Goとマルチコアスケール実装
マルチコア化の未来予測
半世紀前にSF映画「2001年宇宙の旅」に登場するコンピューターHAL-9000が並列コンピューティングの未来を示しました。マルチコアで構成されたコンピューターの物理コアを取り除いてもすぐにクラッシュせずに性能ダウンして処理が継続するという演出がありました。
当時ですらシングルコアコンピューティングの限界が予想されていて、現状のコンピューティングがマルチコア化しているという未来をしっかり予測できていたことがわかります。
演出はコア数に応じてコンピューティング性能がスケールしていることを表現しています。これはマルチコアスケールするソフトウェア実装の未来を示していたと思います。
シングルコア性能向上の頭打ち
2003年以降あたりはCPUの動作周波数が伸び悩み出したところ。
https://queue.acm.org/detail.cfm?id=2181798 より
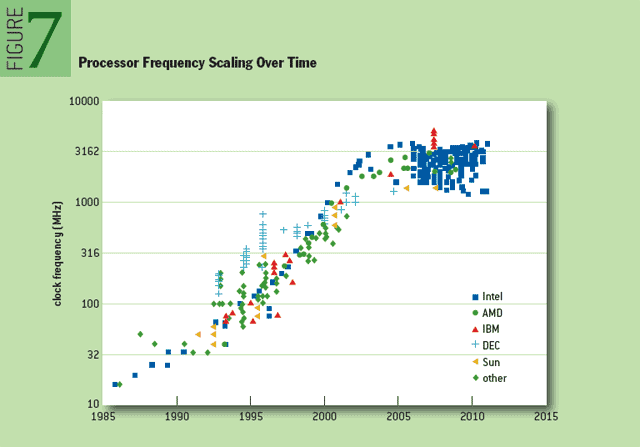
その後もシングルコア性能でみるとちょくちょく上昇はしているけれど、これはキャッシュ増量や予測アルゴリズムの改善によるキャッシュヒット率向上、省電力化によるブースト(オーバークロック)の結果であり、これらはどんなコードもいつでも早くなるというものではありません。
フリーランチの終焉
2003年くらいまでは、同じソフトウェアはハードウェアの性能向上の恩恵を受けて勝手に性能が上がっていきました。この現象は俗に「フリーランチ」と呼ばれていましたが、その恩恵は事実上終了してしまったのです。
つまり2003年以降、性能の向上にはソフトウェア側にも工夫が求められることになりました。
シングルコアに対するソフトウェアの工夫
- SIMD命令への落とし込み
- キャッシュにCPUヘビーなコードやデータがまるまる載るような最適化
マルチコアに対するソフトウェアの工夫
- マルチコア化したハードウェアに適応した実装
つまり、ハードウェアの全体性能の向上はキャッシュやコア数の増量という形で今もなお進歩しているのですが、その恩恵を受け取るにはソフトウェア側にも適応した実装が求められるようになったということです。
プログラミングパラダイムシフト
マルチコア化したハードウェアに適応した実装を求められつつも、依然として多くのプログラマーは多くのケースで「シングルスレッド」または「軽量スレッド+非同期」なコードを書きます。それではシングルコアまでしか活かせないのですが、その理由は?
