はじめに
こんにちは! no plan inc. にてエンジニアやってます @somasekiです。
今回は、Chain Indexer Frameworkの概要とその使い方についてご紹介します。
Chain-Indexer-Frameworkとは
Polygon Labsが開発した、イベント駆動型のデータパイプラインを構築する際に便利なオープンソースのフレームワークです。
特徴
-
イベント駆動型アーキテクチャ
- EVM互換ブロックチェーン上でデプロイされたスマートコントラクトからの特定のイベントをリアルタイムで監視し、それに基づいたアクションをトリガーすることができます。
-
カスタマイズ性と拡張性
- 高いカスタマイズ性を提供し、開発者が特定のニーズに合わせてデータパイプラインを柔軟に構築できます。
-
モジュラー設計
- 独立したコンポーネントによるモジュラー設計を採用し、システムの各部分を独立して開発、テスト、デプロイすることができます。
-
リアルタイムデータクエリとdApps統合
- データをリアルタイムでクエリし、分散型アプリケーション(dApps)とのシームレスな統合をサポートします。
-
パフォーマンスとスケーラビリティ
- 大量のデータとクエリに対応し、データパイプラインのパフォーマンスとスケーラビリティを確保します。
使用技術
-
Kafka (分散ストリーミングプラットフォーム)
- Pub/Subモデルに基づきストリームデータを扱うプラットフォーム
-
MonngoDB (DB)
- ドキュメント指向データベース
言語
- Typescript
- ProtocolBuffers(一部)
アーキテクチャ
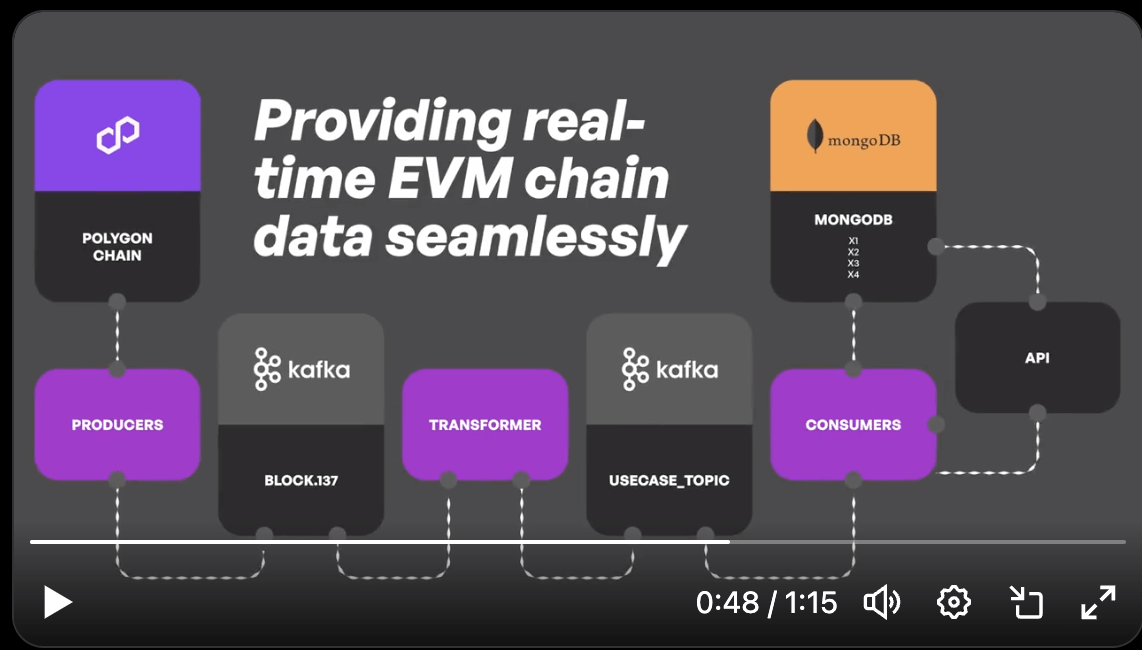
x.comより
Producers
Producerは、ブロックチェーンから生データを取得し、Kafkaのトピックに保存する役割を担います。比較的シンプルに実装されることが多いです。
Chain Indexer Frameworkでは、ブロックチェーンのデータ取得方法に特化した以下の種類のプロデューサーを提供しています。
これらはブロックチェーンのデータ取得方法に違いがあります。
Block Producers
BlockPollingProducer
- ブロックチェーンから新しいブロックを定期的にポーリングする方法で動作します。
- WebSocketノードが利用できないブロックチェーンネットワークに適しています。
ErigonBlockProducer
- WebSocketプロバイダを通じてブロックをサブスクライブし、Erigonノードを利用してデータを生成します。
- Erigonノードの特徴は、各トランザクションのレシートを個別に取得する必要がなく、2回の呼び出しでブロックの詳細を効率的に取得できることです。
QuickNodeBlockProducer
- QuickNode RPCを利用して動作し、qn_getBlockWithReceiptsメソッドを利用してブロックの詳細とトランザクション情報を一度に取得できます。
ここから先は、Kafkaへのデータのパブリッシュ方法に違いがあります。
Synchronous Producer
- 各メッセージがKafkaに正常に書き込まれるまで待機します。
- この方法はデータの整合性を最優先しますが、メッセージを送信するたびにレイテンシーが発生します。
ASynchronous Producer
- メッセージをバッファに追加し、バックグラウンドで非同期的にKafkaに送信します。
- この方法は高いスループットを提供しますが、データ損失のリスクが若干高くなります。
Transformers
Transformersは、ProducersとConsumersの間に立つ重要な役割であり、Producersがpublishしたブロックチェーンの生データの消費、ドメイン固有の形式への変換、そして変換されたデータはConsumersが扱うKafkaトピックへとpublishされます。
Consumers
最終層のConsumersは、Kafkaトピックからデータを消費し、それをデータベースに保存する役割を担います。
2つの主要なクラスを利用してデータを処理します。
Synchronous Consumer
データの整合性を保ち、データ損失を避けることが最優先事項である場合に選択されます。
信頼性を重視するため処理速度は遅くなりますが、より信頼性の高い消費プロセスを提供します。
Asynchronous Consumer
速度を優先し、データ損失が発生しても許容されるシナリオ向けに設計されています。
イベントを非ブロッキング方式で消費し、高速な処理と高いスループットを可能にしますが、データ損失のリスクが高まります。
使い方
実際にexamplesを動かしてみたり、簡単なインデクサーを作成したのでその方法について書いていきます。(Mac(M2)環境)
公式のexamplesを動かしてみる
今回は公式のgithubにある2つのexampleのうち、nft_balancerという、ERC721コントラクトのTransferイベントを取得する方を使ってみました。
この動画の通りにやりました。
事前にコントラクトをデプロイしておく
- remixで作成しました。
- deployして、コントラクトアドレスを控えておきましょう。
- verifyもしてた方が後々スムーズです。
- Transferイベントが実行されるメソッドを実行しておく
- このときのブロックナンバーを控えておきましょう。後にデータ取得を開始するブロックを指定する必要が出てきます。
NFTのコントラクト
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.20;
import "@openzeppelin/contracts/token/ERC721/ERC721.sol";
import "@openzeppelin/contracts/access/Ownable.sol";
contract DummyNFT is ERC721, Ownable {
constructor(address initialOwner)
ERC721("DummyNFT", "DFT")
Ownable()
{}
function safeMint(address to, uint256 tokenId) public onlyOwner {
_safeMint(to, tokenId);
}
}
MongoDB,kafkaを用意する
- MongoDB
brewでインストールしました
brew update
brew tap mongodb/brew
brew install mongodb-community@4.4
brew services start mongodb/brew/mongodb-community
- kafka
- dokcer-compose.yml は用意されてる
- ローカルで立ち上げることも可能
- docker compose up する
環境変数の設定
producer, transformer, consumer各ディレクトリ内に.env.exampleがあるのでそれをベースに設定します。
- .envの作成
- producer
- HTTP_PROVIDER: RPCエンドポイント、今回はAlchemyで作成したエンドポイント
