Authorization Academy を読む
1章は Authorization について
Authentication is the mechanism for verifying who a user is.
Authorization is the mechanism of controlling what the user can do.
認可の場所とできること
- ネットワークレベル
- ip アドレスくらいしか情報がない
- 許可リスト形式のようなものしかできない
- IP 制限 や mTLS など
- Proxy / ルータ
- JWT のようなリクエストトークンやパスの情報を使う
- rate 制限、API key のチェック、WAF など
- WAF (Web Application Firewall):HTTP トラフィックを監視・フィルタリングして不正アクセスを防ぐ仕組み
- web application コントローラー
- DB にアクセスできるので、柔軟に情報を利用できる
- 認可は複雑なのでここでやることが多い
- DB アクセス時 (SQLクエリで)
- データベースのフィルタリングで適用できる
アプリケーションに実装することの多い認可だけど、普通に実装するとコードが重複したりして大変。そこで、よく使われる認可モデル・認可 API のインターフェイスを導入するのをすすめている。
認可モデルは次の3つの要素からなる。例えば、actor: "user A", action: "read", resource: "repository A" みたいな感じ。
- actor: Who is making the request
- action: What are they trying to do
- resource: What are they doing it to
認可 API のアーキテクチャは次の2つからなる
- enforcement
- リクエストから認可モデルを構築
- 認可の結果を受けてどういう処理をするのか決める
- decision
- 認可モデルを受け取って、認可の結果を返す
認可の全体的なアーキテクチャに3つを紹介している
- 分散型アプローチ
- すべてのアプリケーションが独自の承認を管理する
- 実装が最も簡単な一方で、コードの重複実装が必要になる
- 中央集権型アプローチ
- 複数のアプリケーション間で共通の認可ロジックを利用し一貫性を維持する
- 意思決定を行うために多くの認可データをアプリケーション外に一元管理する必要がある。
- ハイブリッドアプローチ
- 必要に応じて他のアプリケーションの認可の結果を利用しつつ、アプリケーションごとに認可する
全体的なおすすめの構成について
- 認証は ID プロバイダーを使用する
- アプリケーションで認可を強制する
- インターフェイスを利用して、認可ロジックをアプリケーションから分離する
- 認可データはアプリケーション内に保持する
