ELYZA-Thinking-1.0で数学オリンピック予選問題を解く
2025/05/01、ELYZAが新しい日本語モデルを三つ公開しました。
- ELYZA-Thinking-1.0-Qwen-32B
- ELYZA-Shortcut-1.0-Qwen-32B
- ELYZA-Shortcut-1.0-Qwen-7B
詳細は下記記事にあります。
すごいところ
- 日本語でreasoningモデルを作成(日本語による数学的、論理的思考能力を向上)
- 非reasoningモデル(Shortcutモデル)の論理的思考能力向上にも成功
- MCTSを合成データセット作成に活用
さて、せっかく有力な日本語モデルが登場したということで、試さない手はないです。数学の問題を解いてもらいましょう。今回はELYZA-Shortcut-1.0-Qwen-7BとELYZA-Thinking-1.0-Qwen-32Bで数学オリンピックの問題にチャレンジしていきたいと思います。具体的にはローカルのGPUマシン(RTX A6000)でvLLMを使ってモデルを動かして、Streamlitで作ったチャットアプリで呼び出します。
以下は詳細な説明。(忙しい人は問題を解くに進んでもOK)
背景と実装
背景(ざっくりと)
大まかにいえば、AlibabaのQwen2.5-32B-Instruct、Qwen2.5-7B-Instructに追加の学習を行い、日本語推論能力を改善したモデルです。
Thinkingモデルは長い思考過程ののちに回答を出力するモデル(reasoningモデル)で、オリジナルのQwen2.5-32B-Instructよりも高い性能を各種日本語ベンチマークと英語の数学ベンチマーク(MATH-500)で発揮しました。
Shortcutモデルは、長いreasoningを経たうえで出てくる回答を、reasoning抜きで再現(shortcut)できるよう問題と答えのペアのみで学習させたモデルです。32Bのshortcutモデルは各種日本語ベンチマークと英語の数学ベンチマークで、GPT-4oと同等以上の精度を達成しました。
特に面白いのがMCTSを使って合成データセットを作成した点です。もともとMCTSは囲碁などのゲームでよく用いられてきた探索アルゴリズムでした。LLMのtokenを出力していき、最終的に目的を達成できるような「よい文章」を作成する過程が、ゲームの手番を進めて勝利を目指すのと似ていることから、推論モデルの訓練でも注目されています。今回は、「妥当な思考過程」を探索、生成するうえで、MCTSが活用されました。
実装
環境
- Windows 11
- WSL2 (Ubuntu 24.04)
- Intel Core i9-10980XE CPU @ 3.00GHz
- NVIDIA RTX A6000
- uvで環境管理
- サーバ側
- Python 3.12
- vLLM==0.8.5
- クライアント側
- Python 3.12
- openai==1.76.2
- streamlit==1.45.0
vLLM
今回はVLLMでELYZA-Thinking-1.0-Qwen-32Bが動作するサーバを立てました。
ELYZA-Shortcut-1.0-Qwen-7B
$ vllm serve elyza/ELYZA-Shortcut-1.0-Qwen-7B \
--max-model-len 32768
ELYZA-Thinking-1.0-Qwen-32B
$ VLLM_USE_V1=0 vllm serve elyza/ELYZA-Thinking-1.0-Qwen-32B \
--max-model-len 8192 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--cpu-offload-gb 32
に基本的には準拠していますが、Thinkingモデルの方は48GBのVRAMに乗り切らず、max-model-lenを減らしたり、CPU offloadingをオンにしたり、その際にGPUの互換性の問題でVLLM_USE_V1を0にしています。
下記のような画面が出てくれば成功で、localhost:8000にOpenAI互換のAPIサーバが起動します。
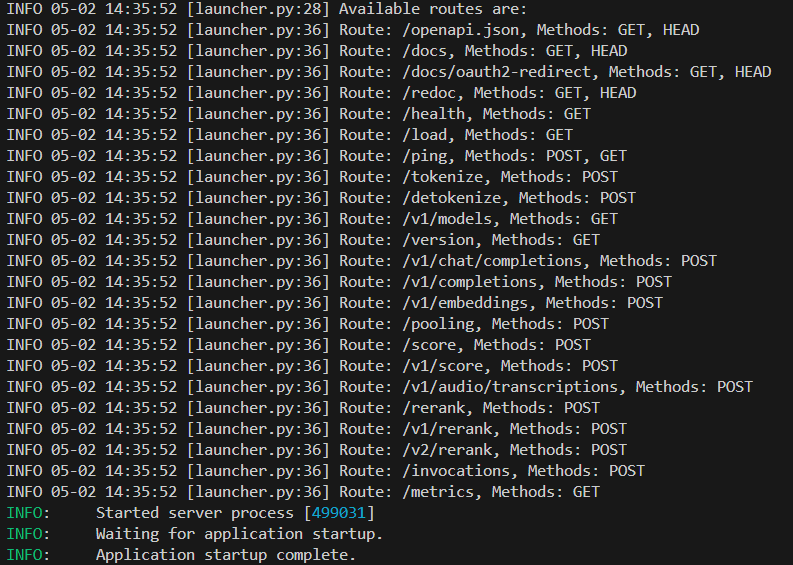
ChatはStreamlitで
ちょっと試してみる上では不要ですが、せっかくなのでUIも用意しましょう。vLLMでOpenAI互換のAPIサーバが起動しているので、openaiライブラリで接続できます。Streamlitのwrite_stream関数で、LLMのレスポンスをstreaming表示できます(便利!)。
Reasoning部分はreasoning_contentに格納されて吐き出されます。今回は推論開始と推論終了で挟んでわかるようにします。
import streamlit as st
from openai import OpenAI
# ---------- 初期化 ----------
@st.cache_resource(show_spinner=False)
def get_client():
return OpenAI(
api_key="token-abc123",
base_url="http://localhost:8000/v1",
)
client = get_client()
