React 18とはなにか、Fiberの観点から理解する
React 18はα版で、主にライブラリ作者のために公開されています。ユーザーが急いで知る必要はありません。この記事は、いわばオタク向けです。
React 18とはなにか、Fiberの観点から理解する
React 18では目新しい機能が多く導入されます。たとえば追加されるものにはConcurrent RenderingやstartTransition、SSRの改善やSuspenseの一部挙動変更などがあります。
私はこれらの機能について解説した記事をいくつも読みましたが、いまいちピンと来ませんでした。
- これらが凄いのは伝わるけれど、どうして必要なのか?
- なぜこれらの機能が一度に追加されたのか?
- React Core Team はどこを目指しているのか?
おそらく、多くの方がこれと同じ疑問を抱いていると思います。これらの機能追加の基本コンセプトは何でしょうか。この記事では、主に上2つの疑問に正面から向き合います。
新機能の方向性を理解するためには、React FiberがReactで果たしている役割を理解することが重要です。もったいぶらずに言うと、この記事で説明したいことは2つあり、それぞれ「①Concurrent Renderingはレスポンシブなアプリケーションを提供する」「②Concurrent APIsやSSR Streamingらは React Fiberの導入をもってはじめて可能になった機能群である」です。
それでは、React Fiberの世界に飛び込みましょう。以下でまず我々は、これまでReactが解決できなかったレンダリングの課題を確認します。つぎにこれらの課題をFiberがどう解決するのか実装されたコードをもとに探っていきます。その後、データ取得においても難点を抱えていることを確認し、それをSuspenseがどう解決するのかを確認します。
Fiberとレスポンス性の向上
Fiberと本質的に関わる、ブロッキングレンダリングから探っていきましょう。
Blocking and Concurrent Rendering
React 18ではデフォルトのレンダリング方法が変更されました。Blocking Renderingはこれまでのレンダリング方法のことで、対してConcurrent RenderingはReact 18 から可能になったレンダリング方法をさします。Concurrent Renderingはバックグラウンドで多くの処理が行われていてもユーザーの入力を受け付けるため、Blocking Renderingに比べて高いレスポンス性という特徴があります。
触ったほうがわかりやすいので、まずデモを触ってBlocking RenderingとConcurrent Renderingの違いを体感してみましょう。フラクタルを"Lean the tree"のスライダーを操作して左右に動かせるアプリです。左端のスライドを上に上げて負荷を増やしたり、"use startTransition"のオンオフを切り替えてみてください。どうなるでしょうか?
おそらく、高負荷の際にstartTransitionを使わないと、「動かそうとしてもスライダーが動かない」状況になり、startTransitionをオンにすると「処理が重くてもスライダーが動き、比較的短時間で図形に反映される」ことが確認できるのではないでしょうか(確認できなければ、CPUのスロットリングやデバウンスにチェックをいれることを試してみてください)。これがConcurrent Renderingの力です。
