DP-900: Microsoft Azure Data Fundamentals
最適化されたファイル形式
-
Avroファイル
- 各レコードには、レコード内のデータの構造を説明するヘッダーが含まれ、ヘッダーはJsonとして格納される。
- データはバイナリ情報として格納される。
- アプリではヘッダーのデータ構造の情報を使いバイナリデータを解析し、格納されているフィールドを抽出する。
- データの圧縮に優位なので、ストレージとネットワーク帯域を最小限に抑えられる。
-
ORC (Potimized Row Cllumnar)
- データは行ではなく列として構成される。
- Apache Hive での読み取りおよび書き込み操作を最適化するために開発されたもの。
※Hive:大規模なデータセットに対する高速なデータの要約とクエリをサポートするデータ ウェアハウス システム
-
Parquet
- Parquet ファイルには、行グループが含まれ、各列のデータは、同じ行グループにまとめて格納される。
- Parquet ファイルには、各チャンクに格納されている行のセットを記述するメタデータが含まれる。
- アプリでは、メタデータを使用して、特定の行セットに対するチャンクを高速に検索し、その行に対する列データを取得できる。
- 入れ子になったデータ型に効率的に格納/検索できる。
- 効率的な圧縮とエンコード処理ができる。
分析データ処理
- 履歴データまたはビジネス メトリックの膨大な量を格納する読み取り専用システムが使用される
アーキテクチャ例
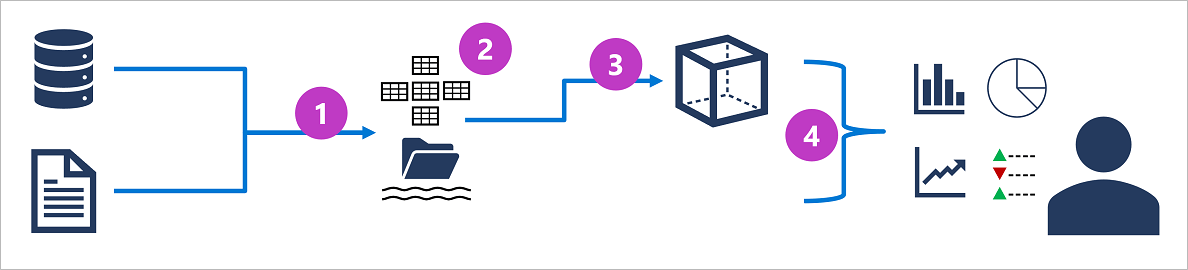
- 解析用に抽出しData Lakeに書き込み
- データウェアハウス。SQLでデータ取得可能
- データウェアハウス内のデータを集計し、オンライン分析処理(OLAP)モデルに読み込まれる。
- データレイク、データウェアハウス、分析モデル内のデータに対してクエリを実行し、レポート、視覚化、ダッシュボードを生成
OLAPモデルは、分析ワークロードに最適化された集計型のデータストレージ。複数の階層レベルで集計を表示するために "ドリル アップまたはダウン"できる。地域別、市区町別、または個々の住所の合計売上を検索する場合などで、OLAP データは事前に集計済みなので、それに含まれる概要を返すクエリをすばやく実行できる。
異なるデータステージで、データ分析を行う。
- データ レイク内のデータ ファイルを直接使用して、データの探索とモデル化を行う
- 複雑なレポートと視覚化を生成するために、データ ウェアハウス内のテーブルに直接クエリを実行する。
- レポートまたはダッシュボードの形式で、分析モデル内で事前に集計済みのデータを使用する

