レイテンシ重視のOLAP DB、Apache Pinot触ってみた
気にはなってるけど触ってないビッグデータ系のツール・サービスを触る Advent Calendar 2022の#16です。
Apache Pinotとは
公式サイト曰く、
Apache Pinot, a real-time distributed OLAP datastore, purpose-built for low-latency high throughput analytics, perfect for user-facing analytical workloads.
です。
大規模なデータの分析用のデータベースといえばSnowflakeやBigQueryが有名ですが、Apache Pinotは少し違うカテゴリーの製品で、エンドユーザが見るダッシュボードのような、レイテンシが重要な用途に特化した分析用のデータベースです。
似たカテゴリの製品としては、
などがあります。
Podcastの発音や同名のワインの名前的に発音は「ピノ」な気がしています。
事例
ロゴが出ている企業だけでも、
- Uber
- Slack
- セブンイレブン
などの企業があります。特にUberとLinkedInはPinotに力を入れているようで(両社はPinotの開発にも関与しています)、
で事例の説明を行っています。
例えばUberのOperating Apache Pinot @ Uber Scaleでは、下図のような、ユーザ(レストラン経営者)が見るダッシュボードの裏側でPinotが使われており、数10TBのデータを100msのオーダーで処理している話が紹介されています。

(Uberのエンジニアブログより)

(Uberのエンジニアブログより)
制限
大規模データ・低レイテンシを実現する代償として、一般的なDB・DWHに比べ弱い部分もあります。例えば、一般的なDB、DWHが行える以下のクエリには制限があります(Druidも同じような制限があったはず)。
これらの機能制限、また、構成がそれなりに重たいこともあり、汎用的なDWHや社内でのデータ分析のDWHの代替にはならず、Pinotの自己紹介にあるように、「user-facing analytics」に用途を限定した方が良さそうです。
連携
クライアントアクセス用のライブラリについては、
- JDBC
- Java
- Python
- Go
が用意されています。また、
- Tableau(BI)
- Trino・Presto(クエリエンジン)
- Superset(BI)
- ThirdEye(異常検知)
についてはドキュメントが用意されています(JDBCが使えるので、これ以外のツールでも連携できると思いますが)。
マネージドサービス・エンタープライズサービス
StarTreeというPinotの開発者が始めた企業が、エンタープライズ版やマネージドサービスを提供しています。
本番運用するなら検討しても良いかもしれません。
学習リソース
Pinotに関する学習リソースとして、
- 公式ドキュメント
-
Building Real-Time Analytics Systems
- ただし出版予定は2023年
- UdemyのHands on(Apache Pinot : A Hands on Course)
などがあります。
Apache Druidとの比較
Apache Druidとは事例やアーキテクチャ共に、よく似ています。
比較記事ありますが(下)、私は違い・使い分けよく分かっていないので詳しい人教えてくれると嬉しいです。
- https://leventov.medium.com/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7
- https://github.com/apache/pinot/issues/4400
アーキテクチャ・概念

(Pinot公式ページより)
Pinotは主に以下のコンポーネントで構成されています。結構多くのコンポーネントが必要ですね。
- Controller(図のZooKeeper(ZK)とHelix)
- Broker
- Server(Offline, Realtime)
- Segment Store(Deep Storage)
- Ingestion Job
- (この図では省略)Minion
それぞれ簡単に説明すると、
- Brokerはユーザからのクエリを行い、実際にデータを提供します
- Controllerは各種サーバ・Segment(テーブルを分割したもの)の管理・管理API・WebUIの提供を行います
- Serverはデータの提供を行います。RealtimeとOfflineの二種類があります(後述)
- Segment Store、Ingestion Jobは、Segmentの保存とOfflineデータの取り込みを行います
- Minionは非同期で何か作業をします
といった役割分担になっています。
Pinotでも他のDB同様にテーブルの概念がありますが、Pinotではデータの取り込み・テーブル(正確にはテーブルを分割したSegment)が3種類に分けられます。
- Kafkaなどのキューからデータを読む、「Data in Motion」(左下)とそこにつながる「Realtime」
- ファイルシステム・オブジェクトストレージからデータを読む、「Data at Rest」(右下)とそこにつながる「Offline」
