Azure Solutions Architect Expert
Azure Storage
Azure Blob Storage(Binary Large Object)
- 大量の非構造化データ(画像やマルチメディア ファイルなど)
- Premium ブロック BLOb
- 高トランザクションが必要なアプリ向け。
- Premium ページ Blob
- OS、VMのデータディスク、データベースのようなインデックスベースのデータ構造を格納するのに適している。
アクセス層
- Premium Blob Storage > ホットアクセス層 > クールアクセス層 > アーカイブアクセス層
この順番でアクセスコストが低く、ストレージコストが高い。データの用途で使い分ける。
不変ストレージ
- WORM(Write Once, Read Many)状態でデータを格納できる。
- 時間ベースの保持ポリシー
- 保存ポリシーが設定されている場合、オブジェクトの作成と読み取りはできるが、変更または削除ができない。 保存期間の期限が切れたオブジェクトは削除はできるが上書きはできない。
- ホット、クール、アーカイブのアクセス層に設定可能。
- 訴訟ホールドポリシー
- 解除されまで不変データが保存される。オブジェクトの作成と読み取りは可能だが、変更と削除はできない。Premium Blob Storageで設定可能。
Azure Files
- SMBプロトコル、NFSプロトコル、RESTAPIを使ってアクセス
- Premium ファイル共有
- エンタープライズまたはハイパフォーマンススケールアプリで使う。
会社の既存のオンプレミス ネットワーク接続ストレージ (NAS) デバイスまたはファイル サーバーを追加したり置き換えたりできる。
ファイルを Azure Filesに移す方法は二つ。
- Azure ファイル共有の直接マウント(SMBプロトコル)
- Azure File Sync を使ってオンプレミスに Azure ファイル共有をキャッシュする
ストレージ層
- Premium(SSD) > トランザクション最適化(HDD) > ホットアクセス層(HDD) > クールアクセス層(HDD)
この順にパフォーマンスが高く、コストが低い。
Azure Managed Disk
- AzureVMのディスク
- Ultra Disk > Premium SSD > Standard SSD > Standard Hdd
この順にスループットと最大IOPSが高く、料金が高い。 - データキャッシュを使い、パフォーマンスを向上できる。OSディスクの場合の規定のキャッシュ設定はReadWrite、データディスクの場合の規定値はReadOnly
Azure Queue Storage
- キューによる非同期処理で使う。
RDB用データストレージソリューション
Azure SQL データベース
OS と SQL Server インスタンスの両方がユーザーから抽象化されたフルマネージドなPaaSサービス。
- 高可用性、チューニング、バックアップの構成と管理などをする必要がない。
- 最新バージョンの SQL Server を実行するように各 SQL データベースを自動的にアップグレードする。
SQL Database エラスティック データベース プールを使用して、エラスティックデータベースプール内のすべてのSQLデータベース間で共有するコンピューティングリソースとストレージリソースのセットを支払う。
価格オプション
- 仮想コア
- 仮想コア数を選択して、コンピューティングコストを制御できる。SQLServerと予約容量のハイブリッド特典が利用可能。
- 複数のSQLデータベースまたはエラスティックデータベースプールに対して、コンピューティングリソースとストレージリソースを個別に設定。
- DTU
- コンピューティング、ストレージ、I/Oリソースを組み合わせたオプション。事前構成済みのシンプルなオプション。
- Azure SQL Managed Instanceでは使用できないプラン。
- サーバレス
- SQLDatabaseの単一データベースのコンピューティングレベル。ワークロードの需要に基づいて自動でスケーリング。使用したコンピューティング量に対してのみ請求。
Azure SQL Managed Instance
PaaSのフルマネージドサービス。SQLServerのインスタンスが提供される。
- アプリ再設計をする必要なく、オンプレからAzureへのリフト&シフトが可能。
- SQL Serverエージェント、共通言語ランタイム、などのインスタンス機能を使い場合に有効
- 仮想コアモードで動く。マネージドインスタンスに割り当てられる最大CPUと最大ストレージを定義する。
- SQL Serverで利用できる機能のほとんどはSQL Managed Instanceでも利用可能。
Azure VM上のSQL Server
オンプレのマシン不要でSQLServerをクラウドで利用可能。自前でSQLServerを立ててすべての機能が使えるため、カスタマイズしたい場合に有効。
- 仮想マシンに対して、SQLServerの自動管理機能を使用できる。
#Azure SQLのデプロイオプション比較
| SQL Database | SQL Managed Instance | SQL Server on AzureVM |
|---|---|---|
| 単一データベース | 単一インスタンス | AzureVM |
| エラスティックプール(複数データベース間のリソース共有、複数データベースに対するパフォーマンス管理) | インスタンスプール(コスト効率の高い以降) | - |
| フルマネージド | フルマネージド | - |
Azure SQL Edge
IoTやIoT Edge向けに最適化されたRDPエンジン。
- コンテナ化されたLinuxアプリケーション。
デプロイオプション
- 接続されたデプロイ:Azure IoT Edgeのモジュールとしてデプロイ。
- 非接続のデプロイ:Azure SQL Edgeのコンテナイメージを実行。DockerHubからPullして、スタンドアローンのDockerコンテナ/Kubernetesクラスタとしてデプロイ。
ポイント
- ネットワーク接続の有無にかかわらず機能するソリューションがある
- 接続速度が遅い場合や断続的な接続の問題がある場合は、ローカル データベースを使う。クラウドベースのデータベースにすべてのデータを転送する必要がなく、待機時間が発生しない
- Azure SQL Edge には、RBAC および ABAC、暗号化、データ分類が実装されているため、IoT アプリ データへのアクセスをセキュリティで保護できる。
RDBソリューションの非機能ソリューション
動的スケーラビリティ
最小限のダウンタイムで、CPU パワー、メモリ、I/O スループット、ストレージなど、データベースに割り当てられたリソースを簡単に変更できる。
- DTUまたは仮想コアモデルで割り当て最大量を定義
- エラスティックデータベースプールを使用して最少と最大のリソース制限を設定
- 垂直方向のスケーリング
- 理想的な動的スケーリング ソリューションは、垂直方向のスケーリングで SQL エラスティック データベース プールを使用すること。

