異なる時系列間でもGBDTの予測結果をロバストに 〜WarpGBMとDirectional Era-Splitting〜
紹介するもの
Kaggleの仮想通貨予測コンペを見ていたら面白そうなディスカッションを見かけたので、以下のディスカッションで使われいるツールを紹介します。
リポジトリは以下。時系列などなんらかの要因で変化する環境(時間、レジーム、データセットなど)にわたって安定したシグナルを学習するための強力なアプローチとして、Directional Era-Splitting(DES)を導入している点が新しいようです。
論文は以下からアクセスできます。
コンセプト
一般的な決定木は分割によって最も不純度が減少するように分割点を決めますが、Directional Era-Splitting(DES)では、分割によって誘導される予測の方向を最大化させるように分割点を決めます。
以下の図のOK/NG例を見ていただくとわかりやすいかと思います。NG例では、Era1とEra2で相関の方向が違いますが、OK例では、Era1とEra2で相関の方向が同じため、OK例の特徴量が選ばれる...というコンセプトです。

実験: 使用データ
株式の予測データとして、Numeraiデータを使います。
株式のデータは時系列ごとの変化が大きく、以下のように突然使えなくなる特徴量があることがフォーラムでも言及されています。(X軸が時系列で、Y軸が相関係数の累積和。Era600くらいから突然の死をかましています)
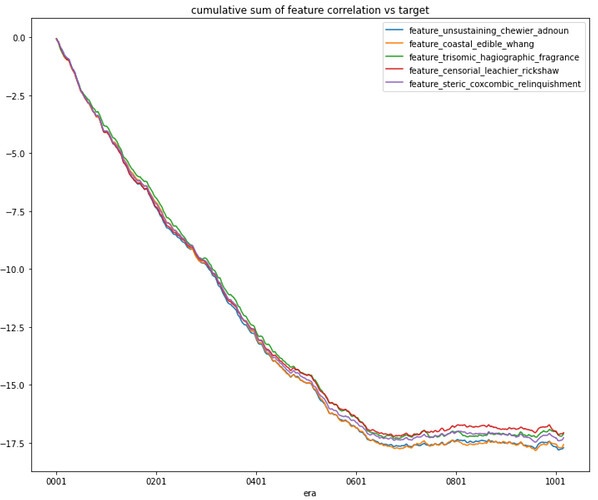
画像は: https://forum.numer.ai/t/removing-dangerous-features/5627 より。
実験: 結果
Numeraiが配布する学習データ(train.parquet)で学習を行い、Numeraiが配布する評価データ(validation.parquet)で評価を行いました。結果として、相関係数の平均値もシャープ・レシオも上がっています。
| 方法 | 相関係数(平均) | シャープ・レシオ |
|---|---|---|
| LightGBM | 0.025 | 1.118 |
| WrapGBM | 0.028 | 1.262 |
各時系列ごとの相関係数は以下の通りです(青がLightGBM、赤がWrapGBM)。
WrapGBMのほうが全体的に相関係数の値が安定していることがわかるかと思います。

参考: コード
!pip install -Uqq numerapi lightgbm==4.0.0
!pip install -Uqq git+https://github.com/jefferythewind/warpgbm.git
!mkdir -p models/
import gc
import os
import glob
import json
import pickle
import numerapi
import itertools
import cloudpickle
import numpy as np
import pandas as pd
import lightgbm as lgb
import scipy.stats as st
import matplotlib.pylab as plt
from tqdm import tqdm
from warpgbm import WarpGBM
from collections import defaultdict
from sklearn.model_selection import KFold
from contextlib import redirect_stderr, redirect_stdout
napi = numerapi.NumerAPI()
# Notebook実行時に大量に出力がでてしまうため抑制
with redirect_stderr(open(os.devnull, 'w')):
napi.download_dataset("v5.0/train.parquet", "train.parquet")
napi.download_dataset("v5.0/validation.parquet", "valid.parquet")
napi.download_dataset("v5.0/features.json", "features.json")
feature_metadata = json.load(open("features.json"))
# 学習周りのconfigファイル
debug = False
n_splits = 3
seed_all = 0
params = {
'n_estimators': 2000,
'boosting_type': 'gbdt',
'learning_rate': 0.03,
'num_leaves': 32,
'metric': 'rmse',
'colsample_bytree': 0.1,
'subsample': 0.8,
'seed': seed_all,
'force_row_wise': True,
'device': 'gpu'
}
# targetsの選択
targets = ["target"]
# 特徴量の選択
feature_set_name = "medium"
feature_cols = feature_metadata["feature_sets"][feature_set_name]