- 「Data in Motion」「Data at Rest」の両方を含む「Hybrid」
- テーブルに対応するRealtime ServerとOffline Serverが両方あるテーブル(一つのServerで兼務も可能ですが本番ではおススメしないらしい)
クエリの実行は、RealtimeテーブルでもOfflineテーブルでも同じようにできますが、
-
Ingestion Aggregation(realtimeだけ)
- 取り込み時に集計することで、データ量を削減・クエリ高速化する機能
- 重複の排除(realtimeだけ)
- MinionによるMerge・Rollup(offlineだけ)
といった機能(と性能)の違いがあります。
試してみる
- ローカル
- Docker
- Kubernetes(Helm)
- パブリッククラウド(Azure、AWS、GCP)
でのデプロイ方法と、
- バッチインポート(Offline Segmnet)
- ストリーミングインポート
- (Kuberenetesのみ)BI(Apache Superset)との連携
- (Kuberenetesのみ)Trino・Prestoとの連携
の例が記載されています。今回はDockerを使い
- 各コンポーネントの起動
- テーブルの定義
- Offlineテーブルに、ファイルからデータを取り込み
- standaloneスクリプトを動かします
- Onlineテーブルに、Kafkaからデータを取り込み
を行いました。チュートリアルそのままだと動かない箇所があったため、一部を変更しています。
Ubuntu 20.04 (Windows10のWSL2上)、minikube kubernetes-version v1.23.8で試しました。
各コンポーネントの起動
- Zookeeper
- Controller
- Broker
- Server
のコンポーネントをDockerコンテナを起動します。
起動する前にネットワークの作成と、コンテナイメージの指定をしておきます。
docker network create -d bridge pinot-demo
PINOT_IMAGE="apachepinot/pinot:0.9.3"
各コンポーネントを起動します。
docker run --rm -ti \
--network=pinot-demo \
--name pinot-controller \
-p 9000:9000 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms1G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-controller.log" \
-d ${PINOT_IMAGE} StartController \
-zkAddress pinot-zookeeper:2181
docker run --rm -ti \
--network=pinot-demo \
--name pinot-broker \
-p 8099:8099 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx4G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-broker.log" \
-d ${PINOT_IMAGE} StartBroker \
-zkAddress pinot-zookeeper:2181
docker run --rm -ti \
--network=pinot-demo \
--name pinot-server \
-p 8098:8098 \
-e JAVA_OPTS="-Dplugins.dir=/opt/pinot/plugins -Xms4G -Xmx16G -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -Xloggc:gc-pinot-server.log" \
-d ${PINOT_IMAGE} StartServer \
-zkAddress pinot-zookeeper:2181
localhost:9000をWebブラウザで開くと、PinotのWebUIが表示されるはずです。

Offlineテーブルの定義・データの読み込み
テーブル定義
サンプルのファイルを作成します。
mkdir /tmp/pinot-quick-start/rawdata/
cat > /tmp/pinot-quick-start/rawdata/transcript.csv << EOS
studentID,firstName,lastName,gender,subject,score,timestampInEpoch
200,Lucy,Smith,Female,Maths,3.8,1570863600000
200,Lucy,Smith,Female,English,3.5,1571036400000
201,Bob,King,Male,Maths,3.2,1571900400000
202,Nick,Young,Male,Physics,3.6,1572418800000
EOS
テーブル定義を作成します。Pinotでは一般的にRDBのようにCREATE TABLEではテーブル(多分)作れず、
-
テーブル定義の設定ファイル
- インデックスやセグメントの設定を定義します
-
スキーマ定義の設定ファイル