- 理想的な動的スケーリング ソリューションは、垂直方向のスケーリングで SQL エラスティック データベース プールを使用すること。
- 水平歩行のスケーリング
- シャーディングを使用してデータをパーティションに分割するか、スケールアウトプロビジョニングを読み取って水平方向のスケーリングを適用
可用性
サービスレベル「General Purpose」の可用性
価格モデル「仮想コア」の高可用性について。

フェールオーバする場合の動き
- 予備容量があるノードに、SQLServerインスタンスを起動
- データベースファイルとアタッチし、バックアップファイルを使い復旧
- 新しいノードに接続するようにゲートウェイを更新
サービスレベル「Business Critical」の可用性
Business Criticalは、すべてのAzureSQLサービスの中で最高レベルのパフォーマンスと可用性。

- データとログファイルはすべてSSD
- 3つのセカンダリレプリカを持つ。
サービスレベル「Hyperscale」の可用性
※Azure SQL Databaseでのみ使用可能なサービスレベル
キャッシュとページサーバの層を使い、データファイルに直接アクセスしないため、高速。

- コンピューティングとページサーバのセットが水平方向にスケーリングして、すべてのデータをキャッシュ レイヤーに配置する。
- データベースの復元は数分で完了。
- 一定の時間でスケールアップ/スケールダウン可能
まとめ
| SQL Databaseの仮想コアレベル | SQL Managed InstanceのDTUレベル | データベース可用性サポート |
|---|---|---|
| 汎用 | Standard/Basic | コスパ良い |
| Business Critical | Premium | パフォーマンスが高く、可用性は最も高いオプション |
| Hyperscale | なし | スケーリング可能。読み取りパフォーマンスが最も高い |
暗号化方法
| データの種類 | 暗号化方法 | 暗号化レベル |
|---|---|---|
| 保存データ | Transparent Data Encryption (TDE) | Always Encrypted |
| 移動中のデータ | Secure Socket Layer または Transport Layer Security (SSL/TLS) | Always Encrypted |
| 処理中のデータ | 動的データ マスク | 特定のデータは暗号化されず、残りのデータは暗号化されます |
- 動的マスキング:データベース内のデータは変更せず、クエリの結果セットで機密データを非表示にできる。
Azure Cosmos DB と Table Storage
- Azure Cosmos DB では、数ミリ秒 (1 桁台) の応答時間に対応し、あらゆるスケールで速度が保証される。
- Azure Table Storage 向けに作成されたアプリケーションは、ほとんどコードを変更せずに Azure Cosmos DB Table API に移行できる。
- Azure Cosmos DB Table API と Table Storage は同じテーブル データ モデルを共有しており、SDK を介して同じ作成、削除、更新、クエリ操作が可能
データ統合
Azure Data Factory を使用したデータ統合ソリューション
- データ移動し、大規模にデータを変換できる
- データドリブン ワークフロー、または、パイプラインは、異種データ ストアからデータを取り込む
- ETL (抽出、変換、読み込み) データ統合プロセス。複数のデータ ソースのデータを 1 つのデータ ストアに結合できる
データドリブン ワークフロー
以下の手順。

- データを取り込んで、さまざまなソースからすべてのデータを一元化された場所に収集
- Azure Databricks や Azure HDInsight Hadoop などのコンピューティング サービスを使用してデータを変換
- GitHub とAzure DevOps を使って CI/CD をサポートし、ETL プロセスを実行し、データを分析エンジンに発行
- Azure portal を使用して、スケジュールされたアクティビティとすべてのエラーについてパイプラインを監視
データ移動とデータ統合のためのコンポーネント

- データセットはデータ ストア内のデータ構造
- アクティビティはパイプライン内の単一の処理ステップ
- パイプラインはタスクを実行するアクティビティの論理的なグループ
- リンクサービスはAzure Data Factory から外部リソースに接続するために必要な必須接続情報を定義
- データ フローでコードを記述せずにデータ変換ロジックを開発
- 統合ランタイムは、アクティビティとリンク サービスの間のブリッジ
Azure Data Lakeを使用したデータ統合ソリューション
ビッグ データの分析用に Azure に組み込まれている、包括的で拡張性があり、コスト効率に優れたデータ レイク ソリューション。
Azure Blob Storage 機能を基に構築されている。BlobStorageの課金体系なので、大量データでも料金が抑えられる。
特徴
- Azure Data Lake Storage では、任意のデータ形式と大規模なデータ サイズをサポートし、構造化データ、半構造化データ、非構造化データを処理できる
- 主に Hadoop と、Apache Hadoop 分散ファイル システム (HDFS) をデータ アクセス層として使用するすべてのフレームワークと連携するように設計されている。
しくみ
- データを取り込む。

- BlobStorageにデータを入れるのと同じで、AzCopy、Azure CLI、PowerShell、Azure Storage Explorerを使える。
- RDBの場合はAzure Data Factoryを使える。Azure Cosmos DB、SQL Database、Azure SQL マネージド インスタンスなど、任意のソースからデータを転送できる
- 格納データにアクセス
- Azure Storage Explorerを使う。PowerShell、Azure CLI、HDFS CLI、言語SDKでアクセスも可能
- アクセス制御を構成。
- Azure RBAC または ACLでユーザ認証。
Azure Databricksを使用したデータ統合と分析ソリューション
フル マネージドでクラウドベースのビッグ データおよび機械学習プラットフォーム。
仕組みはApache Spark に基づいている。
仕組み
- コントロール プレーン
- Databricks のジョブ、ノートブックとクエリ結果、およびクラスター マネージャーをホストする。Web アプリケーション、Hive メタストア、およびセキュリティ アクセス制御リスト (ACL)、ユーザー セッションもある。
- 利用者の Azure サブスクリプション内には存在しない
- データ プレーン
- ワークスペース内でホストされている Azure Databricks ランタイム クラスターがすべて含まれる。
- 利用者のAzureサブスクリプションに存在する。
Azure Databricks でデータ集中型アプリケーションを開発するための環境
- Databricks SQL
- SQLクエリをデータレイクに対して実行するアナリストのためのプラットフォーム
- Databricks Data Science & Engineering
- データ エンジニア、データ サイエンティスト、機械学習エンジニアの間のコラボレーションを可能にする対話型のワークスペース
- Databricks Machine Learning
- 統合型でエンドツーエンドの機械学習環境
Azure Synapse Analyticsを使用したデータ統合と分析ソリューション
ビッグ データ分析、エンタープライズ データ ストレージ、データ統合の機能がある。サーバーレス データや大規模なデータに対してクエリを実行できる。
特徴 超並列処理 (MPP) アーキテクチャ
- 1つのコントロールノードと複数のコンピューティングノード。