- START_BLOCK: デプロイ成功したときorNFTをTransferしたときのtxのブロックナンバー
- transformer
- NFT_CONTRACT: デプロイしたコントラクトのアドレス
- consumer
- .env.exampleのまま
- producer
インデクサーの実行
実際に立ち上げてみます。(再度MongoDBとdokcerコンテナが立ち上がっていることを確認)
producer, transformer, consumer各ディレクトリで以下のコマンドを実行します。
npm i
僕の環境ではエラー起こった。
npm iのとこでエラー起こった。
- node-rdkafkaのインストールでエラー起こっているよう
- https://stackoverflow.com/questions/64140006/npm-install-node-rdkafka-fails-with-node-gyp-rebuild-error
- M1,M2チップでnode-gypのインストールするときによく起こるエラーぽかったですが、nodeのバージョンをv18.18.0->18.19.0に上げたら解消しました。
npm run build && npm run start
立ち上げに成功するとそれぞれ以下のようなログが表示されると思います。
producer
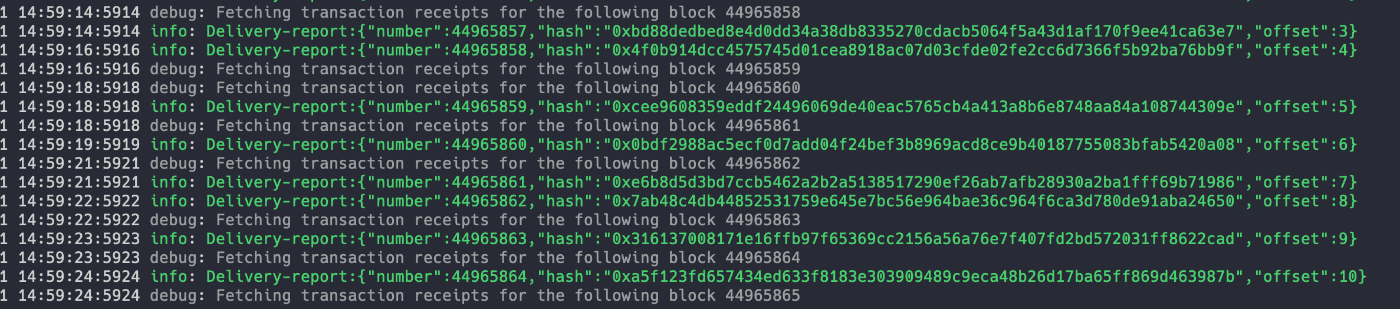
transformer

consumer

コントラクトのメソッドを実行してみる
今回のexamplesのnft_balancerでは、ERC721のTransferイベントを取得するので、最初にデプロイしたコントラクトからMintメソッドやTransferメソッドを実行してみます。(Remixだとそのまま実行できる)
- そのtxが含まれたブロックをインデクサーが読み込むと、MongoDB側に反映されてるはず
producerが正常に動いていると、producedblocksというテーブルのnumberとhashが数秒ごとに変わっていきます。 (MongoDB Compassというアプリ使用)

tokenId 33333というトークンをミントしました。

transferした後、そのtxのブロックが取り込まれるとownerが変わっていることが確認できました。

これでインデクサーが正常に動いてることがわかりました。
ERC20トークンのインデクサーを作ってみる
なんとなく正常な動きがわかってきたので実際に書いてみたいと思います。
ERC20のApprovalイベントのみを取得するようなインデクサーを作ります。
早くコード全て見たい方はこちら
前提
- 先述しましたが、MongoDBは起動されてるものとして進めていきます。
- 基本的には、ディレクトリやファイル構成は、examplesのコードをコピーしそれを編集していきます。
コントラクト書いておく
一般的なERC20のコントラクトです。
remixで作りました。
作った後、デプロイ & approveメソッドの実行をしておきます。コントラクトアドレスとブロックナンバーを控えておきます。
erc20コントラクト TestToken.sol
// SPDX-License-Identifier: MIT
pragma solidity ^0.8.20;
import "@openzeppelin/contracts@5.0.0/token/ERC20/ERC20.sol";
import "@openzeppelin/contracts@5.0.0/access/Ownable.sol";
contract TestToken is ERC20, Ownable {
constructor(address initialOwner)
ERC20("TestToken", "TTK")
Ownable(initialOwner)
{}
function mint(address to, uint256 amount) public onlyOwner {
_mint(to, amount);
}
}
kafka-uiの追加
docker-compose.ymlに、kafka 内の処理やデータが見れるkafka-uiコンテナを追加しました。
docker-compose.yml
---
version: "3"
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.0.0
hostname: zookeeper
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.0.0
container_name: broker
ports:
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
kafka-ui: # <-----新しく追加
container_name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- 3000:8080
depends_on:
- broker
restart: always
environment:
KAFKA_CLUSTERS_0_NAME: nft-indexer
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: broker:29092
Producer
producerのコードはexamplesのコードと同じです。BlockPollingProducer を利用します。
.env書く
.env
HTTP_PROVIDER=https://polygon-mumbai.g.alchemy.com/v2/XXXXXXXX #XXXXXXXXはAlchemyのAPIキー
START_BLOCK=45135681 # 取得したいブロックの開始番号
BLOCK_POLLING_TIMEOUT=20000 # ポーリング間隔
KAFKA_CONNECTION_URL=localhost:9092 # kafkaのローカルホスト
MONGO_URL=mongodb://localhost:27017/erc20-indexer # MongoDBのローカルホストとDB名
PRODUCER_TOPIC=mumbai.80001.blocks # 特に命名に決まりはないが、他のトピックと被らないようにする
#LOGGER_ENV
SENTRY_DSN=
SENTRY_ENVIRONMENT=
DATADOG_API_KEY=
DATADOG_APP_KEY=
src/index.ts書く
src/index.ts
import { produce } from "@maticnetwork/chain-indexer-framework/kafka/producer/produce";
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import dotenv from 'dotenv';
import { BlockPollerProducer } from "@maticnetwork/chain-indexer-framework/block_producers/block_polling_producer";
dotenv.config();
Logger.create({