- テーブルに含まれる各カラムについて、名前・型・カテゴリーを定義します
をJSONで記載し、テーブル作成を行います。
(余談ですがWeb UIからもテーブル作成は可能です)
cat > /tmp/pinot-quick-start/transcript-schema.json << EOS
{
"schemaName": "transcript",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}
EOS
cat > /tmp/pinot-quick-start/transcript-table-offline.json << EOS
{
"tableName": "transcript",
"segmentsConfig" : {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"replication" : "1",
"schemaName" : "transcript"
},
"tableIndexConfig" : {
"invertedIndexColumns" : [],
"loadMode" : "MMAP"
},
"tenants" : {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableType":"OFFLINE",
"metadata": {}
}
EOS
Pinot Controllerでテーブルを登録します。チュートリアルではcontrollerHostはmanual-pinot-controllerですが、Dockerコンテナ起動に合わせてpinot-controllerに変えています。
docker run --rm -ti \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-batch-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-offline.json \
-controllerHost pinot-controller \
-controllerPort 9000 -exec
ファイルの読み込み
PinotでOfflineテーブルにファイルをアップロードするには
- Spark
- Hadoop
- Flink
- Standalone
の方法があります。ここではStandaloneで取り込みます。
(本番では他の三つの方法が推奨らしい)
Standaloneの取り込みを行う設定ファイルを準備します。入力ファイルの場所・フォーマット、取り込み先のテーブルなどを定義してます。
cat > /tmp/pinot-quick-start/docker-job-spec.yml << EOS
executionFrameworkSpec:
name: 'standalone'
segmentGenerationJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentGenerationJobRunner'
segmentTarPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentTarPushJobRunner'
segmentUriPushJobRunnerClassName: 'org.apache.pinot.plugin.ingestion.batch.standalone.SegmentUriPushJobRunner'
jobType: SegmentCreationAndTarPush
inputDirURI: '/tmp/pinot-quick-start/rawdata/'
includeFileNamePattern: 'glob:**/*.csv'
outputDirURI: '/tmp/pinot-quick-start/segments/'
overwriteOutput: true
pinotFSSpecs:
- scheme: file
className: org.apache.pinot.spi.filesystem.LocalPinotFS
recordReaderSpec:
dataFormat: 'csv'
className: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReader'
configClassName: 'org.apache.pinot.plugin.inputformat.csv.CSVRecordReaderConfig'
tableSpec:
tableName: 'transcript'
schemaURI: 'http://pinot-controller:9000/tables/transcript/schema'
tableConfigURI: 'http://pinot-controller:9000/tables/transcript'
pinotClusterSpecs:
- controllerURI: 'http://pinot-controller:9000'
pushJobSpec:
pushParallelism: 2
pushAttempts: 2
pushRetryIntervalMillis: 1000
EOS
なお、チュートリアルの設定ファイルから以下を変更しています(元々の設定ファイルだとエラーになりました)。