(このアプリはつねにReact 18で動いているので、すこしミスリーディングなのですが。FiberではなくStackで動いている例があれば教えて下さい。)
観察できる違いを明確にしておきましょう。旧来のレンダリング方法(Blocking Rendering)の高負荷での特徴は次のとおりです(これらを覚える必要はありません)。
- 描画がスローモーションのように遅くなる
- その間スライダーをほとんど動かせない
- レンダリングの負荷を示す画面上部のレーダーは赤色(遅延大)や、描画が止まる
Chrome DevToolsのパフォーマンスタブから確認すると、一回のTaskに500 ~ 1200msほどかかっており、複数回のレンダリングが連続して起こっています。画像の上部分から、Task数回ごとにフラクタルが変形していることがわかります。
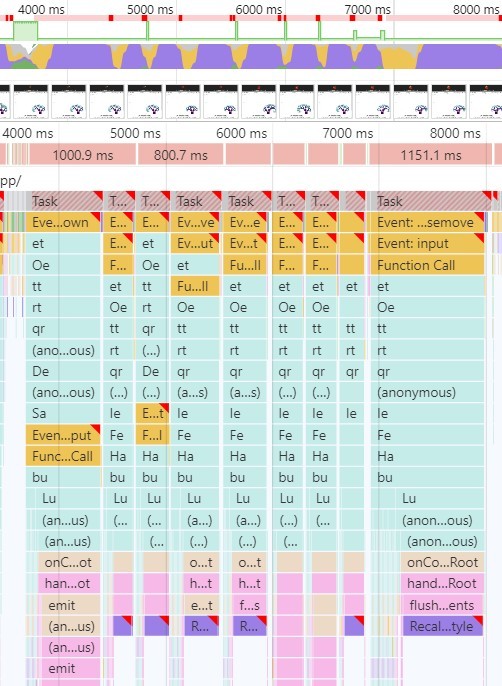
一方でstartTransitionをオンにすると(Concurrent Rendering)高負荷のときの特徴は次のとおりです。
- 途中の変形はスキップされ最終的なフラクタルだけが表示される
- スライダーは比較的スムーズに動く
- 画面が更新される直前だけスライダーが動かなくなる
- 画面上部のレーダーは緑やオレンジ色(低負荷から中負荷)が多い
Chrome DevToolsから確認すると、Concurrent Renderingには所要時間が全く違う2種類のTaskがあります。右のTask(DOMの更新)は800msかかっているのに対し、左のTask群はごく短時間(5ms)のTaskが連続しています。また、この画像からはわかりませんが、Blocking Renderingと異なり長時間のタスクが連続していません。
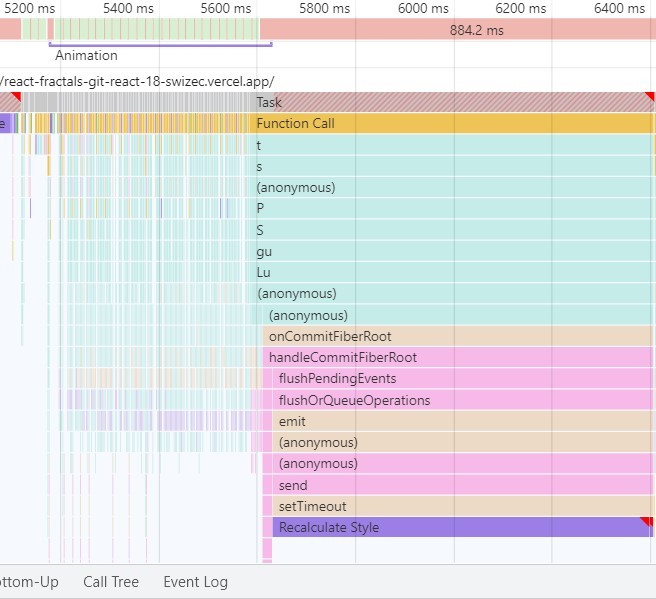
つまり、高負荷でのBlockingとConcurrentレンダリングの違いはこうまとめられます。
- Blockingはゆっくりと描画するのに対し、Concurrentは最後以外の描画をスキップする
- 高負荷な計算中、Blockingはユーザーの入力に反応せず、Concurrentは反応することが多い
- Blockingは大きなTaskが5秒以上連続している一方、Concurrentは2種類のTaskがあり、大きなTaskは連続しない
これら詳細な違いを措いても、2つのレンダリング方法の比較から次のように言うことができます。高負荷のときConcurrent Renderingはよりインタラクティブで、ユーザーの入力を阻害しません。
これらの違いは、Reactがレンダリングする方法によって生まれています。Concurrent RenderingはReact Fiberを使うことで、よりインタラクティブでスムーズな体験を提供します。一方、Blocking Renderingは従来のアルゴリズムを使っているため、負荷に対して脆いです。
(デモで示した例は、React Fiberでブロッキングレンダリングをエミュレートしたものです。)
この2つのアルゴリズムはどう異なるのでしょうか?
