Amazon DevOps Guruを使ってみた
Amazon DevOps Guruとは
機械学習を利用して開発者と運用者がアプリケーションパフォーマンスと可用性を向上させるためのヒントを提示してくれるサービスです。
サービスとしてはサーバレスアプリケーションに向けたAmazon DevOps Guru for Serverlessと、RDSに向けたAmazon DevOps Guru for RDSが提供されています。
また、こちらで検出されるインサイトには2種類あります。
- 事後的(リアクティブ):異常が発生した際に通知される
- 予測的(プロアクティブ):異常が発生する前に通知される
Amazon DevOps Guru for Serverless
アプリケーションの問題をプロアクティブに検出し、事前にレコメンドしてくれるというのが最大の特徴です。例えば、Lambdaを利用している場合、同時実行数の設定ミス等でアプリケーション全体のパフォーマンス低下を引き起こす可能性があります。このケースでは影響の重要度や正常に稼働するための推奨同時実行数を提示するなどの洞察が得られます。
さらに、Amazon CodeGuru Profilerと統合されているので、Lambdaのコードで不備がないかについてもチェックすることが可能です。
Amazon DevOps Guru for RDS
もともとRDSに関しては Amazon RDS Performance Insights がありましたが、DevOps Guruに統合されました。
これによって、RDSのパフォーマンスに関して一元的に分析し、異常を自動検出できるようになりました。DBインスタンスのOSのメトリクスまで様々なテレメトリが収集され、問題解決がより迅速に行えます。
アプリケーションメトリクスについて
どのようなメトリクスが見れるのか見ていきたいと思います。今回はServerless版のものを見ます。
なお、今回取得しているメトリクスはこちらのWorkshopで出力されたものを確認しています。
ダッシュボード
ダッシュボードにはDevOps Guruを適用したアプリケーションの一覧が確認できます。なお、アプリケーションは「アカウントの特定リージョン全体」か「CloudFormationの特定スタック」のどちらかで設定することになります。以下は「アカウント内の東京リージョン全体」で設定した場合の画面イメージです。
