表形式データを markdown テーブルに変換
はじめに
本記事では「表計算ソフト(例:Microsoft Excel や Google Sheets など)のデータを、Markdown テーブル に変換する」ことを目的とし、その実装を考えていきます。なお 実際の動き(利用)としては、下記を想定しています。
- 表データをコピーする
-
クリップボードを経由して、テキスト形式(≒
tsv)でフォームに貼り付け - フォーム内容を基に、
markdownテーブルを作成
クリップボードについての話は、最下段に補足として乗せておきます。
その他紹介
本記事と逆のパターンも用意していますので、興味がある方は下記記事を参照してください。
なお 本記事で扱った内容は、下記場所にて使っています。
事前準備
ここでは設計を始める前段階として、目的や条件等の詳細を考えていきます。
環境の定義
本記事では JavaScript を使って処理していきます。
なお JavaScript 特有の機能を使うわけではないので、他言語でも 設計 や作成 の内容を流用することは可能です。本記事で主に必要となる機能は、下記のとおりです。
- 「改行コード」や「タブ文字」といった特殊文字を扱う
- 配列を操作する(要素数の取得や、分割・統合・挿入など)
条件の定義
ここでは、実装する機能の入出力データをどうするかについて定義します。
入力値となる表形式データはタブ文字と改行コードによるものとする
表形式のデータと言っても、Excel や GoogleSheets など様々あります。下図は GoogleSheets を使った場合のデータ(表形式+テキスト)です。

表 列A 列B
行1 セルA1 セルB1
行2 セルA2 セルB2
上記テキストは、タブが列の区切り、改行が行の区切りで表現されています。そのため タブを \t、改行を \n に置き換えると、下記のようになります。
表\t列A\t列B\n行1\tセルA1\tセルB1\n行2\tセルA2\tセルB2
よって 入力されるデータについては、下記のように定義します。
- 各行は改行コード(例:
\n)によって区切られる - 各列はタブ文字(例:
\t)によって区切られる - セル結合は考慮しない
空白セルが含まれる入力を想定する
更に、入力に使われるデータはこうした綺麗なデータのみとは限りません。例えば下図は、中央のセルが空白になった状況を表しています。

こうしたデータも入力として想定し、出力の際に行列の関係が崩れることなく処理することが求められます。
出力する文字列はmarkdown形式のテーブルとする
出力される文字列について、markdown のテーブル形式となるようにします。下図は、先程の入力を markdown に変換した結果(テーブル形式+テキストデータ)です。
| 表 | 列A | 列B |
|---|---|---|
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
このことから 出力されるデータについて、下記のように定義します。
- 表の見出し(ヘッダー)は、1行目を使用する(≒クロス集計表のような、行列組み合わせた表は想定しない)
- 最小限の構成で出力する
- 左右揃え、中央揃え等を考慮しない
- スペースやハイフンを使った見栄え調整(例:テキスト上での列幅を揃える)は行わない
オプション項目:出力時のエスケープ処理について
上記の入力や出力に関する条件は、機能として必須のものとなっています。ここでは、必須ではない努力項目としてmarkdown ルールに抵触する文字についての処理を定義します。
下記は、基本となる入出力の例です。タブによる区切りがパイプ(|)による区切りに変わっていることが確認できます。
表 列A 列B
行1 セルA1 セルB1
行2 セルA2 セルB2
↓ 正常に出力される
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
では セル内にパイプ記号が含まれた場合はどうなるでしょうか?

