Closed10
【GCP】Text To Speechで音声合成を試す(ターミナルからのリクエストで合成する)
はじめに
- 音声合成を行うまでの手順を、メモしながら確認進める。
公式ドキュメント
デモページ
今回試した環境
| OS・ツールなど | バージョン | 備考 |
|---|---|---|
| MacOS | Ventura( 13.2.1 ) | - |
| Python | 3.9.6 | ※gcloud CLIインストール時にPython必要 |
| iTerm2(zsh) | Build 3.4.20 | ※デフォルトのターミナルでも可 |
音声合成確認までの、大まかなフローまとめ
- 新規GCPプロジェクト作成
- Text To Speechサービスの有効化
- サービスアカウントの作成
3-1. サービスアカウントを新規作成する
3-2. サービスアカウントに JSON キーを作成する
3-3. 認証情報の環境変数を設定する - gcloud CLI をインストール
- コマンドラインを使用してテキストから音声を作成する
5-1. gcloud CLI を使って、認証トークンを取得する
5-2. コマンドラインで、テキストから音声合成を行う(※直接音声ファイルが生成される訳ではない)
5-3. 音声合成結果のデータをデコードし、音声ファイルを生成する
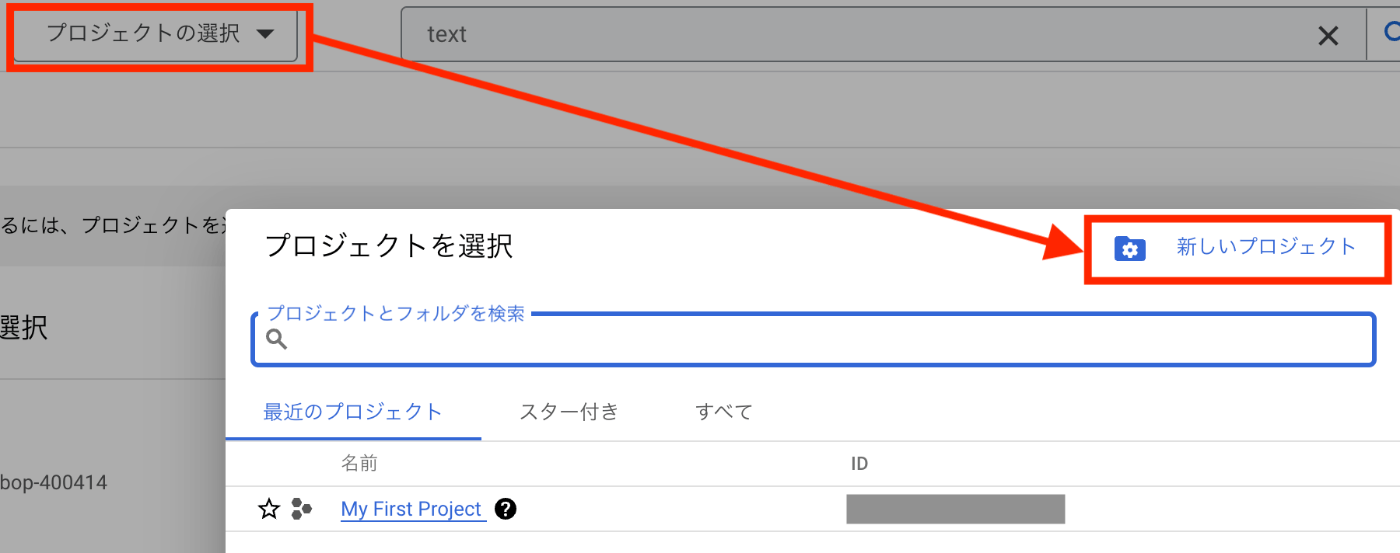
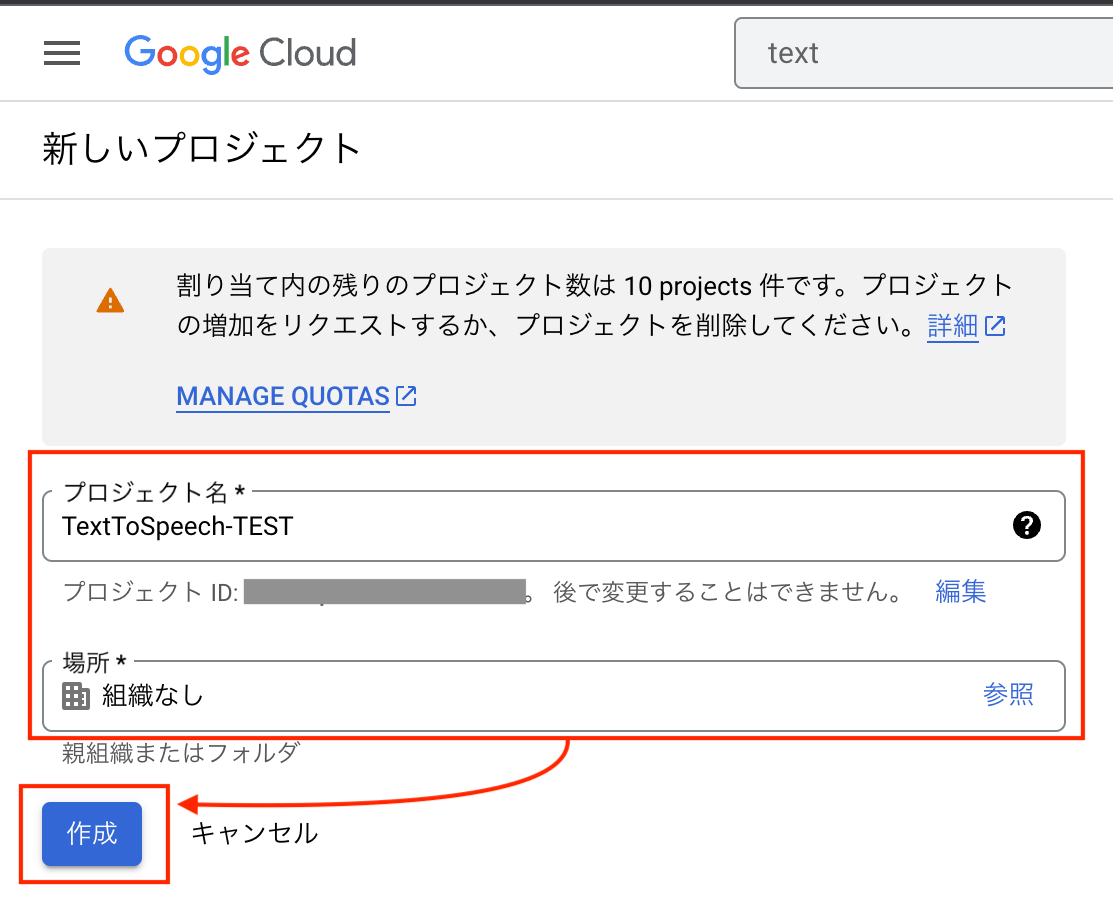
1、新規GCPプロジェクト作成
- ダッシュボードから、[プロジェクトの選択] > [新しいプロジェクト] を選択
- 任意のプロジェクト名を入力し、作成
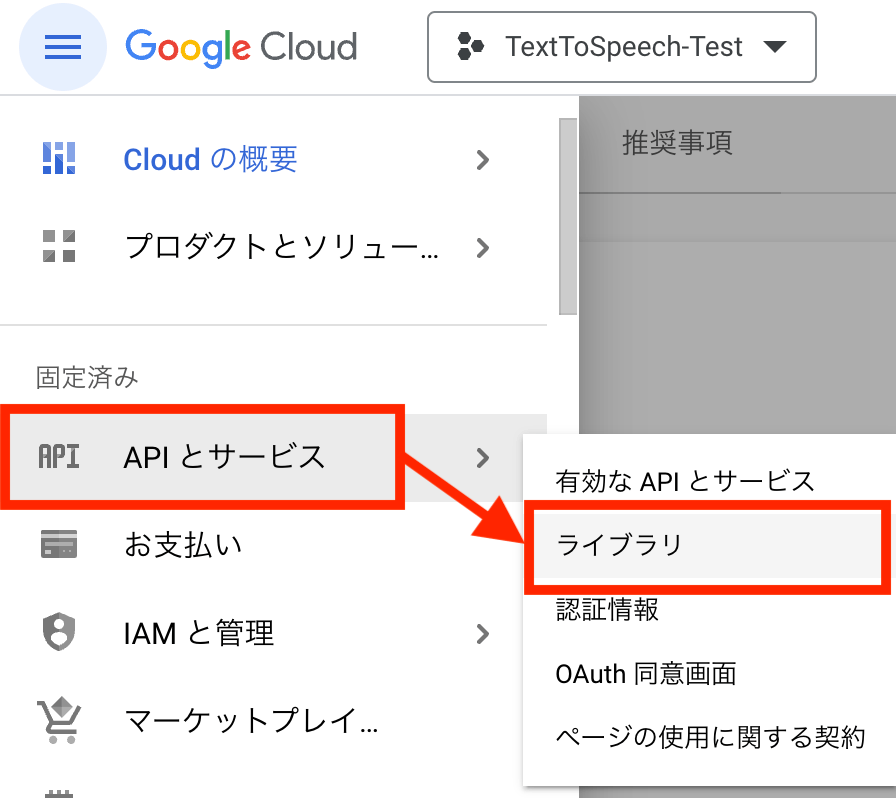
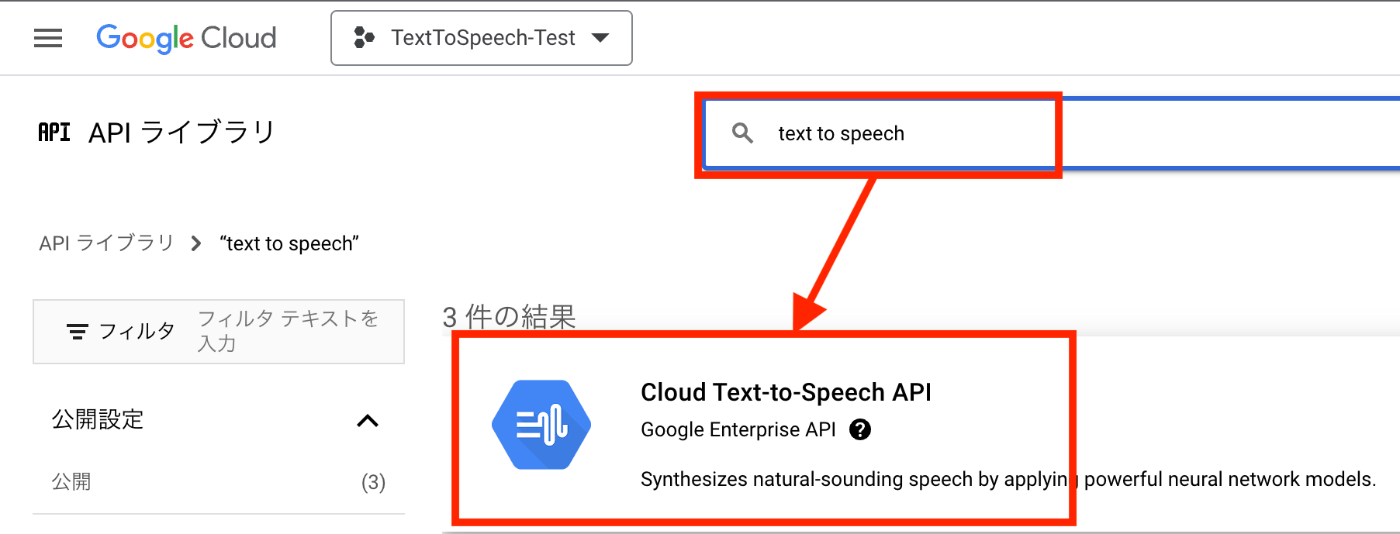
