Copilotでらくらくコードリーディング
GitHub Copilot便利ですね。
2021年にTechnical Previewとして発表された時から便利だ便利だと言われていたGitHub Copilotに、2023年の4月末ごろからデビューしました。
デビューしたは良いものの最近は仕事ではコーディングよりアーキテクト的な方面でのお仕事が多かったり、個人の時間でもコーディングするよりOSSのコードを読むことのほうが多くコーディングのアシスタントツールとしては使いこなせていません。
そのため最近はPostgreSQLのコードを読むときのアシスタントとして利用することが多いです。
なのでこの記事ではCopilotでコードリーディングをするとここが素晴らしいという話をしたいと思います。
そもそもなぜコードリーディングにCopilotを導入するのか?
現代のシステム開発において完全にゼロから開発を行なうことは殆どありません。
既に稼動しているアプリケーションへの機能追加だったり開発がある程度進んだシステムの開発への途中参加といったケースはもちろん、なんらかのフレームワークやアプリケーションから通信を行うソフトフェアなどエンジニアが把握するべきコードベースは膨大です。
ドキュメントが整備されていればわざわざコードを読まなくても概形は理解できるかもしれませんが、実装がドキュメントといったプロジェクトも少なくありません。
また詳細な挙動を理解しようとするのであれば、ソースコードの読み込みは避けられません。
