OLAPデータベースを支える技術
今年に入ってからCarnegie Mellon UniversityのAdvanced Database SystemsでReading Assignmentとして出ている論文リストで必須とされているものや講義資料を読みました。
この記事では紹介されていた論文やAdvanced Database Systemsの講義資料・動画を振り替えることで、BigQueryやRedShift、Snowflakeといった最新の分析用データベースがどのように優れたパフォーマンスを実現しているかを考えます。
最初は全ての講義資料を網羅的に纏めた資料を作成しようと思いましたが、誰向けの記事か別らなくなってしまったためクエリ実行以降については省略します。
需要がありそうならそのうち書きます。
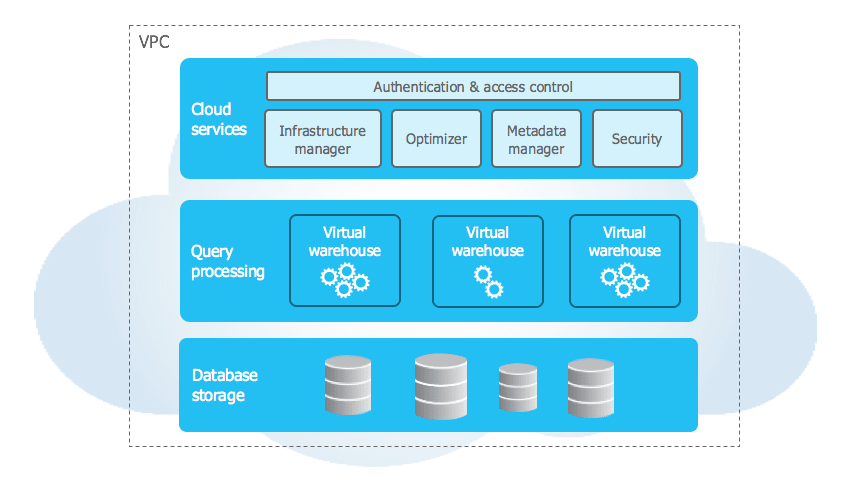
アーキテクチャ
最新のDWHソリューションでは計算リソースと永続化データを分離することで、それぞれのコンポーネントを別々にスケールアウトすることが可能にしています。
計算リソースが独立しているため、任意のタイミングで不要な計算リソースをシャットダウンすることができます。
データの永続化にはGoogle Cloud StorageやAmazon S3などObject Storageを使用します。
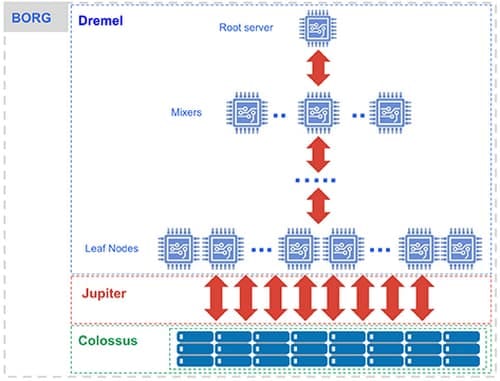
このShared DiskアーキテクチャはGoogleのMapReduceやHadoop時代の分散処理から受け継がれています。
ストレージモデル
モダンな分析データベースでは従来のDBMSで使われてきた列指向ストレージではにストレージモデルが採用されています。
列指向ストレージモデル(N-Ary Storage Model)ではヘッダーデータとそのレコード全体を一つのページ(ページ)に格納する一方で、行指向ストレージモデル(Decomposition Storage Model)ではヘッダーデータと単一行のデータのみをページに格納します。
このストレージモデルの何がうれしいかというと
- 分析クエリで頻出する
SELECT SUM(column1) from table1;のような単一行に対する集計処理を必要最低限のデータ読み込みで済み - データのローカリティが上がり
- データの圧縮効率が上るといったメリットがあります。
もちろんデメリットもあり、DMLのデータを複数の異なるページに書き込む必要があるため列指向ストレージほどのパフォーマンスを期待できません。
またこの二つのストレージモデルの合せ技としてPAX(Partition Attributes Across)というストレージモデルがあります。
このストレージモデルはRow Group(Partition)として垂直に分割されたレコードデータを行ごとにまとめて書き込むという手法をとっています。
PAXでは行指向と列指向それぞれのメリットを享受することができます。
ほとんどの分析用データベースでは何らかの形でPAXが使用されています。
INDEX手法
分析ワークロードで使われるデータベースは検索がメインのタスクとなるため、テーブルからのデータフェッチを最適化することはパフォーマンスに関わる大きな要素です。
OLAPで使われる代表てきなINDEXには以下のような物があります。
-
Zone Maps
パーティションされたデータの統計量(MIN/MAX/AVGなど)をあらわしたデータで、メタデータとして管理されていることが多いです。データの配置と値に相関があるときほど効果を発揮します。
INDEXというよりはメタデータやフィルターに近いです。PostgreSQLではBRINに応用されています。 -
Bitmap Indexes
カテゴリカルなデータでそれぞれのデータ毎にbooleanデータのベクトルとして表現する方法です。
全てのオフセットが固定長になるためnオフセット目がn番目のデータとなりデータ効率に優れます。
機械学習を噛った人にはone-hotエンコーディングのようなことをしていると説明すると分かりやすいかもしれません。
PostgreSQLではBitmap Indexとして実装されています。 -
Column Sketches
不可逆圧縮を用いたINDEXでデータをレンジごとにbit化します。
例えば0-60を00、60-132を01、132-170を10、170-256を11というbit化処理を行なったデータに対してWHERE column1 >= 140という検索をしたとすると140という値が10にマッピングされ11に所属するデータは個別に比較することなく返すことができ、
実際の値を参照する必要があるデータは10に所属するデータのみに抑えることができます。
すばらしい技術なのは分かるものの、実装しているデータベースは(私の知る限り)ありませんでした。
前進となるColumn Imprintという技術はMonetDBで採用されています。
データ圧縮
データアクセスの高速化において物理的なデータサイズを小さくすることは非常に重要です。
なぜなら大量のデータを処理するに当たり、ボトルネックとなるのは計算リソースやディスクI/Oだからです。
DBMSにおけるデータ圧縮は以下の三つを達成する必要があります。
- 固定長データを生成する
各データが固定長になることで、n番目のデータへのアクセスが効率化できます。 - データが完全に復元できる(lossless)
データを完全に復元出来ないならデータベースじゃないですよね? - 出来る限りデータの展開を後回しにできる
圧縮されたデータを直接取り回せる時間が長いほど、メモリ効率が上ります。
クエリ実行
クエリ実行におけるクエリプランは複数処理からなるDAGと見做すことができます。
たとえば以下のようなクエリはそれぞれのテーブルからのScan処理と結合処理に分解できます。
SELECT A.id, B.value
FROM A JOIN B
ON A.id = B.id
WHERE A.value < 99
AND B.value > 100;
この処理を実行するときDBMSは出来る限りタスクを並列で処理します。
クエリ実行をさらに紐解くとタスクを実行を制御するクエリスケジューリングや、マルチコアに対応するためのデータ処理手法、大量データに対するJOINやそれらのオプティマイズなどを含みます。
まとめ
我々が当然のように使用しているBigQueryやRedShiftを始めとしたDWHソリューションは魔法ではなく、今回紹介した手法やそれ以上の手法を用いて大量データを高速に処理するシステムを構築しています。
結局この記事は何を書きたかったのでしょうか?
Discussion