表 列A 列B
行1 セルA1 セルB1
行2 セルA2 セルB2
↓ A1セルが分割されてしまう
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル|A1 | セルB1 |
| 行2 | セルA2 | セルB2 |
この場合、markdown では 「セル|A1」を「セル」「A1」と分割してしまい、正しい形にはなりません。これは | がセルを区切る役割とセル内の単なる文字列のどちらであるのか、区別できないためです。
これを区別させるには、特殊な意味を持たない、単なる文字であることを伝えるためにエスケープ処理を挟む必要があります。
| 表 | 列A | 列B |
|---|---|---|
| 行1 | セル|A1 | セルB1 |
| 行2 | セルA2 | セルB2 |
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル\\|A1 | セルB1 |
| 行2 | セルA2 | セルB2 |
このように、markdown出力時に影響を及ぼす文字に対し、エスケープ処理を行うことをオプション項目として条件に設定しておきます。
設計
ここからは事前準備で決めた内容を基に、どのように実装していくかを考えていきます。大きな流れとしては、必須のものとして変換処理があり、その前後にオプションとして無害化と復元処理が入る形となります。具体的には、下記となります。
- 処理に不都合な文字列を無害化(オプション)
- 変換処理
- 特殊文字の表現を統一
- 二次元配列の形で格納
- 列数を調べ、セパレート行の文字列を生成
- 各行処理(一次配列を
|で繋げて文字列化し、両端に|を付ける) - 2行目にセパレート行を挿入し、改行コードで繋げて 1 つの文字列に
- 1番で施した処理を、エスケープ処理した形で元に戻して完成(オプション)
2番の「変換処理」を ひとまとめにしているのは、後の作成段階で 一連の処理を関数化するためです。変換処理を行う関数をベースとして、それをラップする形でエスケープ処理付き変換関数を作成することになります。
1:処理に不都合な文字列を無害化(オプション)
まずは、セル内に含まれている | などを無害化しておきます。後の処理で markdown テーブルのセル区切りとしての | が出てきてしまうので、識別できる内に何とかしなければなりません。
ここでは、別の文字列に置き換えることで無害化します。例えば | は @@PIPE@@ といった、通常使われることのない文字列に置換しておきます。処理の最後で復元する必要があるので、無害化する文字種が複数ある場合は区別できるようしておかなければなりません。
2:変換処理
ここからは、必須条件となる「表形式データを markdown に変換」する処理となります。
2-1:特殊文字の表現を統一
無害化処理が終わったら、後の処理に備えて特殊文字の表現を統一しておきます。例えば改行コードは OS によって、LF(\n) や CRLF(\r\n) のように表記ブレが起きるケースがあります。
これを片方に合わせておくことで、後の処理をスムーズにしておきます。
2-2:文字列を二次元配列に
ここでは表形式データの文字列を、配列形式で格納します。中身は改行コードとタブ文字の組み合わせでデータが分けられているので、それを利用し二次元配列の形式に変換します。
表 列A 列B
行1 セルA1 セルB1
行2 セルA2 セルB2
[
['表', '列A', '列B'],
['行1', 'セルA1', 'セルB1'],
['行2', 'セルA2', 'セルB2'],
]
2-3:列数からセパレート行文字列を作成
配列に格納したことで、表の列数がわかります。ここでは配列の最初の要素の数を調べ、列数を調べます。
[
['表', '列A', '列B'],
['行1', 'セルA1', 'セルB1'],
['行2', 'セルA2', 'セルB2'],
]
列数がわかれば、markdown テーブルのセパレート行を作れます。セパレート行とは、表頭(ヘッダー)と表体(ボディ)の間にある、|---|---|---| 形式の文字列です。
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
これには まず列数分の --- を用意し、それを | で繋げた文字列を作ります。そして その文字列に対し 両端に | を加えれば、セパレート行の完成です。
2-4:各行のデータ(配列形式)を文字列化
セパレート行は完成したので、次は残りの表データを markdown 文に変えていきます。残りの表データというのは、下記の配列のことです。
[
['表', '列A', '列B'],
['行1', 'セルA1', 'セルB1'],
['行2', 'セルA2', 'セルB2'],
]
この配列の要素は各行単位となっており、各行の中に更に列単位の要素に分けられています。そのため、まずは各行単位で 1 つの文字列としてまとめていきます。
処理の内容は、先程のセパレート行の生成と ほぼ一緒です。各要素を | で繋げて 1 つの文字列とし、それの両端に | をつければ完成です。
[
'| 表 | 列A | 列B |',
'| 行1 | セルA1 | セルB1 |',
'| 行2 | セルA2 | セルB2 |',
]
2-5:表データ(配列形式)を文字列化
先ほど作成した 各行単位の markdown 文ですが、完成させるためには セパレート行 が不足しています。そこで、用意したセパレート行文字列を配列の中に挿入します。