Stack Reconciler
かつてReactは差分検知システムReconcilerに、いまはStack Reconcilerと呼ばれるアルゴリズムを使っていました。これが、Blocking Renderingに結びつくものです。Stack Reconcilerは再帰的にコンポーネントを呼び出すことで差分検知を実現します。まず、再帰的な呼び出しによって呼び出されたコンポーネントの作業はコールスタックと呼ばれるStackに格納されます。コールスタックは自身に格納された処理がなくなるまで、休みなくそれらを処理し続けます。この再帰的な処理が終わるとReactはどこが更新されたか把握するため、画面を更新します。
さて、Stack Reconcilerの問題は、レンダリング中に画面が固まってしまうことです。コールスタックはインタプリタの領域にあり、Reactがこれらを中断しろと指示することができません(と理解しています)。そのため、コールスタックは重い処理が紛れ込んでも自身を空にするまでずっと働きます。ふつうレンダリングの計算は高速に終わるので、画面の停止は知覚できないほど短いです。しかし計算が長時間続くとフレーム落ちが発生し、アニメーションの描画やユーザーの入力への反応への遅れが生じます(デモ)。これは先程デモのBlocking Renderingで見た現象で、ユーザー体験を損なわせる現象です。
率直にいって、もっと動的なものを提供できればよいでしょう。欲を言えば高負荷の処理中でも、ユーザーのイベントにはすぐに反応してほしいですし、アニメーションはフレーム落ちなくなめらかに表示されてほしいです。これらを実現するにはReactに以下の機能が必要です。
- 中断可能な作業を小分けに分割する機能
- 進行中の作業に優先順位を付けたり、再配置や再利用をする機能
しかしStack Reconcileでは、これらの機能が追加できません。コールスタックを使っているため、中断できるかたちで作業をすることも、優先順位をつけることもできません。Stack Reconcilerでは難しいこれらの機能を実現するのがReact Fiberです。
Fiber Reconciler
Fiber Reconcilerは協調的マルチタスクと呼ばれる方法を採用しています。
まず、個々の作業単位を細かく分割することで、ミリ秒レベルのマイクロタスク化します。Fiberはそれぞれが次のFiberへのポインタを持っているので、中断しても復帰できるようになっています。
// 深さ優先探索で次のfiberを決める
let root = fiber;
let node = fiber;
while (true) {
// Do something with node
if (node.child) {
node = node.child;
continue;
}
if (node === root) {
return;
}
while (!node.sibling) {
if (!node.return || node.return === root) {
return;
}
node = node.return;
}
node = node.sibling;
}
次に優先度の実装です。React内部で優先度には2つあり、片方をReconciler内のLaneが、もう片方をSchedulerのHeapが管理しています。Laneは優先度の計算にBit演算によるフラグ管理を用いています。
n個のBitを独立したフラグとみなすと、立っているフラグの集合を対応する数値で表現することができるため、集合への操作をSetよりも高速なbit演算でまかなえます。
export function getHighestPriorityLane(lanes: Lanes): Lane {
return lanes & -lanes;
} // 立っているフラグのうち、一番右のフラグを与える
Laneにより、同じ優先度をもつstateの更新がバッチ処理されることを保証します。
SchedulerはJavaScriptのイベントループと共存できるように作られた独自のイベントループです。今積まれているタスクtaskQueueと将来やるべきタスクtimerQueueをヒープで管理して、taskQueueから順に処理していきます。
function workLoop(hasTimeRemaining, initialTime) {
let currentTime = initialTime;
// 時計を進め続けて、仕事ができたら作業を開始する
advanceTimers(currentTime);
currentTask = peek(taskQueue);
while (
currentTask !== null
) {
if (
// まだtaskの実行を遅らせる猶予があり、一度作業を中断しなければいけない
currentTask.expirationTime > currentTime &&
(!hasTimeRemaining || shouldYieldToHost())
) {
// This currentTask hasn't expired, and we've reached the deadline.