- PCのコア数が伸び悩んでいたこと
- マルチコアスケール実装を書くのが複雑かつ面倒であることやノウハウ不足
などが挙げられます。
現時点でPCのコア数は下手をするとスマホよりも少ないのが現状です。これはインテルのPC向けCPUのほぼ独占状態がしばらく続いたことと、半導体プロセスの進歩が停滞していたことなども少し影響しています。しかし、AppleのM1を筆頭に今後はPCのコア数は8個以上が一般化するでしょう。クラウドサービス側ではすでに64〜128コアというものも利用可能になってきています。
そうなってくると、ヘビーな処理をするアプリケーションが1コアしか使えないというのはかなり煙たがられるようになるでしょうし、競合ソフトがマルチコア対応を出せば処理時間の短さで負けてしまいます。
自力でのマルチスレッド活用はアプリケーションコードの書き手にかなりの労力を必要とします。そして別のアプリケーションを書くときにも同じように多くの労力を要求します。調整がアドホックにならざるを得ないため要件ごとに多くの調整時間が必要になります。
そこで研究や新しい言語処理系ではマルチコアスケール実装をより容易に書けることを目標にしているものが増えてきました。これは長い時間をかけたプログラミングパラダイムのシフト、つまり変革期にあるということなのです。
マルチコアスケールを目標とする言語処理系の歴史
1980年台半ばあたりから、マルチコアスケールすることを見据えた実用言語が開発され始めます。
- 1986年にErlang
- 1987年にOccam(2、それ以前は研究レベルでしか使われていない)
- 1992年にGHC(Haskell)
- 2012年にPony(Erlangの並行モデルを持つ静的型処理系)
これらの言語処理系の特徴は生まれながらにして並行・並列処理を意識した実装が書けるようになっているところ。特にOccamはTransputerという専用ハードウェアと連携し数十コアの運用を実際に作ることができました。
学生の頃にOccam+Transputerに触れる機会があり、レイトレーシング実装にてラインごとにタスクを複数のコアに振り分け、結果がチャネルを通してまばらに戻ってくるのは面白かった(1ラインごとに必要な計算総量は変化するので)。
しかしOccamは現在事実上開発は停止していますし、ErlangやGHCも用がある人が使っているというところに留まっているように思います。
後付けで並行・並列処理を書けるようにしようというライブラリも生まれました。
- 2009年にJava/Scala向けのAkka(Erlangインスパイアード)
Akkaはライブラリというよりはフレームワークというべきものになっていますし、これもまた用がある人が使っているというところに留まっているように思います。
いずれも、細かい設計思想が異なる部分はありますが、チャールズ・アントニー・リチャード・ホーア(Charles Antony Richard Hoare)考案のCSPを基礎にしているというところは 共通しています。 共通ではありませんでした。
Erlang/Akka/Ponyがベースにしているのは「Actorモデル」と呼ばれ、CSPに似た概念ですが、CSP以前にHewittらにより発明されているとの指摘がありました!
アムダールの法則
コア数を増やした時にマルチコア分散したときのシングルコアに対する性能向上比率には「並列度」に応じた理論上の限界があります。「並列度」とは並列に動けない時間と並列に動ける時間の比で、完全に並列に動ける状態を「並列度100%」という状態と表現します。
- 並列度P=並列時間/(並列時間+not並列時間)
- 並列数N
このとき、並列数1(シングルコア動作)に対し性能向上の期待値は以下の計算式になります。これをアムダールの法則といいます。
そして、Nを無限大とした時、理論上の性能向上限界値が得られます。
つまり並列にできない動作時間比の逆数の倍率まで性能向上が期待できるのですがこれをスケール性能と呼びます。
- 並列時間比が95%の場合は20倍まで
- 並列時間比が99%の場合は100倍まで
- 並列時間比が90%の場合は10倍まで
- 並列時間比が100%の場合は無限大まで(つまり並列数を増やせば増やすほど性能が伸びる)
すなわち、90%以上の並列度を確保している場合、ほんの数%の並列度向上が大きくスケール性能を伸ばすということなのです。
なのでマルチコアスケール実装を記述するときはミッションクリティカルな処理を行う時に如何にして並列度を高く保つかということが重要になります。
並列に動作できないものというのは突き詰めていくとハードウェアの課題と
ソフトウェアの課題によるものがあります。
- 主メモリやストレージにアクセス可能なコアは一つだけ(キャッシュはある程度独立)
- ネットワークインターフェースやBluetoothなど
