Amazon Rekognition を使ってみる
Amazon Rekognition を使ってみる
Amazon Rekognition は、事前トレーニングされたカスタマイズ可能なコンピュータビジョン (CV) 機能を提供して、画像と動画から情報とインサイトを抽出します。
from. Amazon Rekognition
今回は Amazon Rekognition をざっくりと使って、知見を広めておこうと思います。そのため、ここではそこまで深掘りして言及しません。あくまで、「こんなサービスなんだね〜」「こんな使い方できそうだね〜」を浅く理解することを目標にします。
概要
事前に学習されたモデルを使って、画像と動画に対して簡単に各種のタスクを実行することができるサービスです。現在(2023年11月)サポートされているタスクは下記になります。
- Face Liveness
- 顔比較と検索
- 顔検出と分析
- コンテンツのモデレーション
- カスタムラベル
- テキスト検出
- ラベル
- 動画セグメント検出
- 有名人の認識
今、会社で活用シーンがありそうな部分として「動画セグメント検出」があるので、そこを目標に進めていこうと思います。
この記事では、簡単にカスタムラベルの検出を画像に対して適応したり、動画セグメントの検出を行ったりして API の動作を確認します。その後、セグメント検出のソリューションデモをデプロイして色々な動画に対して結果を確認し利用シーンを想定してみました。
試しに、適当な画像で DetectLabels
準備
Document に従って、aws cli を使える様にして S3 に対象の画像を用意
aws rekognition detect-labels \
--image '{"S3Object":{"Bucket":<your bucket name>,"Name":<target image file name>}}'
これだけで、解析結果が JSON で返ってきます。
{
"Labels": [
{
"Name": "Clothing",
"Confidence": 98.87437438964844,
"Instances": [],
"Parents": []
},
{
"Name": "Footwear",
"Confidence": 98.87437438964844,
"Instances": [],
"Parents": [
{
"Name": "Clothing"
}
]
},
{
"Name": "Sandal",
"Confidence": 98.87437438964844,
"Instances": [
{
"BoundingBox": {
"Width": 0.026499267667531967,
"Height": 0.07430583983659744,
"Left": 0.5979822278022766,
"Top": 0.7266873121261597
},
"Confidence": 98.87437438964844
}
],
"Parents": [
{
"Name": "Clothing"
},
{
"Name": "Footwear"
}
]
},
{
"Name": "Adult",
"Confidence": 98.44705200195312,
"Instances": [
「何が」「どれくらいの確度で」「どこに」位はここから取れますね。
めちゃ簡単。。。
動画セグメントの検出をしてみる
SDK と CLI どちらからもリクエストを投げられる。
ただし、画像と違って、解析に時間がかかることを想定してるので、SNS などによる処理結果通知の実装を推奨している。が、問い合わせに行けば答えてくれる模様。。。
とりあえず CLI で
▷ ラベルの検出