- 「manual-pinot-controller」を「pinot-controller」に
- pushJobSpecを追加
処理を実行します。
docker run --rm -ti \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-data-ingestion-job \
apachepinot/pinot:latest LaunchDataIngestionJob \
-jobSpecFile /tmp/pinot-quick-start/docker-job-spec.yml
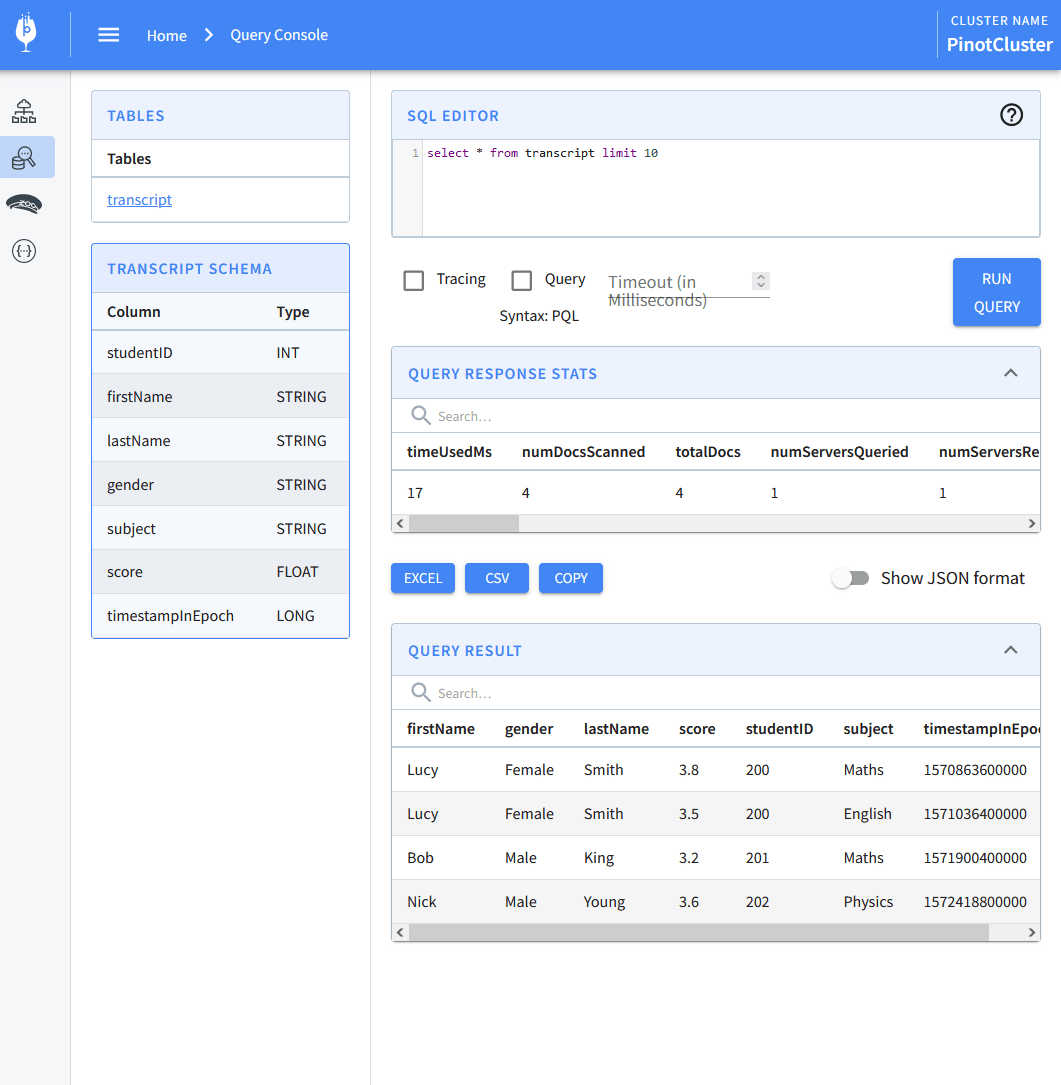
PinotのWebUI(localhost:9000)でテーブルの確認ができます。
Onlineテーブルの定義・データの読み込み
PinotのRealtimeテーブルでは、
- Apache Kafka
- Apache Pulsar
- Amazon Kinesi
に対応しています。DockerでKafkaを動かしてみます。
docker run \
--network pinot-demo --name=kafka \
-e KAFKA_ZOOKEEPER_CONNECT=pinot-zookeeper:2181/kafka \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ADVERTISED_HOST_NAME=kafka \
-e ALLOW_PLAINTEXT_LISTENER=yes\
-d bitnami/kafka:latest
なお、KAFKA_ZOOKEEPER_CONNECTはmanual-pinot-zookeeperから、pinot-zookeeperに変更しています。
Kafkaのトピックを作成します。
docker exec \
-t kafka \
/opt/bitnami/kafka/bin/kafka-topics.sh \
--bootstrap-server localhost:9092 \
--partitions=1 --replication-factor=1 \
--create --topic transcript-topic
なお、
- kafka-topics.shの場所を変更
- zookeeperオプションをbootstrap-serverに変更
しています。
Offlineテーブルと同様にテーブル定義を行います。
cat > /tmp/pinot-quick-start/transcript-schema-realtime.json << EOS
{
"schemaName": "transcript_realtime",
"dimensionFieldSpecs": [
{
"name": "studentID",
"dataType": "INT"
},
{
"name": "firstName",
"dataType": "STRING"
},
{
"name": "lastName",
"dataType": "STRING"
},
{
"name": "gender",
"dataType": "STRING"
},
{
"name": "subject",
"dataType": "STRING"
}
],
"metricFieldSpecs": [
{
"name": "score",
"dataType": "FLOAT"
}
],
"dateTimeFieldSpecs": [{
"name": "timestampInEpoch",
"dataType": "LONG",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}
EOS
cat > /tmp/pinot-quick-start/transcript-table-realtime.json << EOS
{
"tableName": "transcript_realtime",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestampInEpoch",
"timeType": "MILLISECONDS",
"schemaName": "transcript_realtime",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.topic.name": "transcript-topic",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": "kafka:9092",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "50M",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}
EOS
docker run \
--network=pinot-demo \
-v /tmp/pinot-quick-start:/tmp/pinot-quick-start \
--name pinot-streaming-table-creation \
apachepinot/pinot:latest AddTable \
-schemaFile /tmp/pinot-quick-start/transcript-schema-realtime.json \