コンポーネント
- Azure Synapse SQLプール
- 予測可能なパフォーマンスがわかる場合は専用SQLプール
- 予測不可能な場合はサーバーレスSQLプール
- Azure Synapse Sparkプール
- データを処理するサーバのクラスター(Python, Scala, SQL, C#)
- Azure Synapse パイプライン
- Azure Data Factoryの機能。データの移動と変換を行うデータドリブンなワークフロー
- Azure Synapse Link
- CosmosDBに接続可能
- Azure Synapse Studio
- Synapse Analyticsのすべての機能の作業を行う
Azure Data Factory か Azure Synapse Analyticsか
| 項目 | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| データ共有 | 異なるデータ ファクトリ間でデータを共有できる | サポートなし |
| ソリューション テンプレート | ソリューション テンプレートが Azure Data Factory テンプレート ギャラリーで提供 | ソリューション テンプレートが Synapse ワークスペース ナレッジ センターで提供 |
| 統合ライフサイクル管理ツール | リージョン間データ フローがサポート | サポートなし |
| データの監視 | Azure Monitor と統合 | 診断ログを Azure Monitor で利用できる |
| データ フローについて Spark ジョブを監視する | サポートなし | Synapse Spark プールを使用してデータ フローについて Spark ジョブを監視 |
ホット、ウォーム、コールド データ パス
ウォーム データ パス
Azure Stream Analyticsでシステム内を流れるデータを分析可能。
(例)IoT データから分析情報の抽出。
コールド データ パス
時間経過に伴うパターンを検出するためのストリーム処理をする。過去のある期間の使用率を計算する場合もある。
大量の非構造化データを格納するには、Blob Storage、Azure Files、または Azure Data Lake Storage Gen2 が最適なオプション
(例)Web サイトの対話式操作に関する機械学習モデルを時系列で構築する必要があるシナリオ。データ移動を自動化し、データ変換を実行する必要がある。Azure Data Factoryを使う。Azure HDInsight Hadoop、Azure Spark、Azure Databricks などのサービスを使用して、データを処理および変換できる。
ホット データ パス
リアルタイムでデータを処理または表示する。
(例)顧客ポータルのデータ分析。
Azure Stream Analytics ソリューションでデータ分析
Azure Stream Analytics は、フル マネージド でリアルタイム分析を行う複雑なイベント処理エンジン。
IoT デバイス データ、センサー、クリックストリーム、ソーシャル メディア フィードなどのソースからの複数のデータ ストリームに対してリアルタイム分析を実行できる。
機能
- Azure Event Hubs、Azure IoT Hub、Blob Storageからのデータを取り込む。
- Azure Blob Storage、Azure SQL Database、Azure Data Lake Store、Azure Cosmos DBにデータを出力
- Azure Synapse AnalyticsなどのData Warehouseにデータを格納し、機械学習モデルのトレーニング、一括分析を実行
- Azure Functions や Service Busトピック、Queueなどにデータを送信して、ダウンストリームのカスタムワークフローをトリガー可能
- PowerBIにデータを送信してリアルタイムで可視化可能
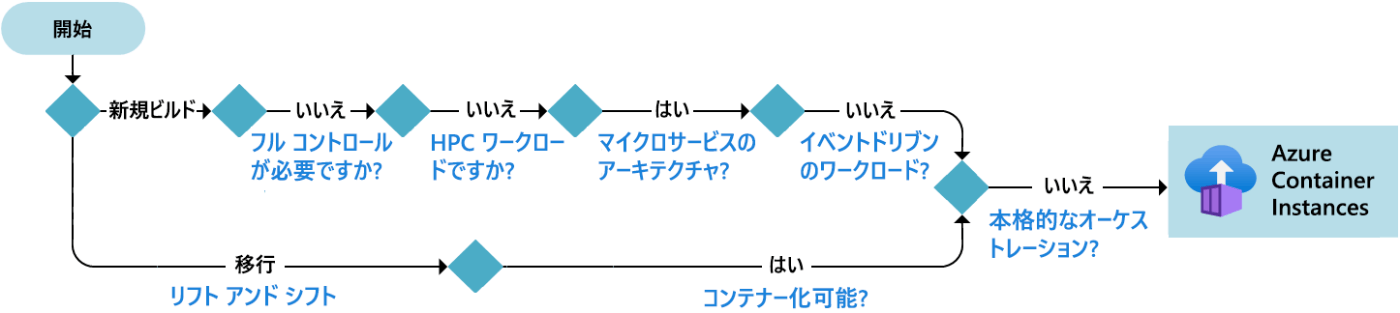
Azure コンピューティング サービスを選ぶ際の考慮事項
ワークロードとアーキテクチャ
- コントロール:インストールされているソフトウェアとアプリケーションを管理する必要があるか。
- ワークロード:HPCワークロードやイベントドリブンワークロードなど。
- アーキテクチャ:マイクロサービス、オーケストレーション、サーバレスなど。
オンプレミスからの移行
- クラウド最適化:クラウドネイティブにアプリをリファクタリングし、クラウド最適化されたコンピューティングサービスを利用する。
- リフトアンドシフト:アプリケーションの再設計やコード変更を必要としないコンピューティングサービスを利用する
- コンテナ化:コンテナ化されたアプリケーションをサポートする必要があるか。
ホスティング
ホスティング オプションによって、開発者とクラウド プロバイダーの責任が決まる。

