📢
[Azure] Speech Serviceで音声合成する




概要
Unityアプリ開発時にナレーション音声を使いたいと思い、
AzureのSpeech Serviceを利用して音声合成を行ってみました。
実現イメージ
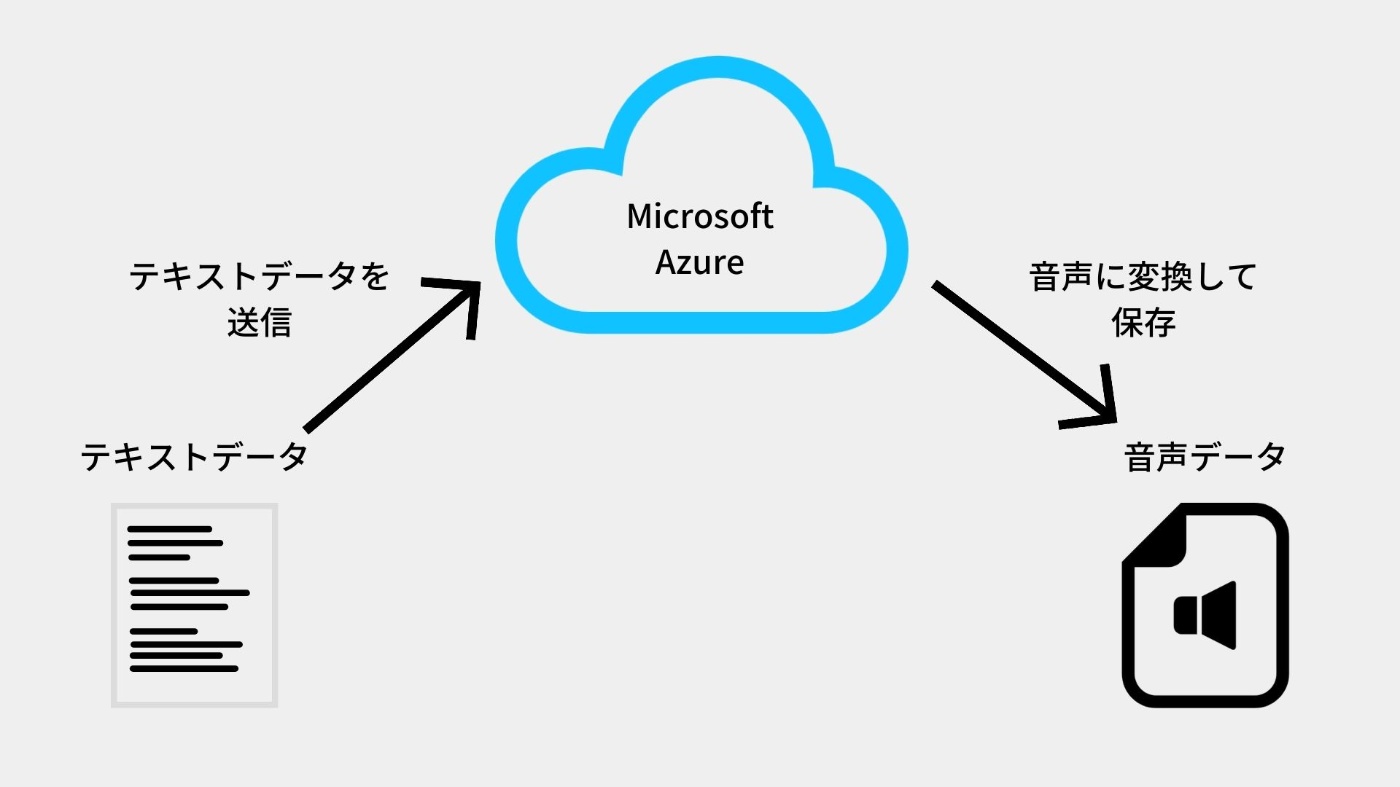
Speech Serviceとは?