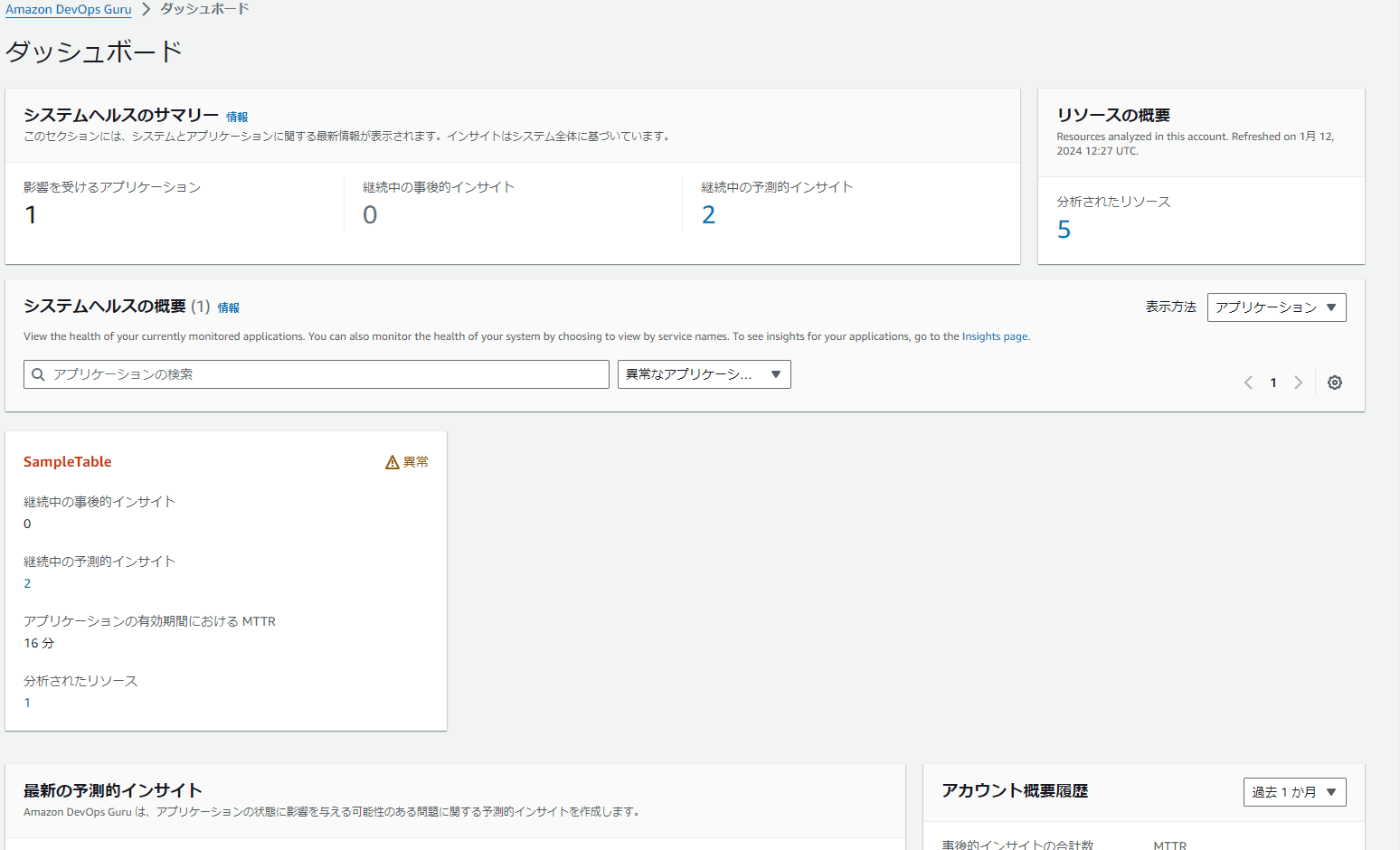
内部的な仕組みとしては、CloudFormationのスタックで定義されるアプリケーションリソースに対応するCloudWatchやCloudTrailのメトリクスやログをGuruに送信して、内部でインサイトを得るという構成になっています。
事後的インサイト
すでにアラートが出力されたインサイトについてはこちらで表示されます。
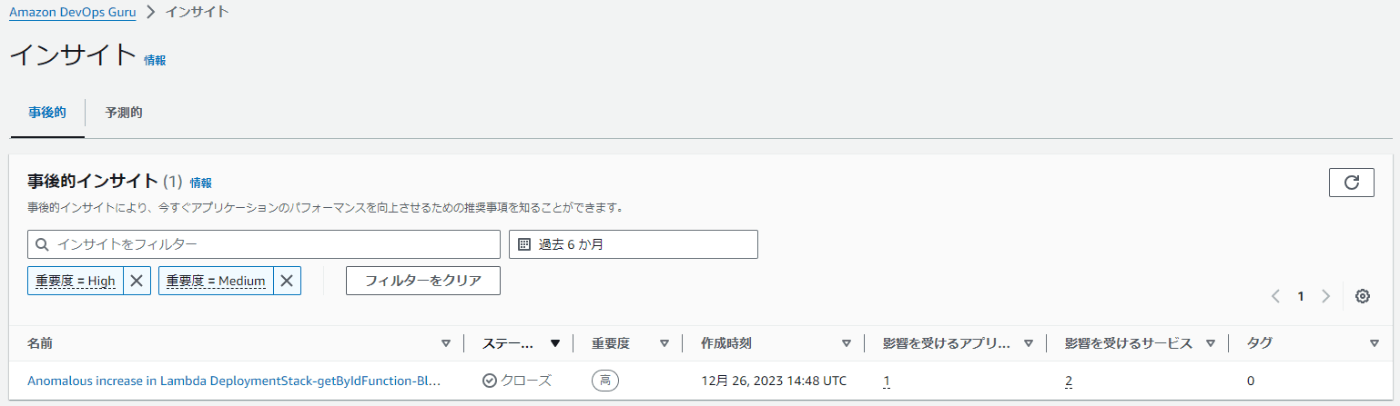
今回は以下の事後的インサイトが表示されています。
- Anomalous increase in Lambda DeploymentStack-getByIdFunction-Bl6xc0t4ezIS duration due to increased number of invocations
これはWorkshopの課題6で性能試験を実施した際に待ち時間が発生していた内容と一致します。アプリケーションの実行を止めているので、メトリクスが正常値に戻りクローズ状態となっていますが、本番環境でこのような検知があった場合は、正確にボトルネックを調査して対処する必要があります。その手助けになるのが、このインサイトのメトリクスやレコメンデーションという訳です。