[
'| 表 | 列A | 列B |',
'| --- | --- | --- |',
'| 行1 | セルA1 | セルB1 |',
'| 行2 | セルA2 | セルB2 |',
]
後は各要素を改行コードで繋げて 1 つの文字列にしてしまえば、必須処理としては完成です。
'| 表 | 列A | 列B |\n| --- | --- | --- |\n| 行1 | セルA1 | セルB1 |\n| 行2 | セルA2 | セルB2 |'
3:無害化していた文字列をエスケープ処理した形で復元し完成(オプション)
1番で行った無害化処理が含まれている場合には、無害化した文字列を元の意味に戻す処理が必要となります。
ただし、無害化した | を そのまま | として戻してしまっては、markdown に影響が出てしまうので意味がありません。そのため | は \\| にするなどの、エスケープ処理した形での復元でなければなりません。
作成
ここからは設計で決めた内容を基に、コードに起こしていきます。設計で説明した通り、大枠として 2 つの関数を作成することになります。
- ベースとなる、表形式データを markdown に変換する関数
- (上記をラップする形で)エスケープ処理付きの変換関数
ベースとなる変換関数
まずは必須条件を満たす、表形式データを markdown テーブルに変換する関数を作成していきます。
ここでは関数名を excel2markdown() とします。テスト文を付けると、下記のようになります。
function excel2markdown(excelStr) {
// 表形式データ(文字列)を、markdown テーブル(文字列)に変換して返す
}
// テスト
const excelStr = `表\t列A\t列B\n行1\tセルA1\tセルB1\n行2\tセルA2\tセルB2`;
console.log(excel2markdown(excelStr));
/* ↓ 出力結果
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
*/
特殊文字の表現を統一
最初に行うのは、OS により表記ブレが起きうる特殊文字を統一です。
ここでは改行コードの LF(\n) と CRLF(\r\n) を、\n に統一しておきます。
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
}
テーブルデータを二次元配列に
次に、テーブルデータを配列形式に格納します。入力として受け取る文字列は、\n で行、\t で列を区切っているので、それらを split() で分割し、二次元配列にします。
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
// 行→列の順で、配列に分割
const rows = normalizedStr.trim().split('\n');
const table = rows.map(row => row.split('\t'));
}
後々の処理は、この table を使っていくことになります。
列数からセパレート行の生成
次に、markdown テーブルに必要となるセパレート行(例:|---|---|---|)を作成します。ここで必要な作業は下記のとおりです。
- 列数分
---を用意し、間を|でつなげる - できた文字列の両端を
|で囲む
列数は table[0].length で取得できます。なので、列数分の枠を設けた空配列を用意し、それに --- で埋めることからはじめます。
const numColumns = table[0].length;
const separateStr = Array(numColumns).fill('---');
最終的に必要なのは |---|---|---| という文字列です。なので列数分あるこの配列を、join(' | ') で繋げて文字列化します。
(※ ここでは最低限の見栄え確保のため、| の前後にスペースを設け、データ間の間隔を空けています)
const numColumns = table[0].length;
const separateStr = Array(numColumns).fill('---').join(' | ');
この段階では、separateStr は --- | --- | --- のような形です。なので、両端に | をつければ完成となります。ここではテンプレートリテラルを使い、これまでの式を埋め込む形で、一気に必要な文字列を作成しています。
(※ ここでも最低限の見栄え確保のため、両端につける | とデータとの間にスペースを設けています)
const numColumns = table[0].length;
const separateStr = `| ${Array(numColumns).fill('---').join(' | ')} |`;
関数の中に組み込んだものが、下記となります。
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
// 行→列の順で、配列に分割
const rows = normalizedStr.trim().split('\n');
const table = rows.map(row => row.split('\t'));
// 列数から、Markdown のセパレート文字列を生成
const numColumns = table[0].length;