とはいえ本質的にコードリーディング自体は価値を産みません。ソースコードを読んで理解した内容が価値を産みます。
なのでコードリーディングは出来る限り短く正確に行なえるべきです。
そこで活躍するのがGitHub Copilotです。
コーディング支援の面が強調されがちなCopilotですが、慣れない言語のコードリーディングや大規模アプリケーションのコードリーディングなど一般的に効率が悪いであろう作業でも大きな価値を発揮してくれます。
前提
- Emacsしか使えない人類なのでzerolfx/copilot.el経由でCopilotを使用しています。公式にはEmacsはサポートされておらず、内部的にはgithub/copilot.vimを利用しているそうです。
- Copilot自体の導入方法は説明しません。VSCodeはわからないので出来ません。
- 説明に用いるコードはPostgreSQLのコードを利用します。PostgreSQLは多量のドキュメントが存在するため、どこまで一般的なコードベースに適用可能かは議論の余地があります。
- ぶっちゃけやってることは殆どこれだけです。
Usecase
コードを自然言語に変換してもらう
使いなれないプログラミング言語で書かれたコードを読むのは時間がかかります。
そういったコードを読むまえに、処理内容を自然言語に変換して理解することでコードを読むトータルの時間を抑えることが出来ます。
もちろんコードそのままの方が理解しやすいこともありますが、様々なアプローチが行なえることは素晴らしいことです。