データサービス
Azure Data Factory
- PaaSサービス
- データを転送および変換するデータ パイプラインを定義してスケジュールを設定できるようにする Azure サービス
- パイプラインを他の Azure サービスと統合することで、クラウド データ ストアからデータを取り込み、クラウドベースのコンピューティングを使用してデータを処理し、結果を別のデータ ストアに保持できる
- 組織全体のトランザクション システムからのデータを分析データ ストアに取り込むために、 "抽出"、"変換"、"読み込み" (ETL) ソリューションを構築する目的で、使用される。
Azure Synapse Analytics
- PaaSサービス
- データ分析用
-
パイプライン
- Azure Data Factory と同じテクノロジ\
-
SQL
- 拡張性の高い SQL データベース エンジンであり、データ ウェアハウスのワークロード用に最適化
-
Apache Spark
- Java、Scala、Python、SQL を含む複数のプログラミング言語と API をサポートするオープンソースの分散データ処理システム。
-
Azure Synapse Data Explorer
- Kusto クエリ言語 (KQL) を使用して、ログおよびテレメトリ データにリアルタイムでクエリを実行するために最適化された高パフォーマンスのデータ分析ソリューション。
Azure Databricks
- 一般的な Databricks プラットフォームの Azure 統合バージョン
- Apache Spark データ処理プラットフォームと SQL データベース セマンティクスおよび統合管理インターフェイスを組み合わせて大規模なデータ分析ができる。
- データ エンジニアの観点
- 既存の Databricks と Spark のスキルを使用して、Azure Databricks に分析データ ストアを作成できる。
- データアナリストの観点
- Azure Databricks のネイティブ ノートブック サポートを使用して、使いやすい Web ベースのインターフェイスでデータのクエリと視覚化
Azure HDInsight
- Apache オープンソースのビッグ データ処理テクノロジに対して、Azure でホストされるクラスターを提供する Azure サービス
- Apache Spark - Java、Scala、Python、SQL を含む複数のプログラミング言語と API をサポートする分散データ処理システム。
- Apache Hadoop - MapReduce ジョブを使用して、複数のクラスター ノード間で大量のデータを効率的に処理する分散システム。 MapReduce ジョブは Java で記述するか、Hadoop で実行される SQL ベースの API である Apache Hive などのインターフェイスで抽象化することができます。
- Apache HBase - 大規模な NoSQL データ ストレージとクエリのためのオープンソース システム。
- Apache Kafka - データ ストリーム処理用のメッセージ ブローカー。
- データ エンジニアの観点
- Azure HDInsight を使用して、複数のオープンソース テクノロジに依存するビッグ データ分析ワークロードをサポート
Azure Stream Analytics
- リアルタイムのストリーム処理エンジン
- 入力からデータのストリームを取り込み、入力ストリームからデータを抽出して操作するクエリを適用し、分析またはさらに処理のために結果を出力に書き込む。
- データ エンジニアの観点
- 分析データ ストアへの取り込みやリアルタイムの視覚化のためにストリーミング データを取り込むデータ分析アーキテクチャに Azure Stream Analytics を組み込む
Azure Data Explorer
- Azure Synapse Analytics の Azure Synapse Data Explorer ランタイムと同じ高パフォーマンスのログおよびテレメトリ データのクエリを提供するスタンドアロン サービス
- データアナリストの観点
- Azure Data Explorer を使用して、たとえば、ログ ファイルや ''モノのインターネット'' (IoT) テレメトリ データで一般的に検出されるタイムスタンプ属性を含むデータのクエリと分析を行う
Microsoft Purview
- 企業規模のデータ ガバナンスと検出可能性を実現するソリューション
- データ エンジニアの観点
- 企業全体にわたってデータ ガバナンスを適用し、分析ワークロードをサポートするために使用されるデータの整合性を確保する
Microsoft Fabric
- オープンで管理されたレイクハウスに基づく統合されたサービスとしてのソフトウェア (SaaS) 分析プラットフォーム
- 以下の機能が含まれる。
- データ インジェストと ETL
- データ レイクハウス分析
- データ ウェアハウス分析
- データ サイエンスと機械学習
- リアルタイム分析
- データのビジュアル化
データ ガバナンスと管理