break;
}
const callback = currentTask.callback;
if (typeof callback === 'function') {
currentTask.callback = null;
currentPriorityLevel = currentTask.priorityLevel;
const didUserCallbackTimeout = currentTask.expirationTime <= currentTime;
const continuationCallback = callback(didUserCallbackTimeout);
currentTime = getCurrentTime();
if (typeof continuationCallback === 'function') {
currentTask.callback = continuationCallback;
} else {
if (currentTask === peek(taskQueue)) {
pop(taskQueue);
}
}
advanceTimers(currentTime);
} else {
pop(taskQueue);
}
currentTask = peek(taskQueue);
}
// Return whether there's additional work
if (currentTask !== null) {
return true;
} else {
const firstTimer = peek(timerQueue);
if (firstTimer !== null) {
requestHostTimeout(handleTimeout, firstTimer.startTime - currentTime);
}
return false;
}
}
Taskは5msごとに終わるので、ブラウザイベントが発生していないか5msごとに確認できるようになっています。
違いを簡単に説明する
たとえるなら、Stack ReconcilerとFiber Reconcilerの違いは、忙しくても時間をとってくれる同僚と、忙しいと返事がこない同僚の違いのようなものです。
私:すみません、この書類にサインもらっていいですか?
----5時間後-----
Stack: 了解です😁
私:(略)
Fiber:了解です。 5分後だったらすこし時間取れますよ😁
おそらく、StackよりFiberと一緒に仕事をしたいだろうと思います。でも、Fiberはもっと優秀です。
私:今のプロジェクト、細かい仕様変更が入りました。
Fiber: じゃあ今やっている作業は不要ですね。これは捨てて、新しい作業を一から始めます。
Stack: (積み上げられたタスクがなくなるまでチャットを確認しない)
Stackはn回の変更に対してn個のアウトプットを出します。一方Fiberは作業が終わればそれを提出しますが、完了前にまた変更が入ると、優先度の高いものだけを更新します。
なかなか賢いと思いませんか?
結局どう体験がかわったのか
Concurrent Renderingによって、ReactはレスポンシブでなめらかなUIをより簡単に提供できるようになりました。フレーム落ちが生じなくなり、画面のブロックも以前より少なくなります。
強調しておきたいのは、Concurrent Renderingに限らずReact 18は全般的にUXを重視している点です。
アプリの合計起動時間だけに注目したくなりますが、ユーザーのパフォーマンスの認識は、読み込み時間の数値だけでは決定されないことがわかりました。たとえば、絶対起動時間が同じ2つのアプリを比較すると、ユーザーは通常、中間の読み込み状態が少なく、レイアウトの変更が少ないアプリの方が読み込みが速いと感じます。サスペンスは、コンテンツを徐々に明らかにするいくつかの明確に定義された状態を使用して、エレガントなロードシーケンスを注意深く調整するための強力なツールです。
小林 ここは誤解されやすいところなんですが、Fiberは単純な速度の向上を目指したアップデートではありません。 あくまで、リコンシリエーションが非同期化され、ユーザーインタラクションを阻害しなくなったということが重要です。 スピードではなくレスポンスの向上を目指していると言ってもいいでしょう。
なので、ベンチマーク結果が劇的に向上するようなことはないでしょう。 おまけに、後方互換性も保たれているので、16になったときに「何も変わってないじゃないか」と言われるのは、予想の範疇であるとも言えます(笑)。
React 18がUXを向上させる例として、デバウンスを今後使う必要がないことが挙げられます。これまで高頻度の更新で入力がつっかえる際にはデバウンスなどでパフォーマンス悪化を防ぐ必要がありました。デバウンスは低いスペックのマシンで描画が遅い問題を解決するために、どんな高性能のマシンでも描画を人工的に遅くして負荷を下げるものです。しかし、これからは、高性能のマシンには最高のUXを、低性能のマシンには悪くても以前よりは良いUXを提供することができます。
Concurrent APIを使いたいかは、アプリケーションによるでしょう。しかし、React 18からなめらかで魅力的なアプリケーションをつくるReactの引き出しが増えたのは間違いないと思います。
