Goならわかるシステムプログラミング を読む
ファイルディクリプタのイメージついてなかったので助かる。
ファイルディスクリプタは、OSがカーネルのレイヤーで用意している抽象化の仕組みです。OSのカーネル内部のデータベースに、プロセスごとに実体が用意されます。OSは、プロセスが起動されるとまず3つの疑似ファイルを作成し、それぞれにファイルディスクリプタを割り当てます。0が標準入力、1が標準出力、2が標準エラー出力です。以降は、そのプロセスでファイルをオープンしたり、ソケットをオープンしたりするたびに、1ずつ大きな数値が割り当てられていきます。
こういうのもできるらしい 📝
io.MultiWriter は、複数の io.Writer を受け取り、書き込まれた内容をすべてに同時に書き込むフィルタです。
なるほど
他の言語だと、ブロックするAPIとブロックしない(ノンブロッキングの)APIの両方が用意されていることも多いのですが、Go言語の場合は並列処理機構が便利に使えるので、それを使ってノンブロッキングな処理を書きます。
エディアン変換
現在主流のCPU 2 はリトルエンディアンです。リトルエンディアンでは、10000という数値(16進表示で0x2710)があったときに、小さい桁からメモリに格納されます
しかし、ネットワーク上で転送されるデータの多くは、大きい桁からメモリに格納されるビッグエンディアン(ネットワークバイトオーダーとも呼ばれます)です
フォーマットは文字列は %s で、構造体のデバックとかは %#v とかが良さそう。
Go言語は型情報をデータが持っているため、すべて「%v」と書いておけば変数の型を読み取って変換してくれます。
Windows 向けバイナリは共有ライブラリを読み込んでいる。
Windowsも内部ではシステムコールを呼び出しているはず4ですが、Windowsは内部のコードを公開していないため、システムコールを直接呼び出せません。
そのためGo言語では、他のOSについては共有ライブラリの読み込みを言語機能としては提供していませんが、Windowsだけは標準ライブラリを使ってDLLをロードできるようになっています。
ソケット通信の例として、双方向の Unix ドメインソケットも確かにあるか
一方的な送信しかできないUDPのようなプロトコルもあれば、接続時にサーバがクライアントを認知(Accept())して双方向にやり取りができるようになるTCPやUnixドメインソケットなどのプロトコルもあります。
Transfer-Encoding: chunked の細かい仕様について
チャンク形式ではヘッダーに送信データのサイズを書きません。 代わりに、Transfer-Encoding: chunkedというヘッダーを付与します。ボディは、16進数のブロックのデータサイズの後ろに、そのバイト数分のデータブロックが続く、という形式です。 通信の完了は、サイズとして0を渡すことで伝えます。
多重化 (パイプライニング) は、リクエストの順序を保つのが難しそうだけど、channel を使って良い感じに実装されていた。
まずはサーバ実装を見ていきましょう。 サーバを実装するうえで注意すべきパイプライニングの仕様は次の2点です。
- サーバ側の状態を変更しない(安全な)メソッド(GETやHEAD)であれば、サーバ側で並列処理を行ってよい
- リクエストの順序でレスポンスを返さなければならない
HTTP に関する話の流れが良かった

UDP はデータロスの検知や通信速度の制御 (輻輳制御) をしない点が着目されるが、こういうメリットもある。
TCPとくらべて機能が少なくシンプルですが、そのかわりに複数のコンピュータに同時にメッセージを送ることが可能なマルチキャストとブロードキャストをサポートしています。 これはTCPにはない機能です。
ここら辺まで読んでいて、bufio ってなんだろう?ioとの違いがよくわからなくなってきたので調べる。