if "messages" not in st.session_state:
st.session_state.messages = [] # Chat 履歴を保存
# ---------- 画面 ----------
st.title("LLM Chat")
# 過去ログを描画
for m in st.session_state.messages:
with st.chat_message(m["role"]):
st.markdown(m["content"])
# 入力欄
prompt = st.chat_input("メッセージを入力してください") # Streamlit 1.28~ :contentReference[oaicite:1]{index=1}
if prompt:
# ユーザ入力を即表示
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)
# アシスタント用プレースホルダ
with st.chat_message("assistant"):
# st.write_stream は「文字列を yield するジェネレータ」を受け取る :contentReference[oaicite:2]{index=2}
def stream_from_vllm():
collected = ""
response_stream = client.chat.completions.create(
model=client.models.list().data[0].id, # vLLM が返すモデル名
messages=[
{"role": "system", "content": "あなたは有能なアシスタントです。"},
*st.session_state.messages
],
stream=True,
)
reasoning_flag = False
for chunk in response_stream:
print(chunk.choices[0].delta) # デバッグ用
token = getattr(chunk.choices[0].delta, "content", "")
reasoning_token = getattr(chunk.choices[0].delta, "reasoning_content", "")
print(token, reasoning_token) # デバッグ用
if reasoning_token:
if not reasoning_flag:
collected += "\n**推論開始**\n"
reasoning_flag = True
yield "\n**推論開始**\n"
collected += reasoning_token
yield reasoning_token
if token:
if reasoning_flag:
collected += "\n**推論終了**\n"
reasoning_flag = False
yield "\n**推論終了**\n"
collected += token
yield token # ここが 1 トークンずつ Streamlit に届く
# ストリーム終了後に履歴を追加
st.session_state.messages.append(
{"role": "assistant", "content": collected}
)
st.write_stream(stream_from_vllm)
app.pyなどの名で保存し、
$ streamlit run app.py
で実行すると、localhost:8501にチャット用のサーバが起動します。
こんな感じです。
まとめると、vLLMサーバとStreamlitサーバの二つのサーバを立てて、StreamlitからvLLMサーバに接続しています。
問題を解く
どんな問題を解いてもらうか悩みましたが、今回は2025年の日本数学オリンピックの予選(JMO)問題を解いてもらうことにします。リンク
予選とはいえ、大学受験の数学の問題と比べるとかなり難しい問題が多いです(特に後半は大学受験では全く出ない難易度)。ただ、ELYZA-Thinking-1.0-Qwen-32BはMATH-500を8割方解けるということで、最初の方の問題ならなんとかなるのではないかと思い、やってもらいます。
今回は問2を出題(問1は画像理解が必要そうでskip!)。
をみたす正の整数の組 abcd = 2025 であって, (a,b,c,d) がいずれも平方数であ ab, bc, cd, da
るようなものはいくつあるか.
数学オリンピックの中では簡単な部類の問題とはいえ、数論と場合の数を組み合わせた良問です。出題年度に絡めて2025を使用しているのが小粋ですね。
素因数の指数部分の分配に注目して、場合の数の問題に帰着させるところや、3と5を独立に考えると効率よく解けるなどの部分は単線的に推論できないかもしれません。(ちょっと見た印象だとMATH-500の最高難度とあまり変わらない難易度かも)
超超略解
GPT-4o
さて、OpenAIのGPT-4oです。Reasoningモデルではないですが、汎用的なタスクに優れていて、数学的思考力もそこそこあります。
全出力
画像1
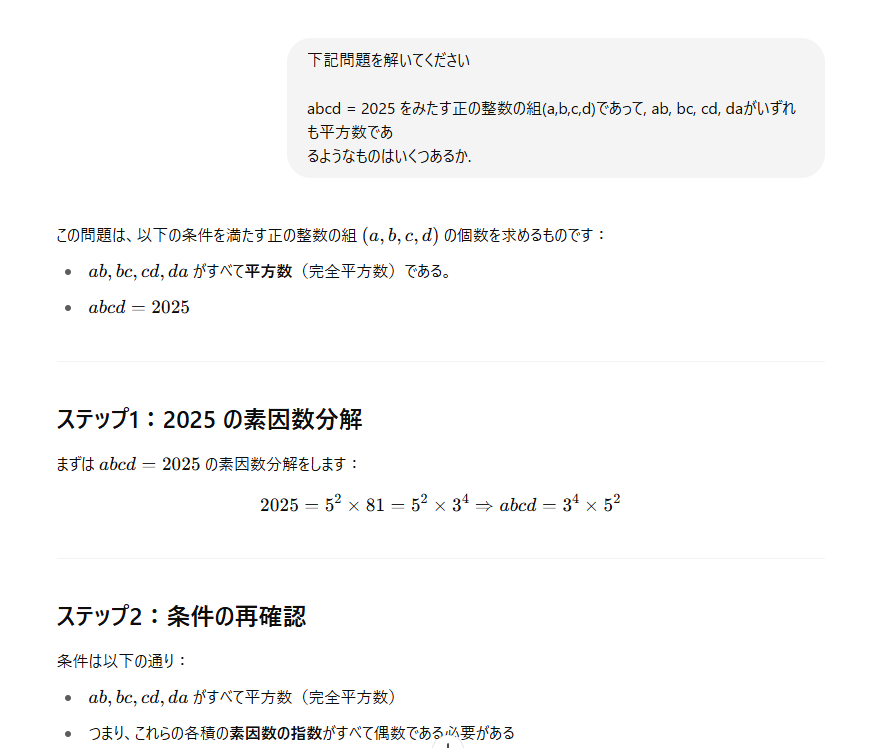
画像2

