🤖
Kaggleでよく使われるStackingとはなにか?(実例を元に解説)
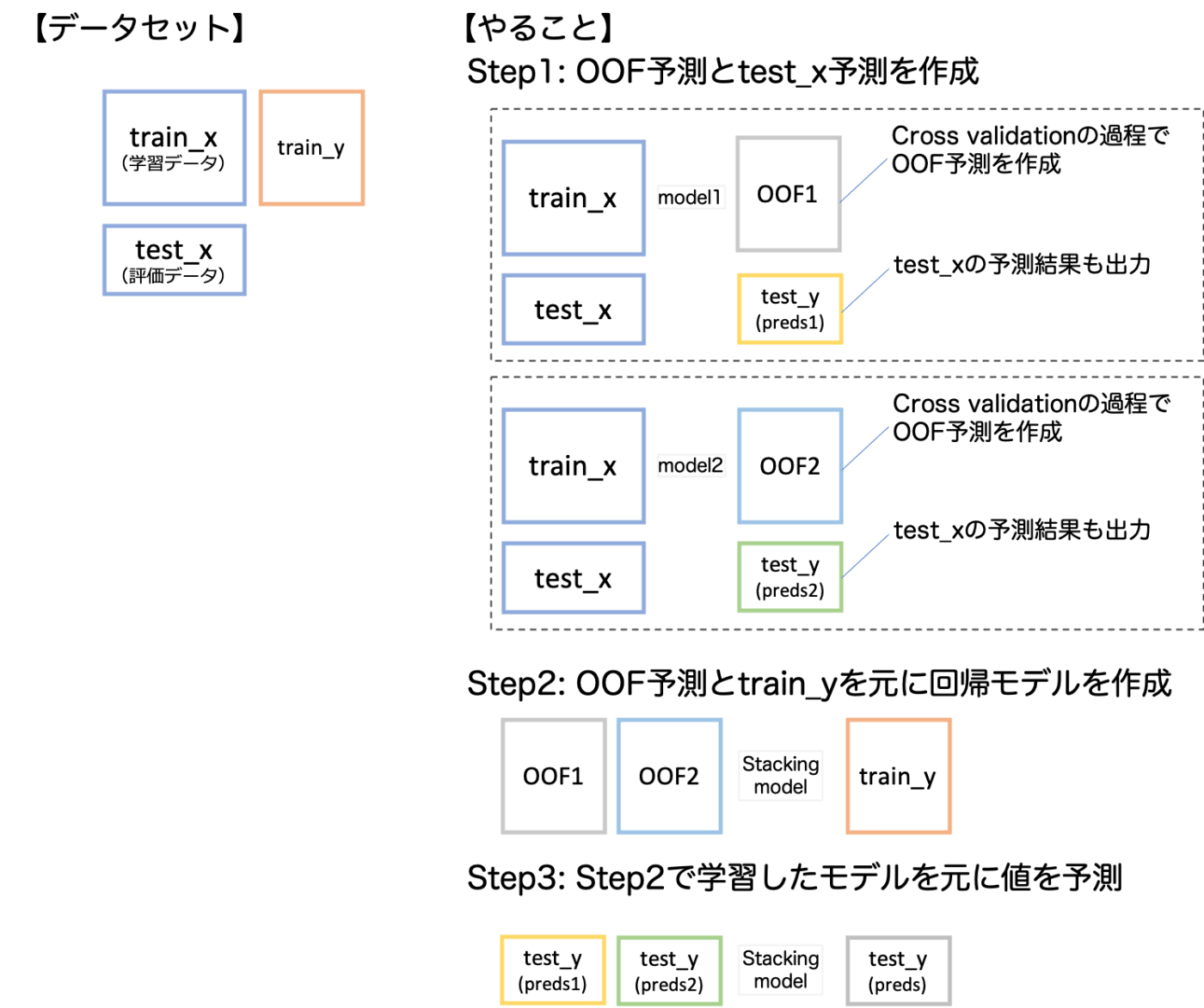
Stackingとは?