Copilotではコードを自然言語(または任意のプログラミング言語[1])に書き変えるようなタスクを行なうことも出来ます。
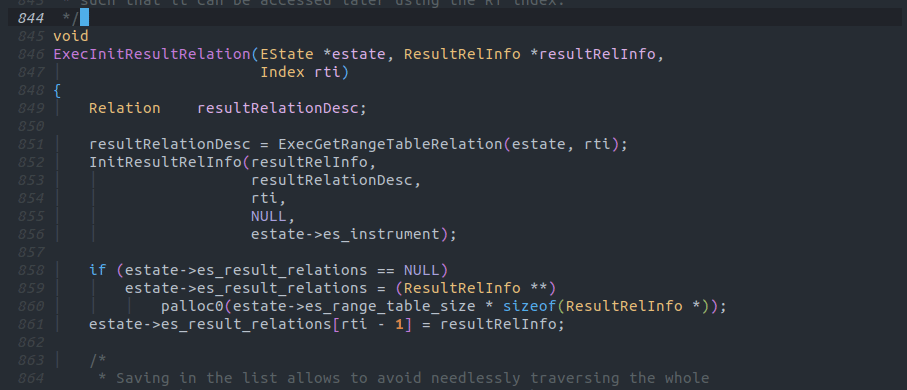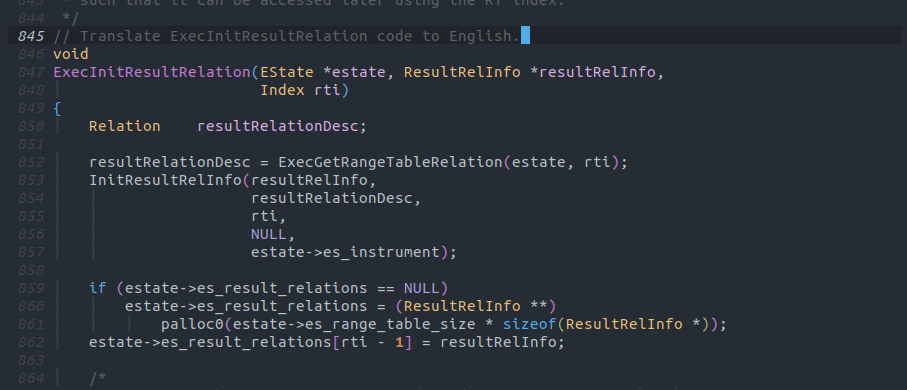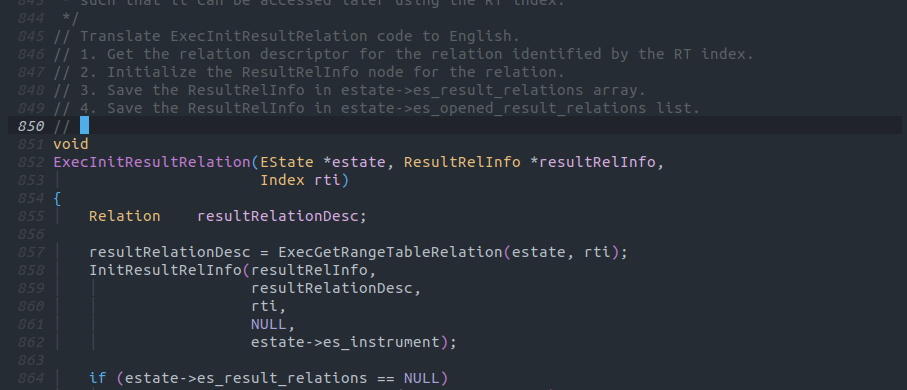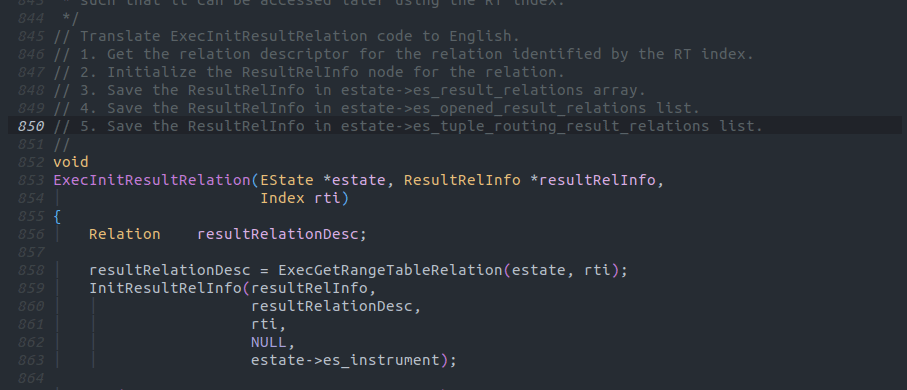
注意点としてChatGPTを始めとしたLLMは結構な確立で嘘を混ぜてくることがあります。
この画像の例では5として出力された5. Save the ResultRelInfo in estate->es_tuple_routing_result_relations listは存在しない処理です。
そのためコードを読むまえにざっくりとした概要を把握して、理解の速度を底上げするといった補助的な利用方法をオススメします。
コードを要約してもらう
関数のネストが深いときに全ての関数を事細かに読んでいては、時間がいくらあっても足りません。
もちろん全ての関連する関数を全て読んだほうが、その処理に対する理解は深まりますがそうは言っていられないことが多いです。
ChatGPTが文章の要約で素晴らしいパフォーマンスを発揮するように、Copilotも関数の要約に利用することが出来ます。
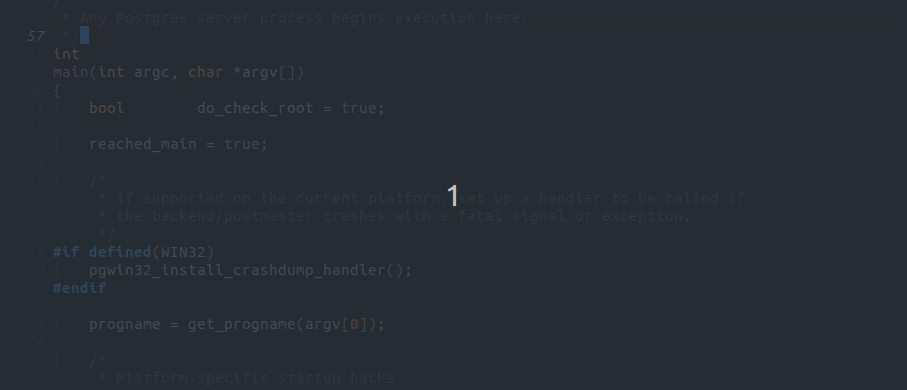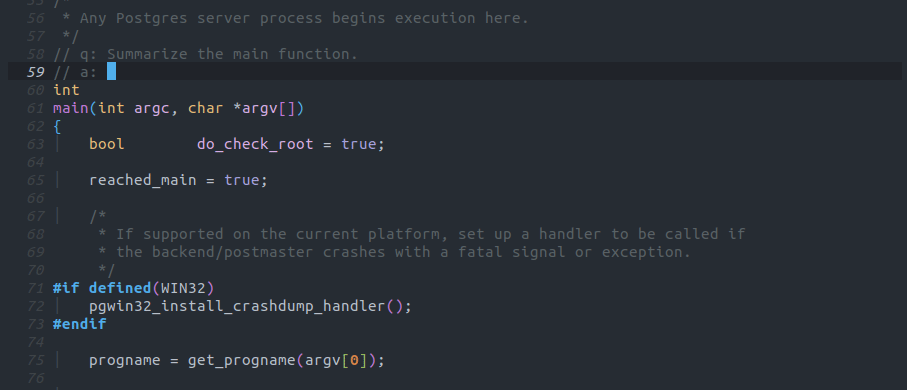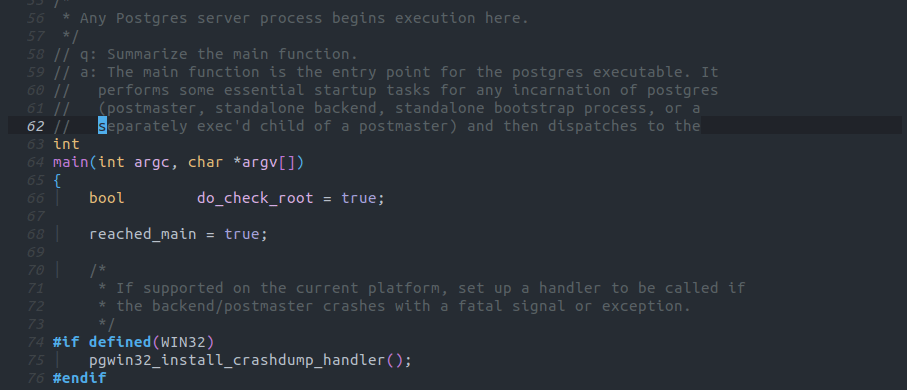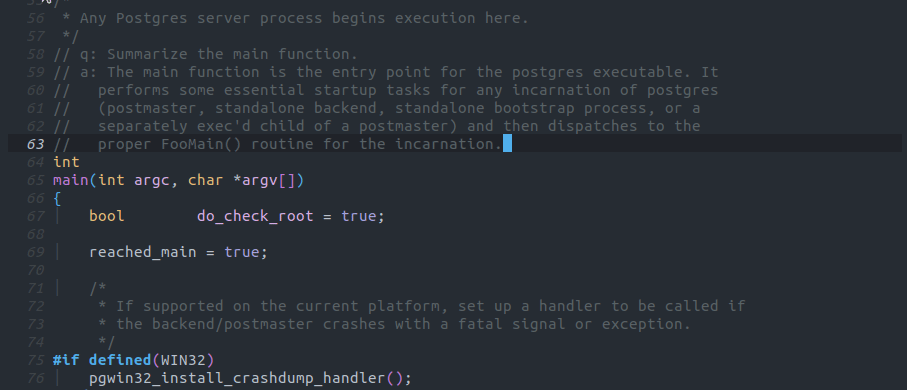