細かいデータをたくさん書き込むとき、毎回 syscall を呼ぶとオーバーヘッドがかかるので、内部でデータを一時的にプールしある程度の塊で書き込むみたいなことをしてくれる仕組みだと理解した。
次の引用部分はUDP のリアルな話な感じがする。小さいデータを扱う分にはメリットが多そうなので、アプリケーション側でそこらへんをちゃんと考慮してあげる必要がありそうという感じなのかな。
MTUに収まらないデータは、IPレベル(TCP/UDPの下のレイヤー)で複数のパケットに分割されます。 これをIPフラグメンテーションと呼びます。 IPフラグメンテーション自体はIPレイヤーで再結合はしてくれますが、分割された最後のパケットが来るまではUDPパケットとして未完成のままなので、アプリケーション側にはデータが流れてくることはありません。 データが消失したら受信待ちのタイムアウトも発生しますし、UDPを使うメリットが薄れてしまいます。
巨大なデータをUDPとして送信するデメリットはもう1つあります。 IPレイヤーでデータを結合してくれるといっても、IPレイヤーや、その上のUDPレイヤーで取り扱えるデータは約64キロバイトまでです。 それ以上のデータになると別のUDPパケットとして扱うしかありません。 TCPであれば大きなデータでも受信側アプリケーションでの扱いを気にすることなく送れます6。 UDPではデータの分割などはアプリケーションで面倒を見るしかありません。 逆に言えば、データの最小単位がこの64キロバイト以下であればアプリケーション内でのデータの取り扱いはシンプルになります。
TCP や UDP と比較してもやることが少ないので、同じホスト内での通信にはハマると効果的という感じなのかな
ファイルシステムの基礎の復習。root ディレクトリの inode の番号は必ず 2 なので、そこから各ディレクトリやファイルを探索していく。
inodeに格納されるファイルの管理情報には、実際のファイルの中身の物理的な配置情報も含まれます。 また、inodeにはユニークな識別番号がついています。 その識別番号がわかればinodeにアクセスでき、inodeにアクセスできれば実際のファイルの配置場所がわかり、その中身にアクセスできる、という仕掛けです。
最後はカーネルのストレージアクセスのバッファリングの話も出てきた。
Go言語で、ストレージへの書き込みを確実に保証したい場合は、os.FileのSync()メソッドを呼びます。
とあったんだけど、呼び出すか呼び出さないかの判断が難しそう
パスにチルダを含む場合などは要注意という感じ。
パス文字列のクリーン化に使う関数では、環境変数の展開や、POSIX系OSのシェルでホームパスを表す~(チルダ)の展開はできません。
共有ロックって何かと思ったら読み取り専用のロックのことだった。
ファイルのようなリソースのロックには、共有ロックと排他ロックという区別があります。 共有ロックは、複数のプロセスから同じリソースに対していくつも同時にかけられます。 一方、排他ロックでは他のプロセスからの共有ロックがブロックされます。 この区別により、「読み込み(共有ロック)は並行アクセスを許すが、書き込み(排他ロック)は1プロセスのみ許可する」、といったことが可能です。
非同期処理の分類
- 同期・ブロッキング
- 同期・ノンブロッキング:いわゆるポーリング
- 非同期・ブロッキング: 準備が完了したものがあれば通知してもらう、イベント駆動モデル
- I/O多重化(I/Oマルチプレクサー)とも呼ばれる
- 非同期・ノンブロッキング:メインプロセスのスレッドとは完全に別のスレッドでタスクを行い、完了したらその通知だけを受け取る
- POSIXのAPIで定義されている非同期I/O(aio_*)インタフェースが有名