意思決定ワークフロー

Azure Batch ソリューションの設計
大規模なアプリケーションをクラウドで効率的に実行する。インフラを管理せずにソリューションのリソースを動的に調整できる。
コンピューティング ノード (仮想マシン) のプールを作成して管理できる。 また、実行するアプリケーションをインストールし、コンピューティング ノードで実行するようにジョブをスケジュールすることもできる。

仕組み
データとアプリケーションのファイルをStorageAccountにアップロードし、Windows/Linuxの必要な数のノードを含むBatchプールを作成する。ノードのスケーリングも可能。

ポイント
- プール
- ジョブが短時間の場合、プールの作成がオーバーヘッドになりやすいため、短時間のジョブ群で同じプールを使用する。
- ノード
- ノードのスケーリングをリアルタイムにしたい場合、分離された仮想マシンサイズにする。個々のノードが常に使用可能であるとは限らないため
- ジョブ
- 監視のために、ジョブに一意の名前を付ける。タスクのまとまりをジョブにすること。(例)10個のタスクを含むジョブを100個作成するのではなく、1000個のタスクを含むジョブを1つ使用するほうが効率的。
Azure App Service
Webアプリケーションに最適なコンピューティングソリューション

- 組み込みの認証と認可の機能(EasyAuth)が用意されている。 ユーザーのサインインとデータへのアクセスを、コード実装を最小限/なしで実現できる。
CD
Azure DevOpsからアプリケーションのビルドとデプロイを行える。デプロイスロットを使って、デプロイされたプライマリスロットを運用スロットとスワップする。
Azure Container Instances
リフト アンド シフト パターンを使用ししてデータを移行するのにも最適なコンピューティング ソリューション
- コストが発生するのは利用コンテナが実行されている間のみ。
- Azure Files 共有をコンテナーに直接マウントすることで、状態を保持できる。
- Linux と Windows で使用できる。
コンテナー グループ
Azure Container Instances の最上位の概念。コンテナー グループ内のコンテナーでは、ライフサイクル、リソース、ローカル ネットワーク、ストレージ ボリュームを共有する。
Azure Kubernetes Service
AKSを使うシーン

AKSを使うかどうか判断するポイント
| 機能 | 観点 | Kubernetesによるサービス |
|---|---|---|
| IDとセキュリティ管理 | すでにAzureリソースを使用していて、EntraIDを使用しているか。 | AKSはEntraIDと統合して、IDのグループも使用できる |
| ログと監視 | AzureMonitorを使用しているか | AzureMonitorクラスターのパフォーマンスを可視化できる |
| ノードとPodの自動スケーリング | 大規模なコンテナ化環境をスケールする必要があるか | Podの水平オートスケーラーでは、Podのリソース需要に合わせてPodを増やせる。クラスターオートスケーラー では、スケジュールされたPodをデプロイするためにノードが自動的にスケーリングされる。 |
| クラスターのアップグレード | クラスタ管理運用を減らしたいか | ノードを切断/ドレインするプロセスが管理されて、Kubernetesのアップグレードされる。 |
| ボリュームストレージのサポート | アプリケーションに永続化されたストレージが必要か | 静的と動的の両方とストレージボリュームがサポートされる。異なるノードでPodが作成/再スケジュールされる場合にアタッチ/再アタッチされる。 |
| 仮想ネットワークのサポート | Pod間通信、AKSからオンプレミスへの通信があるか | AKSは既存の仮想ネットワークにデプロイできる。 |
| HTTPルーティングができるイングレス | デプロイしたアプリケーションをインターネットに公開する必要があるか。 | HTTPアプリケーションルーティングアドオンを使用すると、AKSクラスターでデプロイされたアプリケーションに簡単にアクセス可能 |
| Dockerイメージのサポート | Dockerイメージを使用したいか | Dockerファイルイメージ形式がサポートされている |
| プライベートコンテナレジストリ | プライベートコンテナレジストリが必要か | ACRと統合可能。ほかのコンテナレジストリも使用可能 |
Azure Functions
シナリオ

ポイント
- タイムアウトの問題が発生する可能性がある実行時間の長い大きな関数は避ける。既定のタイムアウトは、従量課金プラン関数の場合は 300 秒で、他のプランの場合は 30 分。
- Durable Functions を使用すると、ステートフル関数を使える。関数チェーンなどの機能が使える。
- 例外を処理するように関数を設計し、エラーが発生した場合に続行できるようにする。
- ストレージ アカウントを共有しない。関数アプリケーションごとに別のストレージ アカウントを使って、パフォーマンスを上げる。
LogicApp
シナリオ