これらのハードウェアにおけるアクセスについては、CPUのメモリやストレージ、ネットワークなどもバッファを持っていてバスの限界速度を長時間常に占有し続けることはほとんどなく、空き時間をうまく使い回すというようなハードウェア上の工夫があります。
ソフトウェアで求められる工夫とはタスクが並列に動くときに他のタスクをブロックする(待たせる)ようなことをできるだけしないということです。
フリーランチの再来
ソフトウェアは並列度を高く保って実装されれば、前述のアムダールの法則により環境投資からの性能向上の余地が生まれます。逆に並列度が低ければある程度コア数を確保してしまったその後はコア数を増やしてもたいして性能が向上しなくなります。
ソフトウェアの並列度を高く保つことができたなら、フリーランチは再びやってくるということになります。
マルチコアスケール実装パターン
マルチコアスケールを目標としない汎用言語処理系でそういう実装が書けないのかというとそんなことはありません。実際に採用されるメジャーな手法は以下のいずれかになります。
- 忙しい処理を2〜3のネイティブスレッドにアドホックに分類してマルチスレッドプログラミング
- 協調型軽量スレッドと非同期I/Oとによる並行プログラミング+RPCによるマルチプロセス構成
- M:Nスレッドシステムの構築とその利用
ネイティブスレッドの課題
ネイティブスレッドへのタスクの分類は実装者が手作業で分類する場合バランス良く行うのは難しく、特にタスクの負荷の変動が大きい場合にバランスさせることは難しい。また以下のような課題もあります。
- 複数スレッド間でシェアするメモリは排他制御が必須
- ネイティブスレッドはガードページを必要とし、メモリの占有量が大きい(1MBなど)
- 一般的なOSでは同時に数百個程度でスレッドスイッチコストやメモリ使用量などによる悪影響が出る
- 一様な実装でいろんなコア構成に最適に動かすのは難しく、多くの場合アドホックな調整が必要になる
- その他の手法に比べトラブルシュートが異常に難解になるため、マルチスレッドを禁止するチームもあった
協調型軽量スレッドの課題
イベント駆動方式であらゆる待ちのある処理を非同期に行うことができるようにして協調型軽量スレッドで処理を並行に行うことを実現する仕組みです。この仕組みはC10K問題をnodeが解決した方法と同じものと考えて良いと思います。
- LL言語で大量のセッションを扱うような場合こちらのスレッドシステムがよく採用されることが多い
- 長くCPUをビジーにしてしまう処理(ブロッキングな処理)がスレッドシステム全体の最短保証レイテンシを悪化させる
- 全てのI/O待ち(時間待ちを含む)を非同期に行う必要がある(同期的に完了を待ってしまうとそこでタスクシステム全体が止まってしまう)
- 各タスクはベストエフォートで微小時間以内に完了するように書くか、適切にタスクスイッチを挿入する必要がある
- 共有メモリの排他処理が部分的には不要になるので実装がシンプルにかける
- 異なる協調型軽量スレッドシステムを混ぜてはいけない
- 協調型軽量スレッド単体では以下のMultiple CPU Danceと同じ状況になる
Multiple CPU Dance
(現代のCPUはヒートアップしたらクロックダウンして熱暴走を防ぎますが)
マルチコアに分散するには、これに加えた何らかの追加の仕組みが必要ですが、その現実解の一つは「RPCベースの処理分散」です。しかし、これもまたいくつかの課題を呼び込みます。
- マルチプロセス構成になるためランチャー部分の実装が必要
- マルチホストマシン構成も許容可能になる代わりに通信のオーバーヘッドが乗る
- やはり複数のコアに均等に負荷を分散するしかけはないのでアドホックな調整が必要
M:Nスレッドシステムの需要と課題
ネイティブスレッドと協調スレッドを組み合わせたM:Nスレッドシステムというものがあり、この手法であればマルチコアへの均等な分散が可能になります。しかしここまで実装するのは多くの知識とコストが必要であり、利用する側にも多くの認識合わせが必要になります。
- コア別の分散は均等になるようになっていて負荷の偏りは発生しにくい
- 協調スレッドとマルチスレッドの双方の面倒さを意識して実装しなければならない
- ブロッキングな処理を決して混ぜてはならない(CPUを長時間占有してはいけない)
- 非同期対応していない処理を呼んではならない
- あらゆるI/Oについて非同期対応したライブラリが必要
- 共有するメモリには排他処理が必須
マルチコアスケールをターゲットとする処理系に加え、RustもM:Nスレッドシステムに近い構造を持っており、いずれもランタイムを通してマルチコアに均等に分散させる機能を持ちます。
そこでGoの誕生
そして2009年に生まれたGo言語もまたCSPを基礎としマルチコアスケールを目標とする言語仕様を持っています。
