Plotlyで出力したSVGの読み書きをするTips
SVG 出力したグラフから凡例を切り取りたい…
前回の記事でデータ個数によるグラフの違いを解説しました。
今回はSVG出力された画像から凡例とグラフを分けるTipsを紹介します。
SVGの操作はPython標準搭載のxmlライブラリを使用しました。
前段: 前回出力したグラフ
今回は以下コード(前回記事)で出力した画像を基に分割作業を行います。
import numpy as np
import plotly.graph_objects as go
import plotly.io as pio
N = 20
random_x = np.linspace(0, 1, N)
random_y0 = np.random.randn(N) + 5
random_y1 = np.random.randn(N)
plot = [
go.Scatter(
mode="lines+markers",
x=random_x,
y=random_y0,
name="sampleA",
line=dict(color="blue", dash="solid"),
marker=dict(symbol="circle-open"),
),
go.Scatter(
mode="lines+markers",
x=random_x,
y=random_y1,
name="sampleB",
line=dict(color="red", dash="solid"),
marker=dict(symbol="circle-open"),
),
]
fig = go.Figure(data=plot)
# SVG出力
pio.write_image(fig, "./output.svg", format="svg")
出力された画像はこちら
この画像から凡例とグラフを別々に出力したいと思います。
画像の構成要素を確認する
画像の要素をデベロッパーツールで解析します。
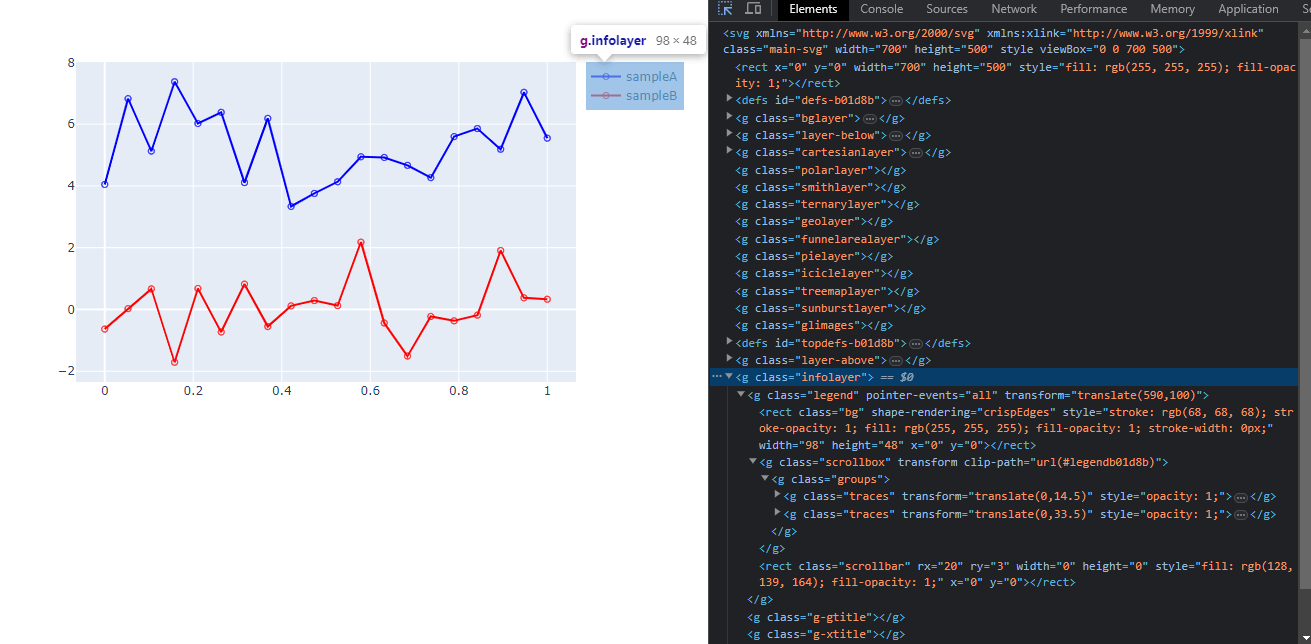
凡例のところだけ切り抜くと以下のようになります。
<svg>
<!-- レイアウト情報 -->
<g class="infolayer">
<!-- 凡例関係 -->
<g class="legend">
<rect class="bg"></rect>
<g class="scrollbox">
<g class="groups">
<!-- ここに凡例の各要素が格納されている -->
<g class="traces"></g>
<g class="traces"></g>
</g>
</g>
<rect class="scrollbar"></rect>
</g>
</g>
</svg>
infolayer→legend の順で掘っていければ目的の凡例に辿り着けそうです。
凡例出力用のテンプレートを準備する
凡例の位置は画像からの絶対値で決まっているようです。
<g class="legend" ... transform="translate(*,*)">の translate は不要のため
テンプレートを準備し、そこに取得した要素を挿入する形にしました。
そのテンプレートがこちらです。
width, heightは環境に合わせて適宜修正してください。
<svg
class="main-svg"
xmlns="http://www.w3.org/2000/svg"
xmlns:xlink="http://www.w3.org/1999/xlink"
width="700"
height="500"
style=""
viewBox="0 0 700 500"
>
<g class="infolayer">
<g class="legend" pointer-events="all"></g>
</g>
</svg>
SVGをXMLとして読み取る
SVGをXMLとして読み込みます。
画像は上で紹介した./output.svgです。
import xml.etree.ElementTree as ET
from pathlib import Path
input_path = Path("./output.svg")
# 読込
tree = ET.parse(input_path)
# 要素を取得
root = tree.getroot()
print(root)
# <Element '{http://www.w3.org/2000/svg}svg' at *********>
rootが要素のルートになります。
