この記事では,第 1 回 C0de ハッカソン with Pixiv に参加した話をします.自分のチームは 2 人チームで,フォントの不足している文字の補完を行うアプリケーションの開発に取り組みました.しかし学習が上手くいかなかったため,途中でつくるものを 2 つのフォントをランダムに混ぜこぜにするアプリケーションに変更して完成させました.
1. 開発したアプリケーションの概要
フォントには対応している文字の範囲に違いがあります:
- アルファベット・数字・記号のみ
- ひらがな・カタカタまで
- 教育用漢字まで
その結果,以下のような事態が発生することがあります:
- 地名や氏名に使われる漢字が表示されない
- 例:「髙(はしごだか)」「﨑(たつさき)」など
- 装飾性の高いフォントは対応している漢字が少ない
- 年賀状を作成する際に「謹」の字が表示されない
したがって,こうした対応している文字の範囲が狭いフォントについて,不足している文字を補完しその範囲を拡張したいという需要があると考えました.
そこで,フォントの文字のパスデータを時系列データとみなして,2 つのフォントの文字のパスデータの対応関係を Echo State Network (ESN) で学習させ,学習した ESN によってフォントの不足している文字のパスデータを補完するアプリケーションを開発しようということを考えました...開発したかったです.
2. 機械学習
2.1. フォントのパスデータの仕組み
フォントのパスデータがどのように記述されているかご存じでしょうか.フォントはどこまで拡大してもぼやけないことからわかるように,ベクター形式で記述されています.実際に Python のライブラリである fontTools でフォントのパスデータを取得してみると,以下のようなデータが得られます.これは「あ」という文字のパスデータです.
[('moveTo', ((472, 792),)),
('lineTo', ((388, 794),)),
('curveTo', ((389, 782), (387, 764), (386, 746))),
('curveTo', ((384, 724), (381, 698), (378, 669))),
('curveTo', ((355, 668), (333, 668), (310, 668))),
('curveTo', ((267, 668), (180, 675), (145, 681))),
('lineTo', ((147, 606),)),
('curveTo', ((188, 603), (266, 599), (309, 599))),
('curveTo', ((329, 599), (349, 599), (370, 600))),
('curveTo', ((366, 553), (361, 503), (359, 453))),
('curveTo', ((221, 389), (109, 258), (109, 129))),
('curveTo', ((109, 44), (161, 3), (227, 3))),
('curveTo', ((282, 3), (342, 25), (397, 58))),
('curveTo', ((402, 38), (407, 19), (413, 2))),
('lineTo', ((485, 24),)),
('curveTo', ((477, 49), (469, 76), (461, 105))),
('curveTo', ((546, 177), (627, 288), (684, 430))),
('curveTo', ((777, 403), (828, 335), (828, 259))),
('curveTo', ((828, 129), (716, 36), (535, 17))),
('lineTo', ((578, -50),)),
('curveTo', ((810, -13), (905, 111), (905, 255))),
('curveTo', ((905, 365), (831, 457), (706, 490))),
('curveTo', ((706, 492), (707, 493), (707, 494))),
('curveTo', ((712, 510), (721, 537), (727, 551))),
('lineTo', ((648, 571),)),
('curveTo', ((647, 554), (642, 528), (637, 513))),
('curveTo', ((636, 509), (635, 506), (634, 503))),
('curveTo', ((622, 504), (610, 504), (597, 504))),
('curveTo', ((546, 504), (485, 495), (429, 479))),
('curveTo', ((432, 521), (435, 563), (440, 602))),
('curveTo', ((562, 608), (695, 622), (800, 640))),
('lineTo', ((799, 714),)),
('curveTo', ((697, 690), (575, 677), (448, 671))),
('curveTo', ((452, 700), (456, 726), (460, 747))),
('curveTo', ((463, 761), (467, 779), (472, 792))),
('closePath', ()),
('moveTo', ((426, 368),)),
('curveTo', ((426, 382), (426, 395), (427, 409))),
('curveTo', ((473, 426), (531, 441), (596, 441))),
('curveTo', ((602, 441), (608, 441), (613, 441))),
('curveTo', ((571, 329), (510, 248), (443, 185))),
('curveTo', ((433, 243), (426, 304), (426, 368))),
('closePath', ()),
('moveTo', ((185, 142),)),
('curveTo', ((185, 224), (259, 323), (356, 378))),
('curveTo', ((356, 372), (356, 366), (356, 360))),
('curveTo', ((356, 285), (366, 204), (380, 133))),
('curveTo', ((329, 97), (281, 80), (242, 80))),
('curveTo', ((204, 80), (185, 101), (185, 142))),
('closePath', ())]
見てわかるように,いくつかのコマンドとその引数の組み合わせからなる命令列で記述されています.各コマンドは次のような機能を持ちます:
-
moveTo(x, y): 目標点までカーソルを移動(描画しない)-
(x, y): 目標点の座標
-
-
lineTo(x, y): 現在点から目標点まで直線を描画-
(x, y): 目標点の座標
-
-
curveTo(x1, y1, x2, y2, x, y): 現在点から目標点までベジェ曲線を描画-
(x1, y1): ベジェ曲線の制御点の座標 -
(x2, y2): ベジェ曲線の制御点の座標 -
(x, y): 目標点の座標
-
-
closePath(x, y): パスを閉じる
このことからもわかるように,パスデータはまさしく筆跡のごとく記述されています.筆跡ということは,つまり時系列データとみなせるということなのです.