AzureのSQLサービス
VM上のSQLServer
- SQL ServerがインストールされたVMマシン
- オンプレのSQL Serverを "Lift&Shift" する際の選択肢
- ハイブリッドデプロイでも有効な選択肢。
Azure SQL Managed Instance
- オンプレで稼働するSQL Serverをほぼ100%の互換性を提供するPaaSサービス
- ソフトウェアの更新管理、バックアップ、その他メンテナンスタスクが含まれているため、管理負担が軽減される。
- 各種機能は、他のAzureサービスと連携する。
- バックアップでは Azure Storage
- テレメトリでは Azure Event Hubs
- 認証では Microsoft Entra ID
- Transparent Data Encryption (TDE) では Azure Key Vault
- 通信はすべて暗号化され、証明書を使って署名される。証明書が失効している場合、マネージド インスタンスではデータを保護するために接続が終了する。
Azure SQL Database
- クラウド向けに設計されたフルマネージドの拡張性の高いPaaSサービス
- オンプレで稼働するSQL Serverのコア機能が含まれている。
- クラウドで新しくアプリケーションを作成する場合に適したサービス。低コストで管理の最小化が可能。
- オンプレミスのSQL Serverとの完全な互換性はない
- Azure SQL Database は、Single Database または Elastic Pool として使用できる。
- Single Database
- 単一のSQL Serverデータベースを設定実行できる
- DBは自動的にスケーリングされ、必要に応じてリソースが割り当て/割り当て解除される
- Elastic Pool
- 複数のデータベースが同じリソース(メモリ、ストレージ、CPU)をマルチテナントで共有できる。
- 時間経過とともに、複数のデータベースの使用頻度が大きく変わる場合に役立つ。
- Single Database
Azure SQL Edge
- 時系列のストリーミングデータを操作する必要がある、IoTシステム向けに最適化されたSQLエンジン
オープンソースベースのデータベース
Azure Database for MySQL
- MySQL Community Editionに基づく、PaaSサービス
- 従量課金制なので使用した分だけ支払う
Azure Database for MariaDB
- MariaDBデータベースのPaaS
※MariaDBの特徴
- MariaDBはOracleDatabaseと互換性がある。
- 一つのテーブルに複数のバージョンを保持できる
Azure Database for PostreSQL
- PostreSQLのPaaS
- デプロイオプション フレキシブルサーバはマネージドで、コストの最適化制御が提供される。

Azure DataLake Storage Gen2
-
Azure Storage に統合された分析データレイク用の階層データを格納するためのサービス
-
Blob Storageのスケーラビリティとストレージ層のコスト制御を活用しつつ、階層ファイルシステムやAzure Data Lake Storeの主要な分析システムとの互換性もある。
-
Hadoop in Azure HDinsight、Azure Databricks、Azure Synapse Analyticsなどのシステムで、Azure Data Lake Store Gen2の分散ファイルシステムをマウントし、膨大な量のデータを処理できる。
-
作成するには、Azure Storageにある階層型名前空間のオプションを有効にする。
※既存のストレージアカウントをアップグレードできるが、戻すことはできない。