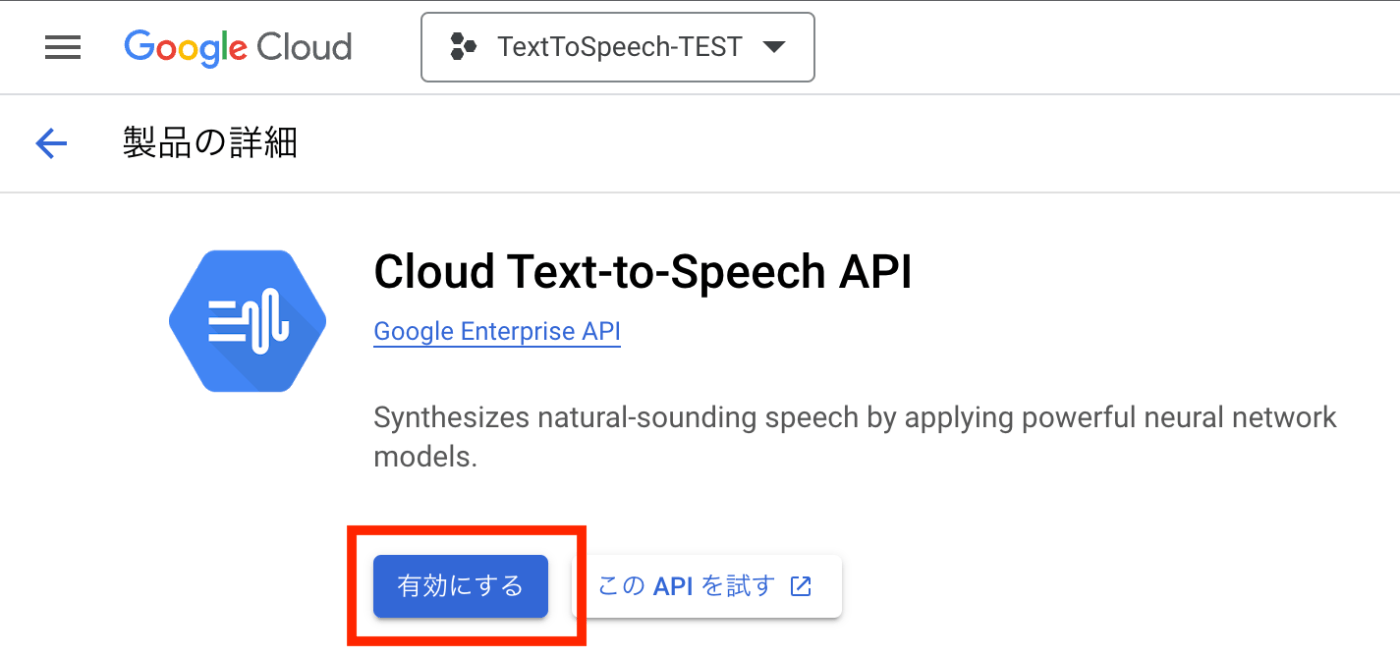
2、Text To Speechサービスの有効化
- メニューから、[APIとサービス] > [ライブラリ] を選択
- 検索欄で "Text To Speech" を検索 > [Cloud Text-to-Speech] を選択
- Text To Speechサービス内の、[有効にする] を選択
3、サービスアカウントの作成
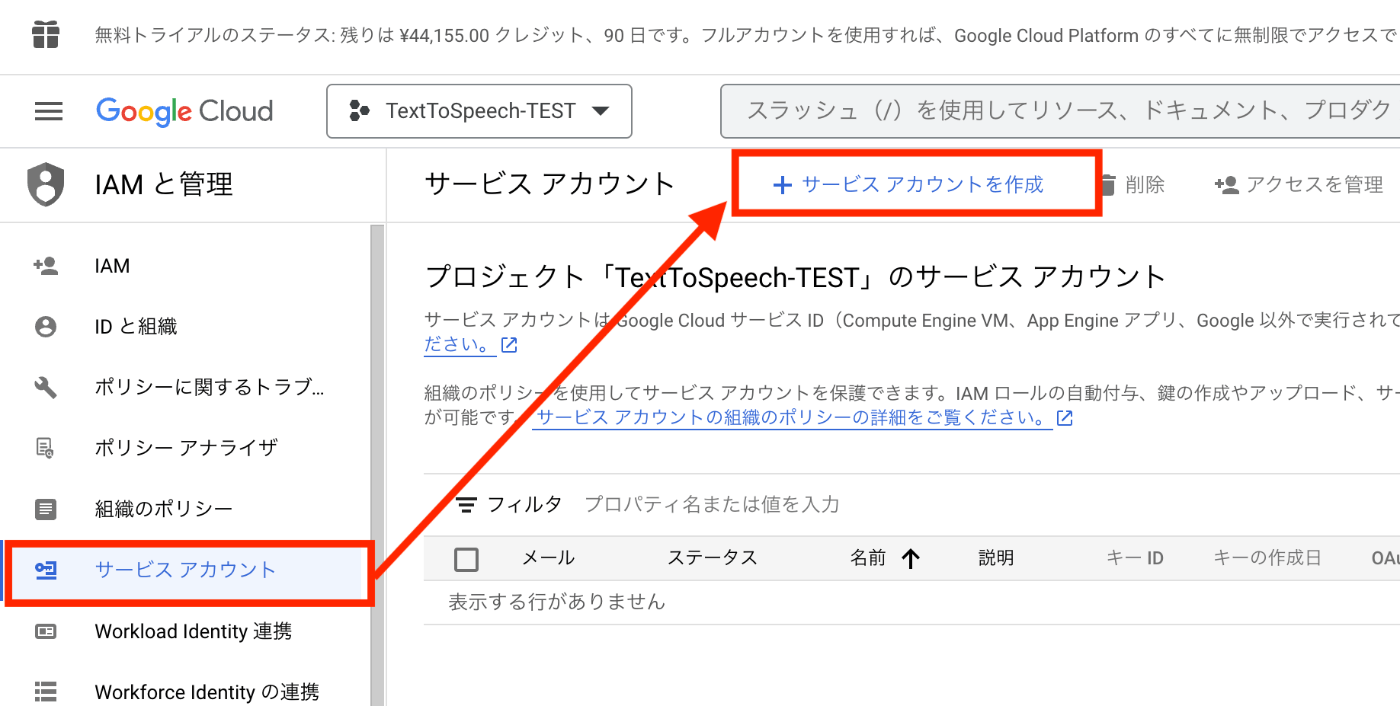
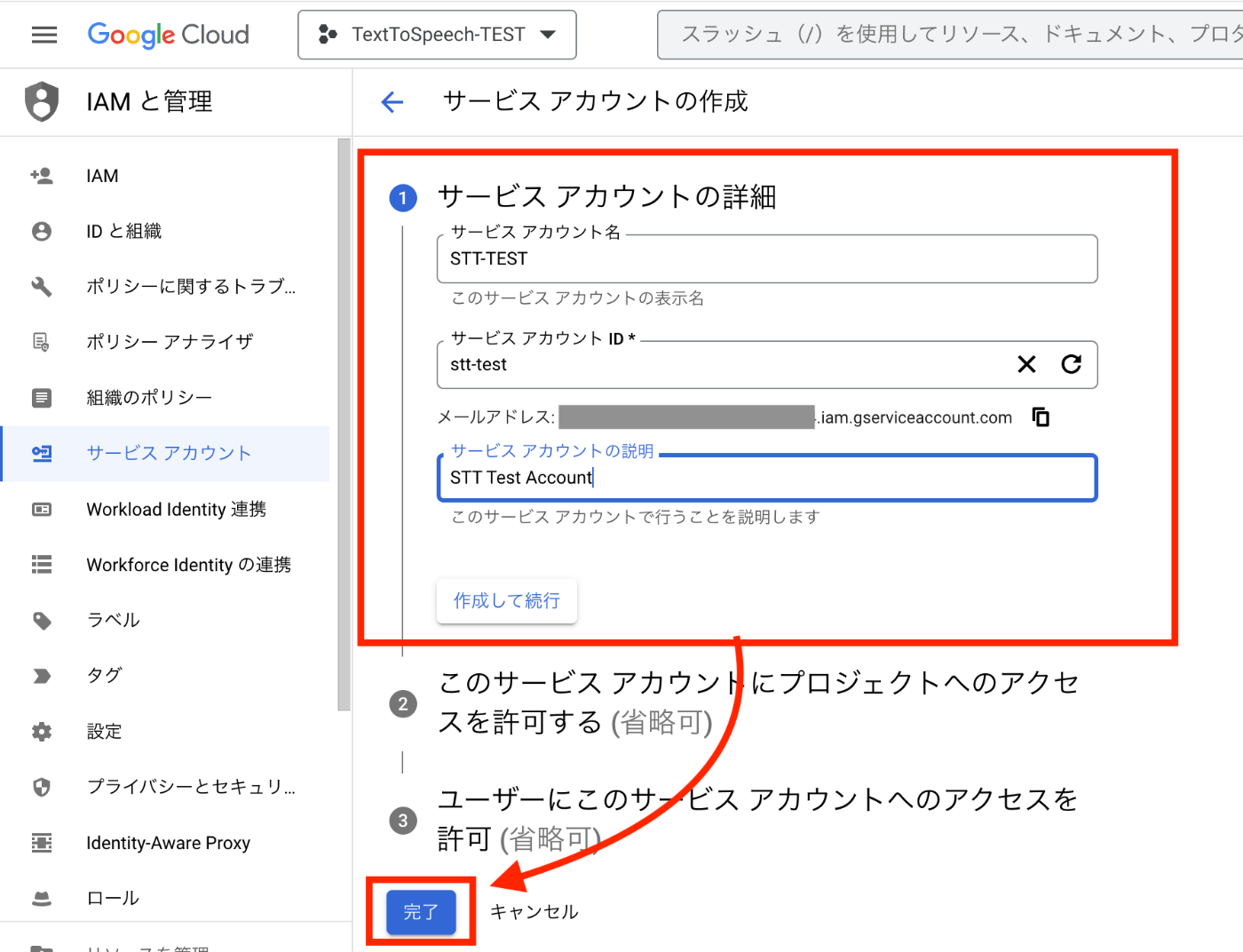
3−1、サービスアカウントを新規作成する
- メニュー内の、[サービスアカウント] > [サービスアカウントを作成] を選択
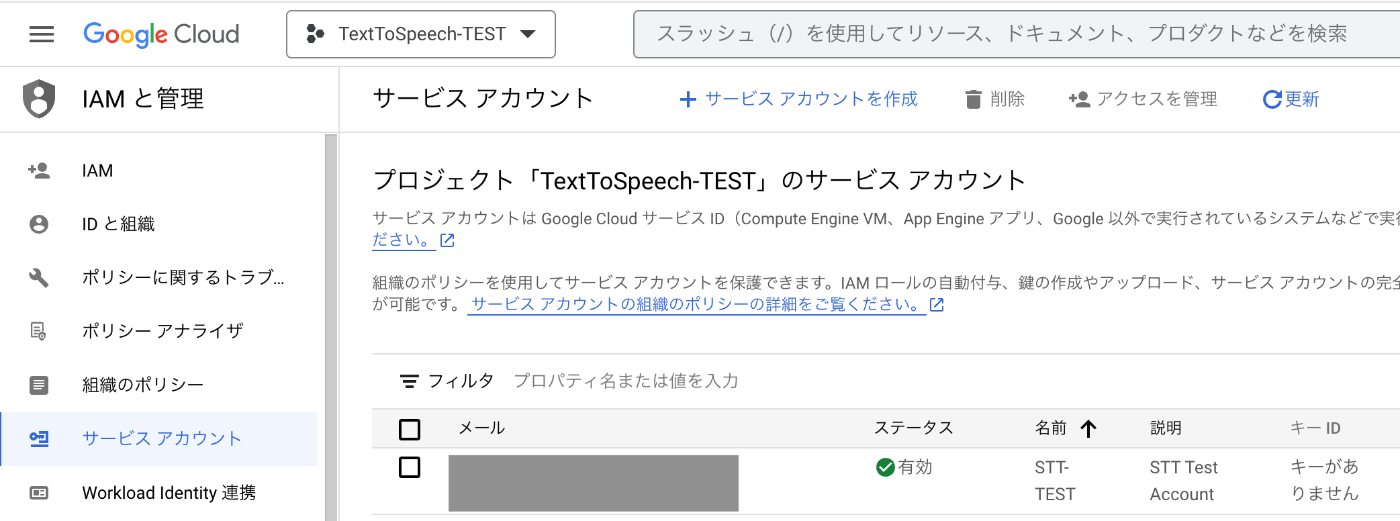
- [サービスアカウントの詳細] を任意の値で入力 > [完了] を選択