- MicroSoft Azureの、Cognitive Servicesの機能の一つ
- 音声認識や、音声合成を行うことが可能
※補足
-
音声合成(Text To Speech) <= 今回試すもの
テキストデータから、人間の声を模した音声データを生成すること。
(Azure公式の、こちら から実際に音声合成をお試し頂くとイメージが付きやすいです。)
-
音声認識(Speech To Text)
音声からテキストデータを生成すること。
環境
| OS・ツールなど | バージョン |
|---|---|
| MacOS | Monterey( 12.5.1(21G83) ) |
| ターミナル | バージョン2.12.7 (445) |
Azure SpeechServiceを作成し、キー値を取得する
- SpeechServiceを作成し、音声合成に必要なキー値を取得します
※作成手順の公式ドキュメントは こちら
作成手順(クリックして開く...)
- Azure Portalへログインする
- 「Cognitive Services」を検索し、選択する
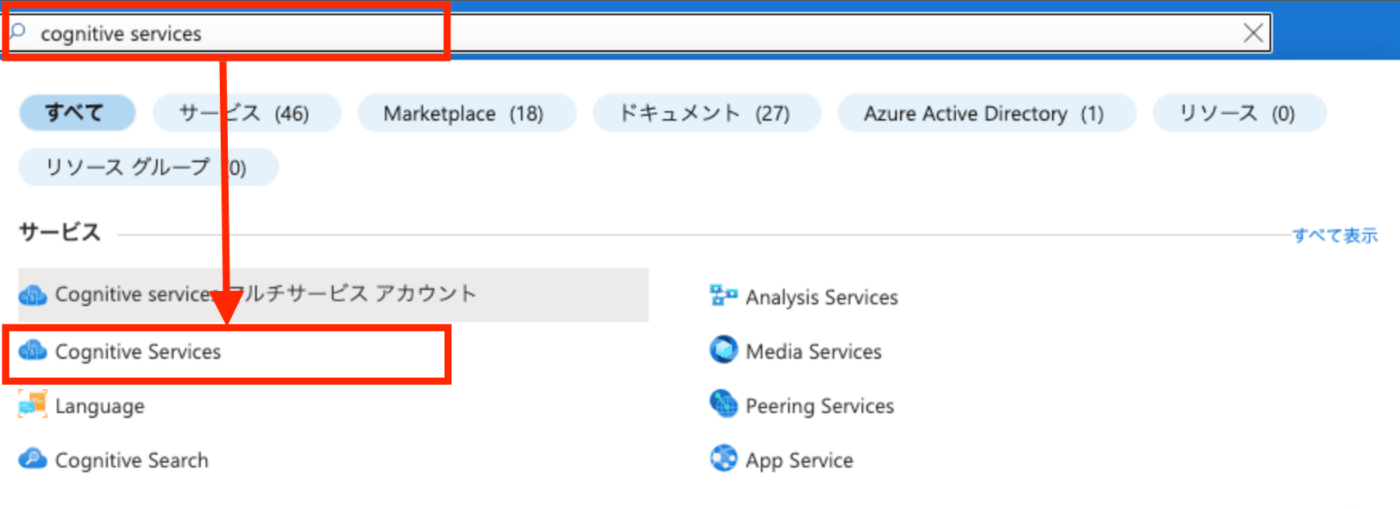