データウェアハウスのアーキテクチャ

-
データインジェストと処理
- データストア、ファイル、リアルタイムストリームなどから、データレイク/RDBに取り込む。
- 取り込む際には、ETL(抽出→変換→取込)またはELT(抽出→取込→変換)プロセスがあり、それによりデータは分析用にクリーンアップ、フィルター、再構築される。
- データ処理は、マルチノードクラスターを使用して大量データを並列処理できる分散システムで実行される。
-
分析データストア
- 大規模な分析用のデータストアには、以下の3つがある。
- リレーショナルな"データウェアハウス"、
- ファイルシステムベースの"データレイク"、
- データウェアハウスとデータレイクの機能を組み合わせたハイブリッドアーキテクチャ(データレイクハウス、レイクデータベース)
- 大規模な分析用のデータストアには、以下の3つがある。
-
分析データモデル
- 分析データをレポート、ダッシュボード、視覚的に生成できるように、データを事前に集計するデータモデルを作成する。
-
データの視覚化
- レポート、ダッシュボード、視覚エフェクトを作成する。
データインジェクションパイプライン
複数のソースから分析ストアにデータを入れる方法について。
- Azure Data Factoryを使ってデー変換パイプラインを作成する
- 統合ワークスペースでデータ分析ソリューションのすべてのコンポーネントを管理する場合は、Azure Synapse Analytics または Microsoft Fabricを使う。
分析データストア
データウェアハウス
- トランザクションワークロードではなく、データ分析用に最適化されたスキーマに格納するRDB
データレイクハウス
- ファイルストア
- 分散ファイルシステムでハイパフォーマンスにデータアクセスする。
- 格納ファイルにクエリし、レポートや分析データを使うために、SparkやHadoopがよく使われる。
- スキーマ オン リード アプローチを適用して、データを分析のために読み取る時点で半構造化データ ファイルに対して表形式スキーマを定義する。格納時には制約はない。
- ストアへのデータ書き込み時にスキーマを適用する必要なく分析対象の構造化データ、半構造化データ、非構造化データの組み合わせをサポートするために最適
レイクハウスとウェアハウスのハイブリッド
- データ レイクに生データがファイルとして格納され、基になるファイルがリレーショナル ストレージ レイヤーで抽象化されて、テーブルとして公開される。
Azure Synapse Analytics
これにより、データ レイク (および他のソース) 内のファイルに基づいて外部テーブルを定義し、それらに対して SQL を使ってクエリを実行できる。
Lake Database アプローチもサポートされています。これは、データベース テンプレートを使用してデータ ウェアハウスのリレーショナル スキーマを定義し、基になるデータを Data Lake Storage に格納することで、データ ウェアハウス ソリューションのストレージとコンピューティングを分離できる
分析ストアのPaaS 3つ
Azure Synapse Analytics
- スケーラブルでハイパフォーマンスなSQL ServerベースのRDBデータウェアハウスに備わる整合性と信頼性を持つ
- データレイクとオープンソースApache Sparkの柔軟性を持つ
- Azure Synapse Data Explorer プールを使用したログ/テレメトリ分析と、データインジェクトと変換のためのデータパイプラインがある
Azure Databricks
- Azure Spark上に構築されたデータ分析ソリューション
- SQL機能、データ分析とデータサイエンスのために最適化されたSparkクラスタ
- Databricksは複数のクラウドプラットフォームで使われているので、マルチクラウドでの運用が必要な場合や移植可能性がある場合に役立つ
Azure HDInsigth
- オープンソール データ分析クラスターの種類を複数サポートするサービス
- 分析ソリューションが複数のオープンソースフレームワークに依存している場合に役立つ
- 既存のオンプレミスHadoopベースソリューションをクラウドに移行する場合に役立つ
Microsoft Fabric
統合されたSaaSで、すべてのデータがOneLakeにオープン形式で格納される。
さまざまなサービスを組み合わせて、ビジネスユーザに提供するインターフェースを実装する必要がなくなる。
- OneLakeは、データエンジニアとビジネスユーザがデータプロジェクトで共同作業するための統合環境。
- データ用のOneDrive
- データを移動/複製することなく、異なるリージョンとクラウド間のストレージの場所を一つの論理Lakeにまとめる。
- データは任意のファイル形式でOneLakeに保存でき、構造化にも飛行増加にもできる
- 表形式の場合、Fabricの分析エンジンはOneLakeに書き込むときにデータをデルタ形式で書き込む。
- どのエンジンによって書き込まれるかに関係なく、すべてのエンジンはその形式を読み取る方法と、デルタファイルをテーブルとして扱うと認識する。
バッチ処理とストリーム処理を組み合わせた大規模なデータ分析アーキテクチャ
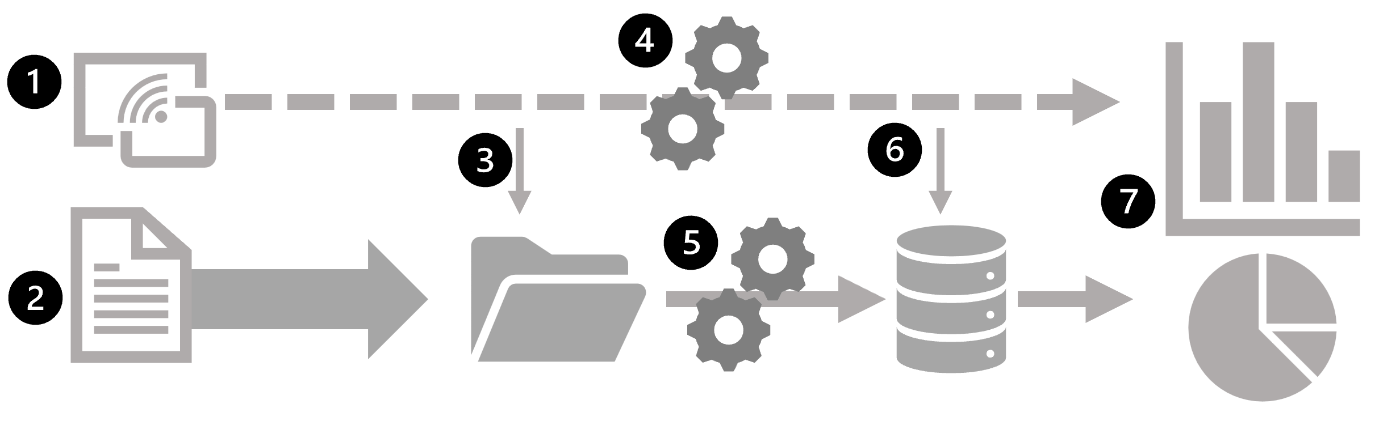
- ストリーミングデータをリアルタイムでキャプチャ
- ストリーミング以外のデータはバッチ処理のためにデータストア(データレイク)に取り込み
- リアルタイム分析が必要ない場合は、ストリーミングデータをデータストア(データレイクに取り込み)
- リアルタイム分析が必要な場合は、ストリーム処理でリアルタイム分析/BIのためのデータを準備。一定期間のデータがフィルター処理または集計される
- 非ストリーミングデータは、定期的にバッチ処理され、分析のために分析データストア(データウェアハウス)に保管される。
- ストリーム処理の結果も、分析のための分析データストアに保持
- 分析ツールとBIツールを使い、リアルタイムデータと履歴データを表示
ストリーム処理のアーキテクチャ

