なるほどTCPソケットをruby 3.4.0preview2でやる
なるほどTCPソケットという本が無料で公開された。
同じ著者、訳者のなるほどUnixプロセスは API サーバーなんかが責任を引き取ってうまくやってくれているので Web プログラミングでは知らなくても初められてしまう Unix のプロセスというものについて実例を手で動かしながら楽しくわかりやすく学べた。
プロセスのこと最初は知らないで書き初めてもなんとか動いたりするんですけど、プログラミングをしていると必ずあるチューニング・デバッグ・トラブルシューティングのときには知らないと進めなくなってしまうので、本で学べたのは私にとって大変よかった。
プロセスと同じように、TCP ソケットを知らなくても初められるけれど行き詰まったときには欠かせない知識なのでこの機会に取り組んでみる。10 年くらい前の本で、最新の Ruby で動くかはわからない。もし動かないところがもしあればそれはそれで面白いし、本やコードへのコントリビュートチャンスでもあるので楽しみだ。
はじめに
ネットワークプログラミングとは、突き詰めると共有と通信のことだ。
なるほどね。一通り読んでからプロローグに戻ると味わい深い作品ってたくさんあると思うので、終わったら最後にまたこの文を眺めてみよっと。
バークレーソケットAPI
本書はバークレーソケットAPI とその使い方に焦点をあてている。バークレーソケットAPI は、1983 年BSD オペレーティングシステムのバージョン4.2 で初めて登場した。
モダンなプログラミング言語のほとんどでサポートされているAPI でもある。そして、このAPI は1983 年に世界に登場したときと変わらないAPI だ。
へえ。最初に出して変わらず使われている頑健さがすごい。
バークレーソケットAPI が古びれない要因の1 つは、基礎となるプロトコルの詳細を知らなくてもソケットが使用できるということだろう。この点は鍵であり、本書の中で詳しく述べるつもりだ。
第1 章 はじめてのソケット
1.2 はじめてのソケットを作る
require 'socket'
socket = Socket.new(Socket::AF_INET, Socket::SOCK_STREAM)
INET ドメインでSTREAM タイプのソケットが作られる
INET はインターネットの略で、具体的にはIPv4 プロトコルファミリのソケットを参照する。
STREAM の部分はストリームを使って通信すると指定している。このストリームはTCP によって提供される。ここでもしSTREAM の代わりにDGRAM(ダイアグラム)を指定した場合は、UDP ソケットを参照する。このタイプの部分は、作成するソケットの種類をカーネルに伝える。
AF_INET とか SOCK_STREAM を説明してと言われてもこれまではできなかったかな。Socket.new のリファレンスは読むだろうけど。これからはリファレンスを読む前からちょっとはわかっている状態になった。
1.3 エンドポイントを理解する
通信したい2 つのソケットがある場合、それらのソケットは、お互いを見つけられるように互いの場所を知っている必要がある。これは電話と一緒だ。もし誰かと電話をしたいと思ったら相手の電話番号を知っている必要があるだろう。
ソケットはIP アドレスを使って特定のホストへとメッセージを送る。ホストは固有のIP アドレスによって識別される。IP アドレスはホストを指す「電話番号」だ。
1.4 ループバック
IP アドレスは、常にリモートホストを参照しているわけではない。とくに開発時には、ローカルホスト上のソケットへ接続したいと思うだろう。
ほとんどのシステムは、ループバックのインターフェイスを備えている。
あたりまえにあって気づかないけど、自身のアドレスを手間少なく指定できるのは便利な仕組みだ。
もしこういう便利なものがないときは「私のアドレスって何ですかね」という問い合わせを誰かにして、返ってきた値を使うということになるんだろうな。
1.6 ポート
エンドポイントには、もう1 つの重要な部分がある。それがポート番号だ。電話番号の例えを続けよう。もしオフィスビル内の誰かと会話をしようとした場合は、内線番号もダイヤルする必要があるだろう。ポート番号はソケットのエンドポイントの「内線番号」だ。
なるほど〜。著者は「電話番号」「内線番号」という比喩でアドレスとポートを説明してくれているんだな。これもまたイメージしやすい。
IP アドレスとポート番号の組み合わせは、各ソケットに対して一意でなければならない。つまり、IPv4 アドレスを持つソケットと、IPv6 アドレスを持つソケットが同じポート番号を持つことは可能
これは知らなかった。
1.7 2 つ目のソケットを作る
他のソケットとデータ交換する準備はできていない。次の章では、ソケットを使って実際の作業を行う準備をしていこう。
👍
1.8 ドキュメント
$ man 2 socket