※今回は必須項目だけ入力とした。作成完了後、サービスアカウントが追加されていたらOK。
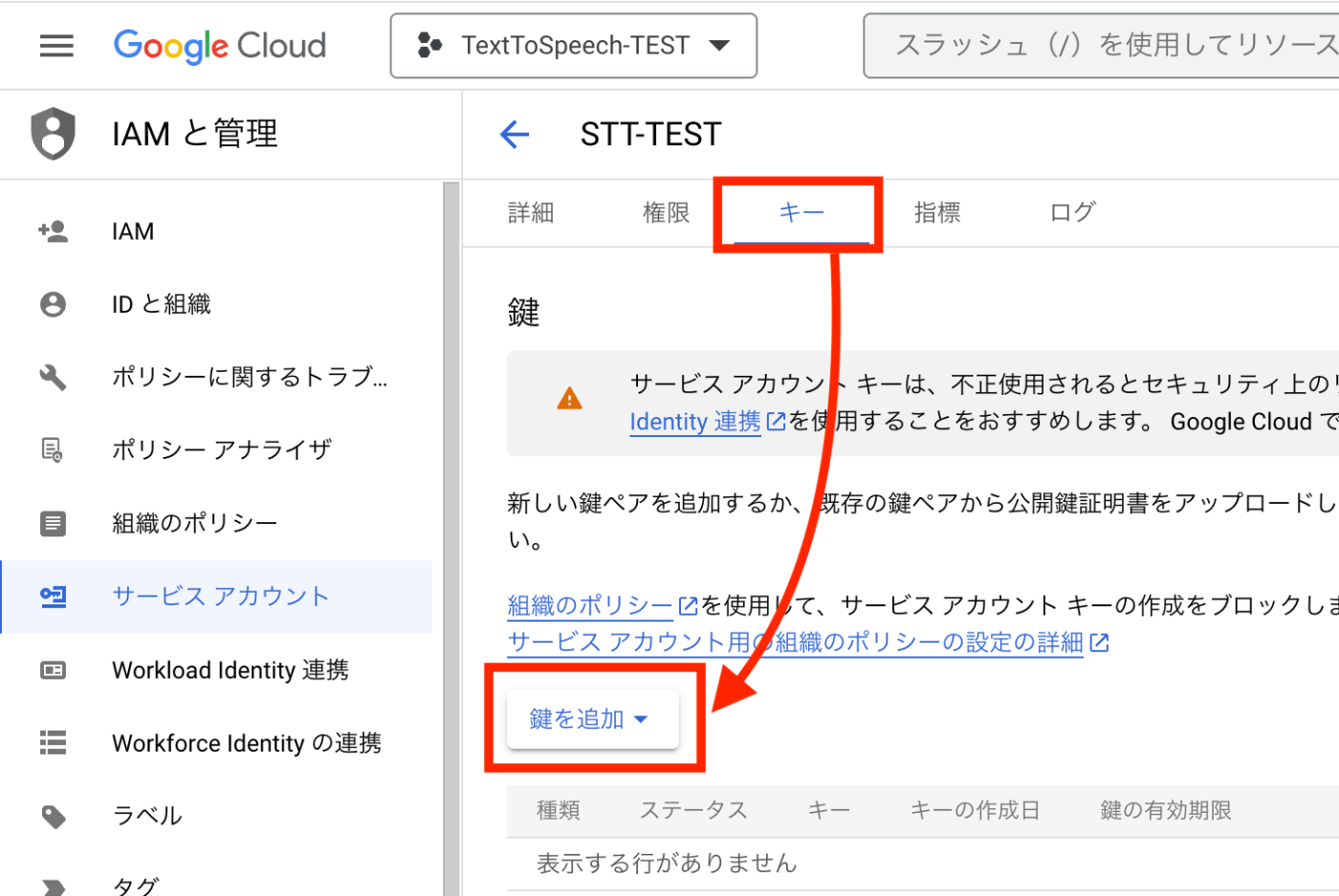
3−2、サービスアカウントに JSON キーを作成する
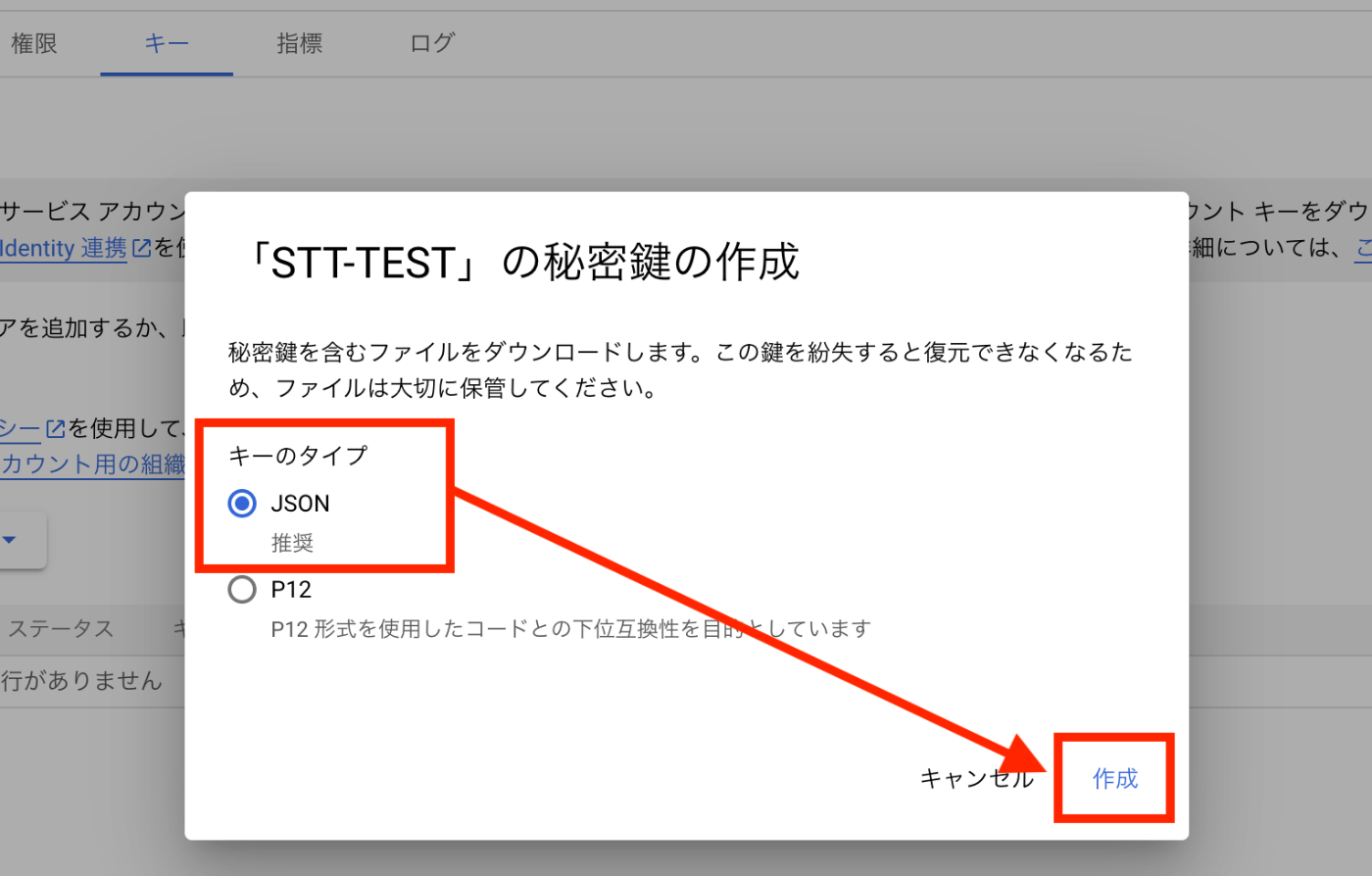
- タブメニューから、[キー] > [鍵を追加] を選択
- キータイプを [JSON] とし、[作成] を選択
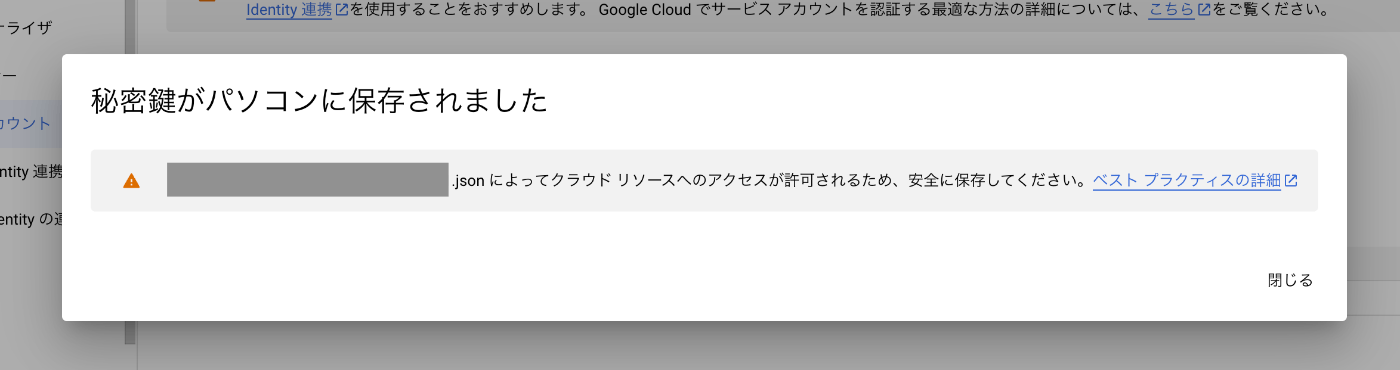
- 作成ボタン選択後、JSONファイルがPCにダウンロードされることを確認する
- ダウンロード後のJSONファイルは、任意の場所に格納する
※今回はユーザーディレクトリ直下にGCP用のフォルダを作成し、格納した。

3−3、認証情報の環境変数を設定する
- ターミナルを起動する(私の環境だとiTerm2を利用)
- 以下コマンドを実行し、環境変数の設定を行う