sentry: {
dsn: process.env.SENTRY_DSN,
level: 'error'
},
datadog: {
api_key: process.env.DATADOG_API_KEY,
service_name: process.env.DATADOG_APP_KEY
},
console: {
level: "debug"
}
});
const producer = produce<BlockPollerProducer>({
startBlock: parseInt(process.env.START_BLOCK as string),
rpcWsEndpoints: process.env.HTTP_PROVIDER ? [process.env.HTTP_PROVIDER] : undefined,
blockPollingTimeout: parseInt(process.env.BLOCK_POLLING_TIMEOUT as string),
topic: process.env.PRODUCER_TOPIC || "polygon.1442.blocks",
maxReOrgDepth: 0,
maxRetries: 5,
mongoUrl: process.env.MONGO_URL || 'mongodb://localhost:27017/chain-indexer',
// blockSubscriptionTimeout: 120000,
"bootstrap.servers": process.env.KAFKA_CONNECTION_URL || "localhost:9092",
"security.protocol": "plaintext",
type: "blocks:polling"
});
producer.on("blockProducer.fatalError", (error: any) => {
Logger.error(`Block producer exited. ${error.message}`);
process.exit(1); //Exiting process on fatal error. Process manager needs to restart the process.
});
これでnpm run build && npm run startすれば、生のブロックチェーンデータを取得してそのブロックナンバーとハッシュ値がMongoDBに保存されます。また、その過程でproducerがkafka topicにデータを送信していることをkafka-ui(http://localhost:3000)から確認できるはずです。
Transformer
.envの設定
.env
# COMMON_ENV
KAFKA_CONNECTION_URL=localhost:9092
# CONSUMER_ENV
CONSUMER_TOPIC=mumbai.80001.blocks <------ ../producer 内の.envで定義したPRODUCER_TOPIC
# PRODUCER_ENV
PRODUCER_TOPIC=apps.80001.token.approve <------ 注意
TOKEN_CONTRACT="0xd219ceBfce78ac7230f78b9F8893BF95Af278D2E" # NFT_CONTRACTと元はなっていたがNFTではないので書き換え。読み込み部分でも変更する必要あり
# LOGGER_ENV
SENTRY_DSN=
SENTRY_ENVIRONMENT=
DATADOG_API_KEY=
DATADOG_APP_KEY=
ここで注意して欲しいのは、ここでいうPRODUCER_TOPICの意味が、Chain Indexer FrameworkにおけるProducerのTopicではないということ。 Kafka(Pub/Sub)の文脈におけるProducer(トピックへのデータ発信者、送信者)であるので、Producerで設定した.envのものとは違う名前にする必要があります。Transformerが整形したデータの送信先Topicなので任意の名前をつけます。
同じように、CONSUMER_TOPICについても、TransformerがConsumer(Kafkaの文脈)として消費するTopicなので、CONSUMER_TOPIC=Producerの.envで設定したPRODUCER_TOPICということになります。
各種ファイルについて
examplesをだいたい踏襲してるので、src/にはinterfaces,mappers,schemasという3つのフォルダとtransformer.ts, index.tsがあると思います。
それぞれについて簡単に説明します。
index.ts
index.ts
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import { BlockProducerError } from "@maticnetwork/chain-indexer-framework/errors/block_producer_error";
import startTransforming from "./transformer.js";
import { TokenApprovalMapper } from "./mappers/token_approval_mapper.js";
import dotenv from 'dotenv';
import path from "path";
dotenv.config();
Logger.create({
sentry: {
dsn: process.env.SENTRY_DSN,
level: 'error'
},
datadog: {
api_key: process.env.DATADOG_API_KEY,
service_name: process.env.DATADOG_APP_KEY,
}
});
/**
* Initialise the transform service with producer topic, proto file names,
* producer config, consumer topic and consumer proto files
*/
try {
startTransforming(
{
"bootstrap.servers": process.env.KAFKA_CONNECTION_URL || "localhost:9092",
"group.id": "matic.transfer.transformer",
"security.protocol": "plaintext",
"message.max.bytes": 26214400,
"fetch.message.max.bytes": 26214400,
coders: {
fileName: "block",
packageName: "blockpackage",
messageType: "Block"
},
topic: process.env.CONSUMER_TOPIC || "polygon.1.blocks",
},
{
topic: process.env.PRODUCER_TOPIC || "apps.1.matic.transfer",
