□■□■□■headless BIツールCube.js触ってみた□■□■
tl;dr
- headless BIだよ。他のBIやアプリケーションにデータを提供するレイヤーだよ
- 企業が顧客に見せるダッシュボード(embedding analyticsとか、User facing Analyticsと呼ばれる分野)での事例が多いよ
- 事前の集計(pre-aggregation)とか、SQLでのアクセスとか、動作確認用のダッシュボードなど便利な機能があるよ
Headless BIなんぞや
ここの私の理解はふんわりしています。話半分に読んでください
Cube.js自身の主張としては、
- 従来のBIツールは、それが可視化するメトリクスを他のツールに提供しない
- メトリクス定義だけを行うheadless BIにより、可視化レイヤーとメトリクスの定義を分離できる
とし、headless BIは以下の4つのコンポーネントで構成されるとしています。
- Data Modeling
- (メトリクスの定義)
- Access Control
- Caching
- API
- (ダウンストリームのツール(BIとか)がメトリクスを利用できるようにする)
ブログにあるheadless BIの概念図がわかりやすいかもしれません。
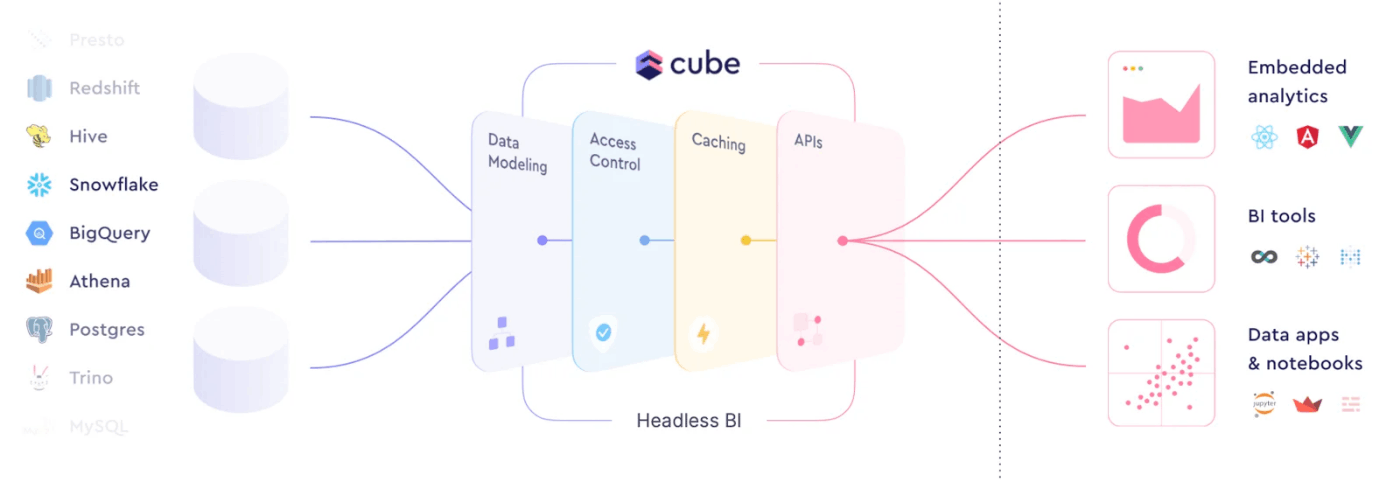
特にData Modelingがheadless BIの主要コンポーネントで
- 一貫した定義
- 一箇所で定義されたメトリクスを使うことで、あるダッシュボードと別のダッシュボードで似た指標の定義が違う事が起きにくい
- 複雑なSQLの隠蔽ができ
- 定義の変更管理などのデータガバナンス
の点で有用だと述べています。
似た概念
- Semantic Layer
- Data Virtualization
- Metrics Layer
- OLAP DB(Apache KylinとかDruid)
がData Modelingの提供する機能と似ていると思います。違いやメリット・デメリットがよくわかってないので、勉強します…
Cube.js概要
Cube.jsは前述のheadless BIの機能を提供するサービスで、クライアント(フロントエンドアプリやBI)とデータベース(DWHやRDB)の間に立って、
- 複数のデータソースへの接続の抽象化
- RDB、DWH、いくつかのNoSQL(MongoDB等)、Trino・Hive等
- LookerのLookML的なモデリング
- 認証認可
- キャッシュ・事前集計
- クライアントへのデータ提供
を提供します。
競合
同じカテゴリー(headless BI・Semantic Layer)では、
あたりが競合でしょうか。
もう少し別のカテゴリーにも比較対象を広げると、
- BI(Tableau、Looker等)
- 複数のデータソースにアクセスする抽象化レイヤーという点で、Data Virtualization(DremioやTrino/Presto)
- キャッシュ・事前の集計の点で、OLAP DB(Apache PinotとかDruid)
などが競合になると思います(事例で比較対象にあげているところが多い)。
ユースケース
Cube.jsのブログ記載のユースケースを見ると、
- 顧客に見せるダッシュボード(embedding analytics・User facing Analyticsと呼ばれる分野)
- Google Analyticsとかのイメージです
- 社内のダッシュボード
のバックンエンドで使っているところが多そうです(事例は前者の方が多い?)。
選んだ理由としては、
- 商用のBI(Looker・Tableau・Qlik)に比べカスタマイズが用意
- キャッシュレイヤー
- Single Source of Truth
- 開発のしやすさ(Developer PlayGround、Reactに簡単に組み込める、バージョン管理等)
を上げている事例が多いです。
また、上記のブログの事例にはないですが、求人票では、Apple、Intel、Walmartも利用しているらしいです。
アーキテクチャ
- リクエストを受け付けるAPI Instance
- クエリー単位のキャッシュ(呼び出したクエリと単純な結果?)と、キューを管理するRedis
- 事前の集計(pre-aggregation)の提供を担当するCube Store
- この図では省略されていますが、おそらくオブジェクトストレージも必要
- 事前の集計(pre-aggregation)の計算を担当するRefresh Worker
の4つのコンポーネントから構成されます。
デプロイ方法としては、
が紹介されています(CloudFunctionsとLambdaの方法も記載ありますが、非推奨らしい)。
機能
機能色々ありますが、重要そうな機能・面白そうな機能を見てみます。
Data Schema
Cube.jsではLookerのLookML的なDSLでデータの定義を行います。
(ちなみに、heavily inspired by LookMLとCube.jsの開発者も明言しています)
- Measure(測りたい指標)
- 「quantitative data, such as number of units sold, number of unique visits, profit」
- Dimension(集計に使う属性)
- 「categorical data, such as state, gender, product name, or units of time 」
- Filter
- 絞り込み。Dimensionの中に記載
を記載し、必要に応じてJOINやキャッシュ(後述のpre-aggregations)の設定を記載します。
継承やファイルの分割、サブクエリなどの仕組みで、大きなSQLを小さいCubeに分割できる点が、(SQLでなく)独自のDSLで記載するメリットだと思います(ここは好みが分かれると思いますが、コンポーネント分割で、再利用が用意になったり、一度に読む範囲が狭くなり理解しやすくなりそうです)。
(チュートリアルに記載されているCubeの例)見ていただくと、
cube(`Users`, {
sql: `SELECT * FROM users`,
measures: {
count: {
sql: `id`,
type: `count`
}
},
dimensions: {
city: {
sql: `city`,
type: `string`
},
signedUp: {
sql: `created_at`,
type: `time`
},
companyName: {
sql: `company_name`,
type: `string`
}
}
});
ユーザのテーブル(users)に対して、
- ユーザ(id)の数を数えたい(measure)
- 集計は都市(city)、登録日時(created_at)、会社名(company_name)で集計したい
を定義できることがわかると思います。
なお、Data Schema(Cube)は単純な設定ファイルではなく、Node.jsで解釈されるJavaScriptファイルで、その性質を利用して