ここから検索して目的の凡例を取得します。
凡例を取得する
凡例の要素を取得します。
gタグは{http://www.w3.org/2000/svg}gで要素検索が可能です。
SVG読込→レイアウト検索→凡例検索→要素取得
の順番です。
import xml.etree.ElementTree as ET
from pathlib import Path
# xmlで読み込んだgタグ
SVG_G_TAG = "{http://www.w3.org/2000/svg}g"
input_path = Path("./output.svg")
tree = ET.parse(input_path)
root = tree.getroot()
# 大元gタグからレイアウト情報取得
g_elems = root.findall(SVG_G_TAG)
info_elems = next(filter(lambda x: x.attrib["class"] == "infolayer", g_elems))
# レイアウト情報から凡例取得
layer_elems = info_elems.findall(SVG_G_TAG)
legend_elems = next(filter(lambda x: x.attrib["class"] == "legend", layer_elems))
findall()でgタグを全て取得します。
その後、next*filterを使用しgタグの中からレイアウト情報と凡例それぞれのクラス名で検索し、要素を特定します。
これで<g class="legend">...</g>が取得できました。
テンプレートに要素を追加する
取得できた要素をテンプレートに追加します。
まずは読み込みと凡例の箇所まで検索します。
import xml.etree.ElementTree as ET
from pathlib import Path
template_path = Path("./legend_template.svg")
template_tree = ET.parse(template_path)
template_root = template_tree.getroot()
# 凡例のタグを取得
template_legend = template_root.find(f"{SVG_G_TAG}/{SVG_G_TAG}")
if template_legend is None:
raise
findメソッドは検索条件に一致する要素を取得します。
結果はOptionalなので、一度None判定を入れて型アノテーションを確定させます。
その後、テンプレートの凡例に対して要素を追加します。
追加するにはappendメソッドを使用します。
# テンプレートに凡例を追加
[template_legend.append(elem) for elem in legend_elems]
legend_elemsが元画像から取得した凡例要素です。
リストの内包表記で凡例以下のタグを全て追加します。
凡例画像出力
凡例画像を出力します。
しかし、そのまま出力するとns:0というNamespaceが追加されてしまいます。
そのため、こちらの記事を参考にns:0を追加しないように上書きします。
# 結果反映
template_tree = ET.ElementTree(template_root)
# ns:0対策
namespaces = {
node[0]: node[1] for _, node in ET.iterparse(template_path, events=["start-ns"])
}
for key, value in namespaces.items():
ET.register_namespace(key, value)
# 凡例出力
legend_output_path = Path("./legend.svg")
template_tree.write(legend_output_path)
出力された画像を確認します。
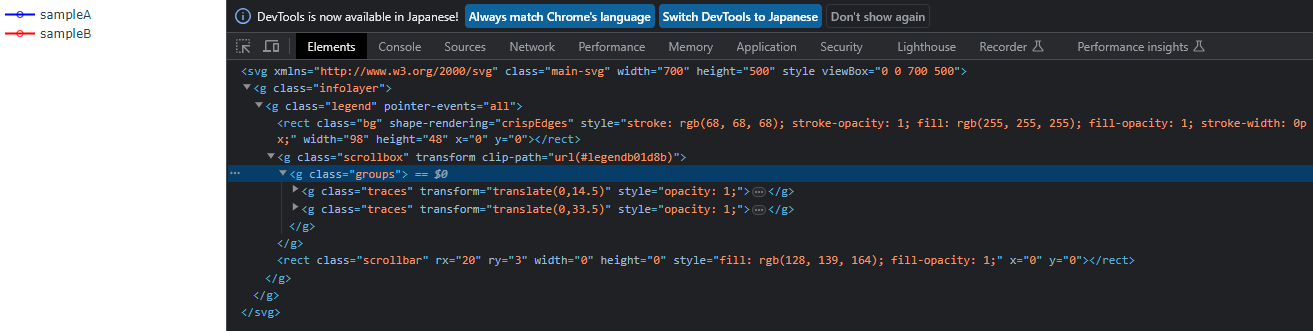
凡例だけ切り抜くことに成功しました。
元画像から凡例を削除
元画像から凡例部分を削除して出力します。
要素の削除にはremoveメソッドを使用します。
# 凡例部分削除
info_elems.remove(legend_elems)
# 変更反映
tree = ET.ElementTree(root)