# データの読み込み
train = pd.read_parquet("train.parquet", columns=feature_cols+["era"]+targets).dropna()
# 学習
cv = KFold(n_splits=n_splits)
models_lgb = []
models_wgb = []
target = targets[0]
for fold, (trn_idx, val_idx) in enumerate(cv.split(train), start=1):
trn_x = train.iloc[trn_idx, :][feature_cols].values
trn_y = train.iloc[trn_idx, :][target].values
val_x = train.iloc[val_idx, :][feature_cols].values
val_y = train.iloc[val_idx, :][target].values
era_trn = train.iloc[trn_idx, train.columns.get_loc("era")].values
era_trn = np.array([int(era) for era in era_trn])
model_lgb = lgb.LGBMRegressor(**params)
model_lgb.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)],
callbacks=[lgb.early_stopping(stopping_rounds=100, verbose=False)],
)
models_lgb.append(model_lgb)
model_lgb.booster_.save_model(f"models/model.lgb.fold{fold}.{target}.txt")
model_wgb = WarpGBM(max_depth=5, n_estimators=2000, learning_rate=0.03, num_bins=7, colsample_bytree=0.1)
model_wgb.fit(
trn_x, trn_y,
era_id=era_trn,
X_eval=val_x,
y_eval=val_y,
eval_every_n_trees=50,
early_stopping_rounds=100,
)
models_wgb.append(model_wgb)
with open(f'models/model.wgb.fold{fold}.{target}.pkl', mode='wb') as f:
pickle.dump(model_wgb, f)
del trn_x, trn_y, val_x, val_y; gc.collect()
del train; gc.collect()
valid = pd.read_parquet("valid.parquet", columns=feature_cols+["era"]+targets).dropna()
era_targets = ["era", "target"]
valid_sub = valid[era_targets].copy()
valid_sub[f"{target}_predict_lgb"] = 0
valid_sub[f"{target}_predict_wgb"] = 0
for model in models_lgb:
valid_sub[f"{target}_predict_lgb"] += model.predict(valid[feature_cols].values) / len(models_lgb)
for model in models_wgb:
valid_sub[f"{target}_predict_wgb"] += model.predict(valid[feature_cols].values) / len(models_wgb)
del valid; gc.collect()
valid_sub.to_csv("valid_sub.csv.gz")
spr_lgb = pd.Series()
spr_wgb = pd.Series()
for era in sorted(valid_sub["era"].unique()):
valid_sub_ext = valid_sub.query("era == @era")
spr_lgb[int(era)] = st.spearmanr(valid_sub_ext[f"{target}_predict_lgb"], valid_sub_ext["target"])[0]
spr_wgb[int(era)] = st.spearmanr(valid_sub_ext[f"{target}_predict_wgb"], valid_sub_ext["target"])[0]
print("## Stats")
print(f"LightGBM, Mean: {round(spr_lgb.mean(), 4)}, Sharpe: {round(spr_lgb.mean() / spr_lgb.std(), 4)}")
print(f"WrapGBM, Mean: {round(spr_wgb.mean(), 4)}, Sharpe: {round(spr_wgb.mean() / spr_wgb.std(), 4)}")
spr_lgb.plot(c="blue")
spr_wgb.plot(c="red")
Discussion