このように生まれ持ってマルチコアスケールする言語処理系というのはレアケースで、他の多くの言語処理系ではシンプルにコードを書けることを優先してマルチコアスケール性能をあえて捨てるということを採用している処理系も多かったりします。
例えばPerlやRuby、Python、Node、Nimはランタイムをシングルスレッド動作に固定しているためにマルチコアスケールさせるのには多くの課題が発生します(マルチプロセスを必要としたり、各スレッドにランタイムを展開するためにメモリ使用量が増大するなど)。
2007年にNim、2010年にRustが誕生していますが、これらは非同期・並行処理の標準サポートは後回しになっており、Nimは2014年ごろ、Rustは2019年ごろになってようやく標準サポートになりました。
PerlやRuby、Python、C/C++、Java、C#、D、Nim、Swift、Rustなどは非同期・並行処理をライブラリや言語機能追加にて後付けしてきた処理系です。さらにこの中でM:Nスレッドのようなマルチコアスケールをサポートしているものはさらに限定的です。
Goは生まれながらにしてM:Nスレッドシステムに近い仕組みを持っていますが、さらにその欠点のいくつかはGoなりの解決を図っています。
Go誕生以降の世の中の動き
KubernetesやECSなどのメニーコンテナ技術の活用でシングルコア実装でも十分な性能を確保できるようになったことが挙げられます。コンテナ技術の台頭でマルチプロセス構成でマルチコア性能を活かすことができるようになりました。
その上で動かす実装はシングルコア実装+RPCで良いという割り切り。これもマルチコアスケールな実装を実現する一つの解なのかもしれません。
このおかげでアプリケーション側のプログラミングにおいてマルチコアスケール実装へのパラダイムシフトは延期されたと言えます。しかしKubernetesがGoのマルチコアスケール実装で実現されているように、インフラ寄りの分野ではマルチコアスケール実装へのパラダイムシフトは確実に進んでいます。
Goのスレッドシステムの特徴
- ユーザーは高度に抽象化した「goroutine」というスレッドモデルだけを意識すれば良い
- goroutineはプリエンプティブなため、ネイティブスレッドライクな挙動
- メモリフットプリントが2KBからスタートなので軽量で、ミリオン数実行可能
- ブロッキングを検出した場合ネイティブスレッドにオフロードする仕掛けを持つ
- goroutineの挙動はネイティブスレッドライクなのでユーザーがネイティブスレッドを扱う必要がない
- OS依存を完全に隠蔽していてどのOSでもgoroutineが同じように機能する
- Go誕生時点から言語仕様に組み込まれていて、あらゆるライブラリがこの標準スレッドモデルを対象に実装されている(ただしgoroutineセーフかどうかは別)のでライブラリの分断がない
- 共有メモリの排他処理は依然として必要
ブロッキング回避の難しさとGoの解決方法
- ブロッキング処理とはCPUを長時間占有すること
- どんな処理を「ブロッキング」とするのかは期待するレイテンシによって変化する
- 例えば20ms以下のレイテンシを保証したいとき、20ms以上CPUコアを占有するようなものは「ブロッキング」な処理だと言える
- 瞬時に応答を返すようなシステムコールであってもパラメータによって「ブロッキング処理」に該当してしまったりする
- あらかじめブロックするものとブロックしないものに完璧に分類することは難しい
- ユーザーが意図せずブロッキング処理を記述してしまう場合もある
以上のような困難さに対しGoではランタイム内で長時間のブロッキングを検出した場合、該当goroutineをネイティブスレッドにオフロードする仕掛けを持っています。この仕掛けにより、M:Nスレッドシステムの応答性能を高くキープすることができます。この仕掛けのおかげでブロッキングな処理をgoroutineに載せたときに悪影響が発生しなくなります。
マルチコアスケールする実装の未来
今後はあらゆるコンピューターがますますマルチコアベースの性能向上をしていく中で、マルチコアスケールする実装の需要はどんどん拡大していて、「複雑な仕組みを使いこなせば書けるよ」じゃなく、もっと「カジュアルに書ける」ことはどんどん求められていくはず。
それにはErlangが先駆者で、GoやPonyはネイティブバイナリを出力する強みを加えてきました。しかし、それでもマルチコアスケールする実装をもっとカジュアルなものにするにはもっと多くの支援やノウハウが必要になると思っています。
マルチコアスケール実装を容易にする要件
- 生まれながらに標準のスレッドモデルを持つ
- SSP/MSP(Single/Multiple Stream Processing)またはActor、CSP(Communicating Sequential Processes)モデルの支援機能を持つ
- 任意のコア数に自動的に適応する機能を持つ