画像3

画像4

画像5
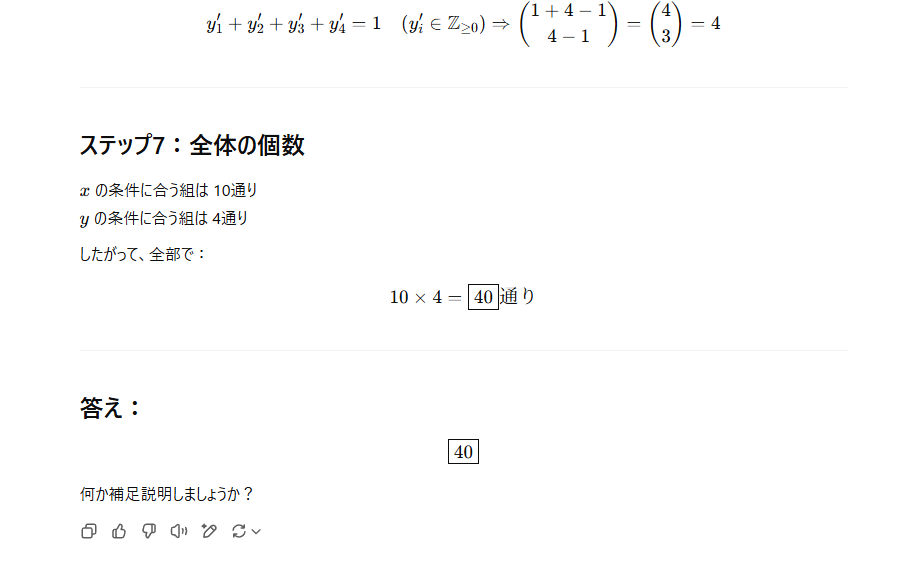
答えの部分の出力です。

本当の答えは44通りなので、見事に撃沈です。かなりいい線行ってますが
ELYZA-Shortcut-1.0-Qwen-7B
手始めに7Bのshortcutモデルで。
全出力