Node.jsでも、Linuxのaioの採用が何度か検討されましたが、「2016年でもまだ安定していない」「Linux作者のリーナスも興味がなく、改善される見込みがない」などのいくつかの理由によって却下されています12
こういうイメージ大事そうだけど、まだ体に馴染んではいない。特に、select構文にdefault節があるときの処理は苦手意識があるなー。
- goroutineをたくさん実行し、それぞれに同期・ブロッキングI/Oを担当させると、非同期・ノンブロッキングとなります
- goroutineで並行化させたI/Oの入出力でチャネルを使い、他のgoroutineとのやりとりする個所のみの同期が行えます
- このチャネルにバッファがあれば書き込み側も、ノンブロッキングとなります
- これらのチャネルでselect構文を使うことで非同期・ブロッキングのI/O多重化が行えます
- select構文にdefault節があると、読み込みをノンブロッキングで行えるようになり、aio化が行えます。
知らなかった。sudo chmod u+s xxxx でフラグは付与できる
プロセスのユーザーのIDやグループIDは、通常は親プロセスのものを引き継ぎます。 しかしPOSIX系OSでは、SUID、SGIDフラグを付与することで、実行ファイルに設定された所有者(実効ユーザーID)と所有グループ(実効グループID)でプロセスが実行されるようになります
ここら辺は気が利いている。
os.StartProcess()を使って実行ファイルを指定する場合は、exec.Command()と異なり、PATH環境変数を見て実行ファイルを探すことはしません。 そのため、絶対パスや相対パスなどで実行ファイルを直接指定する必要があります。 exec.Command()の場合には、内部で使っているexec.LookPath()を使うことで、探索して実行が可能です。
Python の GIL はこういう文脈の話だったのか〜
スクリプト言語では、インタプリタ内部のデータの競合が起きないようにGIL(グローバルインタプリタロック)やGVL(ジャイアントVMロック)と呼ばれる機構があり、同時に動けるスレッド数が厳しく制限されて複数コアの性能が生かせないケースがあります。
sat さんの本でもよく出てきたけど、「コピーオンライト」はよく出てくるな〜 概念としては、書き込みがあって初めて該当のデータをコピーする、それまではデータを共有するという考え方だったはず。
親子のプロセスが作られるときは、どちらかのプロセスでメモリを変更するまではメモリの実体をコピーしない「コピーオンライト」でメモリが共有されます
こう捉えるのは確かにわかりやすそう
これまでの記事で何度も登場したシステムコールは、ユーザ空間で動作しているプロセスからカーネル空間にはたらきかけるためのインタフェースでしたが、 その逆方向がシグナルだと考えることもできます。
シグナル忘れてしまうが、SIGKILL や SIGTERM くらいは覚えておきたい
SIGKILL:プロセスを強制終了
SIGTERM:kill()システムコールやkillコマンドが送信するシグナルで、プロセスを終了させるもの
ここら辺の話は最近インフラ移行をやっているので、身につけた感覚だ
スキーマ変更を伴うような場合に、新旧の環境を自由自在に行き来きしたり、A/Bテスト的に新旧のバージョンを混在させることは、簡単ではないのです。
ほかにもさまざまな方法が考えられると思いますが、メンテのコストや失敗時の影響の大きさを考えると、完全な無停止はあきらめてメンテナンス期間を設けるほうがリーズナブルだと言えます。
このイメージを忘れないようにしたい
並行(Concurrent): CPU数・コア数の限界を超えて複数の仕事を同時に行うこと
並列(Parallel): 複数のCPU、コアを効率よく扱って計算速度を上げること
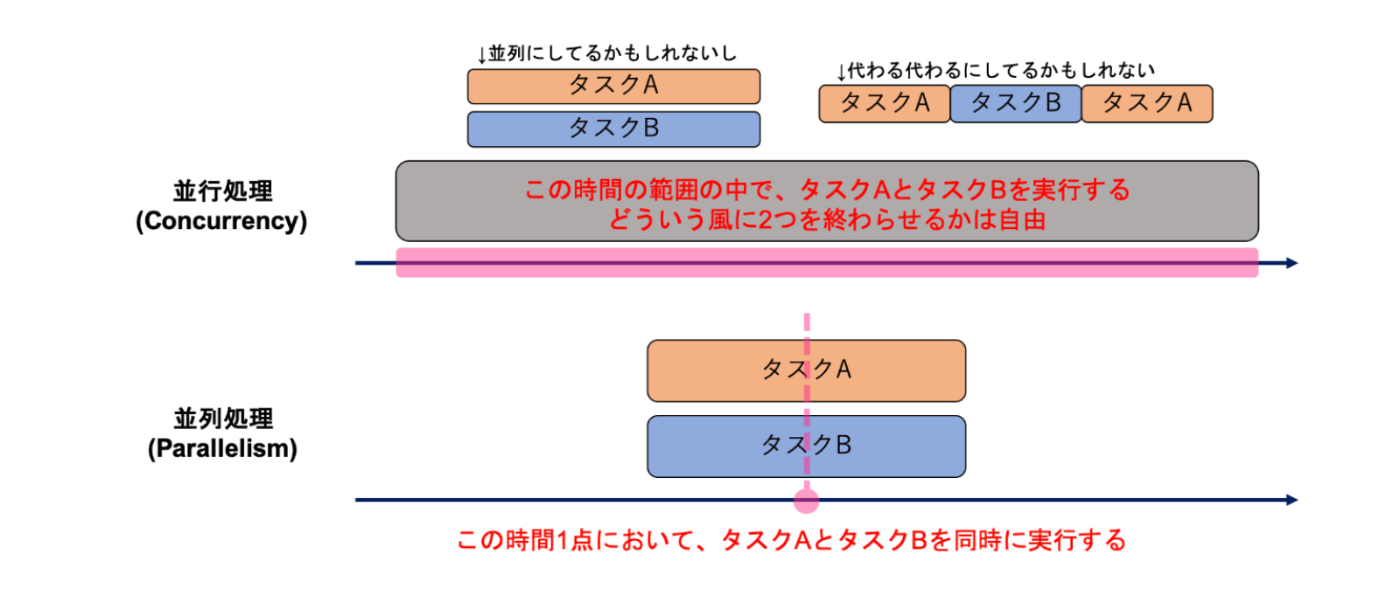
なるほどなー
