Malloy触ってみる
注意:MalloyはExperimentalです
Malloyとは
2021/10にLookerの創業者の人がリリースした「experimental language for describing data relationships and transformations」です。
生のSQLではなく、コンポーネント化が可能な独自のDSLで記述することで、
- 再利用性を上げる
- 理解しやすくする
ことを目指したプロジェクトです。記載したDSLは基本的には(※)VSCodeのプラグインで動かし、SQLの実行・ダッシュボードの表示を行います。
Lookerのコアのコンセプト、データモデリング(LookML)の部分だけを取り出し、OSS・ローカルで動かすようにした製品、というのが個人的な印象です(MalloyのドキュメントにはLookerとの関係を見つけられていないので、不正確かも)。
※ npmのパッケージもあるので、自作すればVSCode以外の利用も可能なはず(それを利用したElectronアプリもあります)
触ってみる
Ubuntu20.04(Windows10 WSL2上)で試しました
インストール
VSCodeをインストールし、VSCodeのプラグインをインストールします。
(以後、.malloyファイルを開くとプラグインが使われます)

ちなみに、ちょっと試すだけの場合はMalloy Fiddleでブラウザで試すこともできます。
準備
MalloyのGitHubリポジトリに
サンプルデータ(FAAデータセット)とMalloyファイルがあるので、それを使ってみます。
ダウンロード
git clone https://github.com/looker-open-source/malloy.git
試しに、VSCodeでmalloy/samples/duckdb/faa/1_airports.malloyを開き、「Preview」(sourceの上)を押してみます。すると、airports.parquetの概要(preview)を確認できるはずです。
(なお、previewの「SQL」を押すと発行したSQLを確認できます)

このディレクトリには、FAAという名前が示唆する通り、アメリカの航空に関するデータ・Malloyファイルが含まれます。
ダッシュボード
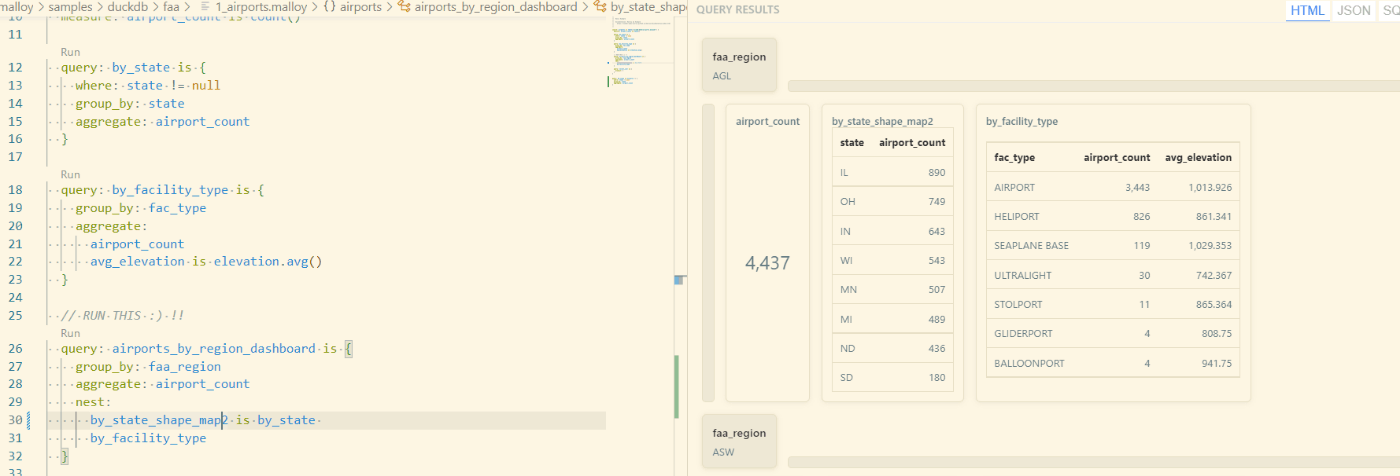
1_airports.malloy「 // RUN THIS :) !!」とあるRun(airports_by_region_dashboardの上)をクリックすると、ダッシュボードが表示されます。