Reference
Questions about specifics of Concurrent scheduling
Real world example: adding startTransition for slow renders
データ取得の問題
React FiberはConcurrent Rendering以外にも、様々な機能を可能にします。今回は、Suspenseを導入することでデータ取得がどのように変化するか確認しましょう。
従来のfetch方法の課題と、Suspenseの解決策
1.レンダー後にフェッチが始まる
ここにユーザー名と記事を取得するコードがあります。この2つのコンポーネントが表示されるタイミングを見てください。
親コンポーネントに比べて、子コンポーネントは表示に時間がかかっているようです。必要なデータ取得にかかる時間が違うからでしょうか?この推測は正しいですが、データ取得にかかる時間が等しい場合でも、子コンポーネントは表示まで時間がかかります。
実はこのコードで、2つのデータ取得の開始タイミングは同じではありません。親コンポーネントのProfilePageは、初めて呼ばれるとき、useEffectでデータ取得を開始します。ですが子のProfileTimeLineは親のuserに値が入るまで呼び出されないため、親のデータ取得が終わるのを待ってから自身のデータ取得を開始します。
return(
<ProfilePage>
{user && <ProfileTimeLine /> }
</ProfilePage>
)
開始タイミングのずれはコンポーネントが呼び出されるタイミングが原因なので、並行してデータを取得してよい場合でも同様のことが起こります。
なぜでしょうか?このコードで開始タイミングがずれる原因は、userデータを取得するまでProfileTimeLineコンポーネントが呼び出されないことです。ReactはProfileTimeLineを表示することになって初めてProfileTimeLineを呼び出します。このタイミングでfetch関数が実行されるため、データ取得のタイミングがずれるのです。これをウォーターフォールと呼びます。
ウォーターフォールの問題は、「userの値によって表示を切り替える」というUIの記述が、データ取得関数を呼び出すタイミングと密接な関係をもってしまっていることです。そのため、必要な情報をそのコンポーネントで素直に取得すると、並行で取得してよいデータを一つずつ取得しなければなりません。
問題:素直な実装では、関数が実行されるまで時間がかかる
2. フェッチを始めてからレンダーする
ウォーターフォールの例では親コンポーネントが子コンポーネントのデータ取得をブロックしているので、親コンポーネントで両方のデータを取得するように改善しましょう。
2つとも同時に表示されるようになりました👏。
ただ、この実装ではデータ取得が1つでも遅いとき、それが完了するまで全てのデータが表示されません。
useEffect(() => {
promise.then(data => {
setUser(data.user);
setPosts(data.posts);
});
}, []);
1つのデータ取得完了を全てが待つ問題は、各データ取得を独立させることで解消できます。しかしこれは「ちぐはぐなデータが表示される」といった、データの不整合を起きやすくします。
データの不整合がどのように感じられるか、次の例を想像してみてください。TwitterでDan Abramovのアカウントを見ようとすると、ページは遷移してもこれまで見ていたSebastian Markbågeの情報が表示されたままで、Danのデータ取得が完了するたびにアイコンやプロフィールやツイートが徐々にDanのものに更新されていきます。すべての部品がDanのものになってからも、「完璧なページ」が表示されたとあまり感じないのではないでしょうか。ユーザーとして見ると、データがちぐはぐなまま表示されるとアプリケーションの魅力が損なわれます。そして開発者としては、面倒でもこれをどうにか修正したくなるでしょう。
このように、データを上位コンポーネントで一括取得する方法はデータの不整合を常に気にかける必要があり、メンテナンスのコストが高いです。データの数が多くなり表示タイミングが複雑になるほど、考慮することも複雑になります。また、この方法は関心の分離をあきらめてデータ取得を一つのコンポーネントにまとめているので、表示タイミング以外のメンテナンスも大変です。このようにデータ取得を一元化すると、表示スピードを得るかわりにメンテナンス性を下げなければなりません。
まとめると、Reactのデータ取得の問題はデータを表示するまでのスピードとメンテナンス性を両立できないことでした。Reactでは宣言的なUIの記述と関数の呼び出しタイミングが深く結びついているため、データ取得を素朴に実装するとウォーターフォールが起きて表示スピードが遅くなります。そして「フェッチしてからレンダー」のパターンはスピードを解決できますが、ロジックがいたずらに複雑化するため、メンテナンスがひどく大変になります。宣言的UIが呼び出しのタイミングを決めてしまう問題にどう対処すればよいのでしょうか?