インサイトのページに行くと、グラフが見れます。(一覧にしているので若干小さいかもしれません。)
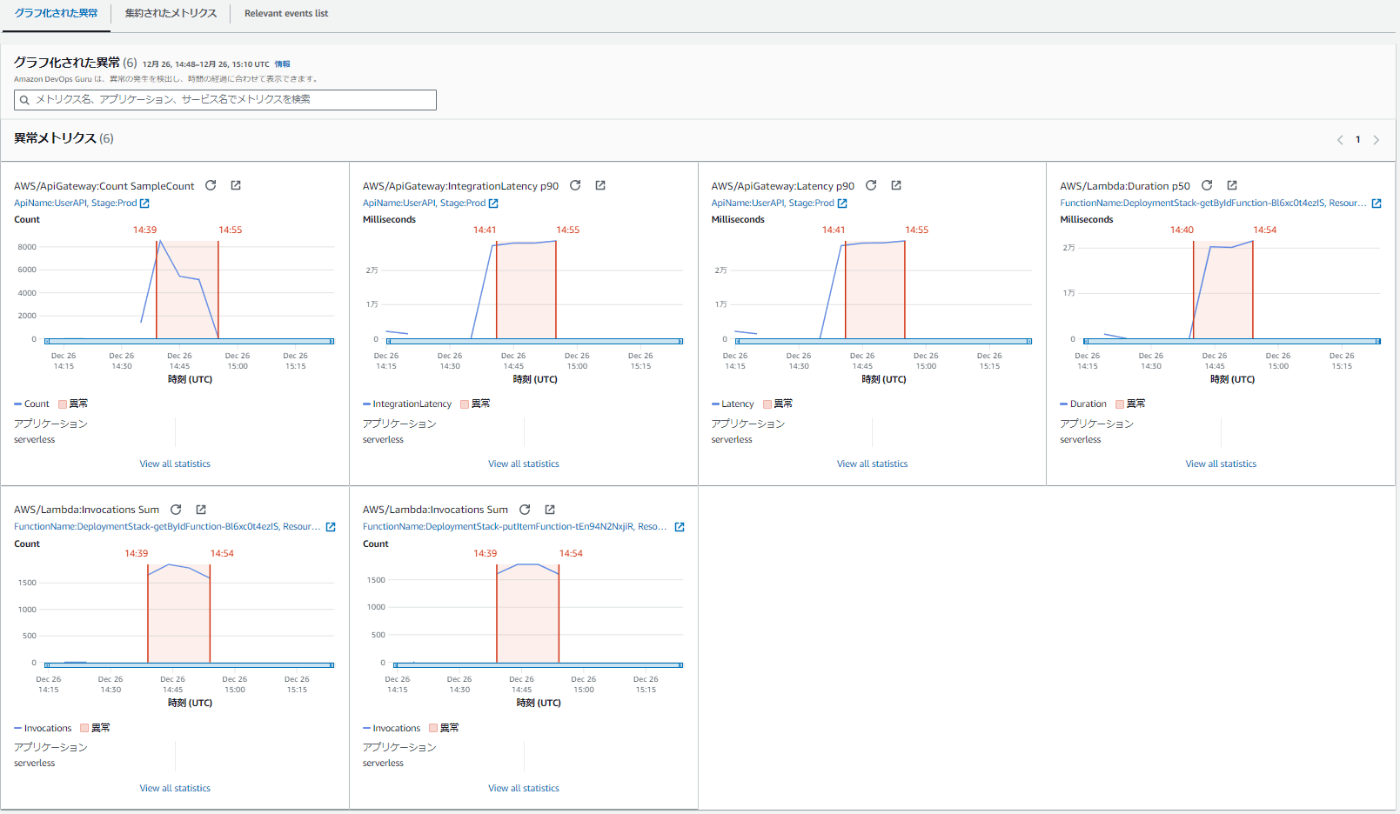
さらに先ほどのグラフをさらに集約したものもタブを切り替えることで確認できます。また、Relevant events listのタブに切り替えると関連するリソースが一覧で表示できます。
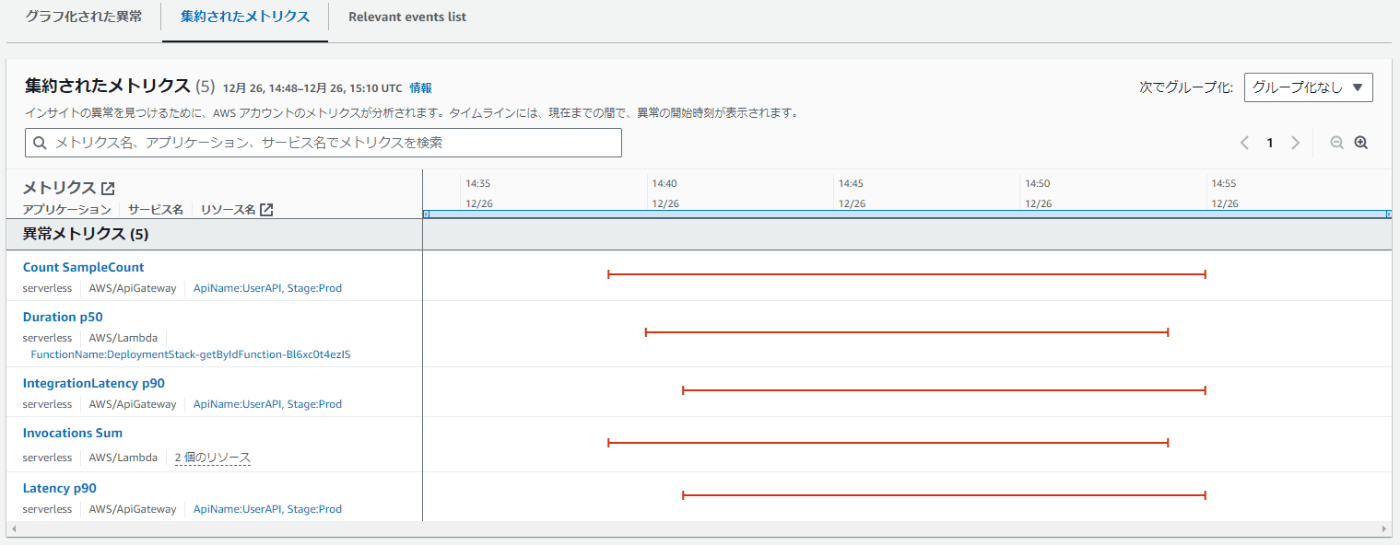
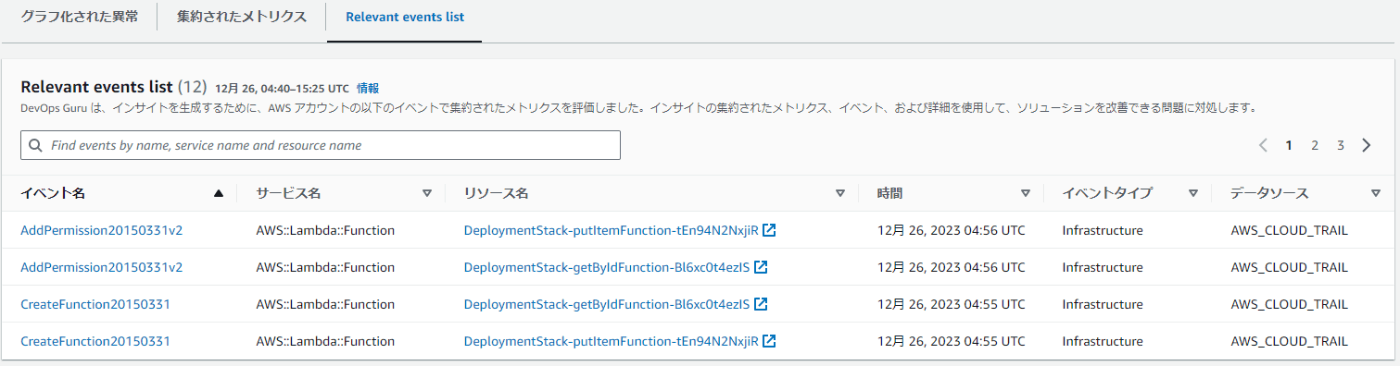
このように、エラーの原因となるメトリクスやリソースが一元的に確認できる点が非常に便利です。また、各リソースページにもそのまま飛べるのはAWSならではかなと思います。
レコメンデーション
このインサイトに関連する解決策のレコメンデーションが提示されます。
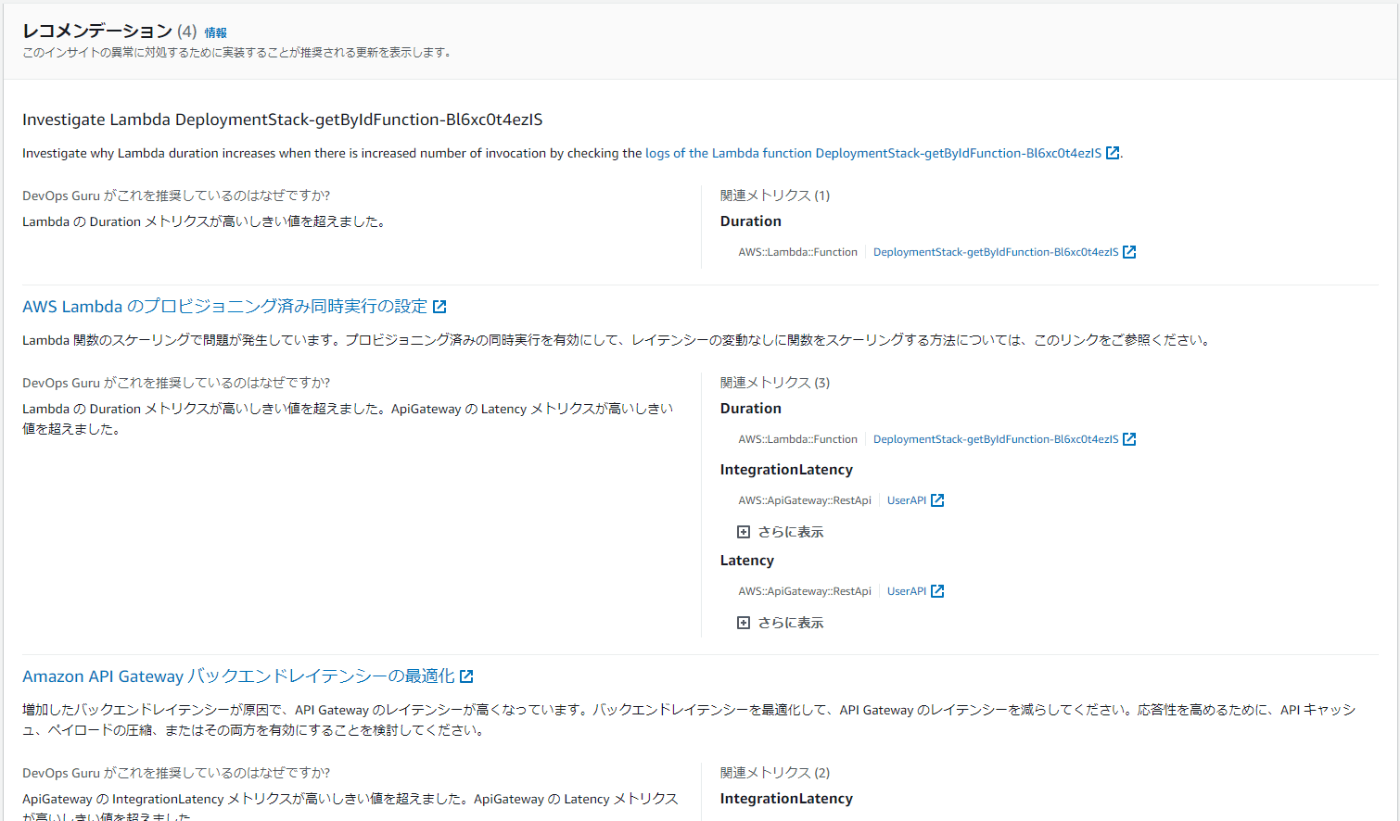