このダッシュボードでは、faa_region(FAAの地域区分?)毎に、
- 空港の数(airport_count。左上の数の部分)
- 州ごとの空港の数(by_state_shape_map。右上の地図の部分)
- 施設の種類ごとの数(by_facility_type。下の表の部分)
が表示されています。
samples/duckdbの下には他の例もあるので、適当に眺めてみてください(imdbサンプルはmakeがっ必要です)。
サンプルで使われている概念
Malloyファイルで使われている概念について、軽く見て行きます。
source
queryが使うデータソースの設定です。元データには、
- テーブル・ビュー(BigQuery、PostgreSQL、DuckDB)
- 別のMalloy
- SQLクエリ
SQLクエリによるソースは、下記のようにSQLクエリを書いて利用します。なお、VSCodeのExploerに表示される「MALLOY CONNECTIONS」で接続するDBを設定する必要があります(デフォルトではBigQueryに接続しようとする?)。
sql: my_sql_query is ||
SELECT
'John' as first_name,
'Smith' as last_name,
1 as gender
;;
source: limited_users is from_sql(my_sql_query) {
measure: user_count is count()
}

query
ソースからの集計・変形処理をqueryに記載します(Lookerでいうところのビュー?)。
1_airports.malloyのようにsourceの中にqueryを記載できますが、4_movie_dashboard.malloyのように、sourceの外に記載することもできます。また、sourceを定義しないで、queryから直接テーブルを見ることも可能です
query: select_star is table('duckdb:data/airports.parquet') -> {
project: *
}
集計・変形処理
query・sourceでは、データに対して以下のような集計・変形処理を記載することができます。
- 集計(sumとか)
- フィルタリング(SQLのWHEREの部分)
- order, limit
- フィールドの操作(追加、削除)
source・queryの再利用
ここまでの機能だけではSQLでよくね?となりますが、Malloyの特徴(「Reusable」)は、定義したsource・queryを再利用できる点にあります。
これにより長大なSQLを小さな単位毎に記載でき、動作確認や理解がしやすくなるというのがMalloyのアピールです(※)。
※HackerNewsだと異論も結構あります
例えば、IMDbのサンプルでは、
と、別のqueryを少しづつ拡張し新たなqueryを作っています。
// (1)元データをソート
query: by_title is {
group_by: primaryTitle, startYear, ratings.numVotes
order_by: 3 desc
}
// (2)by_titleを拡張し、上位20件に
query: top20 is by_title + { limit: 20 }
// (3)top20を拡張し、ホラーだけに
query: top20_horror is top20 + {
where: genres.value = 'Horror'
}
上記はqueryの再利用の例ですが、同様にsourceも再利用することができます。例えば、FAAのサンプルでは、
-
元データ(FAAの飛行記録)のsourceを定義
- カラム名の変更やJOINの設定
- 飛行機毎の集計
を行っています。
テーブルの組み合わせ(JOIN・ネスト)
ダッシュボード
上述の1_airports.malloyの例のように、MalloyのVSCode拡張には(簡易的な)ダッシュボード機能があります。具体的には、テーブルに加え、
を表示できます。
ダッシュボードにどの方法で表示するかは、queryに特定のサフィックス(_segment_map等)を付けるか、設定ファイル(.style.json)に設定を記載して指定します(サンプルでは前者)。
例えば、アメリカの地図が表示されていたby_state_shape_mapを「by_state_shape_map2」に変えると、dashboardの表示が変わります。
1_airports.malloy
Lookerや他のBIですと、インタラクティブにクエリ実行・表示変える機能があると思いますが、Malloyには(たぶん)無いようです。
雑感
- Lookerとの関係
- dbtとの関係(SQLを分割し、再利用・テスト・理解しやすくする意味では似ているかと)
- 用途・ユースケース
- headless BI(cubeとか)・Semantic Layer(dbtとか)との関係
あたりが気になりました。私が使うとしたら、
- 個人利用・小規模でのLookerの代替
- Lookerは個人利用のライセンスは無いと思うので、
- (LookML互換ではないですがノリは似ているかと)
- DuckDBの可視化
- npmパッケージを利用した、カスタマイズしたLooker-likeなプロダクトの作成
とかかなーと思いました(他の用途ご存じの方は教えていてだけると嬉しいです)。
Discussion