2 について教えて欲しいって? これはman プログラムにman ページ中のセクション2 を探すよう指示している。man ページは複数のセクションに分割されている。
• セクション1: だれもが実行できるユーザーコマンド
• セクション2: システムコール
• セクション3: C ライブラリ関数
• セクション4: デバイス
• セクション5: ファイルフォーマット
• セクション7: その他についての概要。tcp(7) は重要
セクションとその番号は、私がなるほどUnixプロセスで学んだやつだ!
$ ri Socket.new

ri はRuby のコマンドラインドキュメンテーションツールだ
便利なことは間違いないけれど、近年だと irb がすごく便利になっているので、学習のときはそこから眺めるのがコンテキスト切り替えが少なくて嬉しいかもしれない。 Socket.new と書いてタブキーを押すと同じドキュメントが出てくる。

全部読みたければ (Macなら) option+d を押すと、ri Socket.new と同じものが読める。ありがとう irb。

第2 章 接続の確立
TCP 接続は2 つのエンドポイント間で行われる。
ソケットを作ると、そのソケットは「接続を開始するソケット」か「接続を待機するソケット」のいずれかの役割を担う。どちらの役割も必須だ。
ネットワークプログラミングで一般的に使われる用語だと、「接続を待機するソケット」がサーバー、「接続を開始するソケット」がクライアントとなる。
TCP 接続には 2 つ必要で、片方が接続を待つサーバー、他方が接続するクライアント 🙆
第3 章 サーバーのライフサイクル
サーバーソケットは接続を開始せず、待機(リッスン)する。典型的なライフサイクルは次のようになる。
- 作成(create)
- 割り当て(bind)
- 待機(listen)
- 受付(accept)
- クローズ(close)
- についてはすでに説明した。ここでは残りの部分について見ていこう。
英語での表現を横につけてくれているのがありがたい。
3.1 サーバーの割り当て
require 'socket'
# まず、新しい TCP ソケットを作成する
socket = Socket.new(:INET, :STREAM)
# 待機用のアドレスを保持する C 構造体を作成する
addr = Socket.pack_sockaddr_in(4481, '0.0.0.0')
# C 構造体をソケットに割り当てる
socket.bind(addr)
このコードを実行すると、プログラムは直ちに終了してしまうだろう。コードは機能している。けれど、接続を実際に待機するには、手続きがまだ十分ではないんだ。サーバーを実際にlisten モードにする方法は、もう少し待って欲しい。
サーバー側の TCP コネクションは、接続を待機してあげないといけないんだけど、まだ手順が必要ということなんだな。
3.1.1 どのポートを割り当てるべき?
1~65,535 のうちの任意のポートが使用可能ではある。けれど、ポートを選ぶ前に考慮すべき重要な慣習がある。
1 番目のルール。0~1024 の範囲のポート番号は極力使用しない。これらのポート番号は「ウェルノウンポート*1」と呼ばれ、システムが利用するために予約されている。
2 番目のルール。49,000~65,535 の範囲のポート番号は使用しない。これらは短命なポート番号だ。通常これらのポート番号は、あらかじめ定義されたポート番号を必要としない、一時的にポート番号を必要としているサービスによって使われる。
これらを除く、1025~48,999 内の任意のポートが、公平に利用できるポート番号となる。
0〜1024 は意識していたけど、49000〜65535 は意識していなかった。
本には書いていなかったけどエフェメラルポートという概念に近しいのかな。その名前は聞いたことがあるぞ。ただエフェメラルポートはシステムによってどの範囲を指すか異なるらしい。
3.1.2 どのアドレスを割り当てるべき?
127.0.0.1 に割り当てた場合は、ソケットは専用のループバックインターフェイス上でだけ待機する。この場合、localhost か127.0.0.1 に対して作られた接続のみが、サーバーソケットへ送信される。
192.168.0.5 に割り当てた場合は、ソケットはそのインターフェイス上でだけ待機する。そのインターフェイスを指定できるクライアントであれば接続は待機される。
すべてのインターフェイス上で待機したい場合は0.0.0.0 を使用できる。
自身からのみ待ちうけたいときは 127.0.0.1、外部からのみ待ちうけたいときは外部に公開している IP アドレス、自身や外部問わずどの IP アドレスであってもとにかく繋ぎに来たやつに対応したいときは 0.0.0.0 なんだな。
ここにあるサンプルコードを mac で順番に実行しようとすると 0.0.0.0 を bind しようとした時に Errno::EADDRINUSE で失敗する。それはそうな気もするんだけど、本では特に明記されていないから意図通りかよくわからないな。後で尋ねてみよう。