Functionとの違い

ポイント
- 外部と接続する必要がある処理に有効
- アプリを自動的にスケーリングし、大規模なデータセットを並列で処理できる。
- アクセスする必要があるすべてのサービスで、事前構築済みのコネクタを使用できるかどうかを調べること。場合によってはカスタムコネクタを作成する必要がある。
- リアルタイム要件、複雑なビジネス ルール、または標準以外のサービスを使用している場合は、最適なソリューションではない。
メッセージソリューション Azure Queue Storage と Azure Service Bus
Queue Storageの特徴
- 数百万のメッセージを含められる
※キューの数とサイズは、QueueStorageを所有するStorageAccountの容量次第 - メッセージにはRESTでアクセス可能
Service Busの特徴
- メッセージキュー と パブリッシュ/サブスクライブのトピック の二種類がある
- メッセージキュー
- メッセージブローカーシステム。メッセージを受信するまでメッセージを保持する。
- パブリッシュ - サブスクライブ トピック
- 一つのメッセージに対し、複数の受信者が同じメッセージを受け取れる。
- メッセージキュー
- アプリケーションとサービスを分離できる。
- 一つあたりのメッセージサイズは64KBまで
- キューストレージのサイズは80GBまで
イベントドリブンソリューション
Azure Event Gridは、Fabric基盤として実行されるフルマネージドなイベントルーティングサービス。
- Event Grid:状態の変更によってイベントを配信する
- Event Hub:テレメトリと分散データストリーミング。イベントをストリーミングする
- Service Bus:メッセージベース
キャッシュソリューション
Azure Cache for Redis
Redis ソフトウェアをベースにしたメモリ内データストアを提供
いくつかのシナリオ例
- データキャッシュ
- キャッシュ アサイド パターンを使用して、必要な場合にだけデータをキャッシュに読み込む。
- コンテンツキャッシュ
- 静的コンテンツに迅速にアクセス
- セッションストア
- Azure Cache for Redis などのメモリ内キャッシュを使用して情報をユーザーに関連付ける方がRDBを操作するよりはるかに高速
- ジョブおよびメッセージ キュー
- 分散キューを提供
- 分散トランザクション
- Azure Cache for Redis では、一連のコマンドを単一のトランザクションとして実行する方法をサポート。
API 統合
Azure API Management
すべての API を発行、セキュリティ保護、保守、分析できるクラウド サービス プラットフォーム。API のフロント ドアとして機能する。
APIManagementが適しているかどうかは、「APIの数」「APIの変更ベース」「API管理」の3点を考慮する。
- APIが多数で管理オーバエッドがある場合、有効
- 小規模でシンプルなAPI管理の場合、不要
アプリ構成管理ソリューション
Azure App Configuration
アプリケーションの設定と機能フラグを一元管理するためのサービス。
Azure ネットワーク接続サービスの設計パターン
パターン 1: 単一の仮想ネットワーク
仮想ネットワークは複数のリージョンにまたがることはできないため、単一のリージョンでのみ運用する場合に使う。
サブネットでワークロードを分け、NSGやASGでネットワークを制御する。
パターン 2: ピアリングを使う複数の仮想ネットワーク
アプリケーションを別の仮想ネットワークにグループ化することや、複数の Azure リージョンにまたいでアプリ構築できる。
パターン 3: ハブスポーク トポロジ内の複数の仮想ネットワーク
ハブ仮想ネットワークではすべてのトラフィックが通過し、異なるリージョンにある他のハブへのゲートウェイとして機能する。
ハブでセキュリティ体制を設定して、仮想ネットワーク間はピアリングで接続し管理する。
利点は、スポークが増えてもネットワークの入口と出口はハブに集約されているため、管理オーバーヘッドが増えないこと。
送信接続とルーティング
Azure Virtual Network NAT
プライベートネットワーク上のリソースが、NATを使い、外部IPアドレスにマップすることで、パブリックネットワーク上の外部リソースにアクセスする。
指定した静的パブリックIPアドレスがすべての送信接続で使われる。
ロードバランサーやリソースにパブリックIPがなくても、インターネット上へのアウトバウンド接続が可能になる。
Route Table
Azureでは、RouteTableを使って内部リソースと外部のインターネットリソース間の通信をルーティングする。
実際には、仮想ネットワークを作成したタイミングで、各サブネットにルートテーブルが自動的に作成される。BGP(Border Gateway Protocol)、UDR(ユーザ定義ルート)、他仮想ネットワークからのルートなどが含まれる。
システムルート
仮想ネットワークを作成したタイミングで作られる。変更はできないが、UDRでオーバーライドすることでルーティング設定する。
UDR(ユーザ定義ルート)
システムルートを上書きしたり、ルートの追加をするときに使う。
他の仮想ネットワークからのルート
仮想ネットワーク間のピアリングを作成すると、それぞれの仮想ネットワークごとに追加されるルート
BGPルート(Border Gateway Protocol)
オンプレミスネットワークゲートウェイがAzureVirtualNetworkゲートウェイとBGPルートを交換すると、オンプレミスネットワークゲートウェイから伝達された各ルートに対応するルートが追加される。
このルートはルートテーブルにBGPルートとして表示される。
サービスエンドポイントルート
Azureサービスのサービスエンドポイントを有効にすると、Azureによって特定のサービスのパブリックIPアドレスがルートテーブルに追加される。
ルーティング順
ルーティングテーブルのルートが競合している場合、プレフィックスの最長一致に基づいてネクストホップを選ぶ。アドレスのプレフィックスが同じネクストホップエントリが複数ある場合、UDR→BGP→システムルートの順でルートを選ぶ。
Azure Virtual Network へのオンプレミス接続
VPN Gateway
Azure仮想ネットワークとオンプレミス間で暗号化されたトラフィックを送信する仮想ネットワークゲートウェイの一つ。
※暗号化されたトラフィックはパブリックインターネットを経由する。
以下のようないくつかの構成あり
- サイト間
- ポイント to サイト
- 仮想ネットワーク間
ExpressRoute
サードパーティ製接続プロバイダーを経由するプライベート専用接続。
トラフィックはインターネットを経由しないプライベート接続。
VPNフェールオーバを使ったExpressRoute
ExpressRouteとVPNGatewayを組み合わせて、ExpressRoute回線の接続が失われた場合にVPN接続へのフェールオーバする構成
VirtualWANとHubSpokeネットワーク
Hub側の「サイト間VPN」「ExpressRoute」「ポイントtoサイトVPN」などの多数の接続サービスを、一つの操作インターフェースにまとめるサービス。
アプリケーション配信サービス
以下の観点でサービスを比較する。
- トラフィック種類:Webアプリをインターネット公開するかしないか
- 仮想ネットワーク内の仮想マシンやコンテナの負荷分散をするか
- リージョン間で負荷分散するか
- 可用性
- コスト
Azureサービスだと、Azure Front Door、Traffic Manager、Load Balancer、Application Gatewayがある。
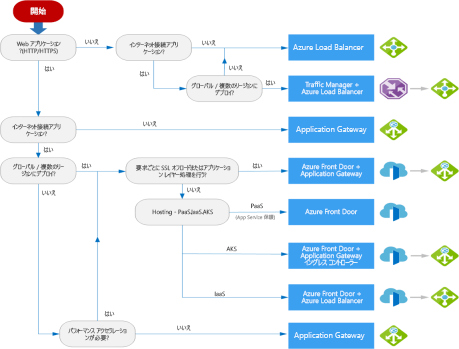
Azure Content Delivery Network
高帯域幅のコンテンツをユーザに配信するためのグローバルなソリューション。世界各地に配置された物理ノードにコンテンツをキャッシュできる
Azure Front Door
Webアプリケーションを、世界中のユーザに配信できる。
Azure Traffic Manager
世界中のリージョン間でサービスへのトラフィックを最適に配分し、高可用性と応答性を実現するDNSベースのトラフィックロードバランサー。
優先順位、重みづけ、パフォーマンス、地理的、複数値、サブネットなどのルーティング方法でトラフィックを分散できる
Azure Load Balancer
UDP、TCPプロトコル向けのレイヤー4負荷分散機能
Azure Application Gateway
Webアプリケーションに対するトラフィックを管理できるレイヤー7のロードバランサー。
パスベースのルーティングと複数サイトのルーティングの2つがある。
異なる URL パスの要求を異なるバックエンド サーバーのプールに送信できる。
アプリケーション保護サービス
DDoS Protection
DDoS攻撃への対抗策。仮想ネットワークにデプロイされたアプリケーションとリソースに対するDDoS軽減機能が強化されている。
これを利用すると、攻撃を受けたときにDDoS Rapid Responseサポートに問い合わせられる。
Private Link
仮想ネットワーク内のPrivateEndpoint経由でPaaSなどに接続できる。
Firewall
HTTP/S 以外のプロトコル (RDP、SSH、FTP など) に対する受信保護、
すべてのポートとプロトコルに対する送信ネットワークレベルの保護、および送信 HTTP/S に対するアプリケーションレベルの保護
WebApplication Firewall
SQL インジェクションやクロスサイト スクリプティングなどの一般的な Web エクスプロイトや脆弱性から Web アプリケーションを保護できる。
NSG
Azure Virtual Network 内の Azure リソースとの間のネットワーク トラフィックをフィルターする。
Service Endpoint
仮想ネットワークのプライベート アドレス空間と ID を直接接続を介して Azure サービスに拡張する。
仮想ネットワークから Azure サービスへのトラフィックは常に、Microsoft Azure のバックボーン ネットワーク上。
管理オーバーヘッドが少ない。
Bastion
Azure portal で TLS を経由し、仮想マシンへのセキュリティで保護されたRDP または SSH の直接接続を提供。
クラウド導入フレームワーク
- 戦略決め
- 計画
- 準備
- 導入