"bootstrap.servers": process.env.KAFKA_CONNECTION_URL || "localhost:9092",
"security.protocol": "plaintext",
"message.max.bytes": 26214400,
coder: {
fileName: "token_approval",
packageName: "tokenapprovalpackage",
messageType: "TokenApprovalBlock",
fileDirectory: path.resolve("dist", "./schemas/")
}
},
new TokenApprovalMapper()
);
} catch (e) {
Logger.error(BlockProducerError.createUnknown(e));
}
- transformer.jsのstartTransforming関数を実行しています。
- 第一引数: データの取得元kafka(Producer)の設定第
- 第二引数: Transformerが整形したデータを保存するkafkaの設定
- 第三引数: マッパーのインスタンス
- 第一引数と第二引数にある、coderというプロパティには、それぞれのkafkaとやりとりするデータのインターフェースが定義されている.protoファイルのファイル名・パッケージ名・メッセージタイプ・コピー先のディレクトリを設定します。
- 第一引数の方は、chain-indexer-frameworkがすでに持っているblock.protoを指しています。
- 第二引数は、後ほど説明するtoken_approval.protoを指します。
transformer.ts
transformer.ts
import { ITransformedBlock } from "@maticnetwork/chain-indexer-framework/interfaces/transformed_block";
import { ITransaction } from "@maticnetwork/chain-indexer-framework/interfaces/transaction";
import { IBlock } from "@maticnetwork/chain-indexer-framework/interfaces/block";
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import { IConsumerConfig } from "@maticnetwork/chain-indexer-framework/interfaces/consumer_config";
import { IProducerConfig } from "@maticnetwork/chain-indexer-framework/interfaces/producer_config";
import { transform } from "@maticnetwork/chain-indexer-framework/data_transformation/transform";
import ITokenApprovalTx from "./interfaces/token_approval_tx.js";
import { TokenApprovalMapper } from "./mappers/token_approval_mapper.js";
export default async function startTransforming(
consumerConfig: IConsumerConfig,
producerConfig: IProducerConfig,
tokenApprovalMapper: TokenApprovalMapper
): Promise<void> {
try {
transform<IBlock, ITokenApprovalTx>({
consumerConfig,
producerConfig,
type: 'asynchronous'
}, {
transform: async (block: IBlock): Promise<ITransformedBlock<ITokenApprovalTx>> => {
let approvals: ITokenApprovalTx[] = [];
block.transactions.forEach((transaction: ITransaction) => {
approvals = approvals.concat(tokenApprovalMapper.map(transaction));
});
return {
blockNumber: block.number,
timestamp: block.timestamp,
data: approvals
};
},
error(err: Error) {
console.error('something wrong occurred: ' + err);
},
})
} catch (error) {
Logger.error(`Transformer instance is exiting due to error: ${error}`);
process.exit(1);
}
}
- ここでは、startTransformingが定義されていて、その中でchain-indexer-frameworkのtransform関数を実行しています。
- 第一引数には、producer,consumerのconfigと同期/非同期を指定するtypeを設定します。
- 第二引数にはIEventTransformerが渡されていて、その中のtransformメソッド内に処理したい内容を書いていきます。
- mapperのmapメソッドを呼び、その返り値を配列にする処理が書かれています。
schemas/token_approval.proto
token_approval.proto
package tokenapprovalpackage;
syntax = "proto3";
message TokenApprovalBlock {
message TokenApprovalEvent {
required uint64 transactionIndex = 1;
required string transactionHash = 2;
required string transactionInitiator = 3;
required string tokenAddress = 4;
required string ownerAddress = 5;
required string spenderAddress = 6;
required uint64 amount = 7;
}
required uint64 blockNumber = 1;
required uint64 timestamp = 2;
repeated TokenApprovalEvent data = 3;
}
- ここではkafkaとデータをやり取りする際のインターフェースを定義しています。
- 今回はデータを送信する際のインターフェースで、後にConsumerでも同じインターフェースを使ってデータの取得を行います。