export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"
# 例: export GOOGLE_APPLICATION_CREDENTIALS="/Users/GCP-Keys/xxxxxxxxxx.json"
4、gcloud CLI をインストール
- Pythonのインストール状況を確認する
※Python3(3.8~3.9)が既にインストール済みだったので、今回はPythonインストールをスキップした。
ターミナル
# 以下いずれかのコマンドで、Pythonバージョンを確認
python3 -V
python -V
- 上記公式サイトより、環境に合った gcloud CLI をダウンロードする
- ダウンロードしたファイルを、任意の場所に展開する
※今回は、ユーザーディレクトリ直下に展開した(例: /Users/ユーザー名/展開先)
ターミナル
# tar.gzの展開コマンド例
tar zxvf google-cloud-cli-447.0.0-darwin-arm.tar.gz
- インストールスクリプトを使用して、gcloud CLIツールをPATHに追加
ターミナル
# 展開したフォルダのルートから以下を実行する
./google-cloud-sdk/install.sh
- gcloud CLI を初期化
ターミナル
# 展開したフォルダのルートから以下を実行する
tar zxvf google-cloud-cli-447.0.0-darwin-arm.tar.gz
5、コマンドラインを使用してテキストから音声を作成する
5−1、コマンドラインで、テキストから音声合成を行う(※直接音声ファイルが生成される訳ではない)
- リクエスト本文を、「request.json」として保存する(ファイル名は任意の名称で可)
※以下は公式のサンプルデータ
{
"input":{