const separateStr = `| ${Array(numColumns).fill('---').join(' | ')} |`;
}
各行単位で配列を文字列化
現在 table は二次元配列となっていますが、これはセパレート行を作るために列数が必要だったためです。
[
['表', '列A', '列B'],
['行1', 'セルA1', 'セルB1'],
['行2', 'セルA2', 'セルB2'],
]
セパレート行を作成した今の段階では、もう各行要素が配列形式である必要はありません。なので、ここで配列を markdown 形式の文字列に変えてしまいます。
ここでは、return で使う変数 result を用意し、二次元配列である table を一次配列にした形で代入します。下記では map 関数を使い各行単位で、配列を文字列化する処理を行っています。
文字列化処理については、セパレート行の生成で行った処理と ほぼ同じです。
(向こうでは空配列に --- を埋めてましたが、こちらはすでにデータはある状態なので そのまま | で繋げています)
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
// 行→列の順で、配列に分割
const rows = normalizedStr.trim().split('\n');
let table = rows.map(row => row.split('\t'));
// 列数から、Markdown のセパレート文字列を生成
const numColumns = table[0].length;
const separateStr = `| ${Array(numColumns).fill('---').join(' | ')} |`;
// 各行を `|` で分割した文字列に再統合
let result;
result = table.map(row => `| ${row.join(' | ')} |`);
}
表全体を一つの文字列にして完成
残る作業は、セパレート行を result の中に組み込んで、配列を 1 つの文字列にすることです。それを結果として返すことで、ベースとなる変換関数は完成となります。
セパレート行を表す文字列は separateStr で用意しています。これを、result のインデックス 0 と 1 の間に挿入するために、ここでは splice(start, deleteCount, item1) を使います。
result.splice(1, 0, separateStr);
これで、result の中身は下記のようになりました(テスト文のケース)
[
'| 表 | 列A | 列B |',
'| --- | --- | --- |',
'| 行1 | セルA1 | セルB1 |',
'| 行2 | セルA2 | セルB2 |',
]
後はこの配列を、改行コード \n で繋げる形で文字列化すれば完成です。これまでのコードに組み込み、関数として完成したものが下記になります。
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
// 行→列の順で、配列に分割
const rows = normalizedStr.trim().split('\n');
let table = rows.map(row => row.split('\t'));
// 列数から、Markdown のセパレート文字列を生成
const numColumns = table[0].length;
const separateStr = `| ${Array(numColumns).fill('---').join(' | ')} |`;
// 各行を `|` で分割した文字列に再統合
let result;
result = table.map(row => `| ${row.join(' | ')} |`);
// セパレート行を2行目に挿入後、配列を改行文字列で繋げて返す
result.splice(1, 0, separateStr);
return result.join('\n');
}
エスケープ処理付き変換関数(オプション)
ここからはベースとなる変換関数をラップする形で、エスケープ処理付きの変換関数を作成していきます。
手順としては、下記のようになります。
- 文字列に含まれる、処理に不都合な文字列を無害化(一時的に別の文字列に置換)
- 変換処理
- 1番で行った処理を、エスケープ処理付きで復元
無害化が必要な文字列としては、markdown 化した際に確実に影響が出てしまう | を想定します。
置換処理について
JavaScript で文字列を置換する主な方法としては、下記の2つが考えられます。
-
replace(pattern, replacement)関数による置換 -
{string}.split(separator1).join(separator2)のように、配列化からの統合
1番については、正規表現を使えるのが特徴です。今回ですと文字列全体を対象とするため g フラグによるグローバル検索を使います。また、| は正規表現において「論理和」の役割を持つため、replace(/\\|/g, '@@PIPE@@') のようにエスケープ処理付きで渡してあげる必要があります。
一方、2番の方法は正規表現を用いないのが特徴です。置換対象となる文字列(今回は |)を区切り文字として配列に分割し、置換先文字列(今回は @@PIPE@@)で文字列として繋ぎなおす処理を行います。