# job request
aws rekognition start-label-detection --video "S3Object={"Bucket":<your bucket name>,"Name":<target video file name>}" \
--region ap-northeast-1
# result request
aws rekognition get-label-detection --job-id <"JobId" from job request> \
--region ap-northeast-1
{
"JobStatus": "SUCCEEDED",
"VideoMetadata": {
"Codec": "h264",
"DurationMillis": 43176,
"Format": "QuickTime / MOV",
"FrameRate": 29.970029830932617,
"FrameHeight": 720,
"FrameWidth": 1280,
"ColorRange": "LIMITED"
},
"NextToken": "B+8QDqEsW55pUB1AbAppLjjJTWkpiUrCFR1O7aSTK6wldI+PhKbBssc3gLcn7xuAKP9j/yDiJ4Dy",
"Labels": [
{
"Timestamp": 0,
"Label": {
"Name": "Aerial View",
"Confidence": 55.361351013183594,
"Instances": [],
"Parents": [
{
"Name": "Outdoors"
}
]
}
},
{
"Timestamp": 0,
"Label": {
"Name": "Beach",
"Confidence": 51.79434585571289,
動画のメタデータに続いて検出した label と確度の情報がズラズラ〜と続きます。
▷ セグメント検出
# job request
aws rekognition start-segment-detection --video "S3Object={"Bucket":<your bucket name>,"Name":<target video file name>}" \
--segment-types "TECHNICAL_CUE" "SHOT"\
--region ap-northeast-1
# result request
aws rekognition get-segment-detection --job-id <"JobId" from job request> \
--region ap-northeast-1
{
"JobStatus": "SUCCEEDED",
"VideoMetadata": [
{
"Codec": "h264",
"DurationMillis": 43176,
"Format": "QuickTime / MOV",
"FrameRate": 29.970029830932617,
"FrameHeight": 720,
"FrameWidth": 1280,
"ColorRange": "LIMITED"
}
],
"AudioMetadata": [
{
"Codec": "aac",
"DurationMillis": 43194,
"SampleRate": 48000,
"NumberOfChannels": 2
}
],
"Segments": [
{
"Type": "TECHNICAL_CUE",
"StartTimestampMillis": 0,
"EndTimestampMillis": 43143,
"DurationMillis": 43143,
"StartTimecodeSMPTE": "00:00:00;00",
"EndTimecodeSMPTE": "00:00:43;03",