# xmlタグ対策
target_namespaces = {
node[0]: node[1] for _, node in ET.iterparse(input_path, events=["start-ns"])
}
for key, value in target_namespaces.items():
ET.register_namespace(key, value)
# 凡例を切り取ったグラフ出力
graph_output_path = Path("./graph.svg")
tree.write(graph_output_path)
グラフの画像を確認します。
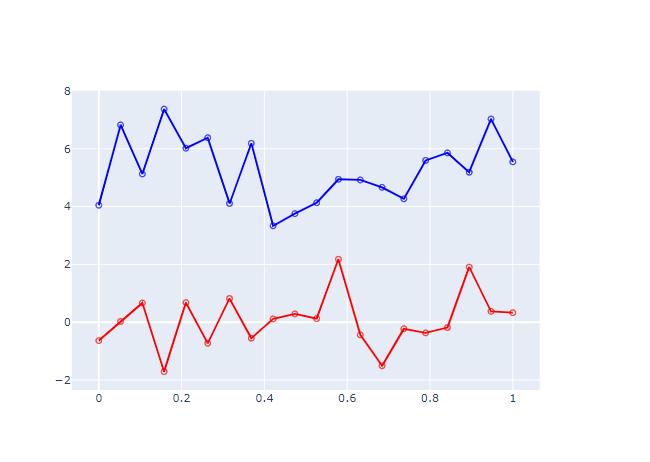
凡例が切り取られているのが確認できました!
実装コード
上記の処理の実装コードです。
import xml.etree.ElementTree as ET
from pathlib import Path
# xmlで読み込んだgタグ
SVG_G_TAG = "{http://www.w3.org/2000/svg}g"
input_path = Path("./output.svg")
template_path = Path("./legend_template.svg")
tree = ET.parse(input_path)
root = tree.getroot()
# 大元gタグから情報レイヤー取得
g_elems = root.findall(SVG_G_TAG)
info_elems = next(filter(lambda x: x.attrib["class"] == "infolayer", g_elems))
# 情報一覧から凡例取得
layer_elems = info_elems.findall(SVG_G_TAG)
legend_elems = next(filter(lambda x: x.attrib["class"] == "legend", layer_elems))
template_tree = ET.parse(template_path)
template_root = template_tree.getroot()
# 凡例のタグを取得
template_legend = template_root.find(f"{SVG_G_TAG}/{SVG_G_TAG}")
if template_legend is None:
raise
# テンプレートに凡例を追加
[template_legend.append(elem) for elem in legend_elems]
# 結果反映
template_tree = ET.ElementTree(template_root)
# ns:0対策
namespaces = {
node[0]: node[1] for _, node in ET.iterparse(template_path, events=["start-ns"])
}
for key, value in namespaces.items():
ET.register_namespace(key, value)
# 凡例出力
legend_output_path = Path("./legend.svg")
template_tree.write(legend_output_path)
# 凡例部分削除
info_elems.remove(legend_elems)
# 変更反映
tree = ET.ElementTree(root)
# ns:0対策
target_namespaces = {
node[0]: node[1] for _, node in ET.iterparse(input_path, events=["start-ns"])
}
for key, value in target_namespaces.items():
ET.register_namespace(key, value)
# 凡例を切り取ったグラフ出力
graph_output_path = Path("./graph.svg")
tree.write(graph_output_path)
SVGはXMLとして操作可能
plotlyから凡例を切り取る方法を紹介しました。
SVGはXMLとして読み込んで処理ができる事を発見したので
今後、色々と活用できそうです!
今回のソースはこちらに置きました。
Discussion