PostgreSQLので全文検索拡張機能、pg_bigmを試す
アプリケーションを開発しているとアプリケーションログの分析や、JSONデータに対する分析など全文検索機能を求められることがたびたびあります。
そういった場合はElasticsearchのように全文検索に特化したデータベースを導入することが多いです。
しかし単純な文章の検索[^特にトランザクション用途]や小規模に利用される場合ばわざわざ専用のデータベースを管理作りたくないというケースが多いです。
今回はPostgreSQLで利用可能な全文検索インデックスの拡張機能であるpg_bigmを紹介します。
検証環境の作成
CloudSQL 構成
- Cloud SQL Editions
- Enterprise
- Database Engine
- PostgreSQL 13.15
- Region
- asia-northeast1(東京)
- Zone
- シングルゾーン
- マシンスペック
- 2 vCPU
- 3.75GB of RAM
- flag
-
cloudsql.enable_pg_bigm- True
-
PostgreSQLのセットアップ
- データベースユーザーを作成
postgresユーザーで下記のコマンドを実行する。
CREATE ROLE test WITH LOGIN ENCRYPTED PASSWORD '********';
GRANT test to postgres;
- データベースを作成
postgresユーザーで下記のコマンドを実行する。
CREATE DATABASE pgbigm_test WITH OWNER=test;
- pg_bigmを有効化
postgresユーザーで下記のコマンドを実行する。
CREATE EXTENSION pg_bigm;
- テーブルを作成
testロールで下記のコマンドを実行する。
CREATE TABLE book_contents (
id SERIAL NOT NULL,
title VARCHAR(256) NOT NULL,
line_num INTEGER NOT NULL,
sentence TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