注意が必要なのは、クローズされているかどうかを受信側で知るための明確な方法がない点です。 過去にはクローズ状態かどうかを判定する関数が提供されていましたが、今はありません。 クローズされているとデフォルト値が返ってくるため、実際に数字の0を送信する必要がある場合には、数値だけ見ても正常値と異常値の判定ができません。 プログラムの意図を明確にするには、終了情報のやりとりのために別のチャネルを利用すべきです。
マルチプロセスはメモリ空間を分離できる一方で、次のようなデメリットもある。
フォークによるマルチプロセスのデメリットは、起動のために時間がかかる点です。 そのため、事前にフォークしておくなどしてプロセスをCPUコア数分作っておき、プロセスプールに貯めておいて必要になったらすぐに使えるようにする、といった工夫が行われます。
プロセス間でデータを共有するには、共有メモリ5やプロセス間通信、メッセージ・キュー6などの仕組みが必要です。
イベント駆動は、並行処理のためによく利用され、I/Oが支配的になるような処理で相性が良い。
イベント駆動が主に使われるのは、並列化ではなく並行処理のためです。 ファイルI/Oやネットワークアクセスなど、I/O待ちが多いプログラム(I/Oバウンドなプログラム)で使います。
たまに CPU を Max で指定すると遅くなる?みたいなことあった気もするけど、こういうこともあったりするのか〜
最速を狙おうとすると、このデフォルト値の半分に設定するほうがスループットが上がる場合があります。 現代のCPUのいくつかは、余剰のCPUリソースを使って1コアで2つ以上のスレッドを同時に実行する機構(ハイパースレッディングや、SMT(Simultaneous Multi-Threading))を備えています。 そのような機構を利用している場合、1コアで2つのヘビーな計算を同時に実行すると、CPUコアのリソースを食い合ってパフォーマンスが上がらないことがあります2。 筆者が執筆で使っているMacBookPro(Core i7の2014モデル)の場合、runtime.NumCPU()は8を返しますが、これも物理コア数が4で、SMT機能による論理コア数がこの返り値となっています。
Mutex と channel の使い分けについて。簡単な message passing ならチャネルで良い気がしつつ、少し複雑になると select を使いこなす必要がありちょっと苦手意識がある。
Go言語Wikiには、Mutexとチャネルの使い分けについて次のようにまとめられています5。
チャネルが有用な用途:データの所有権を渡す場合、作業を並列化して分散する場合、非同期で結果を受け取る場合
Mutexが有用な用途:キャッシュ、状態管理
sync.Cond が出てきて、あんまりよくわからなかったけど、次の記事で少し理解できた気がする?
ここら辺の感覚はバックエンドをやるなら意識した方が良さそうだな〜
I/O待ちが主体であればそれでも問題ありませんが、計算速度はループをいくら増やしてもCPUのコア数以上にはスケールしないため、CPUの負荷が重い場合は次に紹介するgoroutineループを利用するほうがいいでしょう。
Go での Promise がどんな感じになるかイメージついた
依存関係のあるタスクを表現する: Future/Promise
最後の方にあった GPU とかアクターモデルの話はふんわりしか理解できなかったなー
メモリ管理のおおまかな話は読む前から理解していたが、ここでの説明を理解するのは難しかった... もう少し図があると理解しやすかったかも。
ざっくりとこんな流れを解説していた気がする
- プロセスが起動すると OS がメモリを確保する
- 確保したメモリを プロセスが扱えるようにマッピング
- ランタイムが、メモリ領域をヒープやスタックといった種類に分類して管理
仮想化・コンテナの復習の内容だった