- ストリームデータ生成
- ストリーミングサービスにキャプチャされる。例)データストア内のフォルダやデータベース内のテーブル。イベントデータを順番に処理するために、キューが使われる場合もある
- イベントデータをフィルタしたデータ(特定イベント、時間など)で集計
- シンク(ファイル、データベーステーブル、キュー)などに書き込まれる。
Azureでのリアルタイム分析
-
Azure Stream Analytics
- PaaS
- ストリーミングジョブを定義する
- ストリーミングデータを取り込み、連続的にクエリを適用し、結果を出力に書き込む
-
Spark Structured Streaming
- オープンソースのライブラリ
- Azure Syanpse Analytics、Azure Databricks、Azure HDInsightなどのAzure Sparkベースのサービスで複雑なストリーミングソリューションを開発できる
-
Azure Data Explorer
- 時系列要素を持つバッチまたはストリーミングデータを取り込んでクエリするために最適化されている。
- スタンドアロンのAzureサービスとしても利用可能。Azure Synapse AnalyticsワークスペースのSynapse Data Explorerランタイムとしても利用できる。
ストリーム処理のソース
-
Azure Event Hubs
- イベントデータのキューを管理するためのサービス。
- イベントが順番に1回だけ処理されることが保証される
-
Azure IoT Hub
- IoTデバイスからのイベントデータの管理に最適化されたサービス
-
Azure Data Lake Storage Gen2
- バッチ処理のシナリオでよく使われるが、ストリーミングデータのソースとしても利用可能
-
Apache Kafka
- Apache Sparkと主に使用されることが多い。
- Azure HDInsightを使ってKafkaクラスターを作成できる
ストリーム処理のシンク(出力先)
-
Azure Event Hubs
- ダウンストリームでさらにストリーム処理をするために、キューに格納する
-
Azure Data Lake Store Gen 2 、 Azure Blob Storage
- 処理された結果をファイルとして保持する
-
Azure SQL Database、Azure Synapse Analytics、Azure Databricks
- クエリと分析のために処理された結果をデータベーステーブルに保持する
-
Microsoft Power BI
- レポートとダッシュボードでリアルタイムにデータを可視化する
Azure Stream Analytics
- ストリーミングデータのイベント処理と分析のためのサービス
- Input
- Azure Event Hub、Azure IoT Hub、Storage Blobコンテナなど
- データ処理
- Output
- Azure Data Lake Gen2、Azure SQL Database、Azure Synapse Analytics、Azure Functions、Azure Event Hub、Power BIなど
Azure Stream Analytics ジョブとクラスタ
ストリーム処理が複雑ではない場合
- Stream Analyticsジョブを作成し、そのInputとOutputを構成し、ジョブでデータ処理に使用するクエリを定義する。
ストリーム処理が複雑な場合 / リソースを短時間で消費する場合
- Stream Analytics クラスターを作成する。
- クラスターはStream Analytics ジョブと同じ処理エンジンを基盤としている。
- 専用テナントにあるので、他ユーザの影響を受けない。
- スループットとコストを定義できるスケーラビリティがある。
Apache Spark
- Apache Spark は大規模なデータ分析のための分散処理フレームワーク
- Azureでは以下のサービスで利用できる
- Azure Synapse Analytics
- Azure Databricks
- Azure HDInsight
Spark Structured Streamingライブラリ
-
Spark でストリーミング データを処理するには、Spark Structured Streaming ライブラリを使用する。
-
データの連続的なストリームを取り込み、処理し、結果を出力するためのAPIが提供されている。
-
ストリーミング データを Spark ベースのデータ レイクや分析データ ストア内に組み込む必要がある場合には、Spark Structured Streaming がリアルタイム分析のための最適な選択肢。
-
データのテーブルをカプセル化する、"データフレーム" と呼ばれる Spark のユビキタス構造を基にして構築されている。