置換対象が | のみの現状において、本記事では 2 番の処理を採用します。
エスケープ処理付き変換関数の作成
置換する方法が決まったので、ここからはそれに基づきコーディングしていきます。
function excel2markdownWithEscaped(excelStr) {
// (引数に含まれる特定の文字列をエスケープ処理した上で)表形式データを、markdown テーブルに変換して返す
}
// テスト
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
/* ↓ 出力結果
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル\\|A1 | セル\\|B1 |
| 行2 | セル\\|A2 | セルB2 |
*/
変換テーブルの準備
本処理にあたって、必要となる情報は下記の 3 つです。
- エスケープ処理対象となる文字列
- 一時退避用の無害化文字列
- エスケープ処理した文字列
今回は、| のみ考えるので、上記内容をまとめると下表になります。
| 項目 | 値 |
|---|---|
処理対象の文字列 original
|
| |
退避用の文字列 evacuation
|
@@PIPE@@ |
処理済み文字列 escaped
|
\\| |
今後パターンが増えるかもしれないことを考慮して、この 3 つの情報をオブジェクトとして纏め、配列形式で格納しておきます。
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\\\|' // -> エスケープシーケンスで '\\|'
},
];
}
退避用文字列への置換処理
次に変換テーブルをループ(複数パターンを想定)させ、処理に不都合な文字列を退避用文字列に置換します。ここでは original にある文字列を区切り文字として配列に分割し、evacuation にある文字列で繋げることで置換処理を行っています。
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\\\|'
},
];
// 退避用文字列に置換
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.original).join(replacement.evacuation);
});
}
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
/* ↓ この段階だと、下記のようになる
表 列A 列B
行1 セル@@PIPE@@A1 セル@@PIPE@@B1
行2 セル@@PIPE@@A2 セルB2
*/
変換処理後に復元化
処理に不都合な | は @@PIPE@@ に変わっているため、ベースとなる変換関数 excel2markdown() に渡しても問題なくなりました。
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\\\|'
},
];
// 退避用文字列に置換
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.original).join(replacement.evacuation);
});
// ベース処理
excelStr = excel2markdown(excelStr);
}
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
/* ↓ この段階だと、下記のようになる
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル@@PIPE@@A1 | セル@@PIPE@@B1 |
| 行2 | セル@@PIPE@@A2 | セルB2 |
*/
後は @@PIPE@@ をエスケープ処理した文字列 \\| に置き換えれば、関数の返り値が完成します。ここでの置換処理は evacuation 文字列を区切りに配列化し、escaped 文字列で繋げることで行います。
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\\\|'
},
];
// 退避用文字列に置換
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.original).join(replacement.evacuation);
});
// ベース処理
excelStr = excel2markdown(excelStr);
// 退避させてた文字列をエスケープ処理付きで復元
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.evacuation).join(replacement.escaped);
});
return excelStr;
}
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
/* ↓ 返り値は、目標としていたデータと一致
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル\\|A1 | セル\\|B1 |
| 行2 | セル\\|A2 | セルB2 |
*/
補足
コード全文
コード全文(長いので格納しています)
function excel2markdown(excelStr) {