- タスクの記述に伴う制約をできるだけシンプルにする
生まれながらに標準のスレッドモデルを持つ
ここが後付けの場合、スレッドシステムが複数生まれたりしてライブラリ資産の分断が生まれてしまいます(スレッドシステムは通常混ぜて使うことは想定されていません)。
例えばRustでは主に現時点でのデファクトスタンダードであるtokioランタイムと後発のasync-stdの2派があります。これらは同じプロセスの中で混在して使うことはできませんので、同じくtokio依存のサードライブラリとasync-std依存のサードライブラリも混在して使うことができません。
切り替えができるスレッドシステムにもメリットはありますが、Goではコントリビューターが言語組み込みの唯一のスレッドシステムの改良に投資する方がライブラリ資産の充実に対し良い結果を産むと判断したようです。
SSP/MSP(Single/Multiple Stream Processing)またはActor、CSP(Communicating Sequential Processes)モデルの支援機能を持つ
共有メモリへのアクセスは排他処理が必須のため多用すると「並列度」を下げる要因になります。マルチコアスケール性能を維持したいなら「並列度」を高くキープする必要があります。そのための解法がSSP/MSPやActor、CSPです。また、他に並列度を高く保つのにはリードライト型ミューテックス、アトミックアクセス、イミュータビリティ、リードオンリーデータ、コピーで独立などのさまざまな手法があります。
任意のコア数に自動的に適応する機能を持つ
M:Nスレッドシステムのようにタスクをコア数分のスレッドプールに割り当てていくような仕組みがあれば実際に処理されるコア数に応じてタスク負荷は分散します。
タスクの記述に伴う制約をできるだけシンプルにする
ネイティブスレッドにも軽量スレッドにも制約はあって、この辺りを隠蔽や抽象化なしに開発者に解放すると、コードを書くときのコストがどうしても小さくできません。単純にM:Nスレッドシステムを組んだ場合、ユーザー側は意識しなくちゃいけないことの煩雑さにより、じゃあシングルスレッドモデルで組む方が安全確実だという印象を持ってしまいます。(特にRDBを利用するアプリケーションの場合、応答性能はRDBが支配するようになるのでシングルスレッド+非同期I/Oで十分という判断になりがち)
ただし、性能要求は今後拡大します。その時にマルチコアスケールする実装を選択肢に含めるのが一般的になるでしょう。この場合、ユーザーが複雑なマルチコア実装と向き合い疲弊するよりは、もっとカジュアルにマルチコア実装を記述できる支援のある言語処理系を使う方が良い結果につながると思っています。
マルチコアスケール実装の細かい課題
- アトミックアクセス(Go、Rust、Pony、他)
- ブロッキング処理のオフロード(Go)
- プリエンプティブ軽量スレッド(Go、GHC)
- デッドロックの検出(Go)
- デッドロックの静的解決(Pony)
- 排他処理の静的解決(Rust、Pony)
- SSP/MSP、CSPの活用とサンプルコードの充実
- 並列度を高く保つためのノウハウの共有
さらに将来、HAL-9000のように物理コアを増設できるようなものが現れた場合、コア数の変動を受けた時のリカバリー処理なんかも求められるようになるのかもしれない。この辺りはErlangやErlangの考え方を取り入れたPonyの方が向いていそうな気もする(Erlangの軽量processの考え方は「Let It Crash」)。
Goで並列度を高く保つコツ
- ロック待ちになる総時間を減らす(頻度や期間、競合の確率)
- 書き込み競合頻度が少なく同時読み出しが多い場合はRWMutexを使おう
- ロックする範囲を狭くする(ロック範囲の局所化により競合頻度を下げる)
- 排他制御よりもチャネルによるデータ共有やアトミックアクセスを活用しよう
- アトミックアクセスはハードウェア機能で競合を回避する
- 複数コアからの同時メモリアクセスはハードウェア側で優先順位が低いコアからのアクセスを遅延させるという機能が発動することで競合を回避します
- 複数のタスクで共有しているデータの整合性を保つために状況によって処理のシリアライズが必要になってくるが、タスク間の関係性が少なければそうしなければならない頻度は減らせる
- 準備中はミュータブルだが性能が必要な処理中にはイミュータブルなデータであればよいというデータであればそれらのアクセスを区別することで排他ロックで相手を待たせる頻度を大きく減らせるはず
Goはマルチコアスケール実装の期待の星
- これまで述べた要件の多くをGoはカバーしている
- goroutineという単一のスレッドモデルを言語仕様にもつ
- goroutineで実装した並行処理はマシンのコア数分自動的に並列に処理しようとする
- CSPのためのチャネルを言語仕様に持つ