導入プロセスでの移行アプローチ
以下の主要フェーズを経て移行作業を行う。
- 評価:ワークロードを評価し、コスト、モダン化、デプロイツールを決定
- デプロイ:クラウドに移行
- リリース:移行したワークロードのテスト、最適化、文書化を実施。
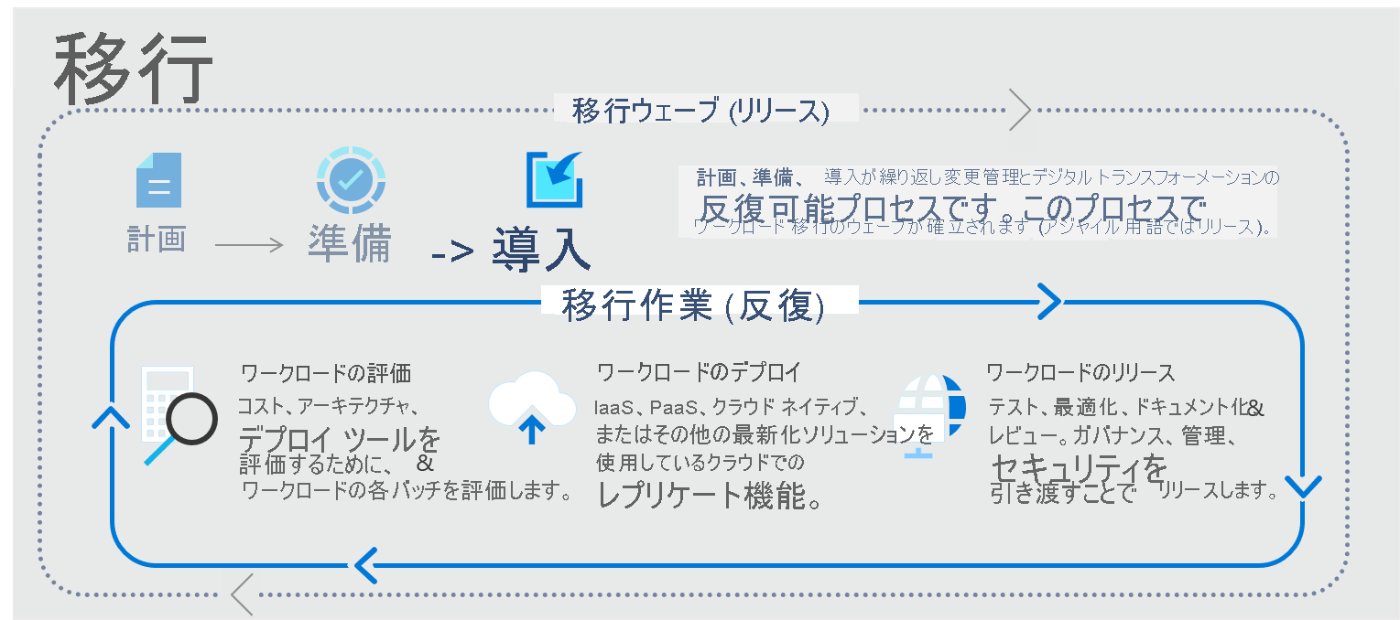
移行フレームワーク
4つのステージ
- 評価
- 移行
- 最適化
- 監視
1.評価
移行戦略パターン
-
リホスト
- いわゆるリフトアンドシフト移行
- コードの変更をせず、既存ワークロードをAzureに移行する。→コード変更に伴うリスクやコストが発生しない 例)VM上でアプリ稼働
-
リファクター
- 再パッケージ化
- アプリが PaaS上で動作するように、アプリに最小限の変更を加える。 例)AzureAppServiceやAzureKubernetesServiceに移行する。 例)RDBや非RDBをAzure SQL Managed Instance、Azure Database for MySQL、Azure Database for PostgreSQL、Azure Cosmos DB に移す。
-
リアーキテクト
- クラウドのスケーラビリティを活かすためにアプリのアーキテクチャを最適化する。 例)モノリシックアプリケーションを、マイクロサービス化する。 例)RDBや非RDBをフルマネージドなソリューション(Azure SQL Managed Instance、Azure Database for MySQL、Azure Database for PostgreSQL、Azure Cosmos DB)にリアーキテクトする。
-
リビルド
- アプリを完全に再構築する。 例)Azure Functions, AzureAI, Azure SQL Managed Instance, Azure CosmosDBなどの、クラウドネイティブなサービスを使い、新しくアプリをビルドする。
-
置換
- 利用可能な最適なテクノロジを使い実装する。
- ホストされるアプリケーションの機能すべてがSaaSとして扱われる。
2.ワークロードの移行
-
クラウドリソースをデプロイ
- 移行で利用できる Azure MigrateやAzure Database Migration Serviceなどがある。
-
ワークロードの移行
- リスク軽減のために、最初は重要ではないアプリでワークロードで移行を確認すべき。
-
オンプレで稼働していたアプリとインフラを停止
- ソースとアプリが正常に移行されたあと、バックアップとアーカイブデータは残したうえで、オンプレ側を停止する。 ※Azure Blob Storageに格納してもよい。
3.移行したワークロードの最適化
重要な点は以下3点
-
ワークロードの移行コストを分析
- Azure Portal の Azure Cost Managementを使用してワークロードのコストを分析。
- Azure Advisorの推奨事項を確認
- コスト削減するための推奨事項を確認
- パフォーマンスを向上する方法があるか確認
4.ワークロードの監視
Azure Monitorで正常性とパフォーマンスを確認する。
アラートは、CPUなどのメトリック値、ログファイル内のテキスト、正常性メトリック、自動スケーリングメトリックを使いアラートを設定できる
- VMの場合
- Azure Monitorを使い、Azure仮想マシンなどから正常性とパフォーマンスの情報を取り込める。AzureMonitorログ エージェントを仮想マシンにインストールし、アラートをレポートを設定可能
オンプレミスのワークロード評価
移行における「評価」「移行」「最適化」「監視」に使えるAzureサービス
| サービス/ツール | ステージ | 説明 |
|---|---|---|
| AzureMonitorのServiceMap機能 | 評価 | Windows/Linuxのアプリコンポーネント間の通信を取得する。移行するデータを決める際の依存関係を特定する。\n※オンプレ環境の仮想マシンにエージェントをインストールする |
| TCO計算ツール | 評価 | TCO(総所有コスト)を計算し、ワークロードをAzureに移行することで実現できるコスト削減額を見積もれる |
| Azure Migrate | 評価、移行 | 仮想マシン(Hyper-VとVMWare)、物理サーバ、DB、データ、WebアプリのAzure移行を評価し、移行を実行する。 |
| Data Migration Assistant(DMA) | 評価、移行 | SQL Server Data Micration Assistantは、最新データプラットフォームにアップグレードする際に、新しいバージョンのSQL ServerやAzure SQL Databaseにした際に影響があるか、互換性の問題を検出する。 |
| Database Migration Service | 評価、移行 | Azure SQL Database以外にも、複数の異なるデータベースの評価と移行を実行する。 |