// 改行コードを \n に統一
const normalizedStr = excelStr.replace(/\r\n/g, '\n');
// 行→列の順で、配列に分割
const rows = normalizedStr.trim().split('\n');
let table = rows.map(row => row.split('\t'));
// 列数から、Markdown のセパレート文字列を生成
const numColumns = table[0].length;
const separateStr = `| ${Array(numColumns).fill('---').join(' | ')} |`;
// 各行を `|` で分割した文字列に再統合
let result;
result = table.map(row => `| ${row.join(' | ')} |`);
// セパレート行を2行目に挿入後、配列を改行文字列で繋げて返す
result.splice(1, 0, separateStr);
return result.join('\n');
}
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\\\|'
},
];
// 退避用文字列に置換
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.original).join(replacement.evacuation);
});
// ベース処理
excelStr = excel2markdown(excelStr);
// 退避させてた文字列をエスケープ処理付きで復元
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.evacuation).join(replacement.escaped);
});
return excelStr;
}
const test = '表\t列A\t列B\n行1\tセルA1\tセルB1\n行2\tセルA2\tセルB2';
console.log(excel2markdown(test));
/* ↓ 出力結果
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セルA1 | セルB1 |
| 行2 | セルA2 | セルB2 |
*/
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
/* ↓ 出力結果
| 表 | 列A | 列B |
| --- | --- | --- |
| 行1 | セル\\|A1 | セル\\|B1 |
| 行2 | セル\\|A2 | セルB2 |
*/
実際に使用する際の注意事項
本記事では、逆パターン markdown から表形式データに変換 が上手く処理できないという理由から \\| という形でのエスケープしています。
ですが実際に使用する際には \| で処理できるケースがあります。例として、私が作成している簡易ツール集 では textarea 要素を使って入力を受け付けており、\| の形で処理できています。
これはスクリプト上で用意した文字列リテラルでは自動的にエスケープ処理されるのに対し、textarea 等に入力されたデータは生の文字列として受け入れているためです。
このような挙動の違いがあるため、実際に利用する際にはエスケープ処理の扱いに注意が必要となってきます。下記は生の文字列が使える場合のパターンで、\| でエスケープするようになっています。
生の文字列で処理する場合の関数
function excel2markdownWithEscaped(excelStr) {
const conversionTable = [
{
original: '|',
evacuation: '@@PIPE@@',
escaped: '\\|'
},
];
// 退避用文字列に置換
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.original).join(replacement.evacuation);
});
// ベース処理
excelStr = excel2markdown(excelStr);
// 退避させてた文字列をエスケープ処理付きで復元
conversionTable.forEach(replacement => {
excelStr = excelStr.split(replacement.evacuation).join(replacement.escaped);
});
return excelStr;
}
const testWithPipe = '表\t列A\t列B\n行1\tセル|A1\tセル|B1\n行2\tセル|A2\tセルB2';
console.log(excel2markdownWithEscaped(testWithPipe));
// ↓ 出力結果
// | 表 | 列A | 列B |
// | --- | --- | --- |
// | 行1 | セル\|A1 | セル\|B1 |
// | 行2 | セル\|A2 | セルB2 |
クリップボードについて
クリップボードの概要

Excel 表をコピーして GoogleSheets にペーストすると、書式(セルや文字の色、太字など)を含めて転写することができます。同じ表計算ソフトとはいえ、何故このようなことができるのでしょう?