"text":"Android is a mobile operating system developed by Google, based on the Linux kernel and designed primarily for touchscreen mobile devices such as smartphones and tablets."
},
"voice":{
"languageCode":"en-gb",
"name":"en-GB-Standard-A",
"ssmlGender":"FEMALE"
},
"audioConfig":{
"audioEncoding":"MP3"
}
}
- curlコマンドを使い、音声合成のリクエストを実行する。
※「request.json」が存在するディレクトリ配下で実行する。
ターミナル
curl -X POST \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://texttospeech.googleapis.com/v1/text:synthesize"
ターミナル
# レスポンス例
{
"audioContent": "//NExAxxxxxxxxxxxxxxxxxxxxx 〜長いので省略〜"
}
5−2、音声合成結果のデータをデコードし、音声ファイルを生成する
- リクエスト結果内の、「audioContent」の値をコピーし(上記の"/NExAxxxxxxxxxxxxxxxxxx"の部分)、テキストファイルに保存する。
- 以下コマンドを実行し、デコードして音声ファイルを生成する
※公式サイトのコマンドだと、「-i」オプションがなかった。付けないと正常に実行できなかったので、付与した。
ターミナル
base64 --decode -i SOURCE_BASE64_TEXT_FILE.txt > DESTINATION_AUDIO_FILE.mp3
音声合成周りの、公式ドキュメント
このスクラップは2023/10/01にクローズされました