- 分散型 or ハイブリッドアプローチを使う
2章は ロールベースのアクセス制御について
→ ロールに権限情報を紐づけて、ユーザーにはロールを割り当てる
ユーザーがとある組織内に所属するとしての認可ロジックの流れを紹介している。次のフローチャートが大変わかりやすかった。認可モデルを使うことで、かなり実装も簡潔になるということも理解できた。

以前の例だとユーザーが1つの組織に所属する前提だったので、複数の組織に所属することも考える。この場合は、ユーザーと組織とロールからなるテーブルを用意し、次のようなフローで認可ロジックを組む。
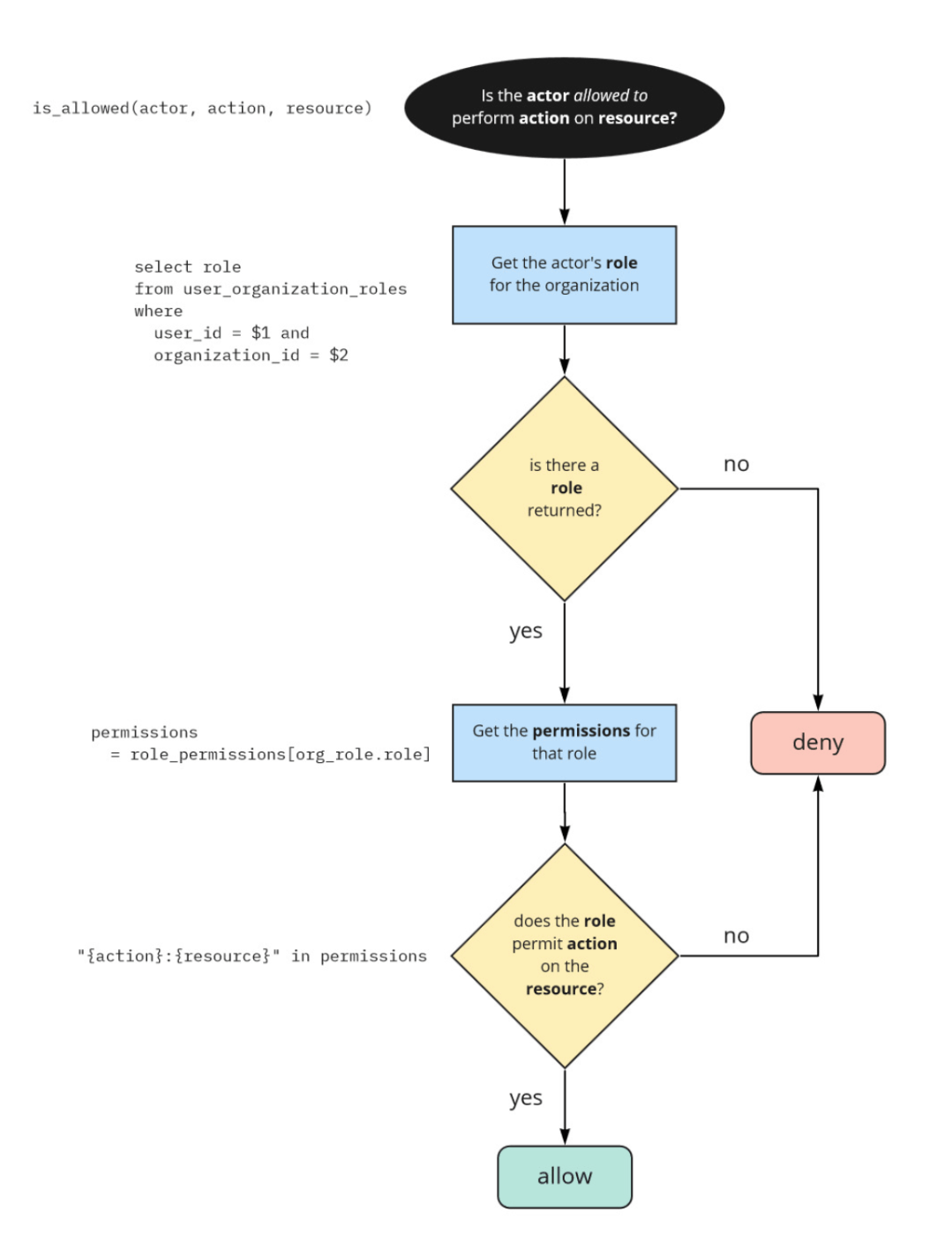
これでも現実的に多くのユースケースをカバーできるが、リソース単位でより細かいアクセス権の制御をしたいことがある。(組織内に複数のリソースがあり、特定のリソースだけアクセス権を厳しくしたい) リソース単位でのアクセス権を導入するとテーブル設計や認可のフローは次のようになる。


リソースの階層ごとに認可をチェックする感じになっている。最後にカスタムロールのテーブル設計や認可フローにも触れていて、なるべく実装しないことを推奨している。
GitLab / GitHub でもカスタムロールは実装してない。
3章は、リレーションベースのアクセス制御について
→ 実は前の章で取り上げたロールもリレーションに内包される概念である
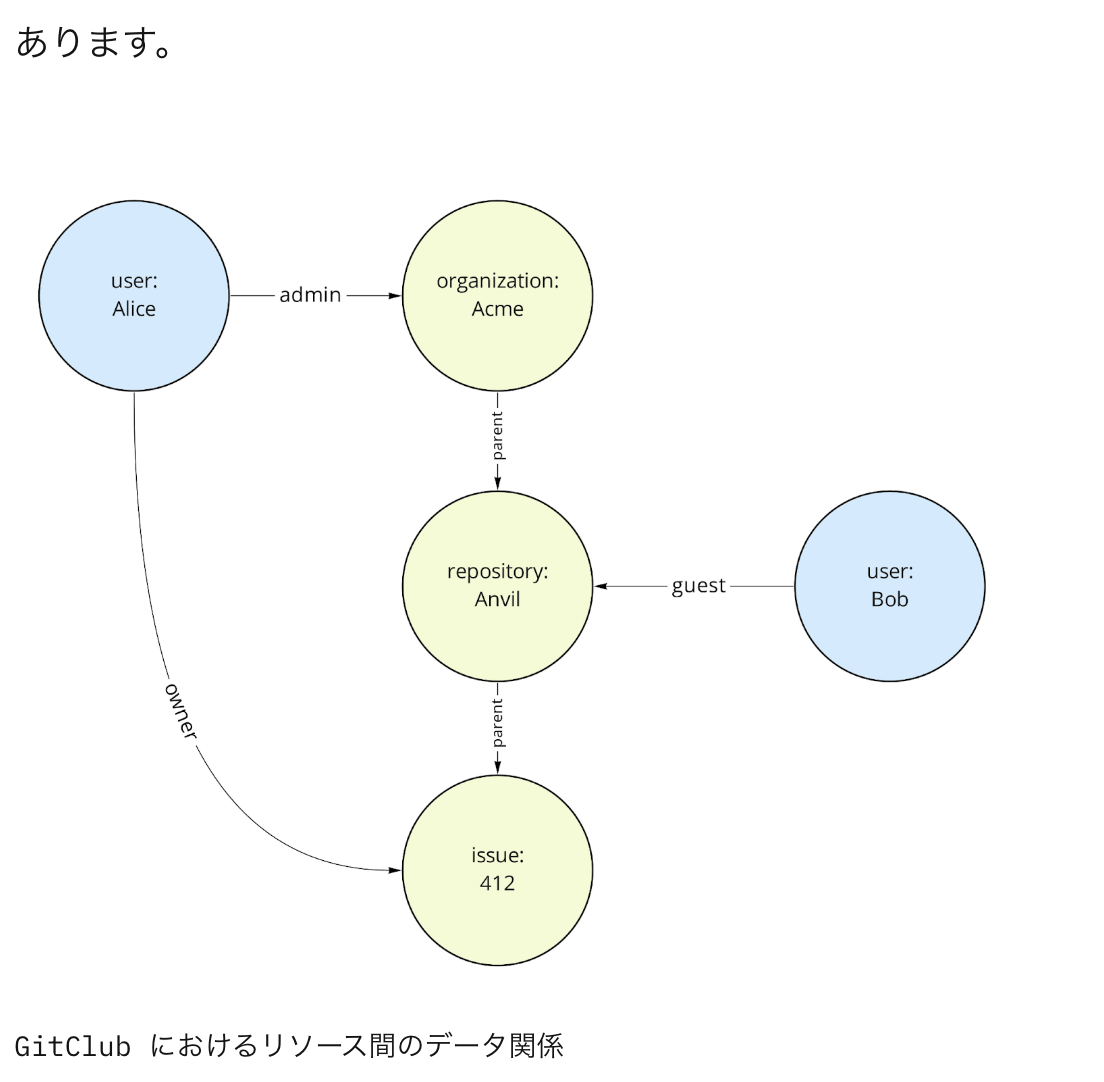
リレーションベースのアクセス制御の例
- 所有者の考慮
- 所有者かどうかを判定して、独自のアクセス制御を追加する
- 親子関係の考慮
- まず、ユーザーに直接アクセス権があるかどうかを確認
- そうでない場合は、親経由でアクセス権があるかどうかを確認
- ユーザーグループの考慮
- まず、ユーザーに直接アクセス権があるかどうかを確認
- そうでない場合は、グループにアクセス権があるかどうかを確認
所有者 (owner) を考慮した時の認可のフロー。リレーションベースのアクセス制御は次のようにロールと組み合わせて使える

ここまでいくつかのリレーションを考慮したアクセス制御について取り上げたが、リレーションをより抽象化し一元管理する方法もある。(中央集権型のアプローチ) リレーションを (source, target, reraltion_type) のようなデータでモデリングし、グラフを構築する。グラフを走査して、アクセス権について
このモデルは Google で利用されているが、アプリケーションに多くの実装が必要になるため推奨はしていない。
基本は、アプリケーションのデータモデルに今回取り上げた例のような relation を導入し、アプリケーションを起点として少しずつ対応していくのが良いとまとめられている。
4章は、enforcement について (今までは decision が中心だった)
アプリケーションの各レイヤーと認可のレベルについて紹介している