- protocol buffersではuint64が最大
mappers/token_approval_mapper.ts
token_approval_mapper.ts
import { ITransaction } from "@maticnetwork/chain-indexer-framework/interfaces/transaction";
import { IMapper } from "@maticnetwork/chain-indexer-framework/interfaces/mapper";
import { ABICoder } from "@maticnetwork/chain-indexer-framework/coder/abi_coder";
import { BloomFilter } from "@maticnetwork/chain-indexer-framework/filter";
import ITokenApprovalTx from "../interfaces/token_approval_tx.js";
import utils from "web3-utils";
import dotenv from 'dotenv';
import { Logger } from "@maticnetwork/chain-indexer-framework";
dotenv.config();
export class TokenApprovalMapper implements IMapper<ITransaction, ITokenApprovalTx> {
map(transaction: ITransaction): ITokenApprovalTx[] {
const logsBloom = transaction.receipt.logsBloom;
let approvals: ITokenApprovalTx[] = [];
if (this.isTokenApproval(logsBloom)) {
let erc20Approval = this.mapApprovalErc20(transaction);
approvals = [...approvals, ...erc20Approval];
}
return approvals;
}
private mapApprovalErc20(transaction: ITransaction): ITokenApprovalTx[] {
let approvals: ITokenApprovalTx[] = [];
for (const log of transaction.receipt.logs) {
if (
log.topics.length && log.topics.length >= 3 &&
// Check if event was emitted by NFT Contract
log.address.toLowerCase() === (process.env.TOKEN_CONTRACT as string).toLowerCase() &&
log.topics[0] === utils.keccak256("Approval(address,address,uint256)")
) {
approvals.push({
transactionIndex: transaction.receipt.transactionIndex,
transactionHash: transaction.hash.toLowerCase(),
transactionInitiator: transaction.from.toLowerCase(),
tokenAddress: log.address.toLowerCase(),
ownerAddress: ABICoder.decodeParameter("address", log.topics[1]).toLowerCase(),
spenderAddress: ABICoder.decodeParameter("address", log.topics[2]).toLowerCase(),
amount: utils.toBN(log.data).toNumber(),
})
}
}
return approvals;
}
private isTokenApproval(logsBloom: string): boolean {
return BloomFilter.isTopicInBloom(logsBloom,
utils.keccak256("Approval(address,address,uint256)") // Approval(address,address,uint256)
) && BloomFilter.isContractAddressInBloom(
logsBloom,
process.env.TOKEN_CONTRACT as string
);
}
}
-
Transformerの実装の肝です
- IMapperはmapメソッドを実装していて、ITransaction型のtxからApprovalイベントがあるかを判断します(isTokenApproval関数)
- その後、mapApprovalErc20メソッドにてそのtxのログから欲しいデータ取得し、後に説明するITokenApprovalTxの形に整形して返します。
- ここで、ABICoderという、chain-indexer-frameworkのヘルパーを利用して、簡単にtopics内の要素をデコードできます。
interfaces/token_approval_tx.ts
token_approval_tx.ts
import Long from "long";
export default interface ITokenApproveTx {
transactionIndex: Long,
transactionHash: string,
transactionInitiator: string,
tokenAddress: string,
ownerAddress: string,
spenderAddress: string,
amount: number,
}
- 先ほど説明したMapperのmapメソッドが返す値の型です。
- 今回の実装だとこの型が、そのままschemas/token_approval.protoで定義したインターフェースの一部にすっぽり収まるようになっています。
留意点
ここで、イベントが発火したときにどのように引数が保存されているかについて留意しておきましょう
event Approval(address indexed owner, address indexed spender, uint256 value);
indexedが付いている引数はlog.topicsに、そうでない方はlog.dataにデータが保存されることをお忘れなく。
log.topics内に保存されるデータはBloomフィルタによる検索効率が良く、log.dataはそういった検索効率は加味されていないですが、topicsよりも大きく柔軟なデータストレージであるというEVM互換のブロックチェーンの特徴があります。
実装できれば、npm run build && npm run start を実行して成功するはずです。
