Apple Vision Pro座談会のチャプター生成を支える技術
こんにちは、noppeです。
突然ですが私、VTuberというものをやっております。
それがこちら
VTuberなのか?
このApple Vision Pro座談会、Spartial Personaを使ったポッドキャストなのですが、大体週一くらいで投稿しています。
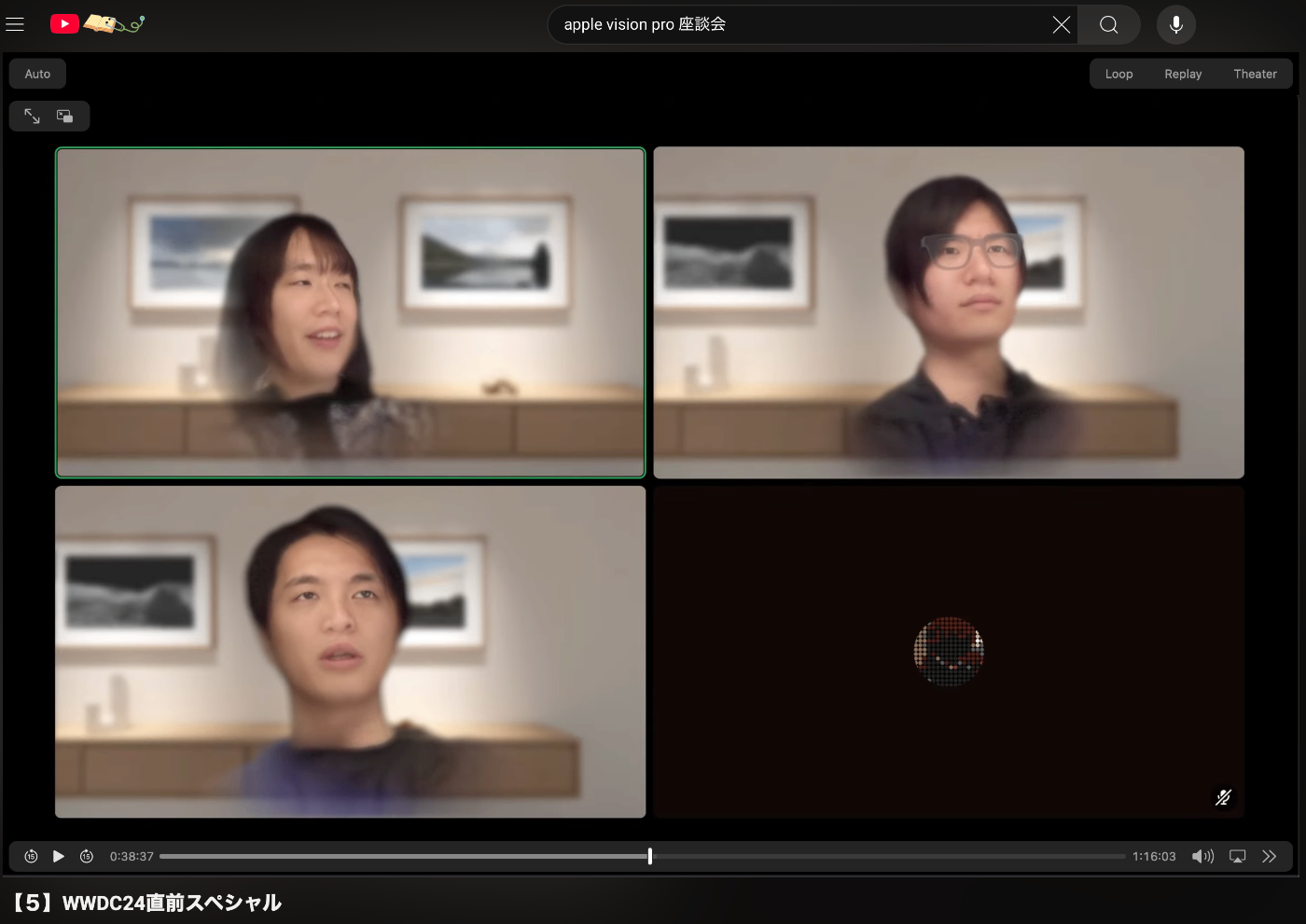
で、この収録の後、概要欄にチャプターを入力します。こういうやつ↓
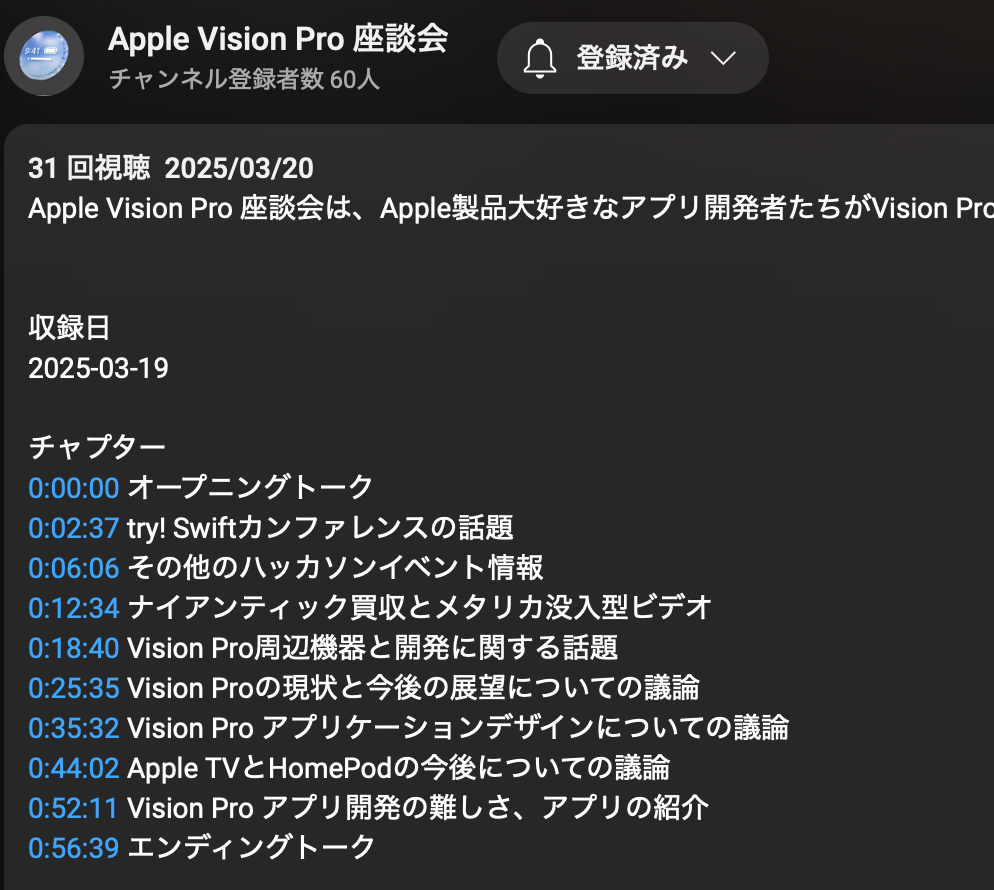
これがま〜〜〜〜〜大変な訳です。
大体1時間くらいの動画なので、知ってる内容を見返しながらポチポチすると。
このチャンネルも、別に誰に言われてやっているわけでは無いので面倒になったらナァナァになって自然消滅だってするかもしれません。
なので、こういう面倒な作業は自動化したいわけです。
自動チャプター生成をやる
結論から言うと、Whisperで文字起こしして、Geminiに食わせる。以上です。
いきなり動画からチャプターが吐ければ良いのですが、現状は別作業になっています。お金もないしね。
文字起こし
mlx_whisperを使っています。
import mlx_whisper
import sys
import datetime