2.2. なぜビットマップ形式にしないのか
そうはいっても,フォントの機械学習の主流は(おそらく)文字データをビットマップ画像にして CNN で学習することです.それなのになぜビットマップ形式にしないのか,それはビットマップ形式のフォントは実用的ではないからです.ビットマップ画像は拡大するとぼやけてしまいます.つまり,実用的なフォントを作るには,そこからまたベクター形式に戻す必要があります.だったら,最初からベクター形式で学習できたほうがいいのではないか.そういうわけで,ベクター形式で学習することに重点を置きました.
2.3. ESN とは
ESN とは,RNN の特殊な例で,リザバーコンピューティングというパラダイムに属します.リザバーとは「貯水池」のような意味合いです.ネットワークは以下の層から構成されます:
- 入力層
- リザバー
- リードアウト(出力層)
リザバーでは,ノード同士をランダムに結合します.また,学習にあたってリザバーの重みの更新は行わず,リードアウトのみを学習させます.このため,通常の RNN と比較して計算コストが小さく,それでいて比較的良好な性能を示します.最近の流行りらしいですね.
3. 技術構成
3.1. 全体像
ESN の特徴である 計算コストが小さい ことを活かし,ローカルで機械学習を実行する形式を採ることにしました.また,チームメンバーが Electron を触ってみたいと言っていたため,以下のような構成としました:
- フロントエンド :
Electron (Node.js) - バックエンド :
Fast API (Python)
スタンドアローンで実行できるようにしたいため,バックエンドについても Python 環境がなくても実行できるようにするため,Nuitka を利用してビルドすることとしました.
以上のような構成は過去に VOICEVOX でも採用されていた(VOICEVOX は実行速度よりもビルドにかかる時間を重視して Nuitka から PyInstaller に移行してしまった)ので,恐らく問題ないという判断がありました.
フォント関連の処理には先ほども登場した fontTools というパッケージを利用しています.
また,ESN の学習には ResevoirPy というパッケージを利用しています.
3.2. ウイルスじゃないですってば
さて,少し話は変わりますが,世の中のマルウェアはどんな言語で書かれていると思いますか?C++ ですか? C ですか?たしかに昔はそうでした.しかし,最近の流行は Python です.たぶんライブラリとかが充実していて,マルウェアを作るのが楽なんでしょうね.
Python でマルウェアを作ると一つ問題があります.それは,Python はインタプリタ言語であるということです.この問題を解決するために,マルウェア開発者は Python のコードを実行ファイル形式に変換するツールをよく利用します.それが PyInstaller や Nuitka です.たとえば,Nuitka は Python のコードを C/C++ に変換したうえでコンパイルするという仕組みになっています.
さて,今回わたしたちはバックエンドがスタンドアローンで動作するようにしたいと考え,Nuitka を利用することにしました.しかし,ああなんということでしょう.Nuitka でビルドすると,Windows Defender がマルウェアと誤認識してしまうのです.コンパイラを MSVC に変更するとよいという情報を得て試してみましたがうまくいきませんでした.とりあえず,Windows Defender で除外設定を行うことで回避しました.あーあ.
3.3. 仮想環境の闇
開発環境を統一するために Dev Container を利用しました.当然 OS は Linux です.しかし,最終成果物は Windows で動作するようにしたかったです.幸い,Electron はクロスプラットフォームビルドに対応しています.とはいっても素の Linux でビルドできるわけではありません.Wine が必要になります.