- Spark Structured Streaming API を使用して、Kafka ハブ、ファイル ストア、ネットワーク ポートなどのリアルタイム データ ソースから、ストリームからの新しいデータが継続的に設定される "境界のない" データフレームに、データを読み取る。
- データフレームに対して、データの選択、プロジェクション、または集計を行うクエリを定義。
- クエリの結果によって別のデータフレームが生成され、分析または追加の処理のためにそれを保持できる。
Delta Lake
-
Delta Lake はオープンソースのストレージ レイヤー
-
トランザクションの整合性、スキーマの適用、その他の一般的なデータ ウェアハウス機能のサポートを、データ レイク ストレージに追加する。
-
ストリーム処理に使用するときは、Delta Lake テーブルを、リアルタイム データに対するクエリ用のストリーミング ソース、またはデータのストリームが書き込まれるシンクとして使用できる。
-
Azure Synapse Analytics と Azure Databricks の Spark ランタイムには、Delta Lake のサポートが含まれる。
-
Delta Lake と Spark Structured Streaming の組み合わせは、SQL ベースのクエリや分析のためのリレーショナル スキーマの背後にあるデータ レイクで、バッチおよびストリーミング処理されたデータを抽象化する必要がある場合に最適なソリューション。
Microsoft Fabric のリアルタイム分析
- 複数のストリーミング ソースからのリアルタイム データ インジェストなど、リアルタイム データ分析のネイティブ サポートが含まれる。

- eventstream を使用してストリーミング ソースからリアルタイムのイベント データを取得し、レイクハウスまたは KQL データベースのテーブルなどの宛先に保持できる。

Microsoft Power BI

- データ視覚化ソリューションを作成する典型的なワークフローは、 Power BI Desktop が出発点
- データ モデルとレポートを作成したら、レポートをパブリッシュしたり、ビジネス ユーザーが対話することができる Power BI サービスというクラウド サービスにそれらをパブリッシュする。
- Web ブラウザーを使用して、このサービスでデータの基本的なモデリングとレポート編集を直接行うこともできますが、これの機能は Power BI Desktop ツールと比較して制限がある。
データモデリングの主要概念
- データを構造化する。
- 分析またはレポート対象である数値(メジャー)
- それらを集計するエンティティ(ディメンション)
- (例)顧客別の合計収益を識別 / 1か月あたりの製品別に販売された商品の合計
- 数値メジャー:売上
- ディメンション:製品、顧客、時間
- モデルは多次元になる。
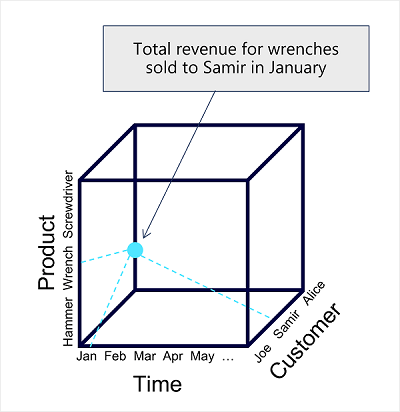
テーブルとスキーマ
- ディメンションテーブルは、数値メジャーを集計するためのエンティティを表す。
- 各エンティティは、一意のキー値を持つ行が格納される。
- 多くの分析モデルは、「時間」ディメンションを持つテーブルを軸に、関連するテーブルを紐づけ、数値メジャーを集計できるようにする。

Microsoft Power BI での分析モデリング
- 1 つ以上のデータ ソースからインポートできるデータのテーブルから分析モデルを定義できる。
- Power BI Desktop の [モデル] タブのデータ モデリング インターフェイスを使用して、分析モデルを定義する。