- サービス層 (middleware) + リクエストレベル
- リクエストパスやリクエストメソッドをベースとした認可
- セッショントークンにデータを付与してできる範囲での権限制御も可能
- すべてのリクエストにわたって共通の認可処理を適用したいときに利用できる
- ビジネスロジック層 + リソースレベル
- データ (リソース) を取得して、そのデータを利用して認可ロジックを構築する
- 基本的にほぼ全ての認可パターンをここで実装できる、まずはここで実装するのがおすすめ
- データアクセス層 + クエリレベル
- SQL クエリでフィルタリングする (データモデルにフィルタリングできるように認可データを追加する)
- データ全体にあらかじめ認可を適用できる
- プレゼンテーション層 + クライアント側
- 認可の状況をユーザーにフィードバックするために使う (ボタンの disable 化とか)
- バックエンドの API を再利用しつつ、ユーザーのためにもできるかぎり実装した方が良い
認可のロジックは可能な限り厳密に実装するべきと説明していて、なるほどなとなった。
ユーザーが属するリポジトリを編集できる場合は、問題をクローズできると暗黙的に想定されています。
issue を閉じれるかどうかを判断するときに、編集できる = 閉じることができるみたいな読み替えをしてはいけない。
6章 はマイクロサービスでの認可についてなので、さらっとよんで終わり。
認可に必要なモデルとデータをどう管理するのか、分散 or 共有の2つのアプローチがあるので、それぞれにメリット・デメリットなどを説明している。
認可モデルについては、基本は一元管理してAPIを公開するのが良いとしている。サービスが少ない場合には認可モデルをコピーするコストが低いので、それぞれのサービスで分散管理するのでも良いと書かれている。
認可データについては、まずは既存のインフラ・アキテクチャの資産を利用するのがよく、API 経由でのデータ共有、JWT 経由でのデータ共有、共有データベースの利用などのアプローチが紹介されている。この話題は、マイクロサービス間でどうやってデータをか共有するのかという非常に汎用的な話題である。
API 経由でのデータ共有では、パフォーマンスが問題になることが多く、サービス全体で gRPC が採用されている場合でないと難しい。
JWT 経由でのデータ共有では、HTTP のヘッダーを利用することになり、共有できるデータのサイズに制限がある。
既存の共有データベースする方法では、読み取り時にはデータベースの read レプリカを各サービスに割り当てるなどができる。通常のデータと join などをしてフィルタリングなどをかけられなくなるという欠点はある。
認可データが多くあり、既存のインフラ資産がない場合は、認可専用のサービスを運用するのも可能。この方針の最大の課題は、サービスに含まれるデータが最新かつ一貫した状態を確実に反映するようにすること。