3. Render-as-You-Fetch Suspense / データを取得しながらレンダーする
「それならコンポーネントが表示できるかに関わらず、関数を呼び出してしまえばいい」と考えたかもしれません。まさしく。これこそSuspenseがReactのデータ取得を変える点です。
次のコードを見てください。
function ProfilePage() {
return (
<Suspense
fallback={<h1>Loading profile...</h1>}
>
<ProfileDetails />
<Suspense
fallback={<h1>Loading posts...</h1>}
>
<ProfileTimeline />
</Suspense>
</Suspense>
);
}
このコードは、これまでのコンポーネントをSuspenseで囲み、userの値で振り分けることをやめただけです。しかし、これだけで並列的にデータ取得ができるようになります。Suspenseがどのようにコンポーネントを処理するか見てみましょう。
Suspenseを使うと、ReactはまずSuspenseで囲われたコンポーネントを呼び出し、レンダリングを開始します。もしデータが取得されていないなら、Reactはそのコンポーネントを「サスペンド」して、ほかのコンポーネントのレンダリングを試みます。Suspense配下のコンポーネントすべてのレンダリングを試みた後、サスペンドしたコンポーネントがあれば、Suspense配下のコンポーネントを表示せずフォールバックを表示します。
Suspenseで囲わなかった場合と違うのは、リソースが準備できるかに関わらずレンダリングを試みることです。
fetchPostsとfetchUserのsetTimeOutを変更してみて、fallbackの表示がどう変化するか確認してみてください。Postの取得が遅い場合には、ProfileTimeLineだけにfallbackが出て、ProfileDetailsは表示されます。一方でUserの取得が遅い場合には、どちらのコンポーネントも表示されません。このようにSuspenseはデータの不整合を防いでくれます。
SuspenseとFiber
これもまた、React Fiberに実装がかわったことで実現した機能です。Stack Reconcilerでは、描画しないものを計算できるようにしたとしても、それを保存する場所がありませんでした。しかしFiber Reconcilerでは個々のFiberに情報を結びつければいいため、比較的容易にこれを実現することができます。
Reference
おわりに
React Fiberは、SuspenseやConcurrent Renderingだけにとどまらず、SSR StreamingやServer Side Componentらも可能にしています。これまで構造上難しかった様々な問題を、一つのデータ構造によって解決しており、とてもエキサイティングです。「アイデアというのは複数の問題を一気に解決するものである」](https://www.1101.com/iwata/2007-08-31.html)という言葉がありますが、React Fiberはそういったアイディアの一つでしょう。
Further Readings
上のものほど実装への言及が少なく、概念的に理解できます。下のものは実際にコードを読みたい人向けです。
Andrew Clark - React Fiber Architecture 2016 翻訳
Lin Clark - A Cartoon Intro to Fiber - React Conf 2017
React 18 Working Group - Questions about specifics of Concurrent scheduling 2021
@koba04 - React Fiber 現状確認 2017
白石 俊平 - ReactはなぜFiberで書き直されたのか?Reactの課題と将来像を探る 2017
Max Koretskyi - The how and why on React’s usage of linked list in Fiber to walk the component’s tree 2018
Andrew Clark - Initial Lanes implementation 2020 拙訳
okmttdhr - ReactのLaneとはなにか React Fiberのアルゴリズムを実装してみた2021
また、これ以上詳しく知りたい場合、次のリポジトリらが便利です。
@koba04 -React Fiber resources
@7kms - react-illustration-series
Internal stories
脚注
- ところで、Stack Reconcilerは再帰呼び出しで実装されているため、自前のStackにデータを保存しているわけではありません(実際、Stackで中断することは容易です)。Stack Reconcilerという呼び方は問題の本質がStackという"データ構造"にあると混乱させるので、Recursive ReconcilerやCall Stack Reconcilerと呼んだほうが適切かもしれません。
- Brian Vaughnがツイッターでスペースを開いていたので今後の変更について質問してみたところ、Fiberをダブルバッファリングモデルから変えていく可能性があると回答をもらいました。
Discussion