成功していれば、kafka-uiにて、Producer,Transformerにて設定したTopicsがkafkaに保存されていることが確認できます。
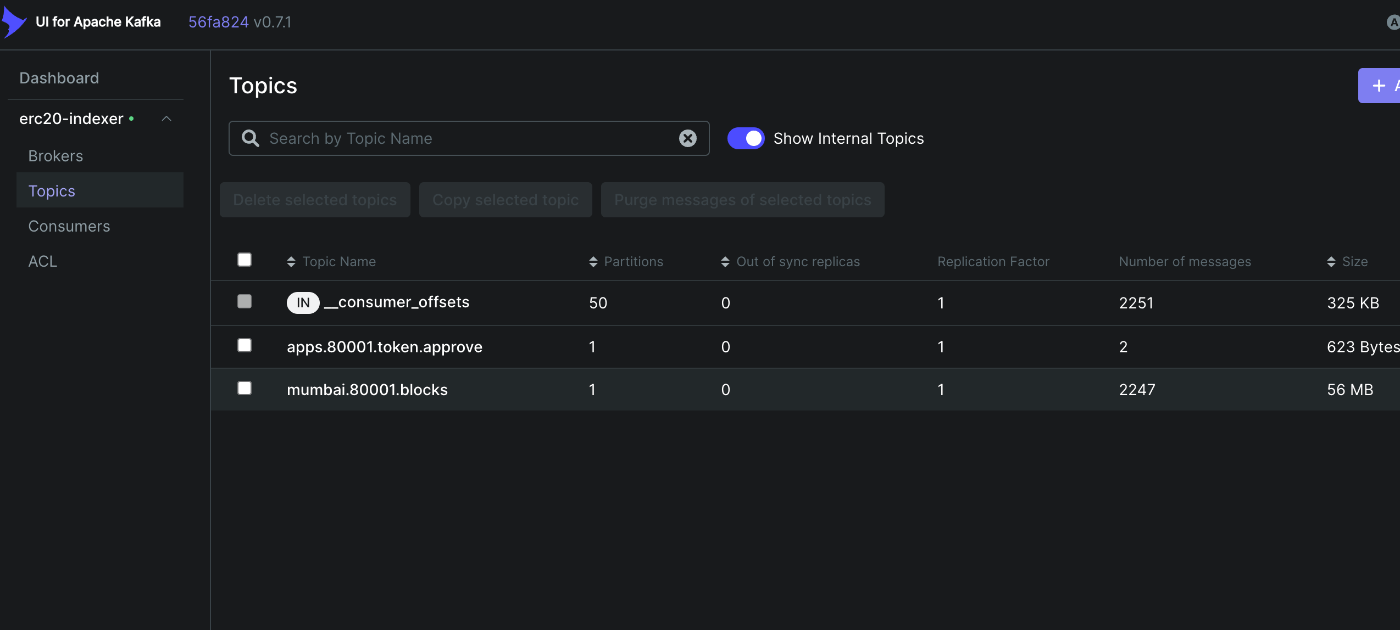
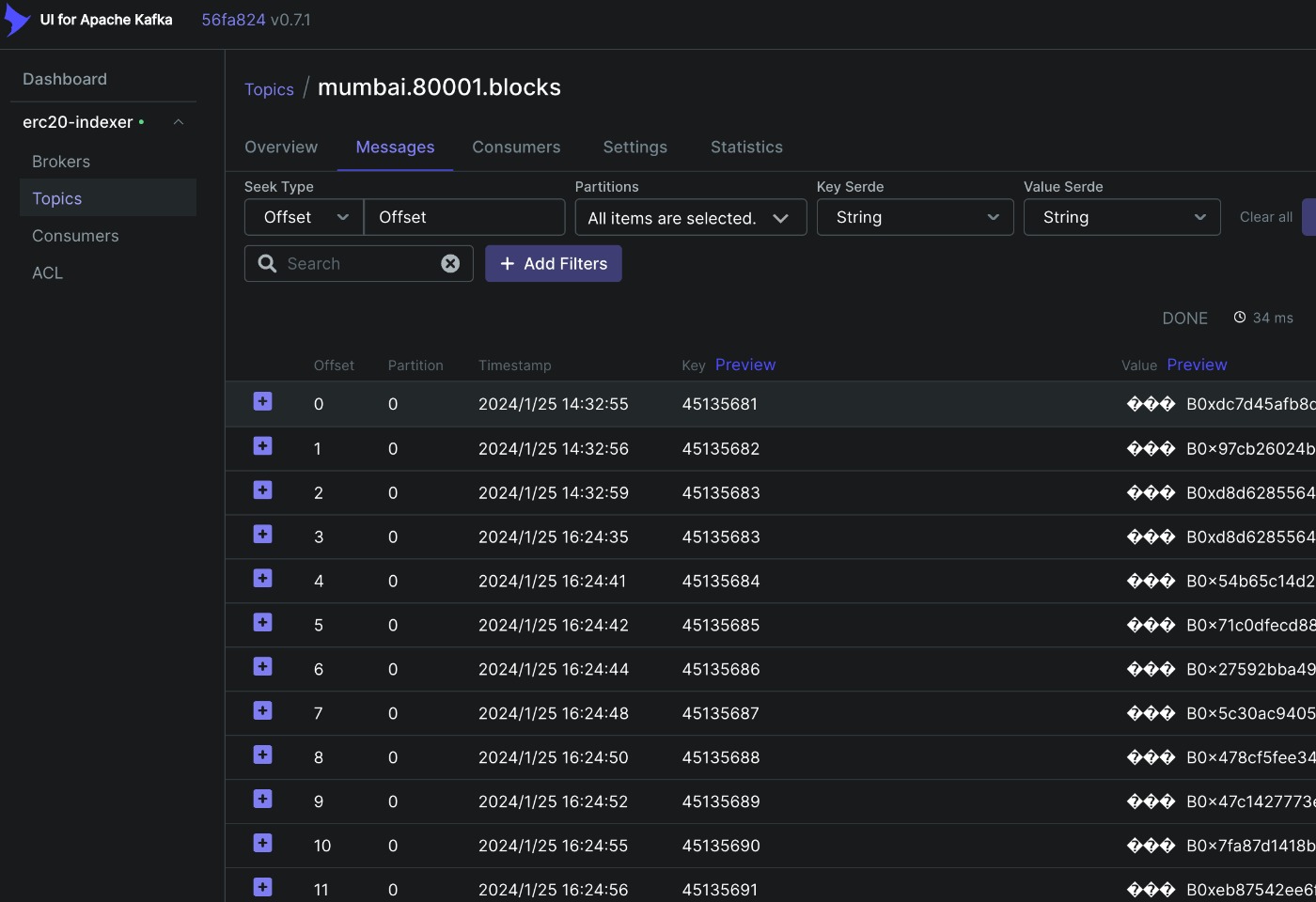
Consumer
.envの設定
.env
# COMMON
MONGO_URL=mongodb://localhost:27017/erc20-indexer
#CONSUMER
KAFKA_CONNECTION_URL=localhost:9092
CONSUMER_GROUP_ID=token.consumer
# MAPPING_TOPIC
TRANSFER_TOPIC=apps.80001.token.approve # Transfomrerが整形したデータを送ったトピック
# LOGGER_ENV
SENTRY_DSN=
SENTRY_ENVIRONMENT=
DATADOG_API_KEY=
DATADOG_APP_KEY=
# START_CONSUMER and START_API_ENDPOINTS can be true and false based on if there will
# be different server for both or same for both.
TRANSFER_TOPICはTransformerの.envで設定したPRODUCER_TOPICであることに注意しましょう
各種ファイルのについて
index.ts
index.ts
import { Database } from "@maticnetwork/chain-indexer-framework/mongo/database";
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import TokenApprovalMapper from "./mapper/token_approval_mapper.js";
import ApprovalTokenService from "./services/approval_token.js";
import { TokenModel } from "./models/token.js";
import startConsuming from "./consumer.js";
async function start(): Promise<void> {
try {
Logger.create({
sentry: {
dsn: process.env.SENTRY_DSN,
level: 'error'
},
datadog: {
api_key: process.env.DATADOG_API_KEY,
service_name: process.env.DATADOG_APP_KEY
},
console: {
level: "debug"
}
});
const database = new Database(process.env.MONGO_URL || 'mongodb://localhost:27017/chain-indexer');
await database.connect();
const approvalTokenService = new ApprovalTokenService(
await TokenModel.new(database),
);
await startConsuming(approvalTokenService, new TokenApprovalMapper());
} catch (error) {
Logger.error(`Error when starting consumer service: ${(error as Error).message}`);
}
}
start();
- start関数が定義され、実行されています
- その中で、データベースのインスタンスを生成してTokenモデルに渡しています
- そのモデルがまた、TokenApprovalSeiviceのインスタンスのコンストラクタに渡されています。
- そのサービスのインスタンスと、マッパークラスのインスタンスがstartConsuming関数の引数として渡されています
consumer.ts
consumer.ts
import { ITransformedBlock } from "@maticnetwork/chain-indexer-framework/interfaces/transformed_block";
import { DeserialisedMessage } from "@maticnetwork/chain-indexer-framework/interfaces/deserialised_kafka_message";
import { consume } from "@maticnetwork/chain-indexer-framework/kafka/consumer/consume";
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import ApprovalTokenService from "./services/approval_token.js";
import ApprovalTokenMapper from "./mapper/token_approval_mapper.js";
import ITokenApprovalTx from "./interfaces/token_approval_tx.js";
import dotenv from 'dotenv';
import path from "path";
dotenv.config()
export default async function startConsuming(approvalTokenService: ApprovalTokenService, approvalTokenMapper: ApprovalTokenMapper): Promise<void> {
try {
consume({
"metadata.broker.list": process.env.KAFKA_CONNECTION_URL || "localhost:9092",
"group.id": process.env.CONSUMER_GROUP_ID || "matic.transfer.consumer",
"security.protocol": "plaintext",
topic: process.env.TRANSFER_TOPIC || "apps.1.matic.transfer",
coders: {
fileName: "token_approval",
packageName: "tokenapprovalpackage",
messageType: "TokenApprovalBlock",
fileDirectory: path.resolve("dist", "./schemas/")
},
type: 'synchronous'
}, {
next: async (message: DeserialisedMessage) => {