- ”音声サービス” の中の『作成』 ボタンを選択する
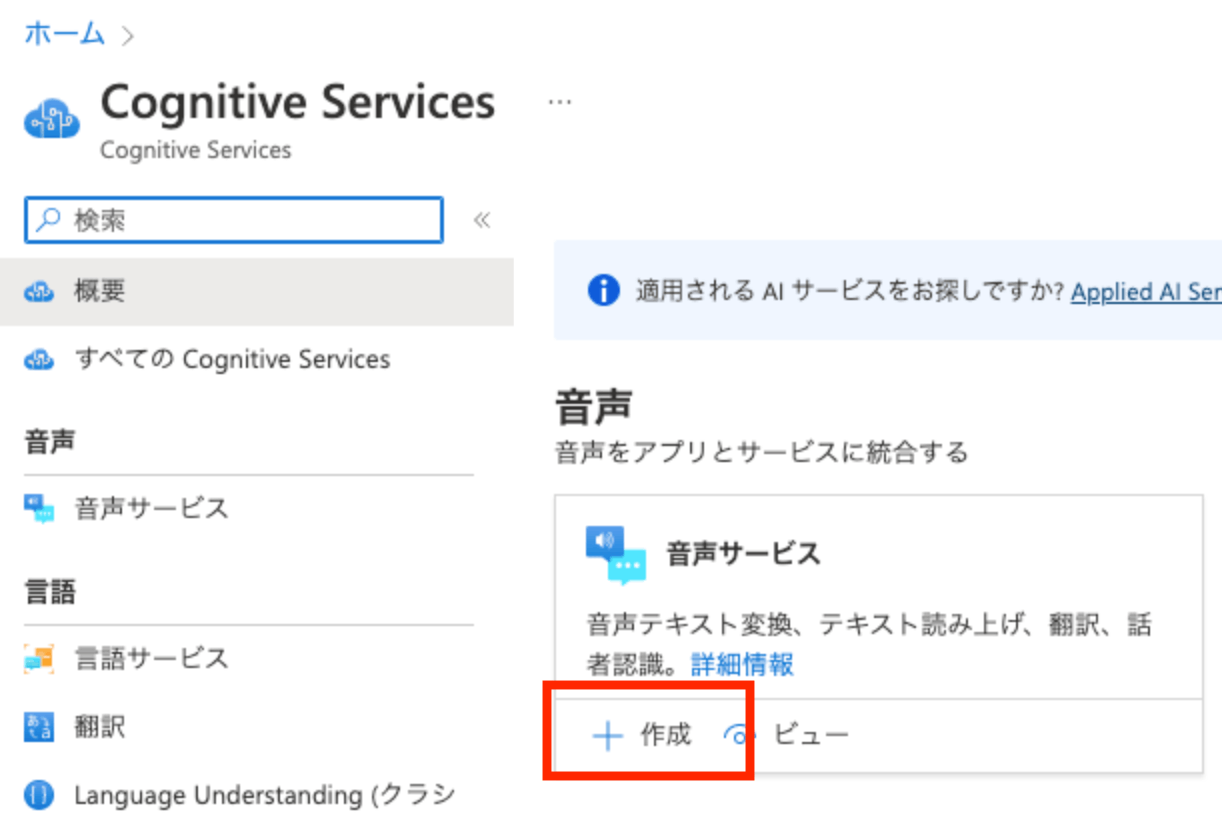
- サービス作成に必要な情報を入力し、『確認と作成』 ボタンを選択する
※入力内容は、適宜お好みの値やリージョンを選択ください。
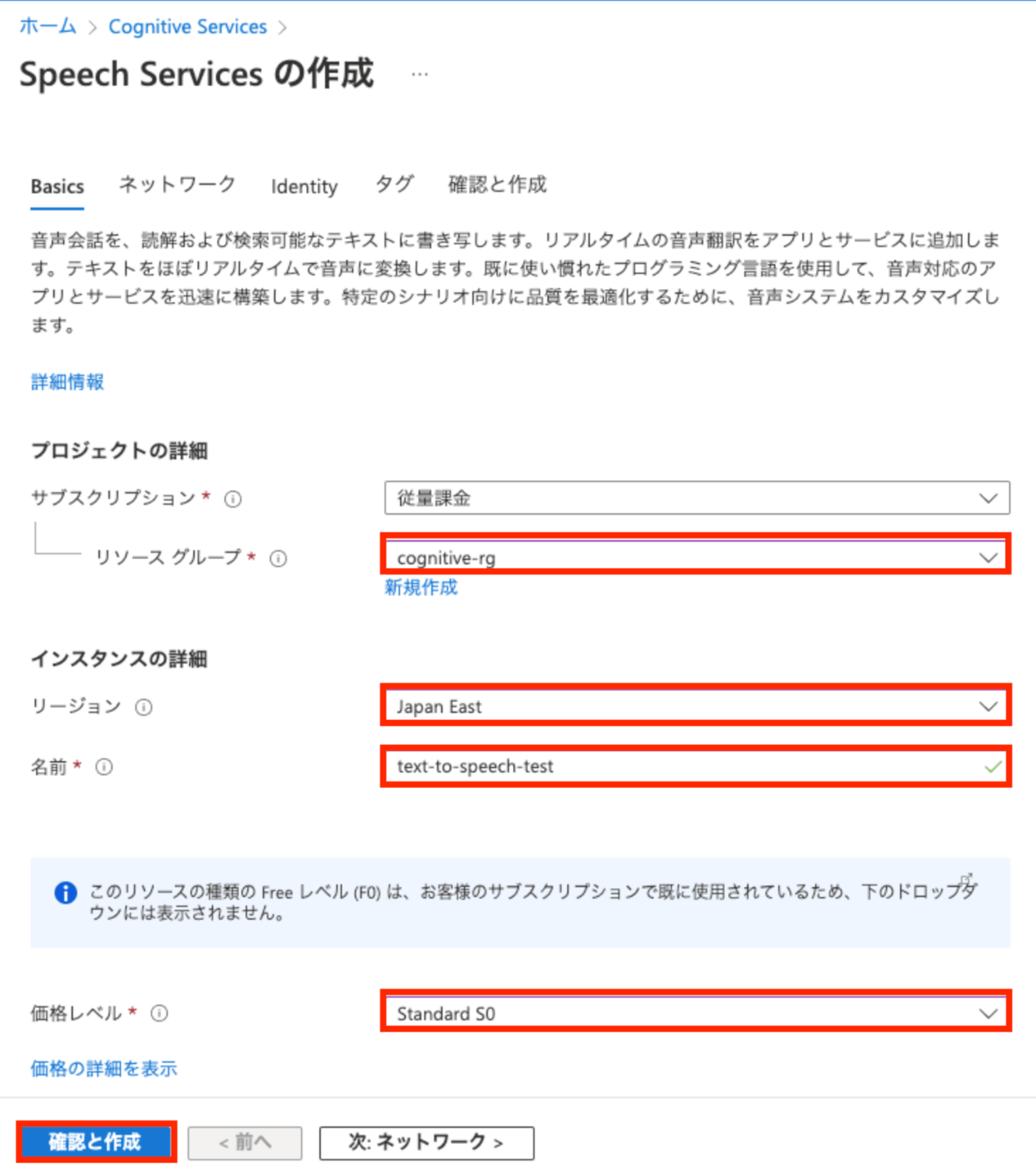
- デプロイ完了後、『リソースに移動』 ボタンを選択する

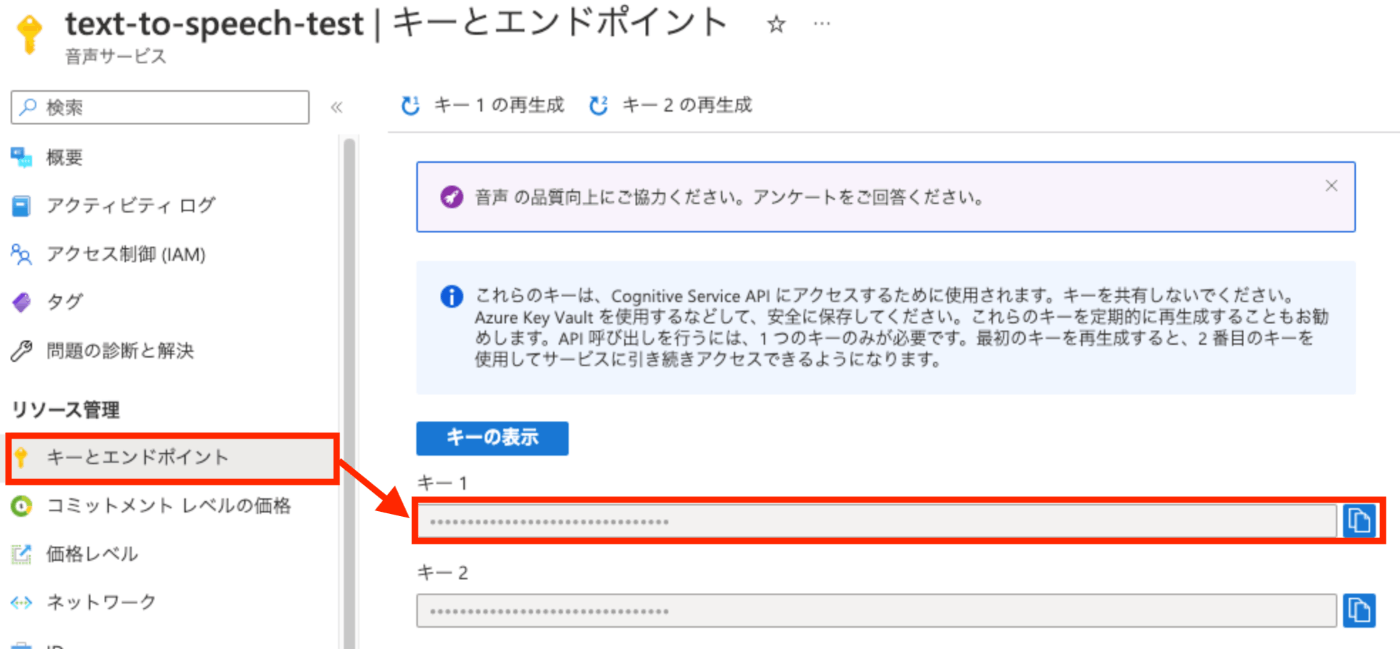
- リソース画面に遷移後、『キーとエンドポイント』 > 『キー1』 の値をコピーする
コピーしたキー値はメモしておいてください。
curlコマンドによる音声合成時のフォーマット
- フォーマット
フォーマットに各情報を当てはめたあと、ターミナルよりコマンド実行します。
curl --location --request POST 'https://<INSERT_REGION_HERE>.tts.speech.microsoft.com/cognitiveservices/v1' \
--header 'Ocp-Apim-Subscription-Key: <INSERT_SUBSCRIPTION_KEY_HERE>' \