などを行うことも出来ます。前者はCubeの分割による開発・保守の改善、後者はCubeやDimensionがたくさんある時の自動作成(COTAの事例)などに役立ちそうです。
キャッシュ
Cube.jsには二種類のキャッシュ
があります。前者は単純にクエリとその結果、後者はクエリが来る前にdimensionに毎の集計の結果を計算しておくことができます(Apache Druid的な計算?)。特に後者に関しては、Cube.jsを選んだ理由に挙げている事例が多い、目玉機能のようです(社外のユーザが見る用途のアプリなのでレイテンシを気にする場合が多い)。
なお、in-memory cache]はRedis(ただし近々Cube Storeに置き換え)、pre-aggregationはCube Storeという独自コンポーネントで計算・保存します。
ちなみに、Cube Storeは、
- メタデータはRocksDB
- 処理はRust・Apache Arrowで実装されたワーカー
- データの保存はObject Storage(S3, GCS)上のParquet
の組み合わせで実装されているそうです。
(本番構成では)クラスターが推奨なので準備・保守結構大変そうですが、Cube Cloudでは準備してくれるようです(Cube Cloud runs hundreds of Cube Store instances to ingest and query pre-aggregations )。
Developer Playground
Cube.jsはheadless BIで画面提供しないカテゴリーの製品ですが、Developer Playgroundという可視化機能があります。
Webブラウザで
- Data Schema(Cube)の確認・作成
- クエリの実行
- 可視化
- フロントエンドアプリケーションの雛形の作成
などを行うことができます。
Developer Playgroundは、
- 開発モード(CUBEJS_DEV_MODE)でCube.jsを起動する
- (本番利用は推奨しないとのこと)
- Cube Cloudを利用する
の2つの方法で利用できます。
試してみる
Cube Cludについては日本語記事を書いてくださっているので、ローカルで動かすCube.js, the Open Source Dashboard Framework: Ultimate Guideを試してみます。
このチュートリアルでは、
- Docker(-compose)でCube.jsのAPIを起動
- Data Schema(Cube)の定義
- Developer Playgroundで表示
- Cube.jsにアクセスし、可視化するReactのアプリを作成
を行います。
なお、他にもチュートリアルはたくさんあります。
インストール
version: '2.2'
services:
cube:
image: cubejs/cube:latest
ports:
- 4000:4000 # Cube.js API and Developer Playground
- 3000:3000 # Dashboard app, if created
- 5432:5432 # (1)supersetの設定のために追加
environment:
- CUBEJS_DB_TYPE=postgres
- CUBEJS_DB_HOST=demo-db.cube.dev
- CUBEJS_DB_USER=cube
- CUBEJS_DB_PASS=12345
- CUBEJS_DB_NAME=ecom
- CUBEJS_API_SECRET=SECRET
- CUBEJS_DEV_MODE=true
- CUBEJS_PG_SQL_PORT=5432 # (1)supersetの設定のために追加
- CUBEJS_SQL_USER=myusername # (1)supersetの設定のために追加
- CUBEJS_SQL_PASSWORD=mypassword # (1)supersetの設定のために追加
volumes:
- .:/cube/conf
docker compose up
ちなみに、CUBEJS_DB_HOST(Cube.jsが接続するデータベース)はDockerコンテナではなく、Cubeが用意してくれているサーバーです。
# 接続するDBは、ローカルからでも名前解決できるサーバーです
host demo-db.cube.dev
demo-db.cube.dev has address 35.223.24.16
ns-1447.awsdns-52.org has IPv6 address 2600:9000:5305:a700::1
ns-1643.awsdns-13.co.uk has IPv6 address 2600:9000:5306:6b00::1
ns-65.awsdns-08.com has address 205.251.192.65
ns-686.awsdns-21.net has address 205.251.194.174
ns-1447.awsdns-52.org has address 205.251.197.167
ns-1643.awsdns-13.co.uk has address 205.251.198.107
接続
APIが起動するとPostgresqlのクライアントでアクセスすることができます)。
$ psql -h 127.0.0.1 --port 5432 -U myusername --password
Password:
psql (12.11 (Ubuntu 12.11-0ubuntu0.20.04.1), server 14.2 (Cube SQL))
WARNING: psql major version 12, server major version 14.
Some psql features might not work.
Type "help" for help.
myusername=> \dt
List of relations
Schema | Name | Type | Owner
--------+------------------------+-------+------------
public | LineItems | table | myusername
public | LineItemsCountByStates | table | myusername
public | Orders | table | myusername
public | ProductCategories | table | myusername
public | Products | table | myusername
public | Suppliers | table | myusername
public | Users | table | myusername
(8 rows)
myusername=> \q
HTTP APIでも接続できます(試していないですがGraphQLも使えるらしい)。
