LLMに人間の価値判断を真似させる試み
この記事は某サークルOB/OGのアドベントカレンダーであるN代アドベントカレンダーの12日目として作成されました。(遅刻すみません.....)
どうしてこのようなことを考えるか?
近年、自然言語処理モデルとしてのLLM(Large Language Model)が非常に進化してきていますが、それらを単純にタスクを定義して渡す方式で運用する際には、ほぼ全ての意思決定を人間が行わなくてはならないという課題を抱えています。これに対して、LLMがユーザーの価値観を学習してくれることで、より高度な判断をLLMに委ねることが可能ではないかと考えられています。これにより、ユーザーが抱えるタスクの一部をLLMに効率的に委任し、業務の自動化や効率化に寄与する可能性があります。
このアイデアの実現に向けた先行研究としては、インタビューを通じて人間の行動を再現する手法が存在します。具体例としては、2時間にわたるインタビューによって個人の人格をモデル化する試みが報告されています。しかし、この方法では時間や労力といったリソースが多く必要となります。そのため、より少ないリソースで同等の結果を得ることが可能かどうかを探ることが目的となります。最終的に、これを数値的または量的に評価する試みが行われ、その結果、完全な成功には至らなかったものの、定量化への一歩となったのではないかと考えています。
どのように定量化するか?
この取り組みでは、まずなるべく独立していると思われる二択問題を100問作成しました。そして、少数の答えをLLM(Gemini 1.5 flash, pro)に教えたあと、残りの問題を正確に当てられるかどうかを検証しました。加えて、LLMには自信度を3段階で答えさせ、回答の分散を観察することで、学習の度合いやモデルの信頼性を測定しました。具体的には、12問、25問、50問と異なる量の問題を用いて結果を評価しました。
さらに、複数のモデルを用いてその性能の違いについても検討を行いました。この研究の再現性を担保するため、使用されたコードと実験の結果はGitHubリポジトリに公開されています (https://github.com/nkowne63/mimic_binary_choice)。このアプローチにより、モデルが価値観や判断をどの程度正確に再現できるかのベースラインを得ることを目指しました。
結果と考察
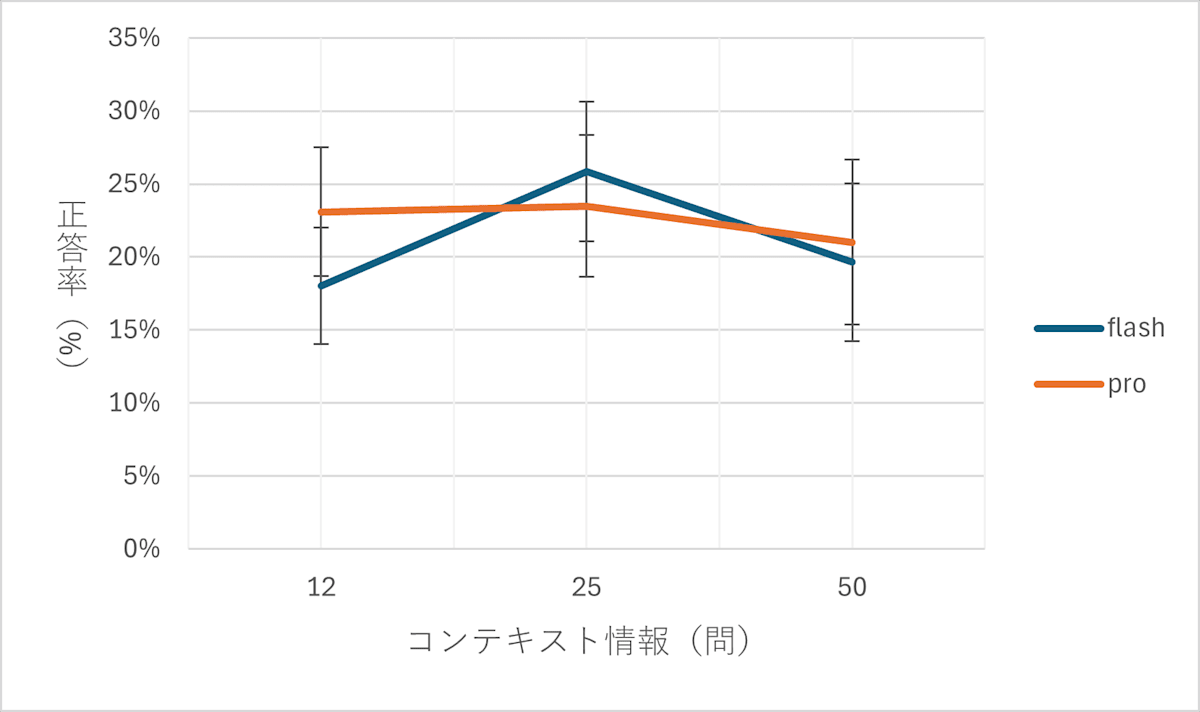
実験の結果は期待には及びませんでした。得られた結果では、モデルは乱数選択と比較しても劣る判断を下すことが多く、さらにLLMは自信を持って誤った回答をするケースが多く見られました。問題を増やしても結果には大きな変化が見られず、モデルの性能には限界があることが示唆されました。
また、モデル間の差も観測することができませんでした。これは、現時点のLLMでは、(仕組みを考えると当たり前なのですが)「コンテキストに明示的に記述されていない情報」に関して、特定の個人と同じように判断する能力が十分ではないことを示しています。特に、二択問題によるアプローチはコンテキストが制限され過ぎており、判断が難しい状況を生んだと考えられます。
今後、人格のコピーとしてLLMを利用するには、「今までのコンテキストで判断が可能かどうか」をより明確に判定する機構が求められるかもしれません。
今後何ができるか?
今後の展望として、二択形式の問題だけではなく、性格やバックグラウンドについてさらに具体的な情報をモデルに与え、いかにそれを定量化するかについての研究が必要になるかもしれません。また、LLMが現時点での状況と既存のコンテキストの関連を正確に判断できるかどうかを確認するプロセスも求められるでしょう。これにより、より個人化されたモデルを構築し、その実用性を高めるための新たな手法を開発する方向に進んでいける可能性があります。
Discussion