この記事は、Sesame AI Inc.の技術記事を解説したものになります
Sesameとは?
- Sesame AI inc.は、スマートグラスを開発しているAIスタートアップ
- 流暢さがほぼ人間と見分けがつかない独自の会話AIモデル「Sesame」を開発
- Xを中心にバズを起こし、大きな注目を集める
Sesameが目指す会話モデルとは?
- 感情的知性がある
- 自然なタイミングでの、休止・強調
- 状況に応じて口調を変化させる
- 一貫した性格
Sesame以前の研究
従来のパイプラインモデル(文字起こし → LLM → 合成音声)では、文字起こしの段階で相手の非言語情報が失われるため、表現力に制限が生じていた。この問題を解決するために登場したのが、Speech-to-Speechモデル(以下、S2Sと表記)である。
先行研究におけるS2Sモデルでは、以下のトークンが利用されてきた。
①セマンティックトークン
- 話者の個性を除いた、「何を話しているか」という内容そのものを表現する。
②アコースティックトークン
- Residual Vector Quantization(RVQ)を用いて生成される。
- 話者の声質や個性を含んだ、「どのように聞こえるか」という情報を表現する。
しかし、これらを使用した遅延パターンでは、N個のコードブックがある場合、最初の音声チャンクの生成までにN回のバックボーン処理が必要となる。これによりリアルタイム性が損なわれ、自然な会話感が失われるという課題があった。
Sesameが提案した新モデル
その名も、CSM(Conversational Speech Model)
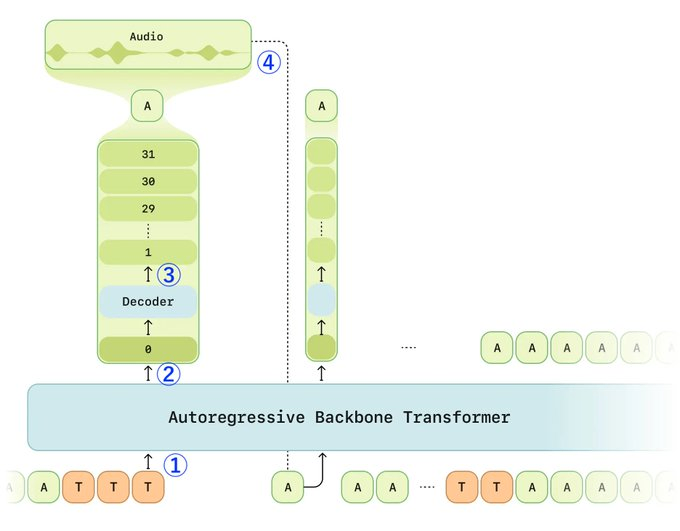
推論プロセスの概要👇(図と合わせて見ると理解しやすいです)
① テキスト(T)と音声(A)トークンが交互に並べられ、順次バックボーンに入力される。
② バックボーンはまず、0番目のコードブックレベルを予測する。
③ デコーダーは、0番目のコードブックレベルを条件として、残りの1〜N-1レベルをサンプリングする。
④ 再構築された音声トークン(A)は、次の処理ステップのためにバックボーンにフィードバックされる。
⑤ このプロセスは、音声終了記号(EOT)が出力されるまで繰り返される。
⑥ 次の推論リクエスト時には、ユーザー発話などの中間音声がテキストとともに処理される。
※ここで言う「コードブックレベル」とは、音声をコンピュータが理解できるように段階的に分解したデータの層を指す。
例として、
0番目レベル:「これは『あ』という母音である」という大まかな情報
1番目レベル:「声の高さはこの程度」という情報
2番目レベル:「声の質感はこのような感じ」という情報
3番目レベル:「少し鼻にかかった音質」という情報
4番目レベル以降:階層を下るほど詳細な情報が表現可能になる
トークナイザーとしてMoshiが開発したMimi(分割Residual Vector Quantizationトークナイザー)が使用されている。
「Mimiと自己回帰型バックボーントランスフォーマー(Autoregressive Backbone Transformer)の役割の違いってなに?」と気になったので整理すると👇
①音声波形をMimiにより離散トークンに変換
②生成されたトークンを自己回帰型バックボーントランスフォーマーに入力
③バックボーンが0番目のコードブックを予測
④デコーダーが残りの1〜N-1番目のコードブックを予測
⑤全コードブックをMimiで再びデコードし、音声波形に復元
CSMモデルの何がすごいのか?