-tableConfigFile /tmp/pinot-quick-start/transcript-table-realtime.json \
-controllerHost pinot-controller \
-controllerPort 9000 \
-exec
Kafkaにデータを流します。
# Kafkaに流すデータの準備
cat > /tmp/pinot-quick-start/transcript.json <<EOS
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"Maths","score":3.8,"timestampInEpoch":1571900400000}
{"studentID":205,"firstName":"Natalie","lastName":"Jones","gender":"Female","subject":"History","score":3.5,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Maths","score":3.2,"timestampInEpoch":1571900400000}
{"studentID":207,"firstName":"Bob","lastName":"Lewis","gender":"Male","subject":"Chemistry","score":3.6,"timestampInEpoch":1572418800000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Geography","score":3.8,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"English","score":3.5,"timestampInEpoch":1572505200000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Maths","score":3.2,"timestampInEpoch":1572678000000}
{"studentID":209,"firstName":"Jane","lastName":"Doe","gender":"Female","subject":"Physics","score":3.6,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"Maths","score":3.8,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"English","score":3.5,"timestampInEpoch":1572678000000}
{"studentID":211,"firstName":"John","lastName":"Doe","gender":"Male","subject":"History","score":3.2,"timestampInEpoch":1572854400000}
{"studentID":212,"firstName":"Nick","lastName":"Young","gender":"Male","subject":"History","score":3.6,"timestampInEpoch":1572854400000}
EOS
# publish
docker cp /tmp/pinot-quick-start/transcript.json kafka:/tmp/transcript.json
docker exec -t kafka sh -c '/opt/bitnami/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic transcript-topic < /tmp/transcript.json'
PinotのWebUI(localhost:9000)でテーブルの確認ができます。

クライアントアクセス
Pythonでのアクセスを試してみます。
pip install pinotdb
from pinotdb import connect
conn = connect(host='localhost', port=8099, path='/query/sql', scheme='http')
curs.execute('SELECT * FROM transcript')
result = curs.execute('SELECT * FROM transcript')
[x for x in result]
テーブルのデータが取得できていそうです。
[['Lucy', 'Female', 'Smith', 3.8, 200, 'Maths', 1570863600000],
['Lucy', 'Female', 'Smith', 3.5, 200, 'English', 1571036400000],
['Bob', 'Male', 'King', 3.2, 201, 'Maths', 1571900400000],
['Nick', 'Male', 'Young', 3.6, 202, 'Physics', 1572418800000]]
Discussion