今回はアプリケーション全体でレイテンシーが悪いという検知で、それに関連するLambdaの同時実行数の変更やAPI Gatewayのキャッシュ戦略などがレコメンドされています。これをもとに実際に改善策を練っていくことが出来ます。
予測的インサイト
インサイトの項目を選択することで、DevOps Guruで設定されているベースラインにそぐわない問題があると検知されたものの一覧が確認できます。
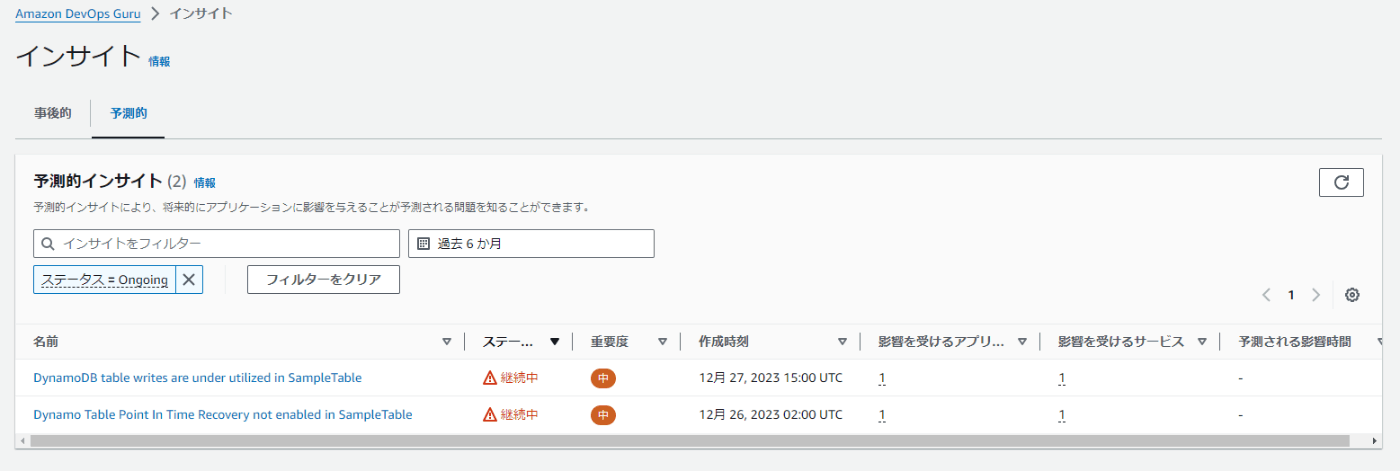
今回は以下の2つが予測的インサイトとして検知されています。
- DynamoDB table writes are under utilized in SampleTable
- Dynamo Table Point In Time Recovery not enabled in SampleTable
さらに各インサイトをクリックすると詳細が確認できます。
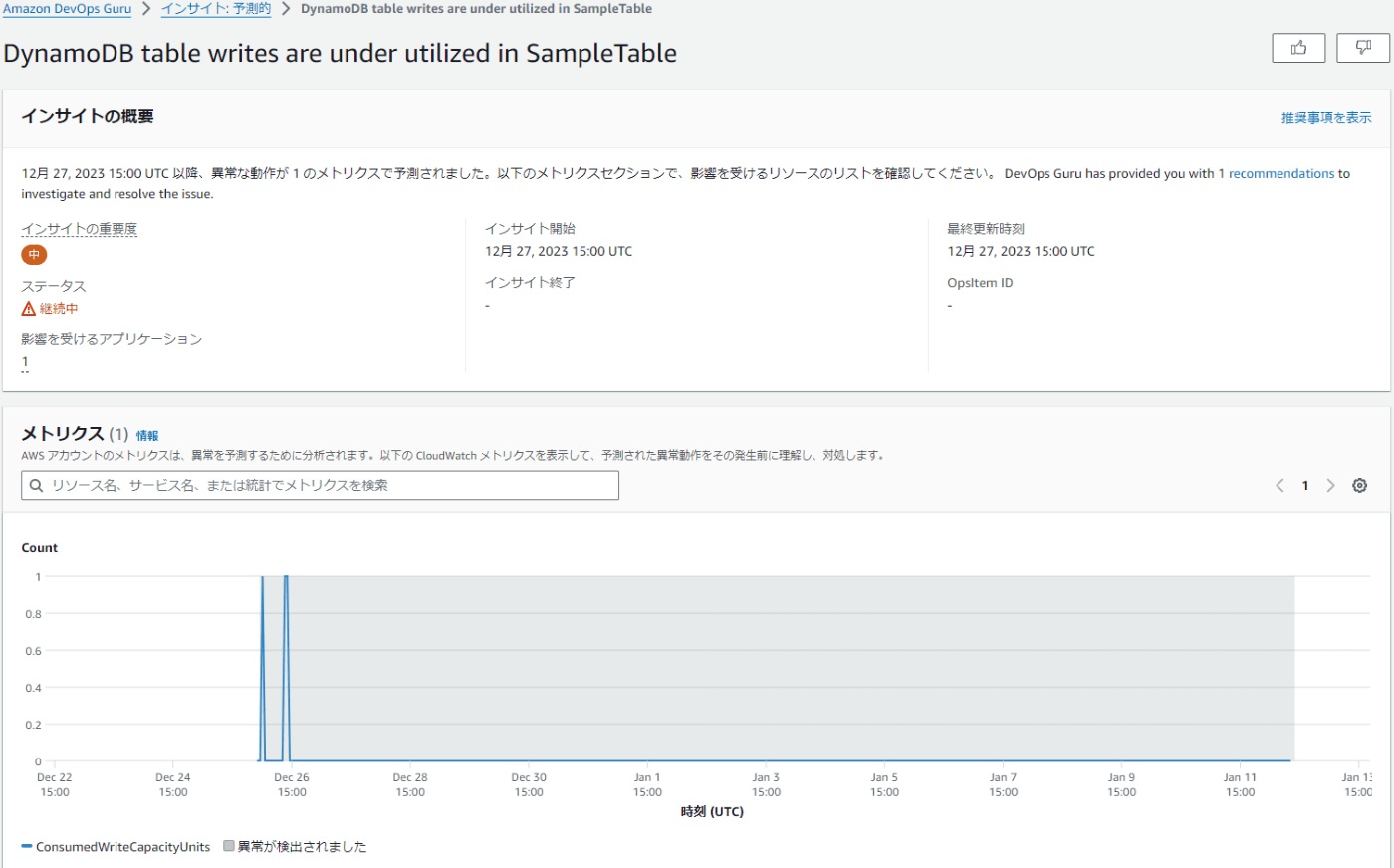
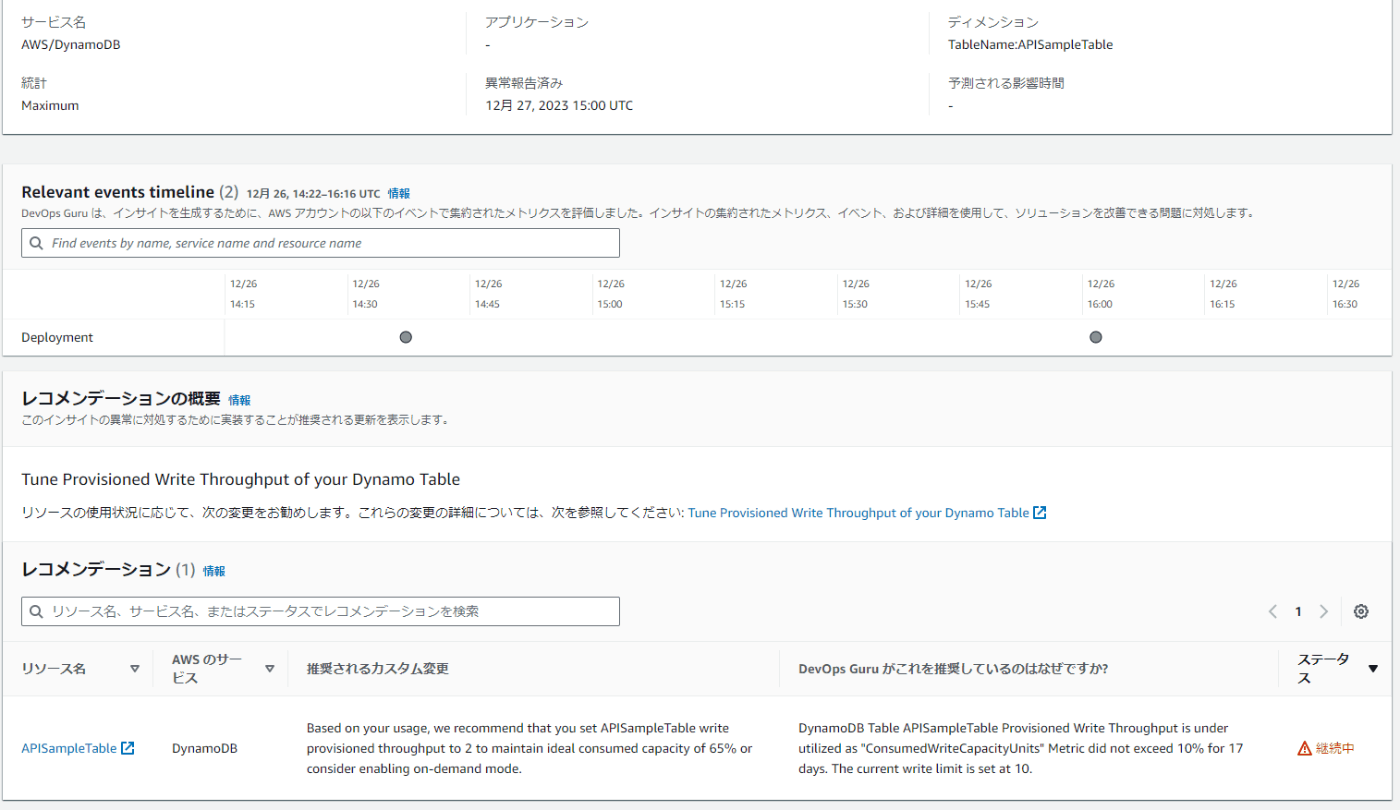
項目の説明は以下の表でご確認ください。
| 項目 | 説明 |
|---|---|