この例ではPostgreSQLのメイン関数の処理を要約していますが、必要なstartupプロセスを行い、PostgreSQLの動作に必要なプロセスを起動すると概ね正常な要約をしています。
コード内の他言語で書かれたコメントを翻訳もらう
現実世界でもOSSの世界でも国外のコミュニティに飛び込む場合の第一言語は英語が基本です。(最近はの中国語のOSSなども増えてきた気もします)
そのためコードの中に書かれたコメントも日本語以外であることが多いです。
もちろん原文は原文のまま読むに限りますが、単純にその言語に精通していなかったり日本語以外を読む気にならなかったりすることは少なくなりません。
コード内に外国語のコメントが出るたびにコピペしてGoogle翻訳やDeepLを使うのも良いですが、外部サービスにアクセスするのは単純に手間で効率を低下させます。
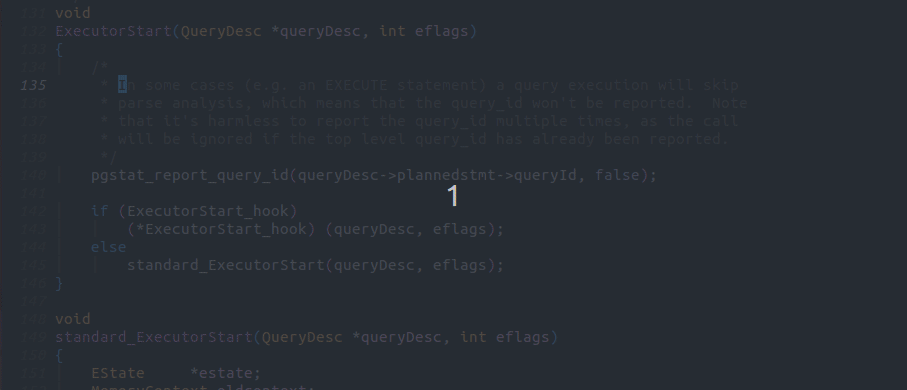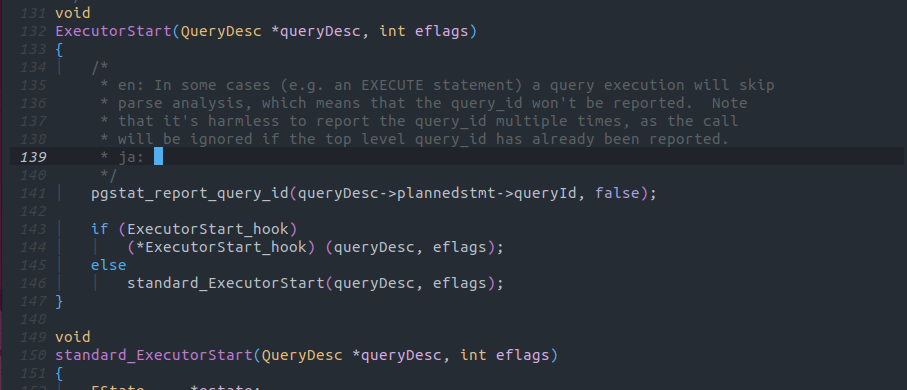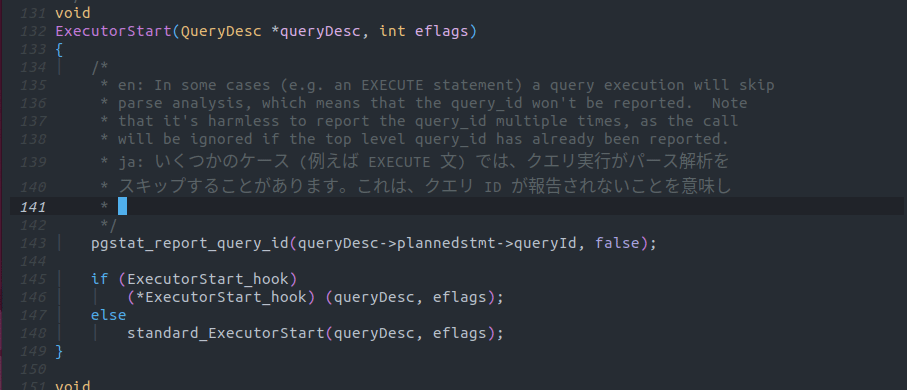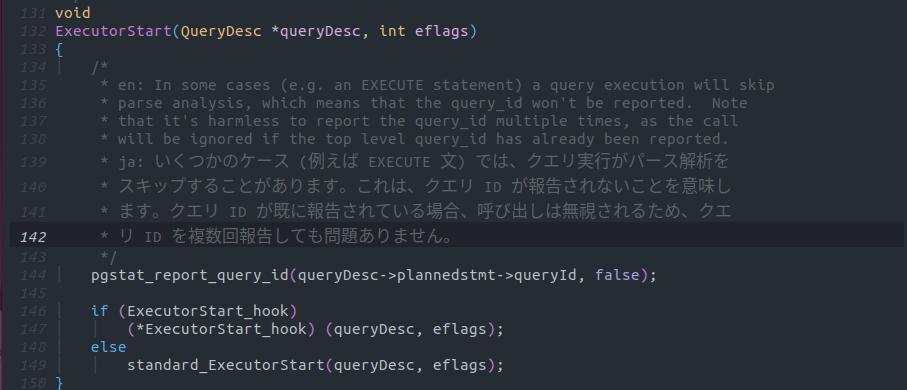
Copilotでは以下の画像のように英語コメントの先頭にen(中国語であればzhなどその言語の言語コードを)、コメントの終りにjaと入力することで英語で書かれたコメントを日本語に翻訳させることが出来ます。