うーん、残念。
しかし、そもそもELYZA-Shortcut-1.0-Qwen-7Bの数学ベンチマークの結果はそこまで芳しくありませんでした。今回の真打はELYZA-Thinking-1.0-Qwen-32Bです。
ELYZA-Thinking-1.0-Qwen-32B
さて、どうなる?
以下が出力です。
全出力
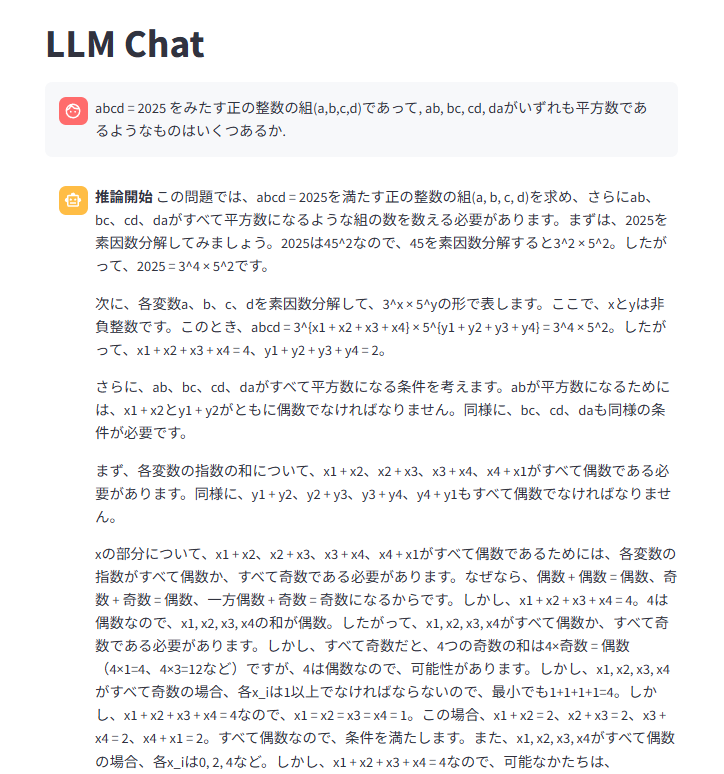




おお!できてる!
・・・のですが、
確信が持てないのかreasoningが収束しません。総当たり検算モード(?)に入ってしまったのでしょうか。
かなりの推論時間がかかったので(ここまでで5時間弱)、打ち切りましたが、多分続けていけば、正解の回答が出力されると思われます。
o3
ちなみにo3でも試してみました。
全出力
画像1

画像2

画像3

画像4

回答部分

さすがの貫禄です。言葉遣いが専門的(正直必要以上に)で、短くまとまっているところがo3らしい。
所感
貴重な日本語reasoningモデルが公開されたことは日本語圏にとって大変有意義なことだと思います。ELYZA-Thinking-1.0-Qwen-32Bは、reasoningが収束しなかったものの、きちんと正答を出せています。日本語的なおかしさ(簡体字が混ざるなど)もありません。
しかし、ローカルで動かしてみて思ったのが、CPU offloadingを使っているせいか、32Bがとてつもなく重い・・・これだけで5時間ぐらいかかりました。量子化モデルを使うか、クラウドでH100のインスタンスでもたてて再チャレンジした方がいいかも?
LLMは推論自体のコストも膨大なので、長い推論パートを省略することを志向したShortcutモデルの試みはとても有意義に感じます。また、ThinkingモデルはMCTSで作り出した推論をMCTSを使わずに模倣できるように学習したわけで、これもある意味"shortcut"といえるのではないでしょうか(MCTSは大変時間がかかります)。
こうしたLLMの効率化は日進月歩で進んでいます。あなたのPCでo3レベルのモデルが動く日もいつかやって来る?
Discussion