- メモリを直接共有するよりもチャネル通信で共有することを推奨
- ブロッキングかそうでないかに関わらずgoroutineに載せられる
- アトミックアクセスでロック不要なデータ交換を実装できる
- Goらしく記述すること(Goが推奨する書き方にならうこと)が並列度を高く保つ基本になっている
- Go1.0リリース以降、現在に至るまでCSPやスレッドモデルの考え方は変わっていない
- そのおかげでマルチコアスケールする実装資産はかなり充実している
- また、ネイティブスレッドを隠蔽しWindowsがサポートしないforkを使わないため、基本どのOSでも期待通りに動く
マルチコアスケール実装は過去、特定OS+ハイスペックエンジニアだけが実装可能だったけれど、Goはその敷居を大きく引き下げたことでクロスプラットフォームでマルチコアスケールする実装を書けるユーザーを大きく増やしています。
まとめ
- シングルコア性能は頭打ちで将来はもう劇的に伸びることはない
- マルチコアプログラミングパラダイムへのシフトは半世紀前から予測されていた
- いくつかの要素が絡んでアプリレイヤでのシングルコアプログラミングパラダイムは延命している
- インフラ寄り分野ではマルチコアプログラミングパラダイムが必須になりつつある
- PCを含み、どんどんコア数は増えていく傾向にある
- マルチコアを生かす実装の要求はPCにも求められるようになる
- かつてシングルコアプログラミングで済ますのが現実解になってしまうほどマルチコアプログラミングには難解さがあった
- 将来はコア数を生かしたソフトウェア実装の需要がどんどん伸びる
- 並列度を高く保てば環境投資でソフトウェア性能が向上するフリーランチが再来する
- 並列度を高く保つにはストリームプログラミングやActor、CSP、アトミックアクセスを活用しよう
- 言語埋め込みのスレッドシステムはとても学びやすく、ライブラリの分断が発生しにくい
- これまでは特定OSでパワーのあるユーザーだけがマルチコアスケール実装を書いていた
- Goは初心者でもマルチコアスケール実装が書きやすく、同じコードが主要なOSの多くでそのまま動き、メニーコア環境に適応して動作する
- GoのgoroutineはM:N型のスレッドシステムでかつブロッキングに対する弱点を解決している
- こういった特性をもつ言語処理系はレアで、Goほどシンプルに見える処理系はおそらく他にはない
- Goはマルチコアスケールを意識し、容易に書けるという点でユニーク
- よくGoは突出した言語機能がないと言われるがここだけは突出しているように思う
Goが生まれてから長期にわたって安定した言語機能により、マルチコアスケールする実装の実績は積まれてきました。そうした資産に触れられるだけでも得られるものは多いし、Goを学ぶことでこれからのマルチコアスケール実装を書くのに必要なエッセンスを多く得られると思います。
追記
Discussion
面白い記事で勉強になりました。細かい指摘で大変恐縮ですが、Erlangや、Erlangを参考としているAkkaはCSPではなく、Actor modelをベースとしており、Actor modelはCSPとは異なる概念である認識です。(仮にActor ModelがそもそもCSPをベースにしている等の話があるのであれば後学のため教えて頂きたいです。)
Actorモデルが他のモデルと異なり独自の利点を持っていることは見聞きします。
などなど。出自はちょっと思い出せず申し訳ありませんが、どこかでCSPをより具体的に発展させたものとしてActorモデルが紹介されていたものを読んだ気がします。今回のCSPという単語はActorモデルを内包しているものとして読んでください。
少なくともHewittらがアクターモデルについて初めに発表した論文にはCSPは登場せず、アクターモデルがCSPを具体的に発展させたものというのは誤りである可能性が高いように思います。
CSPとアクターモデルの違いに関してはこちらも参考になるかと思います。
(記事の本質では無いところに長々と突っ込んですみませんでした)
Actorモデルのほうが早く生まれていることを考えると、たしかに「アクターモデルがCSPを具体的に発展させたもの」というのは誤りですね。
ただ、以下のセクションにて、CSPとActorモデルは概念的に似た存在であると書かれていて、細かいところの考え方が大きく異なるというのが僕の認識です!
誤解を生みそうなところは修正させていただきました!ご指摘ありがとうございます!
GHCはマルチコアサポートに関する機能についてGoより不足するところがあるとは思っていません。ただ、マルチコア実装を入門するならよりカジュアルに書けて一瞬でコンパイルできるという点でGoがおすすめです。でも確かに移行するのに十分な機能があるのでしょう。直接お話ししたことのある人でGopherハッカーからHaskellerになった人が居ますよ!