| データ移行ツール | 移行 | Azure CosmosDB データ移行ツールは、既存のデータベースをAzureCosmosDBに移行する。 |
| Microsoft Cost Management | 最適化 | Azureコストを監視、最適化、制御するのに役立つ |
| Advisor | 監視 | 信頼性、パフォーマンス、コスト、セキュリティのための最適化に役立つ |
| Monitor | 監視 | Azure Monitorは、データ分析、アラート、監視情報を収集する |
| Microsoft Sentinel | 監視 | セキュリティ分析により、インシデントの収集、検出、調査、対応を実行する。 |
Azure Migrate
アプリケーションや仮想マシンなどのワークロードを移行できる。移行対象のワークロードは、オンプレミスのサーバ、インフラストラクチャ、アプリケーション、データ。
以下のコンポーネントがある。
-
移行プラットフォーム
- Azureへの移行と移行状態の追跡を行えるポータル
-
評価、移行ツール
- Server Assessment、Server Migration、その他ISV(独立系ソフトウェアベンダー)ツールなどの、評価と移行のためのツール
-
ワークロードの評価と移行機能
- サーバ:オンプレサーバ→AzureVM
- データベース:AzureSQLDatabase、AzureSQLManagedInstance
- Webアプリケーション:オンプレWebアプリが評価され、Azure AppService Migration Assistantを使ってAzure App Serviceに移行
- 仮想デスクトップ:VDIを評価し、Azure Virtual Desktopに移行
- データ:Azure Data Boxを使って、大量データを移行
-
Azure Migrate Hub ツール
- 移行ツールへの接続
- Server Assesment:SQL、Webアプリを含むサーバの検出と評価
- Server Migration:サーバの移行
- SQL Server Data Migration Assistant:Azure SQL Database、Azure SQL Managed Instance、SQL Server on VMへの移行を評価
- Azure Database Migration Service:オンプレのデータベースを、Azure SQL Database、Azure SQL Managed Instance、SQL Server on VMに移行
- Web App Migration Assistant:オンプレのWebアプリを評価し、Azureに移行
- Azure Data Box:オフラインデータを移行
- 移行ツールへの接続
WebアプリのAzureへの移行
Azure App Service Migration Assistantを使う。ローカル環境にインストールしたエージェントを使って分析する。
- アプリが適切な移行候補かどうかを評価
- 準備チェックを実行し、アプリの構成設定を評価
- アプリをAzure App Serviceに移行
仮想マシンの移行
- Azure Migrate: Server MigrationツールのためのAzureを準備
- オンプレの仮想マシンで移行準備
- オンプレの仮想マシンをレプリケート
- 仮想マシンを移行
Azure Resource Mover
サブスクリプション、リソースグループ、リージョン間でAzureリソースを移行するときに役立つツール。
データベースの構造化データを移行
Azure Database Migration Service
以下のオンプレミスのデータベースを移行できる
- SQL Serverを実行しているAzure仮想マシン
- Azure SQL Database
- Azure SQL Managed Instance
- Azure CosmosDB
- Azure Database for MySQL
- Azure Database for PostgreSQL
前提条件
- DMA をダウンロード
- Azure Virtual Network インスタンスを作成
- NSGを構成
- Azure Windows ファイアウォールを構成
- 資格情報を構成
- Azure でターゲット データベースをプロビジョニング
SQL Serverデータベースの構造化データを移行する方法は2つ。
-
オンライン移行
- ライブデータの継続的な同期がされるため、Azureレプリカデータベースにかっとオーバーできる。ダウンタイムを最小限に抑えられる。
-
オフライン移行
- 移行の開始時にサーバをシャットダウンする必要がある。サービスのダウンタイムが発生する。
SQL Server内データの移行ステップ
※SQL Server Data Migration Assistant(DMA)