検索対象のデータセットをロード
今回検索の性能確認には青空文庫のテキストのみアーカイブである、aozorahack/aozorabunko_textを利用します。
インサートを行うスクリプトの詳細は以下を参照。
利用方法はaozorabunko_textを展開したディレクトリで実行。
pg_bigmを利用するテーブルを作成する。
testロールで下記のコマンドを実行する。
CREATE TABLE book_contents_bigm (
id SERIAL NOT NULL,
title VARCHAR(256) NOT NULL,
line_num INTEGER NOT NULL,
sentence TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
CREATE INDEX book_contens_bigm_index ON book_contents_bigm USING gin (sentence gin_bigm_ops);
insert into book_contents_bigm
select *
from book_contents;
pg_bigmを利用する
ここまでpg_bigmを利用するテーブルと利用しないテーブルで検証する準備ができたので、実際にクエリや実行計画を出力して比較していきます。
SELECTの速度を確認する。
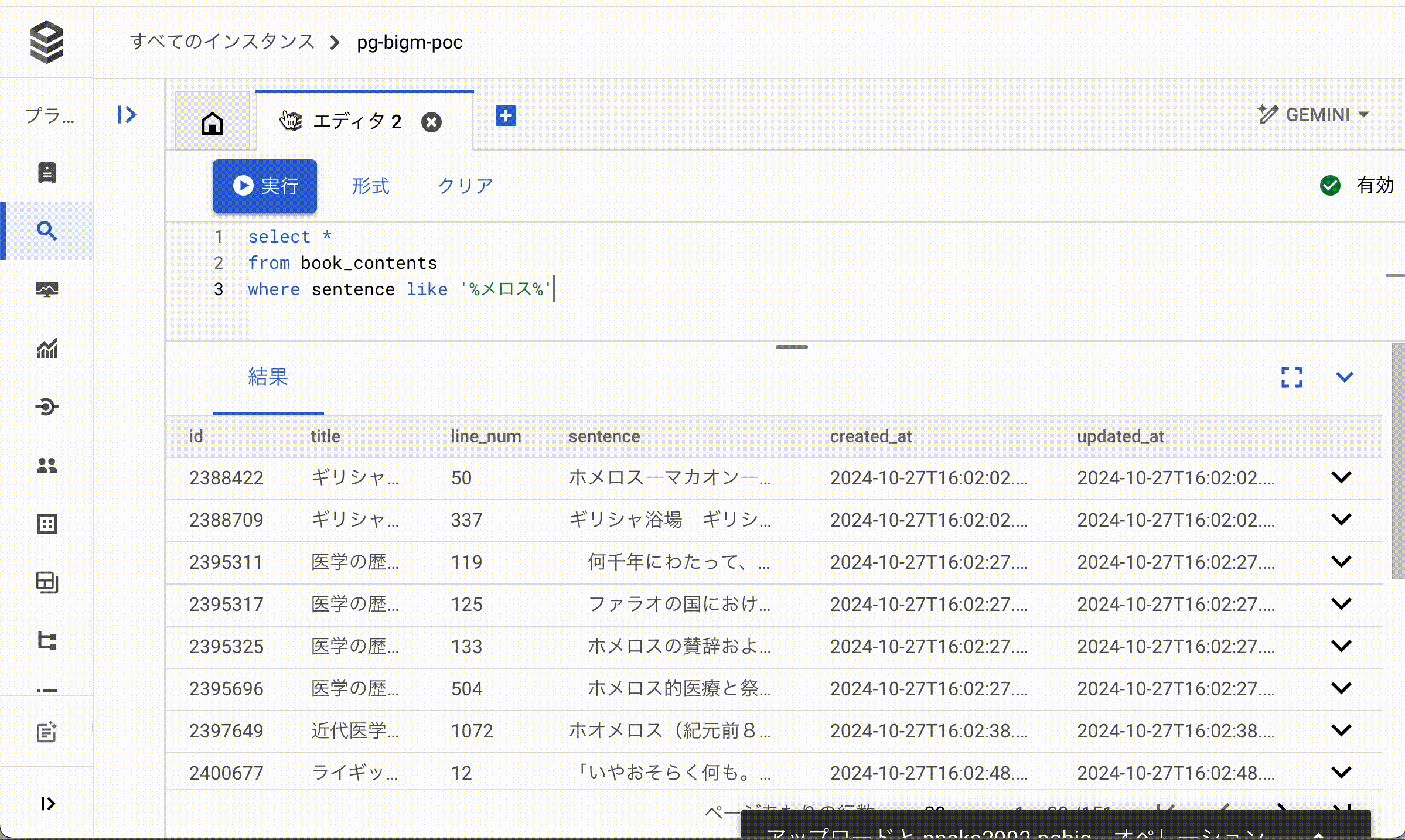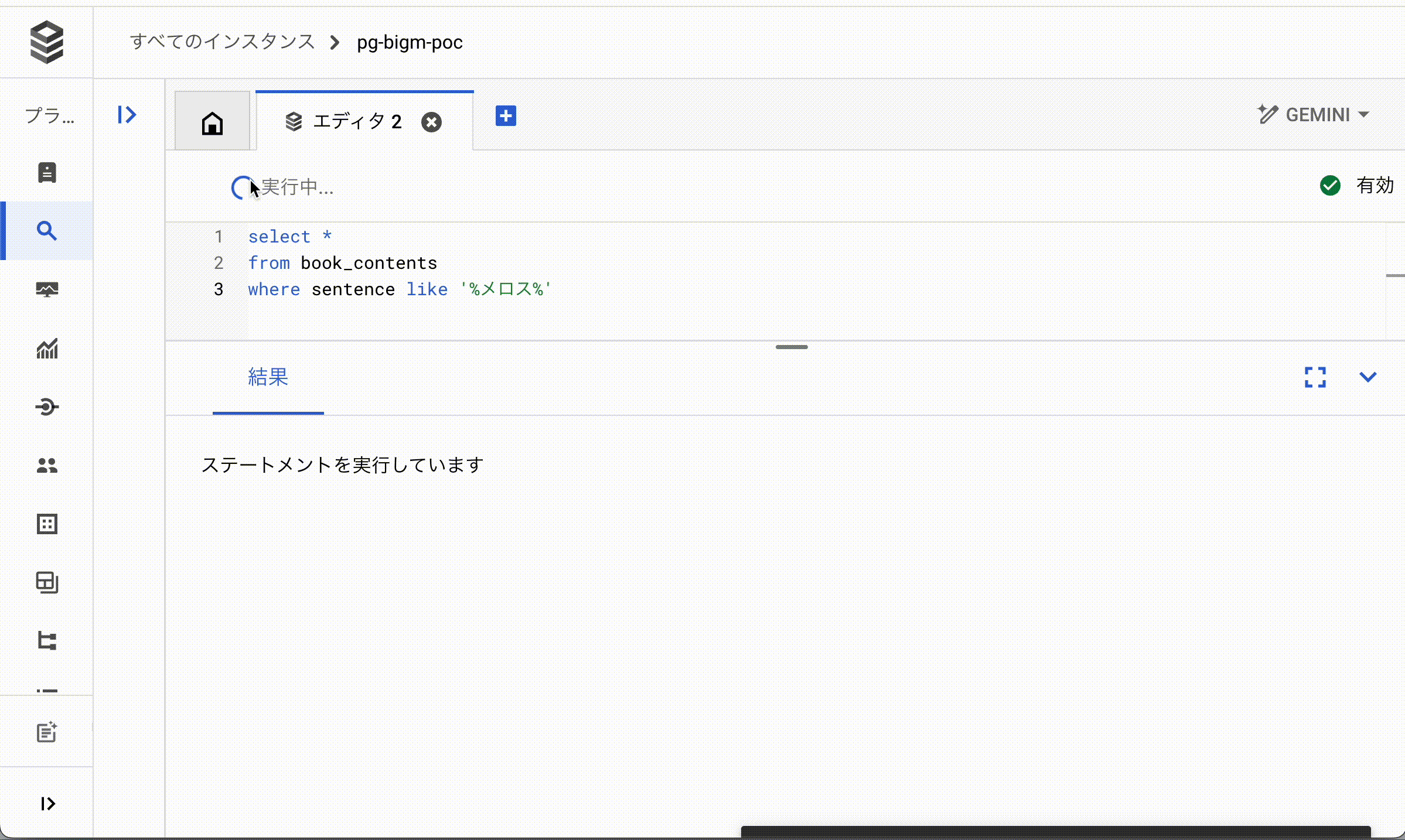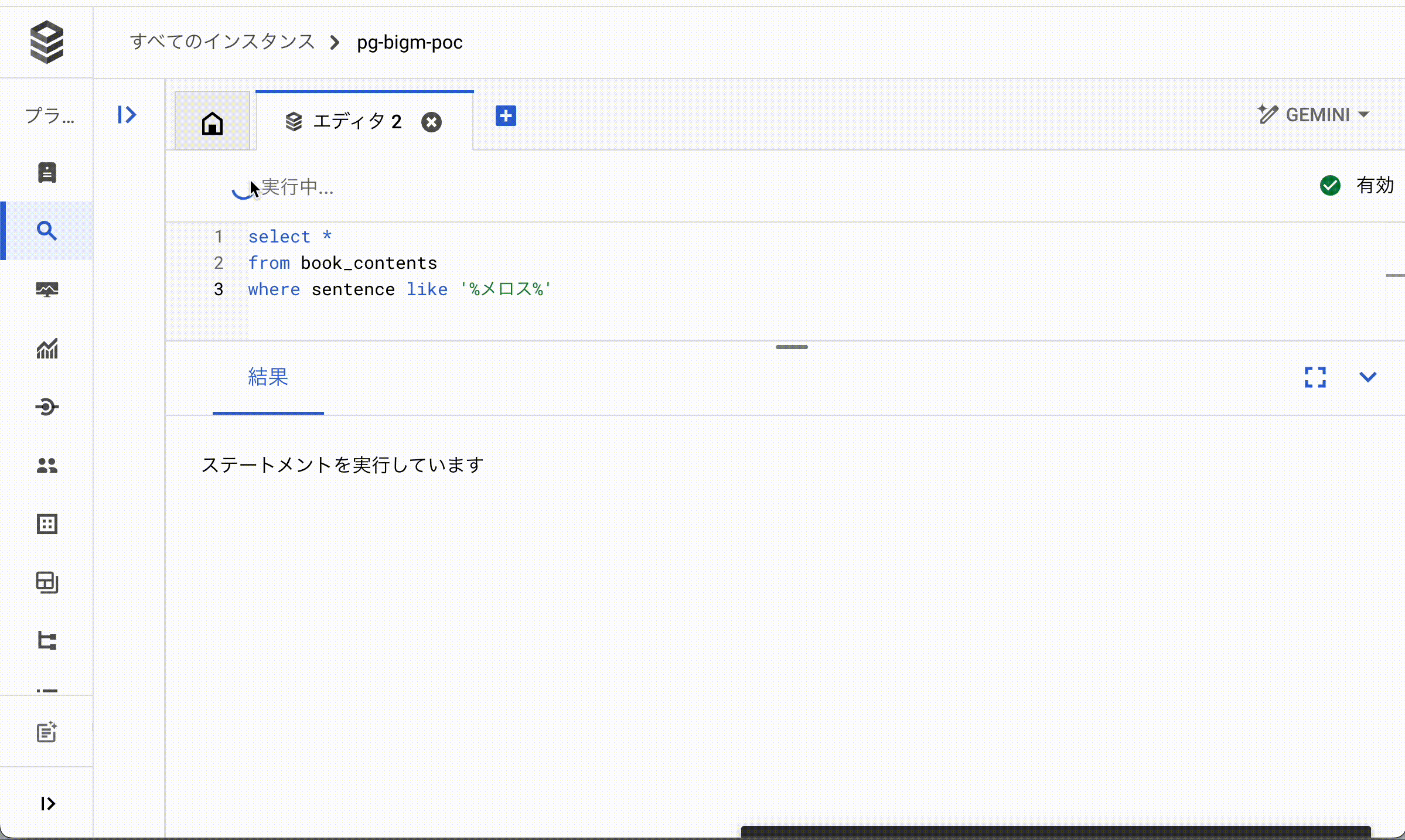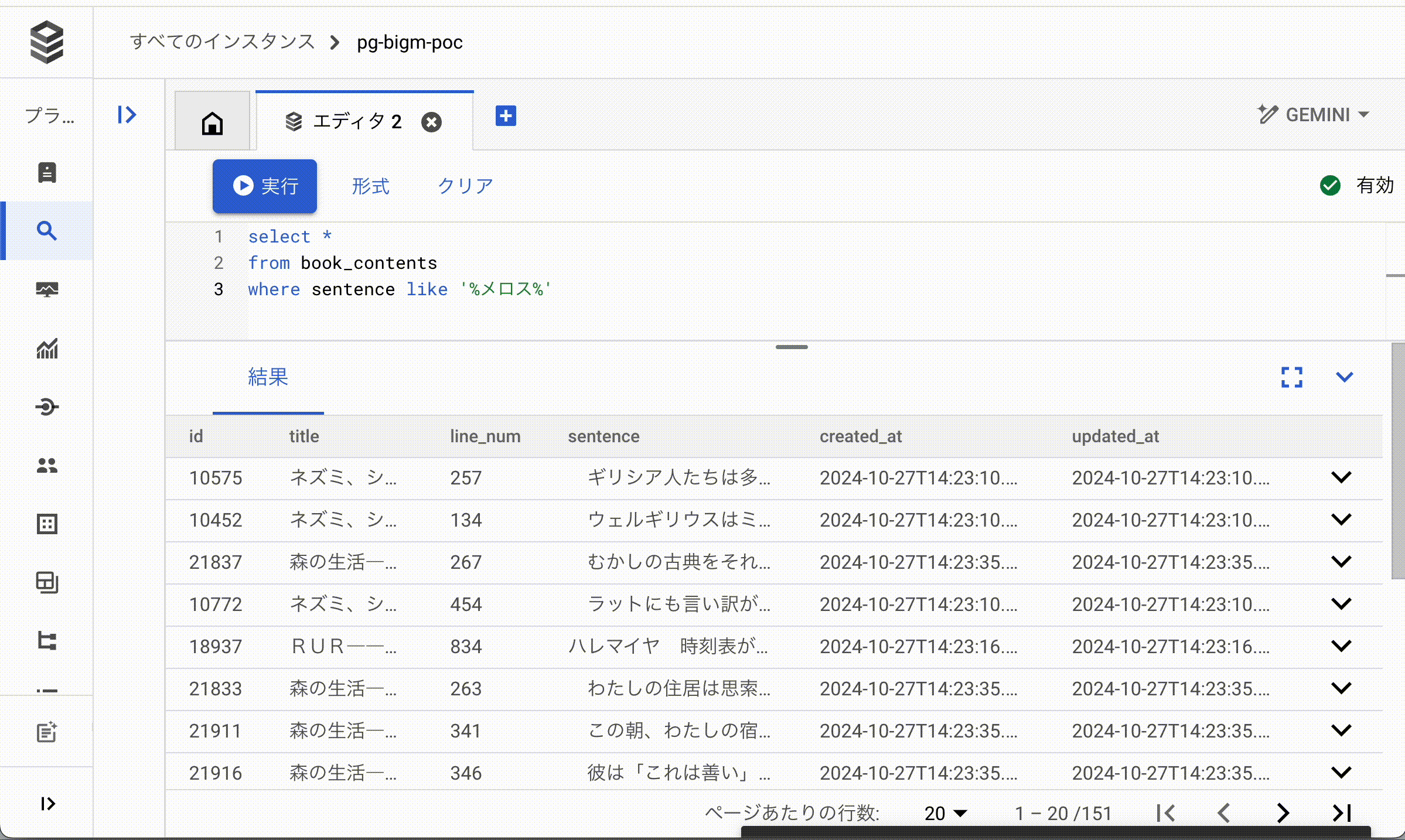
シンプルに日本語文字列の格納されているsentenceカラムに対して%メロス%で中間一致検索を試します。
pg_bigmを利用しないパターン
pg_bigmを利用していないbook_contentsテーブルに対して検索します。
SELECT *
FROM book_contents
WHERE sentence like '%メロス%';
pg_bigmを利用するパターン