"DurationSMPTE": "00:00:43;03",
"TechnicalCueSegment": {
"Type": "Content",
"Confidence": 100.0
},
"StartFrameNumber": 0,
"EndFrameNumber": 1293,
"DurationFrames": 1293
},
{
"Type": "SHOT",
"StartTimestampMillis": 0,
"EndTimestampMillis": 20954,
"DurationMillis": 20954,
"StartTimecodeSMPTE": "00:00:00;00",
こちらは、動画と音声のメタデータに続いて、同定したセグメント情報が記載されています。
どちらも、画像のラベル検出と同様に簡単に情報を引っ張って来れます。
Amazon Rekognition Shot Detection Demo
最後に aws が提供してるソリューションテンプレートからデプロイして、プロダクトでの利用シーンをイメージしてみました。
今回は上記 Github のプロジェクトから AWS CloudFormation Template からのデプロイを実行して、動作検証を行いました。
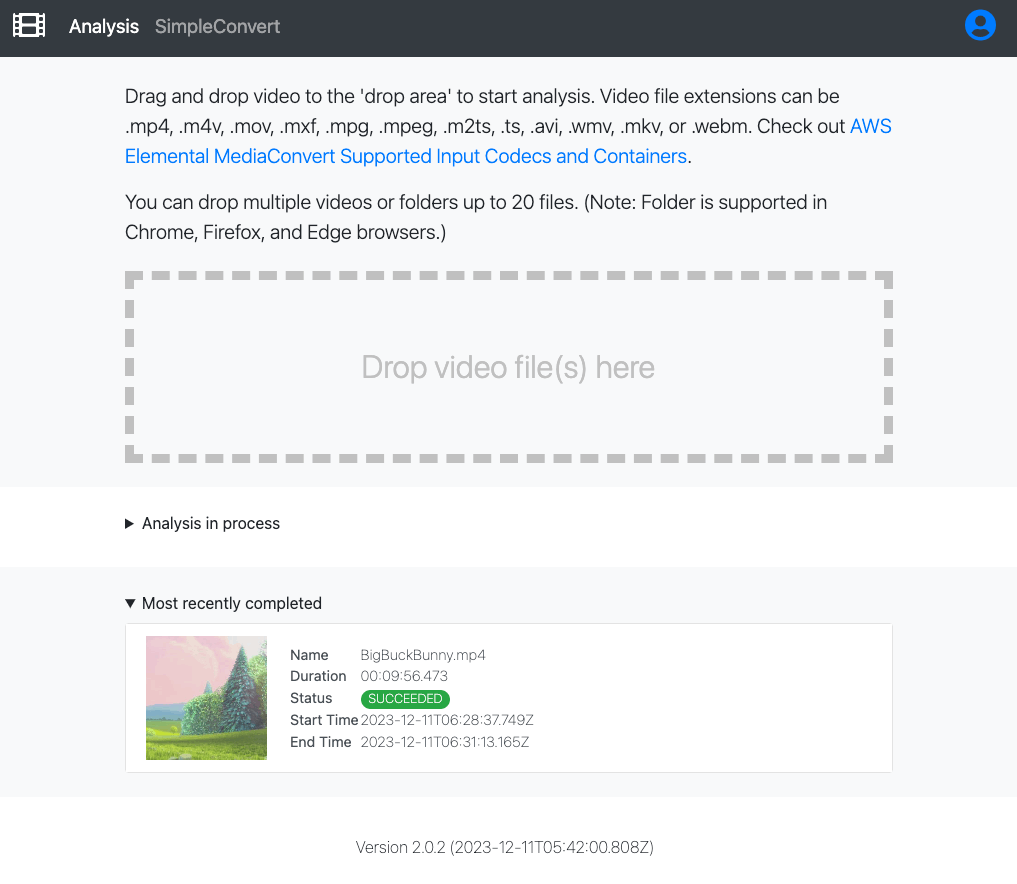
デプロイが完了すると、途中で聞かれた Cognito の mail アドレスに temporary password が送られてきて、パスワードの登録を求められます。パスワードを設定後ログインすると、上のようなポータルに入ります。解析したい動画ファイルをページ上に Drop してアップロードすれば、勝手に解析を始めてくれます。解析完了後の動画を選択して解析の詳細ページに遷移します。
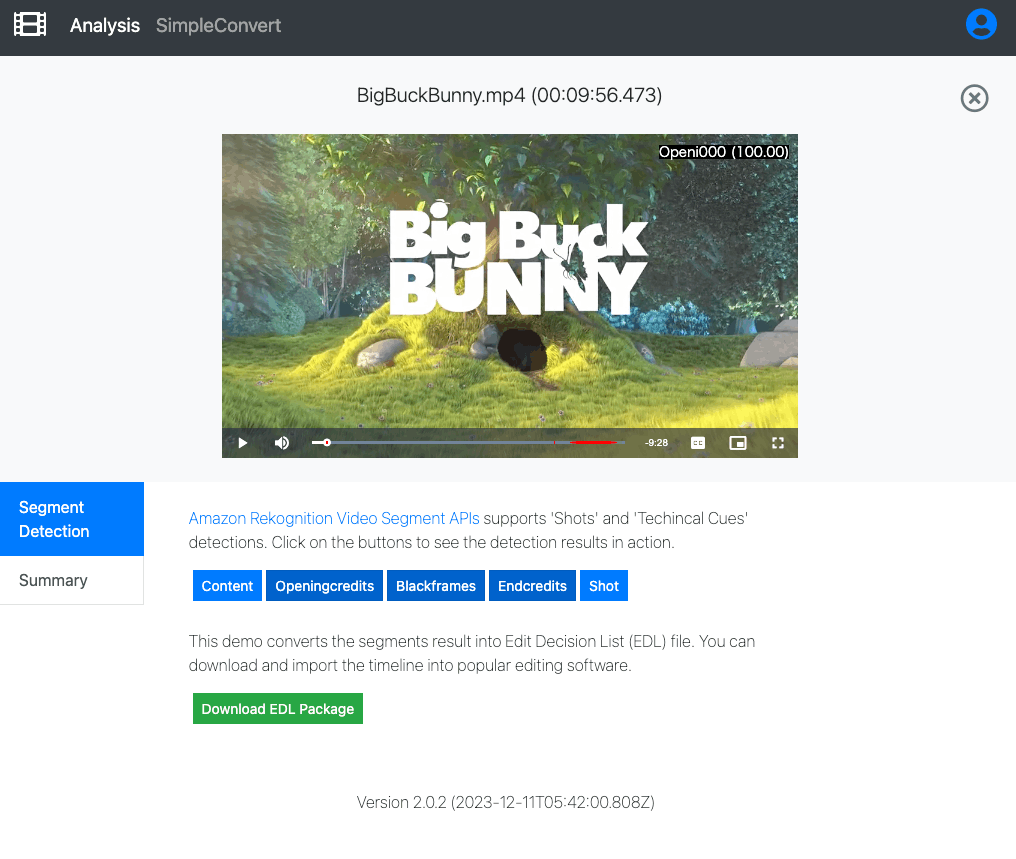
解析動画 : Big Buck Bunney https://peach.blender.org/download/
解析した Segment の結果をシークバー上と画像右上に表示して確かめる事ができます。また、各 Segment の結果を EDL file としてダウンロードすることもできます。
いくつか動画を確認
試しにいくつかの動画を解析してみて〜、の感想を述べて締めようと思います。
ショットの判定精度はかなり良い程度だと感じました。ただし、暗転や明度の足りない環境下での動画進行途中でショット検知をしてしまうケースが見受けられました。今回試した動画の中には、ホワイトアウトするようなシーンを含んでいなかったですが、明るい場面でも同様の事が想定されます。
オープニング/エンディングに関しては、そこまで検証出来ていません。オープニング/エンディングがついた動画をたくさん用意できなかったことも要因です。先の画像で使用した Big Buck Bunney に関して言えば、精度良く抽出出来ていました。
同様に Black Frame や Content の抽出に対しても、検証用の動画を準備できなかったので、評価できません。今後の利用目的次第で、再度検証したい項目ですね。
結局試してみて、このまま直ぐには何もならなそうでした。EDL file が出力できるので、動画編集の補助にはなる印象です。そのため、実際の動画編集と同じだと思いますが、要素分解した後「どう料理するか」を作る必要があります。
今回は、勉強的にな位置付けなのでこの辺で終わりにしたいと思います。
ありがとうございました〜。
余談 : 少し中を覗いてみる
rekognition/APIReference
解析に対してパラメータをいじって良い感じにアレンジ出来るか調べたかったけど、触れる要素少なすぎん!?基本閾値だけですか。。。この辺、もう少し良い感じにできると〜、な感はありますね。
Discussion