- データベースの評価:移行するデータベースを評価。移行の推奨事項と代替アプローチを含むレポートが生成される。移行元と移行先間で互換性の問題がないかレポートで確認する。
- スキーマの移行:新しいAzureSQLDatabaseに空の構造が作成される。接続先との接続を検証。
- データ移行と検証:データベース内のデータが移行先インスタンスにコピーされ、移行先のデータベースが検証される。
非構造化データ用のオンライン ストレージ移行ツール
Azure Storage Migration Service
オンプレミスのファイルサーバに格納されている非構造化データを、AzureFilesやAzureVMに移行するときに役立つ。
移行プロセスはMigration Service、Azure File Sync、Azure Migrateによって提供される機能によって行われる。
- サーバの情報を収集:サーバのインベントリ(ファイルと構成に関する情報)を収集
- データ転送:ソースから宛先サーバにデータ転送
- (オプション)カットオーバー:新しいサーバーにカットオーバー(宛先サーバで移行元サーバのIDを使うようにすることで、ユーザとアプリは何も変更しなくても既存のデータにアクセスできる。)
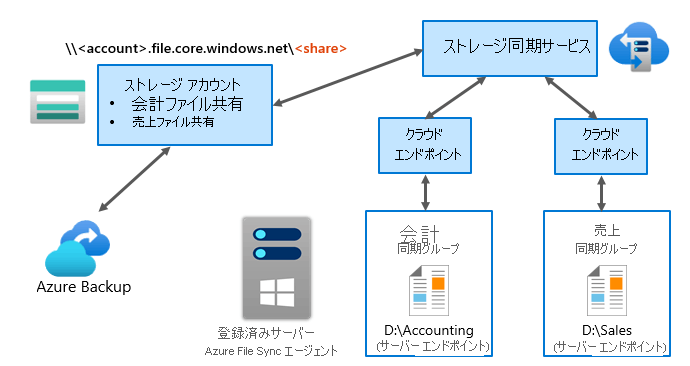
Azure File Sync
AzureFilesの機能。オンプレミスのファイルサーバのパフォーマンス、互換性を維持したままAzure Filesで組織のファイルを一元化できる。
SMB,NFS,FTPSなどのWindows上で利用できるプロトコルを使用可能。
しくみ
オフラインデータの移行
Azure Import/Exportサービス
大規模なデータ転送のためのネットワークが十分な容量ではない場合や信頼性に欠ける場合に最適。
手順
- ImportまたはExportするデータを指定するジョブを作成する。
- データ転送に使用するディスクを準備
- Importジョブ:利用中のデータをディスクに書き込み、Azureデータセンターに送付する。MS側で送付されたディスク内のデータがAzureにアップロードされる。
- Exportジョブ:空ディスクを準備し、Azureデータセンターに送付。MS側で送付された空ディスクにデータコピーされ、返送される。
注意点
- AzureBlobStorageのみからデータをエクスポートできる。
AzureFilesのデータをエクスポートできない。 - オンプレのWindowsでBitLockerを有効にする必要がある。
Azure Data Box
40TBを超えるデータサイズの転送で、インターネット接続が制限されている状況で最適。
手順
- MSから送付されるセキュリティ保護されたストレージデバイスを受け取る。
- オンプレ環境で、Webベースの管理インターフェースを使ってImport/Exportする。
コンポーネント
- Azure Box デバイス:クラウドストレージとの通信を管理し、すべてのデータのセキュリティと機密性を確保するのに使う物理デバイス。最大80TBのストレージ容量
- Data Box サービス:Webインターフェースを使って、地理的に異なる場所のDataBoxデバイスを管理できるAzurePortalの拡張機能。
- Data Box ローカル Webユーザインターフェース:ローカルネットワークにデバイスを接続し、DataBoxサービスにデバイスを登録するために使われるWebUI。DataBoxデバイスのシャットダウンや再起動、コピーログの表示、MSサポートへの連絡やSR要求も可能。
Well-Architected Framework
5本の柱
- コスト最適化
- オペレーショナルエクセレンス
- パフォーマンス効率
- 信頼性
- セキュリティ
コスト最適化
最も効果が大きい部分にコストをかけられるように、非効率で無駄なクラウド支出をなくす。
可能であればIaaSからPaaSに移行する。利用コストが低く、運用コストも低い。
オペレーショナルエクセレンス
DevOpsなどの開発方法を利用し、開発とデプロイのサイクルを高速化する。
ユーザが気が付く前に、障害や問題を検出できるように監視アーキテクチャw整備する。
自動化は重要で、運用の詭弁性を高めながら差異やエラーを除去
パフォーマンス効率
リソースの容量を需要と一致させるために、アプリケーションのアクティビティに基づいて動的にスケーリングする。
信頼性
復旧手段がない状態でダウンしないようにする。
- 目標復旧時点(RPO):データ損失が許容される最大継続時間
- 目標普及時間(RTO):ダウンタイムが許容される最大継続時間
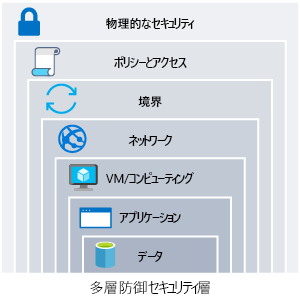
セキュリティ
認証でアーキテクチャへのアクセスを保護する。
ネットワークの脆弱性から保護する。
暗号化ツールを使用してデータの整合性を保護する。
MSとの共同責任

共同責任モデル