const transformedBlock = message.value as ITransformedBlock<ITokenApprovalTx>;
const approvals: ITokenApprovalTx[] = transformedBlock.data as ITokenApprovalTx[];
if (approvals && approvals.length > 0) {
await approvalTokenService.save(
approvalTokenMapper.map(transformedBlock)
);
}
},
error(err: Error) {
console.error('something wrong occurred: ' + err);
},
closed: () => {
Logger.info(`subscription is ended.`);
throw new Error("Consumer stopped");
},
});
} catch (error) {
Logger.error(`Consumer instance is exiting due to error: ${error}`);
process.exit(1);
}
}
- startConsuming関数が定義されています
- その中でconsume関数が実行されています
- 第一引数はデータ取得元のkafkaのconfigが設定されてます
- ここで、schemas/のファイルがインターフェースとしてcodersに設定されています
- 第二引数のnextプロパティ内で、consumerの処理の内容が書かれています
- マッピングして、サービスを通じてDBにsaveします
schemas/token_approval.proto
schemas/token_approval.proto
package tokenapprovalpackage;
syntax = "proto3";
message TokenApprovalBlock {
message TokenApprovalEvent {
required uint64 transactionIndex = 1;
required string transactionHash = 2;
required string transactionInitiator = 3;
required string tokenAddress = 4;
required string ownerAddress = 5;
required string spenderAddress = 6;
required uint64 amount = 7;
}
required uint64 blockNumber = 1;
required uint64 timestamp = 2;
repeated TokenApprovalEvent data = 3;
}
kafkaとデータのやりとりをする際のインターフェースです。
services/approval_token.ts
services/approval_token.ts
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import { Model } from "mongoose";
import { IToken } from "../interfaces/token.js";
export default class ApprovalTokenService {
constructor(
private tokenModel: Model<IToken>,
) { }
public async save(data: IToken[]): Promise<boolean> {
Logger.debug({
location: "approval_token_service",
function: "saveApprovalToken",
status: "function call",
data: {
length: data.length
}
});
if (data && data.length) {
//@ts-ignore
await this.tokenModel.updateTokens(data);
}
Logger.debug({
location: "approval_token_service",
function: "saveApprovalToken",
status: "function completed"
});
return true;
}
}
- ApprovalTokenServiceクラスが定義されています
- コンストラクタで後に説明するTokenModelのインスタンスを設定
- saveメソッド内でTokenModelインスタンスのupdateTokensを利用してdataを保存しています。
- このdataは後に説明するmapperで任意の形にマッピングされているものです
mapper/token_approval_mapper.ts
mapper/token_approval_mapper.ts
import { ITransformedBlock } from "@maticnetwork/chain-indexer-framework/interfaces/transformed_block";
import { Logger } from "@maticnetwork/chain-indexer-framework/logger";
import ITokenApprovalTx from "../interfaces/token_approval_tx.js";
import { IToken } from "../interfaces/token.js";
export default class ApprovalTokenMapper {
public map(transformedBlock: ITransformedBlock<ITokenApprovalTx>): IToken[] {
let tokens: IToken[] = [];
for (const approvalTx of transformedBlock.data) {
tokens.push({
txHash: approvalTx.transactionHash,
ownerAddress: approvalTx.ownerAddress,
spenderAddress: approvalTx.spenderAddress,
amount: approvalTx.amount,
});
}
//Remove below when app is stable
Logger.debug({
location: "mapper: tokens",
function: "mapTokens",
status: "function completed",
})
return tokens;
}
}
- Transformerが整形したデータをさらにDBに保存するための型にマッピングして、配列を返しています
models/token.ts
models/token.ts
import { Database } from "@maticnetwork/chain-indexer-framework/mongo/database";