curl 'http://localhost:4000/cubejs-api/v1/load' -G --data-urlencode 'query={"measures":["Users.count"]}' -H 'authorization: 認証のJWT' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1793 100 1793 0 0 350k 0 --:--:-- --:--:-- --:--:-- 350k
{
"query": {
"measures": [
"Users.count"
],
"timezone": "UTC",
"order": [],
"filters": [],
"dimensions": [],
"timeDimensions": []
},
"data": [
{
"Users.count": "700"
}
],
"lastRefreshTime": "2022-10-17T21:48:04.047Z",
"refreshKeyValues": [
[
{
"refresh_key": "166604327"
}
]
],
"usedPreAggregations": {},
"transformedQuery": {
"sortedDimensions": [],
"sortedTimeDimensions": [],
"timeDimensions": [],
"measures": [
"Users.count"
],
"leafMeasureAdditive": true,
"leafMeasures": [
"Users.count"
],
"measureToLeafMeasures": {
"Users.count": [
{
"measure": "Users.count",
"additive": true,
"type": "count"
}
]
},
"hasNoTimeDimensionsWithoutGranularity": true,
"allFiltersWithinSelectedDimensions": true,
"isAdditive": true,
"granularityHierarchies": {
"year": [
"year",
"quarter",
"month",
"month",
"day",
"hour",
"minute",
"second"
],
"quarter": [
"quarter",
"month",
"day",
"hour",
"minute",
"second"
],
"month": [
"month",
"day",
"hour",
"minute",
"second"
],
"week": [
"week",
"day",
"hour",
"minute",
"second"
],
"day": [
"day",
"hour",
"minute",
"second"
],
"hour": [
"hour",
"minute",
"second"
],
"minute": [
"minute",
"second"
],
"second": [
"second"
]
},
"hasMultipliedMeasures": false,
"hasCumulativeMeasures": false,
"windowGranularity": null,
"filterDimensionsSingleValueEqual": {},
"ownedDimensions": [],
"ownedTimeDimensionsWithRollupGranularity": [],
"ownedTimeDimensionsAsIs": []
},
"requestId": "4523c7da-56d7-428a-a5b6-a7c8a2586c52-span-1",
"annotation": {
"measures": {
"Users.count": {
"title": "Users Count",
"shortTitle": "Count",
"type": "number",
"drillMembers": [
"Users.id",
"Users.city",
"Users.firstName",
"Users.lastName",
"Users.createdAt"
],
"drillMembersGrouped": {
"measures": [],
"dimensions": [
"Users.id",
"Users.city",
"Users.firstName",
"Users.lastName",
"Users.createdAt"
]
}
}
},
"dimensions": {},
"segments": {},
"timeDimensions": {}
},
"dataSource": "default",
"dbType": "postgres",
"extDbType": "cubestore",
"external": false,
"slowQuery": false,
"total": null
}
Developer Playground
Dockerコンテナを起動すると、http://localhost:4000でDeveloper Playgroundを起動できます。
Schemaタブ -> publicをチェック -> Genearate Schemaでデータベースから、Data Schema(Cube)を自動で定義することもできます。
// 自動作成されたSchemaの例
cube(`LineItems`, {
sql: `SELECT * FROM public.line_items`,
preAggregations: {
// Pre-Aggregations definitions go here
// Learn more here: https://cube.dev/docs/caching/pre-aggregations/getting-started
},
joins: {
Products: {
sql: `${CUBE}.product_id = ${Products}.id`,
relationship: `belongsTo`
},
Orders: {
sql: `${CUBE}.order_id = ${Orders}.id`,
relationship: `belongsTo`
}
},
measures: {
count: {
type: `count`,
drillMembers: [id, createdAt]
},
quantity: {
sql: `quantity`,
type: `sum`
},
price: {
sql: `price`,
type: `sum`
}
},
dimensions: {
id: {
sql: `id`,
type: `number`,
primaryKey: true
},
createdAt: {
sql: `created_at`,
type: `time`
}
},
dataSource: `default`
});
Buildタブでグラフにすることもできます。