学習データのout of fold(OOF)の予測値を元に機械学習によってアンサンブルを行う手法のこと。
絵にするとこんな感じです。
例題
いつものごとく、カリフォルニア住宅データセットを使って、回帰問題を解いてみました。データセットに関する説明は以下。
戦略としては、最初にtrain_test_splitを行った上で、test dataの精度を比較しました。評価指標はRMSE。
ソースコード
Google Colab版はこちら
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import KFold, train_test_split
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Ridge
from sklearn.model_selection import GridSearchCV
california_housing = fetch_california_housing()
features = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)
labels = pd.Series(california_housing.target)
train_x, test_x, train_y, test_y = train_test_split(features, labels, test_size=0.2)
train_x.reset_index(drop=True, inplace=True)
train_y.reset_index(drop=True, inplace=True)
test_x.reset_index(drop=True, inplace=True)
test_y.reset_index(drop=True, inplace=True)
# from nyaggle.
# https://github.com/nyanp/nyaggle/blob/master/nyaggle/hyper_parameters/lightgbm.py
params1 = {
'learning_rate': 0.01,
'num_leaves': 256,
'max_bin': 255,
'max_depth': -1,
'bagging_freq': 5,
'bagging_fraction': 0.7,
'feature_fraction': 0.7,
"n_estimators": 10000,
"early_stopping_rounds": 50,
'metric': 'rmse'
}
params2 = {
'num_leaves': 333,
'min_child_weight': 0.03454472573214212,
'feature_fraction': 0.3797454081646243,
'bagging_fraction': 0.4181193142567742,
'min_data_in_leaf': 106,
'max_depth': -1,
'learning_rate': 0.006883242363721497,
'reg_alpha': 0.3899927210061127,
'reg_lambda': 0.6485237330340494,
"n_estimators": 10000,
"early_stopping_rounds": 50,
'metric': 'rmse'
}
# Only this, Optuna tuning result
params3 = {
'bagging_fraction': 1.0,
'bagging_freq': 0,
'feature_fraction': 0.8,
'lambda_l1': 0.4987678118854316,
'lambda_l2': 0.046572639037250035,
'min_child_samples': 20,
'num_leaves': 98,
"n_estimators": 10000,
"early_stopping_rounds": 50,
'metric': 'rmse'
}
def cross_val(cv, model):
preds_y = np.zeros(len(test_x))
preds_oof = np.zeros(len(train_y))
for trn_idx, val_idx in cv.split(train_x):
trn_x, trn_y = train_x.iloc[trn_idx, :], train_y[trn_idx]
val_x, val_y = train_x.iloc[val_idx, :], train_y[val_idx]
model.fit(
trn_x, trn_y,
eval_set=[(val_x, val_y)],
verbose=500,
)
preds_oof[val_idx] = model.predict(val_x)
preds_y += model.predict(test_x) / 3.0
return preds_y, preds_oof
def stacking(preds_test, preds_oof):
train_y_oof = np.stack(preds_oof, axis=1)
preds_y_stacked = np.stack(preds_test, axis=1)
estimator = Ridge(normalize=True, random_state=0, alpha=0.001)
param_grid = {
'alpha': [0.001, 0.01, 0.1, 1, 10],
}
grid_search = GridSearchCV(estimator, param_grid)
grid_search.fit(train_y_oof, train_y)
estimator = grid_search.best_estimator_
preds_y = estimator.predict(preds_y_stacked)
return preds_y
cv1 = KFold(n_splits=3, shuffle=True, random_state=1)
model1 = lgb.LGBMRegressor(**params1)
preds_y1, preds_oof1 = cross_val(cv1, model1)
cv2 = KFold(n_splits=3, shuffle=True, random_state=2)
model2 = lgb.LGBMRegressor(**params2)
preds_y2, preds_oof2 = cross_val(cv2, model2)
cv3 = KFold(n_splits=3, shuffle=True, random_state=3)
model3 = lgb.LGBMRegressor(**params3)
preds_y3, preds_oof3 = cross_val(cv3, model3)
preds_test = [preds_y1, preds_y2, preds_y3]
preds_oof = [preds_oof1, preds_oof2, preds_oof3]
preds_y_stacking = preds_y_stacked = stacking(preds_test, preds_oof)
preds_y_ensemble = np.mean([preds_y1, preds_y2, preds_y3], axis=0)
print("Stacking", np.sqrt(mean_squared_error(test_y, preds_y_stacking)))
print("Ensemble", np.sqrt(mean_squared_error(test_y, preds_y_ensemble)))
出力
Stacking 0.42584899093406925
Ensemble 0.42729936896579673
単純にアンサンブルするより、Stackingする方がわずかに成績がよくなっているのがわかるかと思います。
Discussion
参考になる記事をありがとうございます.初歩的な質問で申し訳ありませんが,一点質問があります.
train, val, testの分割ではなく,trainとvalのみでLeaveOneOutの交差検証でハイパラサーチなしでモデル評価をしたい場合において,このstackingを使うことは可能でしょうか?
返信遅くなってしまいすみません。testがない場合はstackingはleakに相当するため不可ですね。