import { Model, Schema } from "mongoose";
import { IToken } from "../interfaces/token.js";
import statics from "../interfaces/token_methods.js";
const TokenSchema = new Schema<IToken>({
txHash:{
type: String
},
ownerAddress:{
type: String
},
spenderAddress:{
type: String
},
amount:{
type: Number
},
},
{
versionKey: false,
statics: statics
}
);
/**
* This class represents Token Model
*
* @class
*/
export class TokenModel {
/**
* Get the token model defined on this mongoose database instance
*
* @param {Database} database
*
*/
public static async new(database: Database) {
const model = database.model<IToken, Model<IToken>>(
"token",
TokenSchema
);
await model.createCollection();
return model;
}
}
- schemaを定義し、mongooseを利用してコレクションを作成しています
- このschema(TokenSchema)を定義する過程で、後に説明するメソッドであるupdateTokensも組み込んでいます。
interfaces/
interfaces/token_methods.ts
import { IToken } from "./token.js";
/**
* this class contains methods to interact with the database methods
*
* @returns implementation of all the token model method
*/
const statics = {
async updateTokens(data: IToken[]): Promise<void> {
for (let approvalToken of data) {
//@ts-ignore
await this.updateOne(
{ txHash: approvalToken.txHash },
{
txHash: approvalToken.txHash,
ownerAddress: approvalToken.ownerAddress,
spenderAddress: approvalToken.spenderAddress,
amount: approvalToken.amount,
},
{ upsert: true }
);
}
return;
}
}
export default statics;
- TokenSchema が利用するメソッド(updateTokens)を定義しています。
- この中で実行されている
this.updateOneは、mongooseのModel型のメソッドです。- 第一引数: キー
- 第二引数: 変更箇所
- 第三引数: オプション(upsertをOKするか)
- この中で実行されている
interfaces/token_approval_tx.ts
import Long from "long";
export default interface ITokenApprovalTx {
transactionIndex: Long,
transactionHash: string,
transactionInitiator: string,
tokenAddress: string,
ownerAddress: string,
spenderAddress: string,
amount: number,
}
- Topicからデータを取得するときの型です。
interfaces/token.ts
/**
* Interface for token details and its owner
*/
export interface IToken {
txHash: string,
ownerAddress: string,
spenderAddress: string,
amount: number,
}
- MongoDBにデータを保存するときの型です
ここまで書けてnpm run build && npm run startすれば成功するはずです。
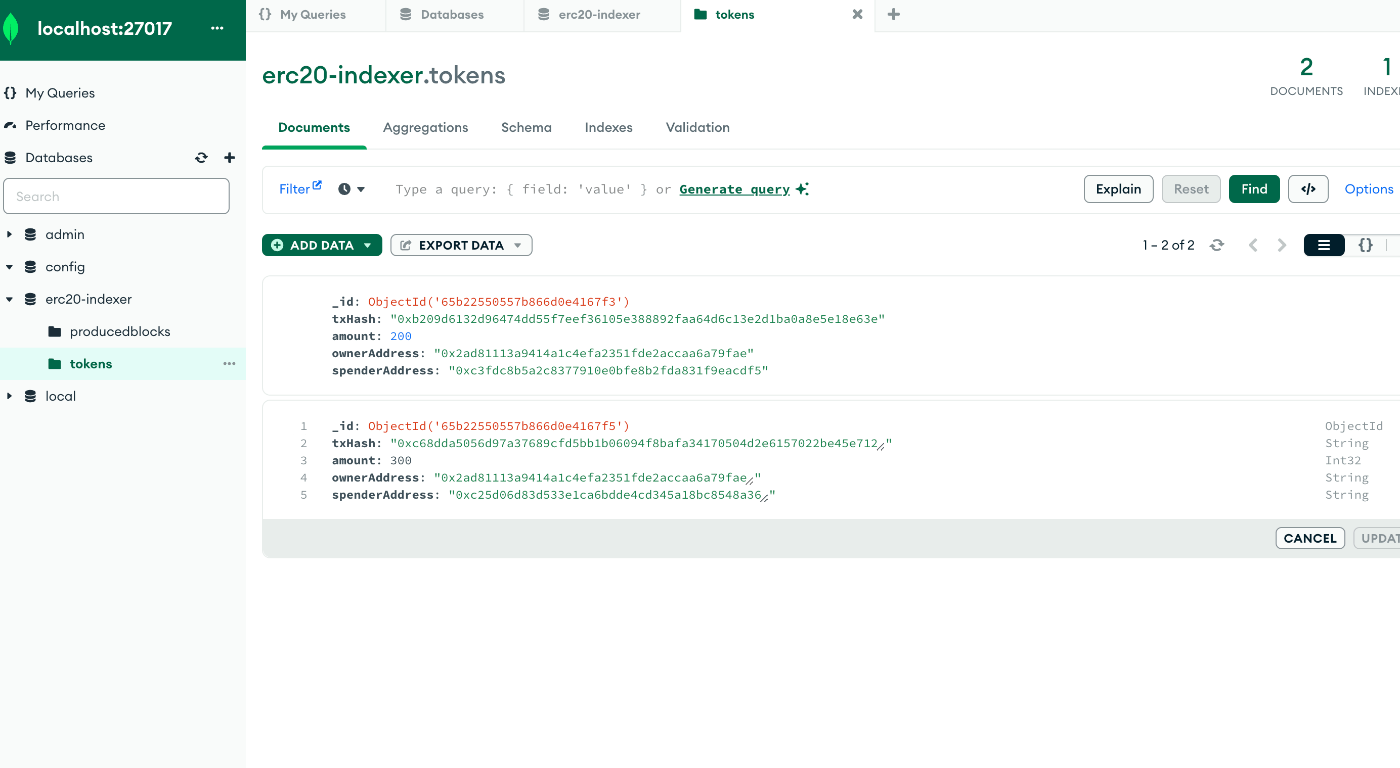
成功していれば、この画像のようにerc20-indexer内のtokensテーブルにドキュメントデータが追加されるはずです
おわりに
Chain-Indexer-Frameworkはそのカスタマイズ性の高さから、さまざまなdappsのユースケースに対応できます。特に、マルチチェーンの環境でデータパイプラインを構築する際に、その疎結合なアーキテクチャがフィットするかと思います。さまざまなブロックチェーンネットワークに対応し、各ブロックチェーンのデータを一元的に処理・分析することできます。
また、ブロックチェーンデータのインデクサー作成と処理に関する複雑さを軽減し、開発者がよりデータ取得のロジックに集中することができます。
独自のインデクサーをゼロから開発する必要がある場合には、Chain-Indexer-Frameworkは有力な選択肢であり、その使いやすさと柔軟性によって開発の効率が大きく向上すると思います。
ぜひ使ってみてください。
no plan株式会社について
- no plan株式会社は 「テクノロジーの力でZEROから未来を創造する、精鋭クリエイター集団」 です。
- ブロックチェーン/AI技術をはじめとした、Webサイト開発、ネイティブアプリ開発、チーム育成、などWebサービス全般の開発から運用や教育、支援なども行っています。よくわからない、ふわふわしたノープラン状態でも大丈夫!ご一緒にプランを立てていきましょう!
- no plan株式会社について
- no plan株式会社 | web3実績
-
no plan株式会社 | ブログ一覧
エンジニアの採用も積極的に行なっていますので、興味がある方は是非ご連絡ください! - CTOのDMはこちら
参考
- https://github.com/0xPolygon/chain-indexer-framework
- https://blog.jarrodwatts.com/create-a-blockchain-indexer-with-chain-indexer-framework
- https://polygon.technology/blog/chain-indexer-framework-your-open-source-gateway-to-building-scalable-dapps
- https://twitter.com/0xPolygonDevs/status/1729520391133995209

Discussion