それは、コピー&ペースト間にあるクリップボードの仕組みが関係しています。クリップボードは、コピー元となる表データのみを記憶しているのでなく、アプリケーション間での利用を想定して様々な形式の情報を取得しています。そしてペースト側のアプリケーションは、情報を解釈しコピー元を可能な限り再現しようと、利用できる情報を拾ってきます。
この一連の流れを図に表すと、下図のようになります。
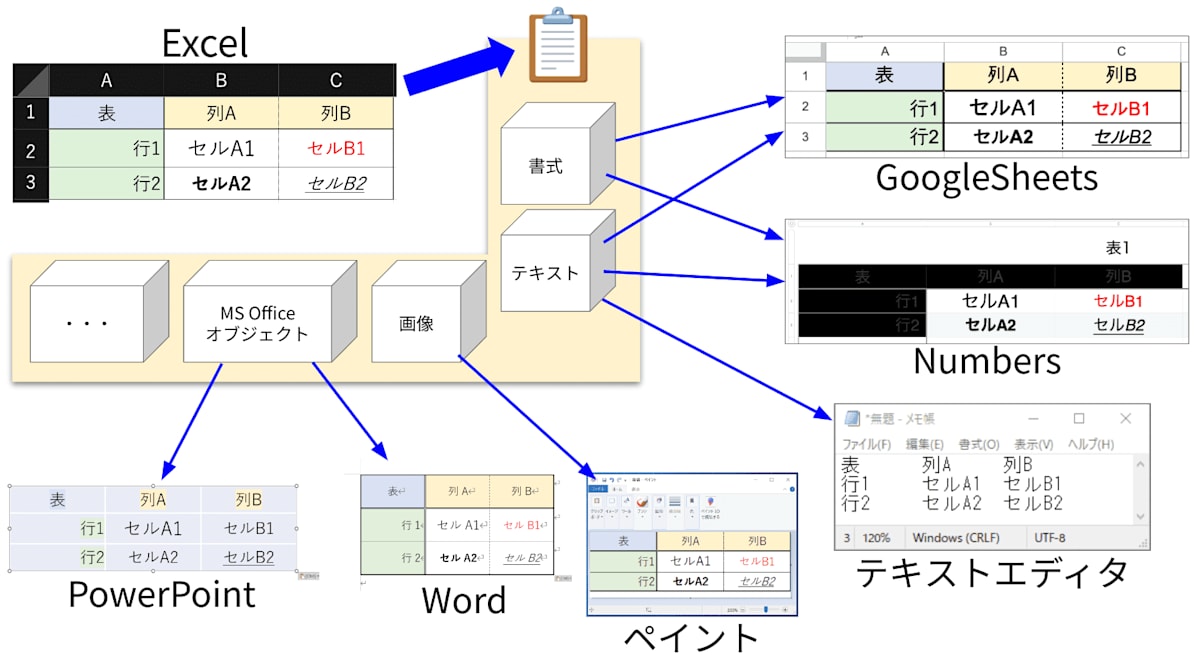
- コピー元から、様々な形式の情報を取得する
- コピー先へは、可能な限り再現しようと情報を利用する
例えば上図のように、表データをコピーしたとします。
テキストエディタにペーストする場合、テキストデータのみ転写され、書式情報や画像は利用できないため抜け落ちることになります。
一方ペイントにペーストした場合は、画像データを転写し、テキストや書式情報は扱えないため抜け落ちることになります。
そして GoogleSheets にペーストした場合ですが、まずテキストデータが転写されます。標準的な表計算ソフトは tsv( Tab-Separated Values ) がサポートされているので、コピー元と同じ行列構造で転写することができます。
更にコピー元を再現する過程で、セルの色やフォント(太字など)といった書式情報も利用可能であるため 転写されます。ただし完全にサポートされるわけではないので、場合によっては一部情報が抜け落ちることはありえます。
(上図では Numbers でセル色が変になっています。こうした場合、「プレーンテキストとして貼り付ける」「値のみ貼り付け」などで引き出す情報を絞って利用した方が良いかもしれません)
このようにデータの解釈がアプリケーション間で行われていることが、クリップボードの特徴となります。
本記事においてクリップボードはどう関わるのか?