--header 'Content-Type: application/ssml+xml' \
--header 'X-Microsoft-OutputFormat: <INSERT_OUTPUT_FORMAT_HERE>' \
--header 'User-Agent: curl' \
--data-raw '<INSERT_DATA_XML_HERE>' > output.mp3
- 要設定項目の説明
利用しているリージョンやキー値など、作成したリソースの情報に従って設定ください。
| 設定項目 | 説明 |
|---|---|
| INSERT_REGION_HERE | SpeechServiceの、リソースを作成したリージョンを設定する |
| INSERT_SUBSCRIPTION_KEY_HERE | SpeechServiceの、【キーとエンドポイント】メニュー内のキー値を設定する |
| INSERT_OUTPUT_FORMAT_HERE | 音声の出力形式を設定する。詳細は こちら を参照 |
| INSERT_DATA_XML_HERE | 音声合成データをXML形式で設定する。詳細は こちら を参照 |
curlコマンドのサンプル
curl --location --request POST 'https://japaneast.tts.speech.microsoft.com/cognitiveservices/v1' \
--header 'Ocp-Apim-Subscription-Key: subscriptionkeyxxxxxxxxxx' \
--header 'Content-Type: application/ssml+xml' \
--header 'X-Microsoft-OutputFormat: audio-48khz-96kbitrate-mono-mp3' \
--header 'User-Agent: curl' \
--data-raw '<speak version='\''1.0'\'' xml:lang='\''ja-JP'\''>
<voice xml:lang='\''ja-JP'\'' xml:gender='\''Female'\'' name='\''ja-JP-NanamiNeural'\''>
音声にしたいテキストデータをこちらに入力します
</voice>
</speak>' > output.mp3
Discussion