ああ,なにか嫌な気配がしてきましたね.そうです,Windows をホスト OS として,Dev Container で Linux のコンテナを立ち上げて,その中で Wine を使って Electron をビルドするということを行いました.バカですね.
とは言ったものの,Electron 公式で Wine まで入っている Docker イメージが提供されていたので,それを利用しました.手間で言えばそれほどでもないです.計算リソースが潤沢にある現代だからこそできる芸当ですね.良い時代です.
ちなみに,Nuitoka のビルドはクロスプラットフォームに対応していないので,バックエンドのビルドは Windows でビルドする必要がありました.なんのために Dev Container を使っているのか.
開発期間の半分くらいは環境構築に費やしていました.やっぱり環境構築って難しいですね.
4. 完成したもの
4.1. 方針転換
機械学習の結果は以下のようになりました:



ははは,これは酷い.C はまだ少し面影が残っていますが,それ以外は壊滅的です.
と,こういうわけで,途中で方針転換しました.
4.2. 完成したもの
完成したアプリケーションは以下のようになりました:
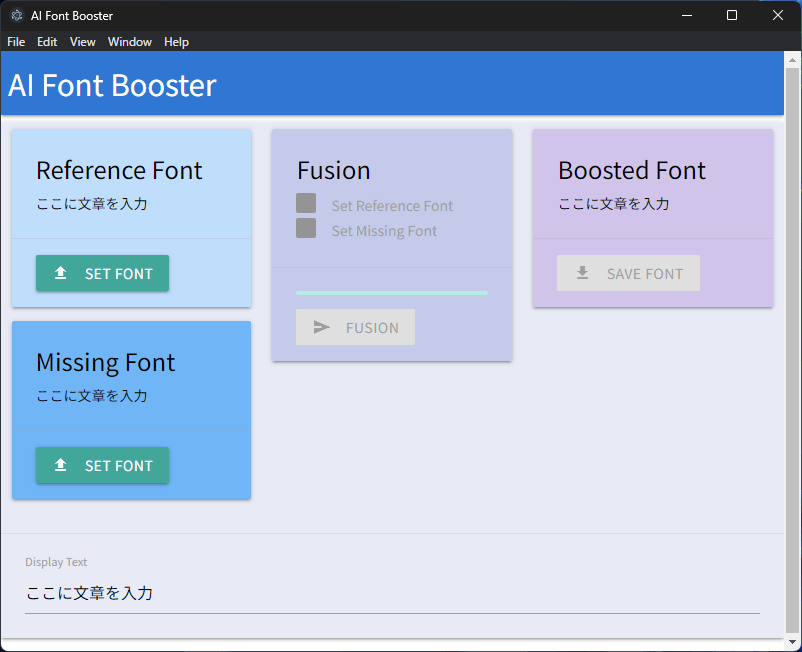
本当は不足している文字の補完を行う予定だったので,UI はそのままになっています.機能としては,2 つのフォントをランダムに混ぜこぜにするというものです.実行結果は以下のようになります:

これが一体何の役に立つのかというと,グラフィックデザインで新聞を切り貼りしたようなデザインを作るときとかですかね.えてして,文字ごとにフォントを変えるというのはとっても面倒な作業です.これをフォントのレイヤーで混ぜこぜにしたものを作るというアプローチで実現するのは,手間がかなり省けるので意外と有用かもしれません.フォントのライセンス的にはちょっと怪しいですけどね...
一応 GitHub で公開しています.リポジトリはこちらです:
5. おわりに
さて,当初作りたかったものは完成しなかったわけですが,新しいフレームワークを使ってみたり機械学習してみたり,とても有意義な時間を過ごすことができました.このような機会を与えてくださった Pixiv さんに深く感謝したいと思います.ありがとうございました.
また,実はわたくしプログラミング部 C0de 所属ではなく,コンピュータ倶楽部 NITMic という別の団体に所属しています.中の人同士は結構つながりがあったりして,同じ情報系の団体ということで仲良くしたいという機運もあり,大学祭では NITMic の部誌に C0de のみなさんから記事を寄稿していただいたということもありました.そのような縁もあって,C0de のみなさんから NITMic にお誘いをいただき,今回参加することができました.C0de のみなさんにも感謝したいと思います.ありがとうございました.
それから,チームメンバーの Mass さんにも感謝をば.感謝~.
6. 後日談
うまくいかなかった機械学習ですが,実装にミスがありました.修正後の結果は以下のようになりました:



きれいに予測できていますね 😢

Discussion