pg_bigmを利用していないbook_contents_bigmテーブルに対して検索します。
SELECT *
FROM book_contents_bigm
WHERE sentence like '%メロス%';
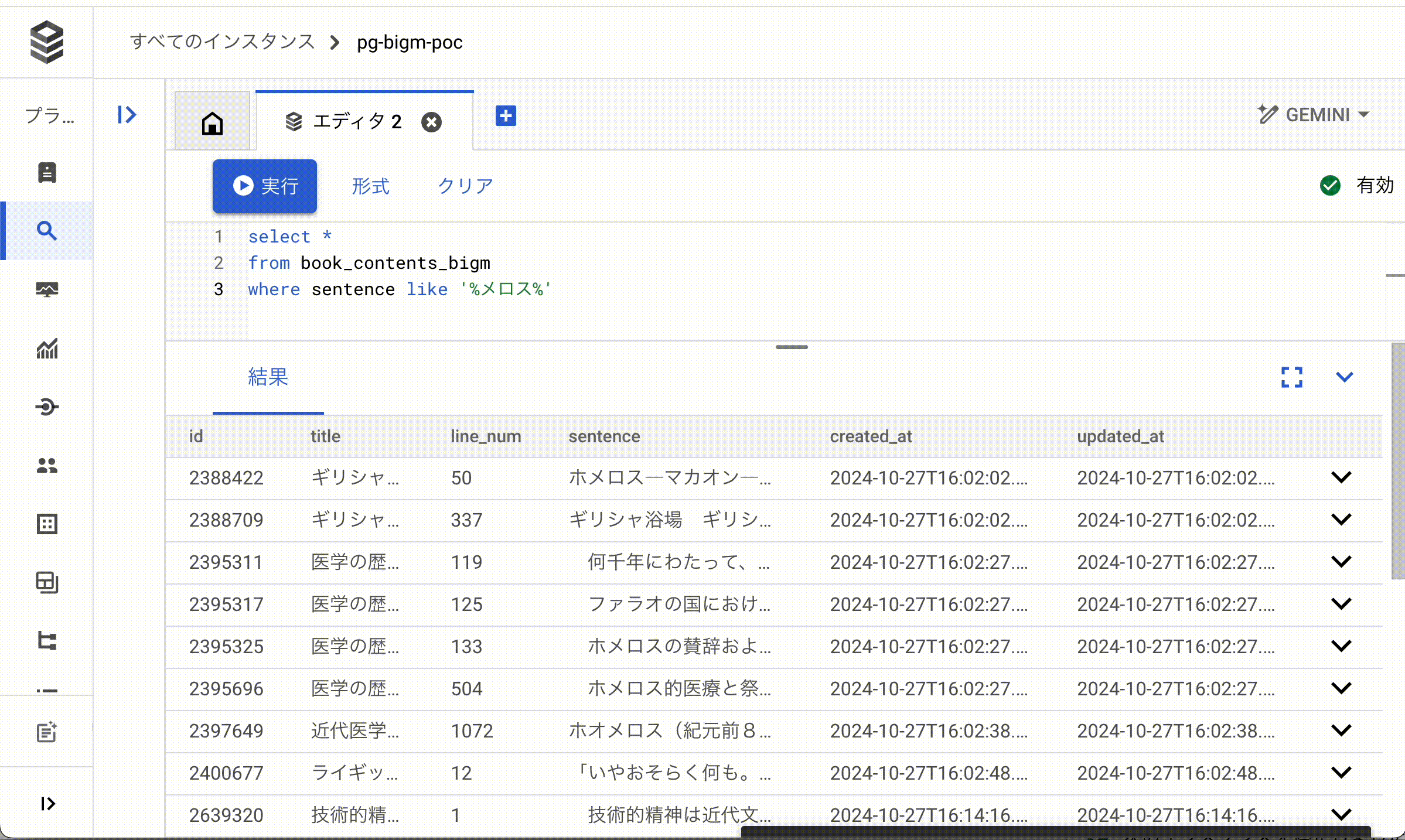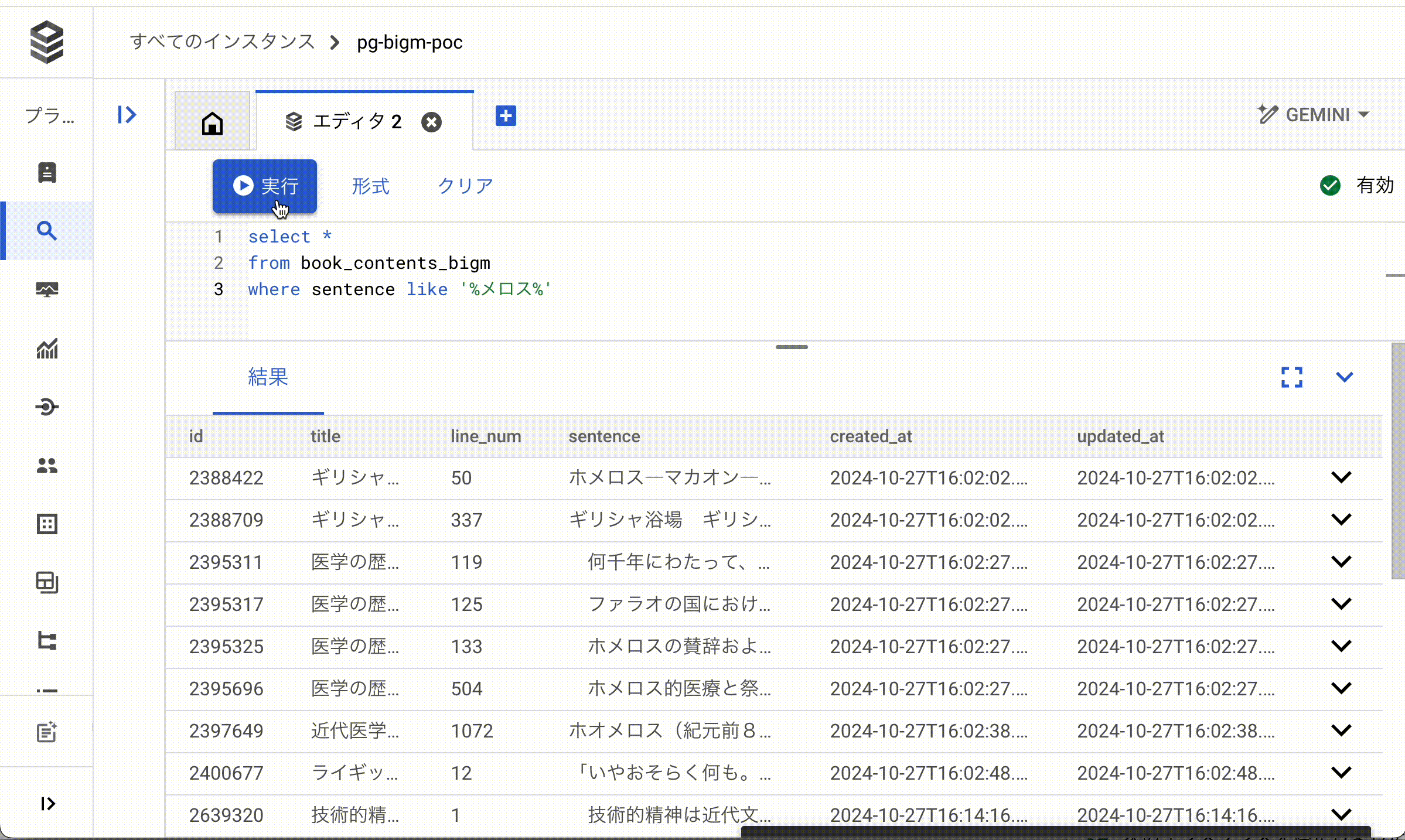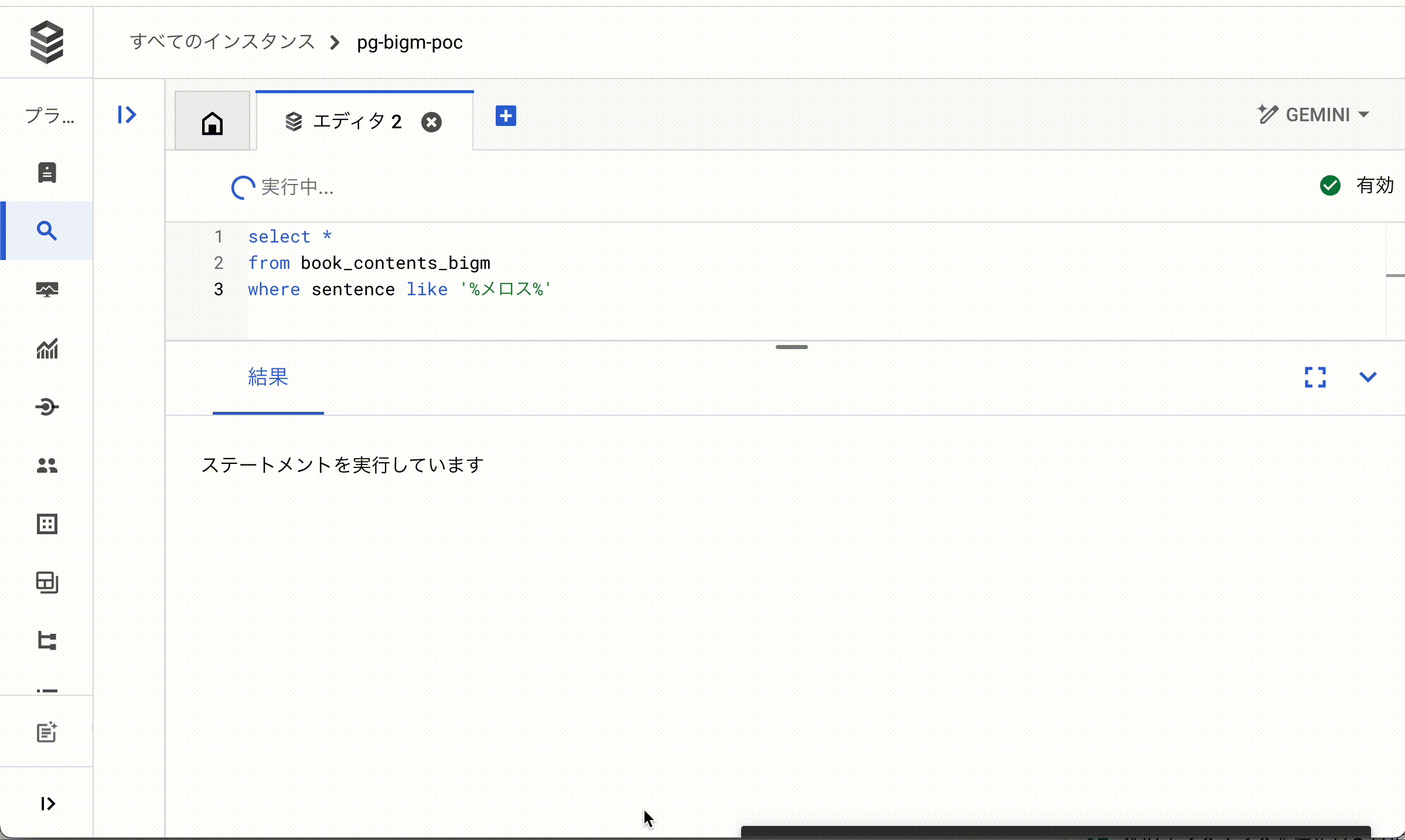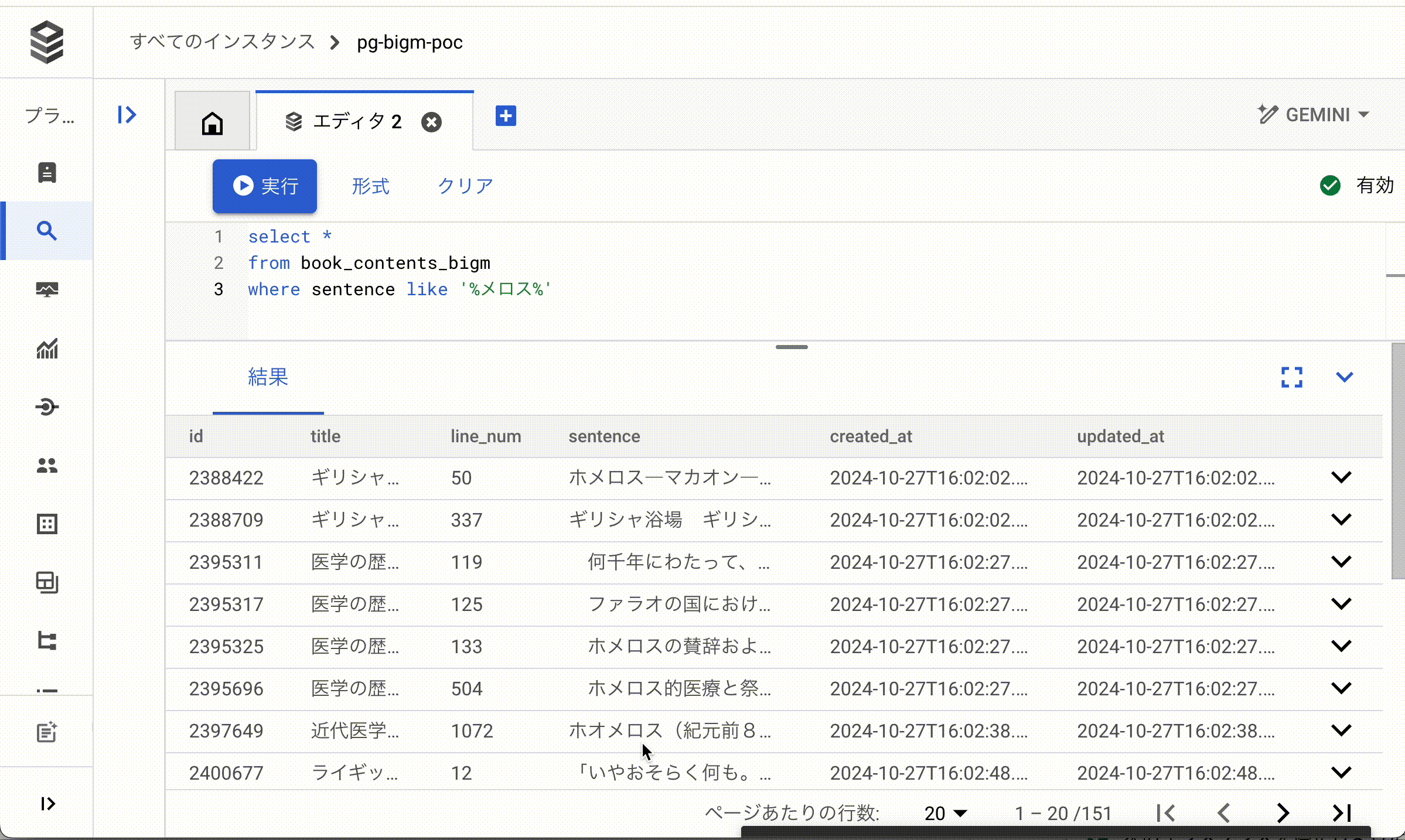
SELECT結果(パフォーマンス)の違い
もちろんデータベースですので、キャッシュのデータ状態などによって速度が変わることはありますが、pg_bigmを利用しているテーブルはそうでないテーブルに対して無視できない程度に高速化されていることが分かります。
比較的小規模なデータセットでこれだけの違いが出ているので、より大規模な実サービスのデータベースではよりおおきな差がでることを想定できます。
実行計画の比較