| インサイトの重要度 | インサイトの作成に寄与した最も重要度の高いイベントレベルが設定されます。このレベルはAWSが独自に定義するものです。 |
| ステータス | インサイトの状況(継続・終了)が表示されます。 |
| 影響を与えるアプリケーション | このインサイトによって影響があると考えられるアプリケーションの一覧が確認できます。 |
| 開始日時 | インサイトが最初に検知された日時を示します。 |
| 終了日時 | アプリケーションの改善によってインサイトがクローズされた日時を示します。 |
| 最終更新時刻 | インサイトの情報が更新された日時を示します。 |
| メトリクス | このインサイトをオープンにするに至った異常なメトリクスをグラフ表示します。 |
| Relevant events timeline | インサイトを作成するために評価された期間を示します。 |
| レコメンデーションの概要 | このインサイトを解決するために推奨される対策が表示されます。 |
レコメンデーション
DevOps Guruの一番のポイントは、このレコメンデーション機能だと思っています。
この例では、DynamoDBに対してオンデマンドモードへの変更やWCUの変更が提示されています。
Based on your usage, we recommend that you set APISampleTable write provisioned throughput to 2 to maintain ideal consumed capacity of 65% or consider enabling on-demand mode.
さらに、そのレコメンドに対して理由まで提示してくれています。今回はWCUを10に設定していることで消費されたWCUに対して過剰だというメッセージです。こういった点でコストの削減や、逆に拡張判断を事前にすることが可能になります。
DynamoDB Table APISampleTable Provisioned Write Throughput is under utilized as "ConsumedWriteCapacityUnits" Metric did not exceed 10% for 17 days. The current write limit is set at 10.
また、Dynamo Table Point In Time Recovery not enabled in SampleTableに関してのレコメンデーションは、ポイントインタイムリカバリの有効化となっていました。
Enable Point In Time Recovery to ensure data is recoverable.
最後に
DevOps GuruをたまたまWorkshopで触る機会があり、初めて利用してみて非常に効果のあるサービスだと感じたので、簡単に紹介させていただきました。
こういった開発者と運用者が同じダッシュボードから、アプリケーションの問題を特定し改善に着手していくためのツールとしては、AWS内に閉じるアプリケーションであれば非常に効果を発揮するのではないでしょうか。
ぜひご自身のアプリケーションに対しても有効にしてみてください。最初はミニマムに効果を検証していくことが大事ですが、コスト見積もりをDevOps Guruのコンソールから行うこともできますので、こちらもご活用ください。
なお、今回ご紹介したインサイトは冒頭にも紹介したWorkshop内のServerlessセクションで実践できますので、簡単に検証したい方はそちらも参考にしてみてください。
参考
Discussion