CopilotはOpenAIが開発したCodexというGPT-3に大量の自然言語とコードで再学習させた機械学習モデルを利用しています。[2]
Microsoftの論文によればChatGPTでお馴染のGPT-3(text-davinci-003)は翻訳のタスクでも優れたパフォーマンスを発揮することを示しています。
そのためCopilotを利用した言語翻訳は実用に耐える精度があると判断して良いでしょう。
ただし全ての翻訳ツールに言えることですが過信は禁物です。
存在は知っているけど宣言されている場所が分からないコードの場所を知らべる
大規模OSSなどでは概念は知っているものの、コードレベルではなんという名称なのか分からない機能などがあると思います。
PostgreSQLであればPageの概念は一般的ですが、コードとしてPageを扱うのはエントリーポイントから大部深くまでコードを追わなければ見つけることが出来ません。
そのためコードベースでは全くPostgreSQLを知らない状態からPageを表わす構造体を見つけるには少なくない時間が必要となります。
Copilotではこういった実質的な構造体の検索も実行できます。
以下の画像のようにq: Page構造体が宣言されている場所は? という形式でコメントを書くことで任意のコードを宣言しているファイルを見つけることが出来ます。
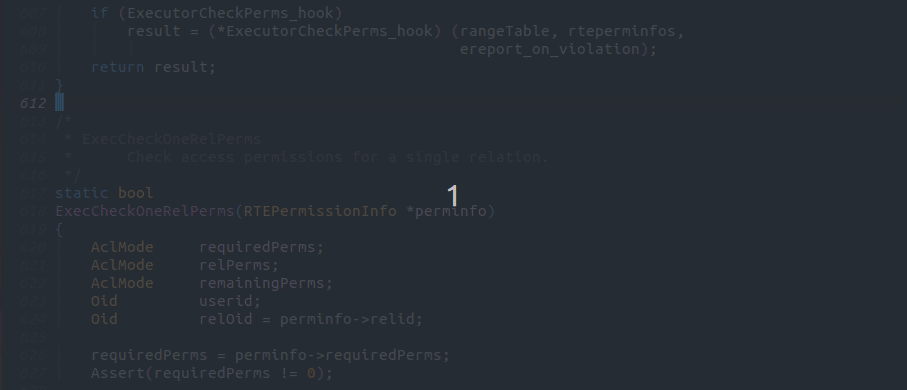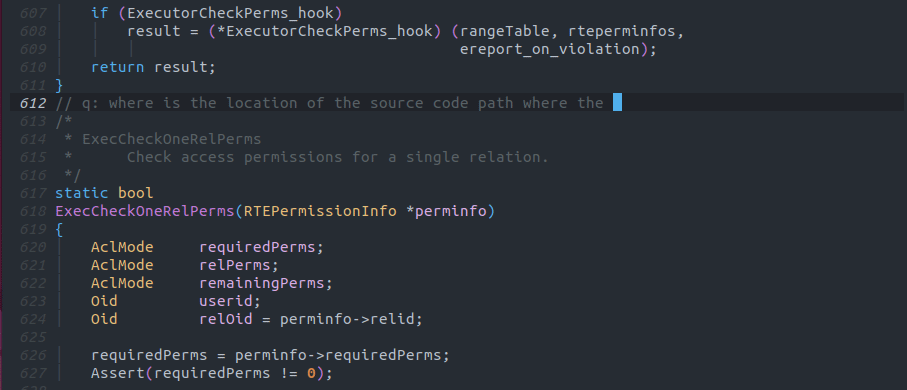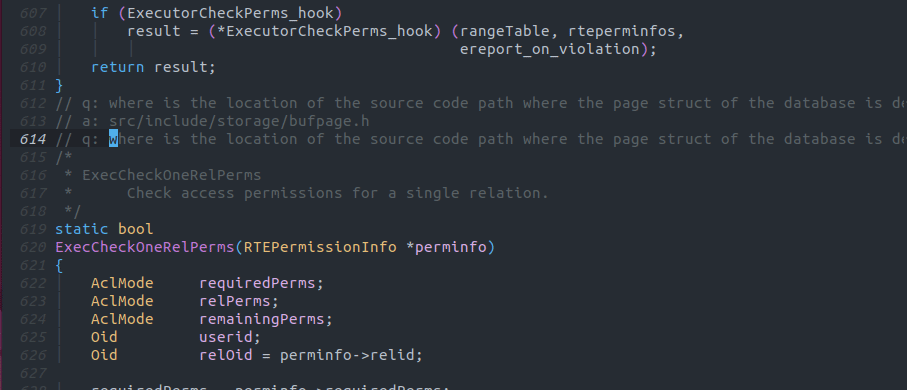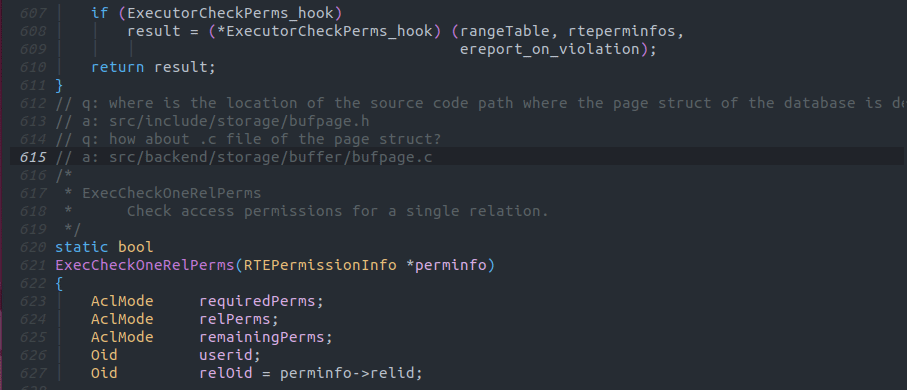
日本語でコメントを書いても動くかも知れませんが、生成AIは一般的に英語を入力としたほうが優れたパフォーマンスを発揮することで知られているため、英語で実行することを推奨します。[3]
Copilot時代のコーディングに寄せて
GitHub Copilotはエディタで開かれているファイルをプロンプトとして、言語モデルに転送し我々の命令に応答しています。
そのため質の高いコードを生成するにも、質の高いコードの説明を生成するにもコメントが今まで以上に重要になります。
単純に優れたコメントが記載されているだけで、コードリーディングの手間は大きく短縮されます。それに加えてこの記事で紹介したようなCopilotを駆使したテクニックを用いることで開発者がコードを理解する速度は今までの何倍にもすることが出来るでしょう。
コードをすばやく理解できればあなたのコードに貢献する開発者のファーストステップが早くなり、またOSSプロジェクトであればより多くのエンジニアに利用してもらえるかも知れません。
私が楽するためにも是非ともコードにコメントを書いてください。
-
正式な機能として提供されている訳ではないので出力されるかは博打です。GitHub Copilot Labsでは提供されているらしいです。 ↩︎
-
要出展 ↩︎
Discussion