CSMモデルが従来モデルに対して画期的な進化を遂げたポイントはこの2点
- バックボーンとデコーダーの分離点を「0番目のコードブックレベル」に設定したことで、処理を効率化
- デコーダーを小型化することで低遅延を実現
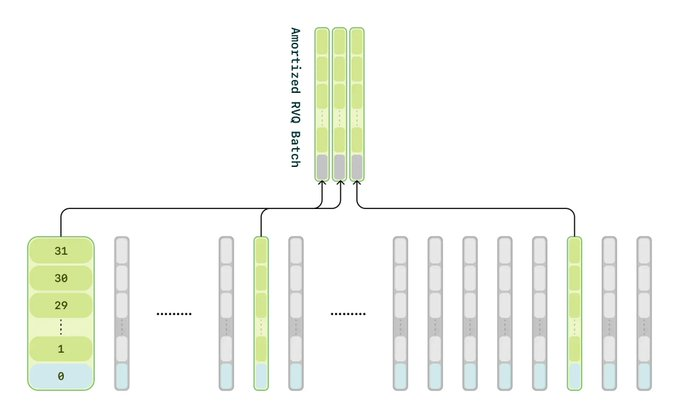
トレーニング時の工夫
音声デコーダーのトレーニングには通常、(バッチサイズ) × (シーケンス長) × (RVQコードブック数)分の計算資源が必要となり、莫大な負荷がかかる。そこでCSMモデルでは、0番目のコードブックレベルについては全データを学習し、それ以降のコードブックレベルについてはデータの1/16のみを学習するという戦略を採用。
その結果、
- トレーニング速度の大幅な向上
- デコーダーの品質には目立った低下なし
トレーニングデータセット
- 文字起こし、話者分離、セグメント化が行われている公開オーディオデータの大規模データセット
- フィルタリング後、約100万時間の主に英語の音声データ
👉それらを使用して、Tiny、Small、Mediumの3つのモデルサイズを作成
評価指標
指標はこの5つ
- WER(ワードエラーレート)
- 話者類似性
- 同形異義語の正確性
- 発音一貫性
- 主観的な評価
ワードエラーレート
・生成された音声をテキストに変換した際のエラー率(低いほど良い)
結果:人間と同等の性能
話者類似性
・元の話者の性質を真似られたか?(高いほど良い)
結果:ほぼ完璧にトレース

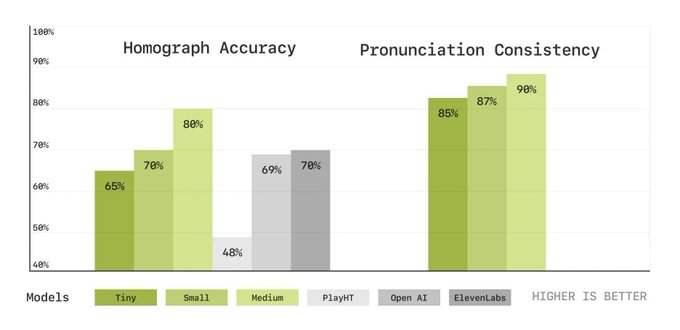
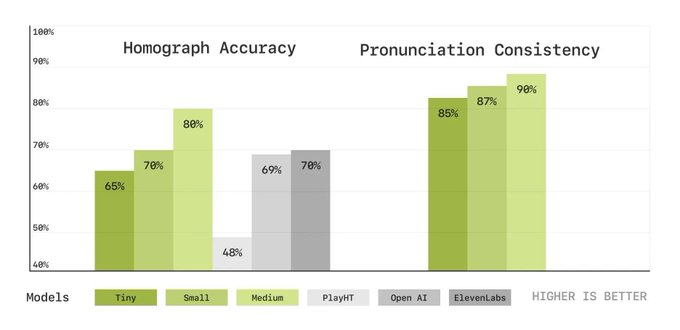
同形異義語の正確性
・例:「しじょう」を文脈から判断して、「市場」「史上」など使い分けができるか?
結果:図の左側。Mediumが80%でElevenLabsよりも10%改善
発音一貫性
・例:同じコンテキストで「明日」を「アシタ」「ミョウニチ」「アス」など発音がブレないか?
結果: 図の右側
主観的な評価
人間に「どちらの表現が人間の話し声に似ているか」を判断してもらうタスク
・ポンだし(文脈なし)場合、人間よりもSesamiの方が52.9%も「人間らしいと評価」
・コンテキストありの場合、上記よりも若干減り、33.3%が「人間らしいと評価」
文脈がなければ人間と区別がつかないレベル。ありでも1/3の人はAIとは気づかない。
最後に
nocall株式会社では、MoshiやSesameなどのSpeech to Speechを作りたい機械科学習エンジニアを募集しています
Xをフォローしてください!
カジュアル面談はここから👇

Discussion