なお、Developer Playgroundには フロントエンドアプリケーションの雛形の作成する機能があるようですが、私の環境では失敗しました(これと同じバグ?)。
フロントエンドアプリ
Reactを使ったダッシュボードの例(可視化はRecharts)もあります。

Apache Supersetとの連携
Cube.js自身は(基本的には)可視化を担当しないため、(headlessでない)BIと組み合わせることも想定されています。
いくつか(Tableau等)例がありますが、OSSのBIのApache Supersetを試してみます。
Cube.jsにはPostgreSQL互換のインターフェイスがあるため、設定は簡単で、
- Cube.js(のAPIサーバー)をSupersetからアクセスできるようにする
- Supersetのセットアップ
- 今回はDockerを使用
- SupersetからCube.jsへの接続を(PostgreSQLとして)設定
するだけです。
(BI側からはCube.js独自の機能は使っていないので、Superset以外も同様にできると思います)
Cube.jsをSupersetからアクセスできるようにする
先程のチュートリアルで起動しているので省略します。
Supersetの準備
README通りにSupersetを準備します。
docker run -d -p 8080:8088 --name superset apache/superset
docker exec -it superset superset fab create-admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--username admin \
--password admin
docker exec -it superset superset db upgrade
docker exec -it superset superset init
SupersetからCube.jsへの接続を(PostgreSQLとして)設定
ローカルのブラウザからlocalhost:8080でSupersetの画面が開けます

右上のSetting->Database Connection -> +Database ->PostgreSQLを選び、Cube.jsのAPIサーバーへの設定を追加します。
(172.17.0.1)はSupersetから見たホストのIPアドレス(仮想ネットワークのGatewayのIPアドレス)。この指定方法は邪道な気もするので、気になる人はDocker composeとかでネットワークの設定してください。

Datasets -> +Datasetで先ほど設定したDatabase Connectionを選びDatasetを作ります。

Chartを選ぶ画面が表示されますので、適当なチャート(ここでは「Time-series Line Chart」)を選び

表示されたグラフ画面で、MetricsをCount(*)にしてCreate Chartにすると画面が表示されます。

Discussion