつそのパラメータから少しズレたパラメータも最小値に近くになる、性質の良い、扱いやすい状況を指している。損失関数を最小にするパラメータが何通りもある(無限通りもありうる)ケースの方がイメージが沸きやすいので、この後本でも性質の良い正則理論から取り扱われている。
p.32 カルバック・ライブラ擬距離が0のとき、関数として q(x) = p(x | w)
真の分布と確率モデルのカルバック・ライブラ距離...はつねに非負であり、0になるのは
が成り立つ時に限る。 q(x) = p(x | w)
とあるが、証明を確認しておく。カルバック・ライブラ擬距離[1]が非負であり、0になるのは
一般に以下の対数関数において成立する不等式が成立することを利用する。
等号成立条件は
等号成立条件は、すべての
p.38 F(t) = \frac{t^2}{2} \exp(-t^{\ast}) \, (|t^\ast | < |t|)
という
が成り立つことが、平均値の定理より成り立つと書かれていたが、導出方法を確認しておく。
一方で、
が成立する。テイラー定理におけるラグランジュの剰余項を求める際に平均値の定理が必要になっている。もしかしたら、もっと直接的に平均値の定理で上記は証明できるかもしれないが、良い方法がわからなかった。
p.57 3.1.4 の平均値の定理で紹介されているものを使っても証明はできそう。ここで紹介されている平均値の定理は、上で記載したラグランジュの剰余項の内容も含むものの模様。
p.47 補題8 の証明
- 命題
- 補足する部分
(要約) 以下のヘルダーの不等式の結果と補題7と注意19とから補題8が得られる
ただし、
とする。
この省略されている部分を少し丁寧に追いかけておく。
最初に
が成り立つ。
ヘルダーの不等式の結果において、
より
である。したがって、
となる。最後の行でヘルダーの不等式の結果を使った。
以上より、
が導かれる。途中の変形で三角不等式を使った。これは
3 正則理論
p.60 補題10 の説明
確率過程
このとき、
というのが補題10であった。
説明は 8.5.3 の紹介に留めているので、この部分を少し確認する。
8.5.3 に書かれている中でこの補題に関わる部分は以下の2点。
- コンパクト集合上の正規確率過程は、平均関数と相関関数が決まるとユニークに定まる
- 経験過程は、同じ平均関数と相関関数を持った正規確率過程に法則収束する[1]
そして、
-
この事実は、関数空間での中心極限定理と呼ばれているとのこと。 ↩︎
p.63 J(w) w_0
補題13 の証明の中で、平均対数損失関数
したがって、
同じような議論で一般に、非正則行列の列は正則行列には収束しないことも証明できる(
非正則行列は
-
このことは Twitter で@mo20211201さんに教えていただいた ↩︎
p.62 補題13 のざっくりとした理解
補題13 の計算は置いておいて、ざっくりとした理解を整理しておく。
なので、
一方で、
であり、補題10より
であるので、
p.75 事後確率最大化推定量、最尤推定量、平均パラメータの違い
注意28 で真の分布が正則であり、事後分布が正規分布で近似できる場合、
p.75 定理5 の証明の補足
定理5 の証明の中でこれがさらっと書かれていたが、パッとわからなかったので補足しておく。
p.63 で議論されているように、
であり、
p.75 定理5 の解釈
定理5より
である。
また、平均対数損失関数と経験対数損失関数は第二項の2倍になっており、これも