# コマンドライン引数からファイル名を取得(指定がなければデフォルト値を使用)
audio_file = sys.argv[1] if len(sys.argv) > 1 else "output_audio.mp3"
# 完全な結果オブジェクトを取得(["text"]で取り出さない)
result = mlx_whisper.transcribe(
audio_file,
path_or_hf_repo="mlx-community/whisper-large-v3-mlx",
word_timestamps=True,
language="ja",
)
# 発話セグメントごとにタイムスタンプと一緒に表示
for segment in result["segments"]:
start_time = segment["start"]
text = segment["text"]
# 秒を時:分:秒形式に変換
time_str = str(datetime.timedelta(seconds=int(start_time)))
print(f"[{time_str}] {text}")
こんな感じのスクリプトで、次のようなファイルが出来上がります。
[0:51:38] 台の円柱みたいなの出ても結構するんだろうな
[0:51:41] 確かに
[0:51:43] 場所を取るものは置けないので
[0:51:47] その趣味では
[0:51:48] 趣味であるけど
[0:51:51] VisionOSのデベロッパーにリソースを寄せた方が
[0:51:55] VisionOSの成功確立としては
[0:51:57] 高まりそうな気はするんで
大体10倍速くらいで処理できます。1時間のファイルを処理するのに6分くらいかかる。
でもMacbookProで実行しているので無料です。
上手く文章になってないものもありますが、関係ないです。雰囲気が掴めていれば次のステップでチャプターになります。
チャプター生成
文字起こししたファイルは70~90KB程度になります。
これを最初はChatGPTに読ませていたのですが、ファイルが大きいと中盤あたりのチャプター生成までで止まってしまいました。

そこで、コンテキストサイズが大きいGemini 2.0 Flashで実行してみたところ次のように綺麗なチャプターが生成されました。これも無料。
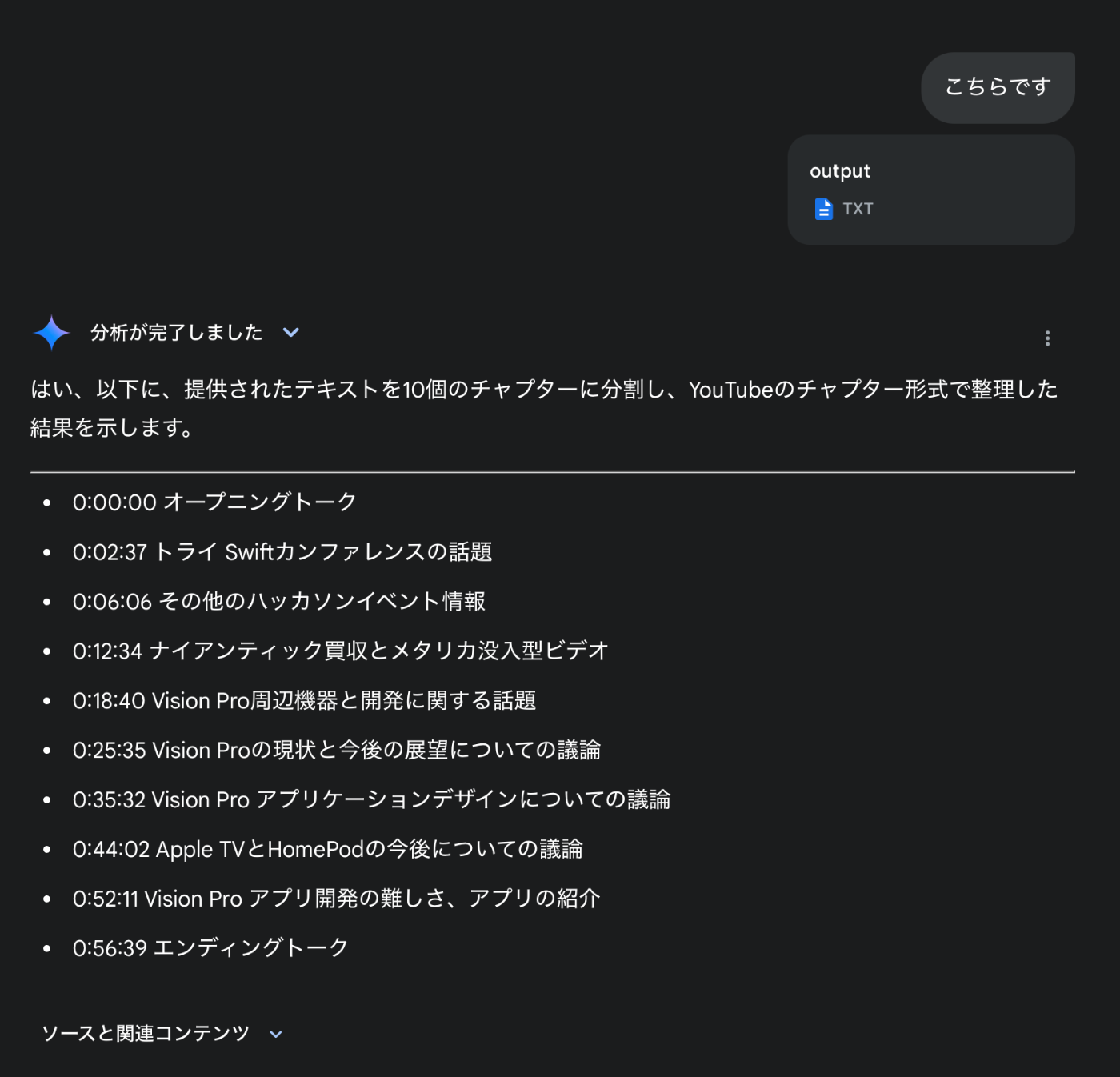
使っているプロンプトは次のような感じ
以下のテキストはPodcastの書き起こしです。視聴者がアクセスしやすいように、全体をおよそ10個のチャプターに細かく分割し、YouTubeのチャプター形式(「分:秒 チャプタータイトル」)で整理して書き出してください。特に話題や内容が変わる部分を意識して、視聴者が興味のあるポイントに簡単にアクセスできるようにしてください。
特に後半部分も含めて全体を均等に細かく分割するように意識してください
めでたし
と言うわけで、Youtube動画のチャプター生成が無事自動化されました。
よかった〜
Discussion