本記事においては、tsv 形式のテキストデータのみを利用して処理をしています。Excel, GoogleSheets において表をコピーすると、タブ文字と改行コードで区切られた tsv 形式のテキストを取得できるので、これを利用して markdown テーブルに変換しています。
なお tsv 形式なら良いため、実は HTML の table 要素にも本機能が使えたりします。下図は本記事の文字列をカウントし、様々な情報を table 要素で出力しています。
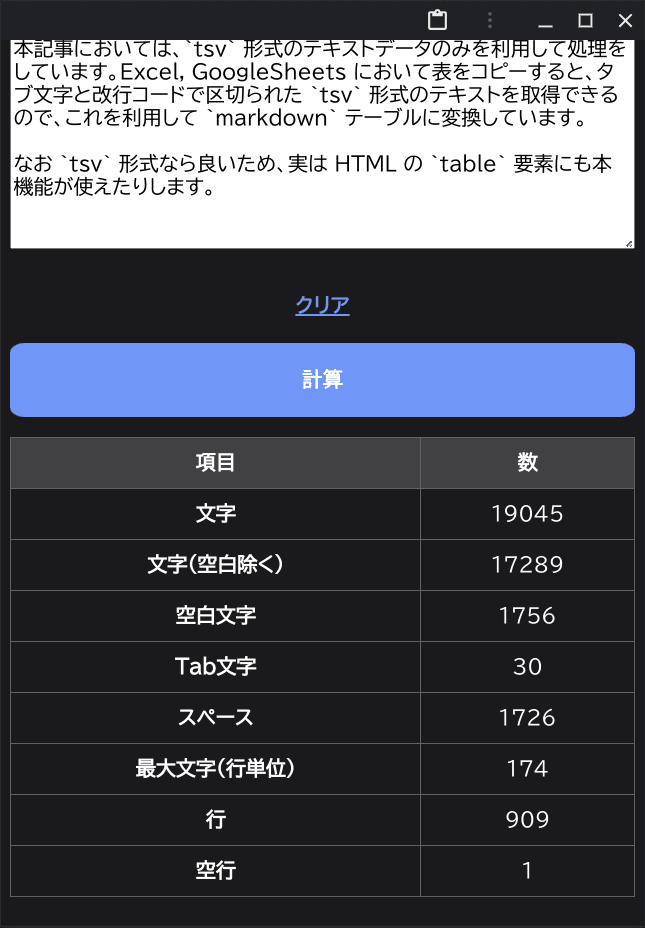
この table 要素をコピーし、本記事での処理に掛けると、問題なく markdown 形式に変換されていることがわかります。
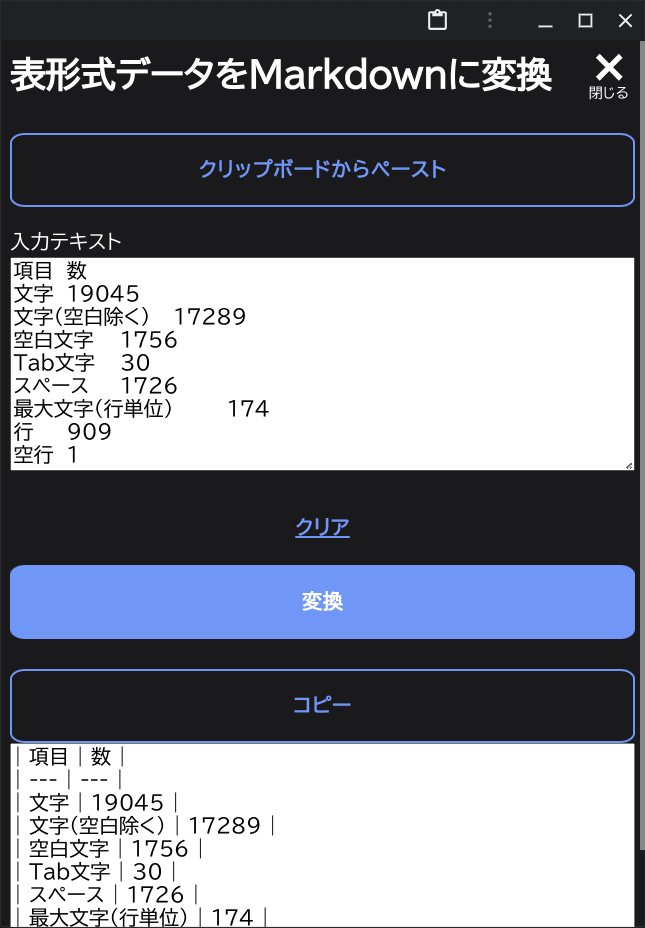
これもクリップボードが html 要素を格納するだけでなく、tsv 形式のテキストデータを取得しているからできるものだと思われます。
Discussion