上記のSELECTの速度の確認で利用したクエリの実行計画を観察します。
pg_bigmを利用しないパターン
explain analyze
select *
from book_contents
where sentence like '%メロス%'
Gather (cost=1000.00..111920.66 rows=305 width=216) (actual time=21.243..3140.102 rows=151 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on book_contents (cost=0.00..110890.16 rows=127 width=216) (actual time=15.952..3128.825 rows=50 loops=3)
Filter: (sentence ~~ '%メロス%'::text)
Rows Removed by Filter: 1025368
Planning Time: 0.578 ms
Execution Time: 3140.242 ms
pg_bigmを利用するパターン
explain analyze
select *
from book_contents_bigm
where sentence like '%メロス%'
Bitmap Heap Scan on book_contents_bigm (cost=46.36..1214.52 rows=304 width=218) (actual time=0.176..0.664 rows=151 loops=1)
Recheck Cond: (sentence ~~ '%メロス%'::text)
Rows Removed by Index Recheck: 2
Heap Blocks: exact=106
-> Bitmap Index Scan on book_contens_bigm_index (cost=0.00..46.28 rows=304 width=0) (actual time=0.156..0.156 rows=153 loops=1)
Index Cond: (sentence ~~ '%メロス%'::text)
Planning Time: 1.209 ms
Execution Time: 0.995 ms
実行計画の違い
実行計画からも分かるようにpg_bigmを利用していないテーブルでは全文検索をするのにもちろんINDEXが利用されていないため、全文検索の対象カラムはsequential scanが使われています。
一方でpg_bigmを利用しているテーブルでは全文検索対象カラムがbitmap Index Scanを利用されていることが分かります。
まとめ
複雑な全文検索による集計処理など行うにはElasticsearchのような全文検索に特化したデータベースを利用したほうがパフォーマンスやリソース効率に優れることが多いですが、既存のアプリケーションに軽めの用途で全文検索を導入したい場合pg_bigmは非常に優れた選択肢と言えます。
一方でpg_bigmの課題としてはILIKE検索[^大文字と小文字を区別した部分一致検索]ができないというものがあります。
検索対象がアルファベットのみである場合、pg_trgmを利用することでその問題も解決できます。
Discussion