3.2 接続の待機
require 'socket'
# ソケットを作成し、ポート番号 4481 に割り当てる
socket = Socket.new(:INET, :STREAM)
addr = Socket.pack_sockaddr_in(4481, '0.0.0.0')
socket.bind(addr)
# やってくる接続を待機するようソケットに指示する
socket.listen(5)
このコードを実行しても、やはりまだすぐに終了してしまうだろう。接続を処理できるようになるには、サーバーソケットのライフサイクルとして必要なステップがあと1 つ必要だ
3.2.1 Listen キュー
listen メソッドに整数の引数が渡されていることに気付いただろうか。この数値は、サーバーソケットが保留可能な接続の最大数を表している。この保留可能な接続のリストはListen キューと呼ばれる
listen キュー知らなかった。
サーバーにやってきた新しいクライアント接続がいずれもListen キューに格納されるような状況を、クライアント接続の処理によって「サーバーがビジー状態である」と言う。もし、新しいクライアント接続があってListenキューがいっぱいだった場合は、クライアントはErrno::ECONNREFUSED例外を発生する
キューに入れられないときの動きというのは大別して、キューに入れられるまでクライアントを待たせる(ブロッキング)か、キューに入らないよとすぐにエラーを返すとなるんだけど、TCP 接続の場合はエラーを返すなんだな。
3.2.2 Listen キューはどれくらい大きくすべき?
Listen キューの大きさは何だかマジックナンバーのようだ。なぜキューの最大数を10,000 に設定しないのだろう?なぜ接続を拒否しないといけないのだろう?なるほど。よい質問だ。
実行時にSocket::SOMAXCONNを評価することで、Listen キューの設定可能な制限値を取得できる。私の
Mac 上では、この値は128 だった。なので、私はそれよりも大きい値は設定できない。root ユーザは、必要に応じて、システムレベルでサーバーのこの制限値を上げられる。
通常は接続を拒否したくはないはずだ。server.listen(Socket::SOMAXCONN) とすることで、Listen キューのサイズをシステムとして許可された最大値に設定できる。
3.3 接続の受付
サーバーが接続を実際に処理する部分について説明する。接続の受付はaccept メソッドを使って行う
require 'socket'
# サーバーソケットを作成する
server =Socket.new(:INET, :STREAM)
addr = Socket.pack_sockaddr_in(4481, '0.0.0.0')
server.bind(addr)
server.listen(128)
# 接続を受けつける
connection, _ = server.accept
$ echo ohai | nc localhost 4481
実行すると、nc(1) が実行され、Ruby プログラムが正常に終了することを確認できるはずだ
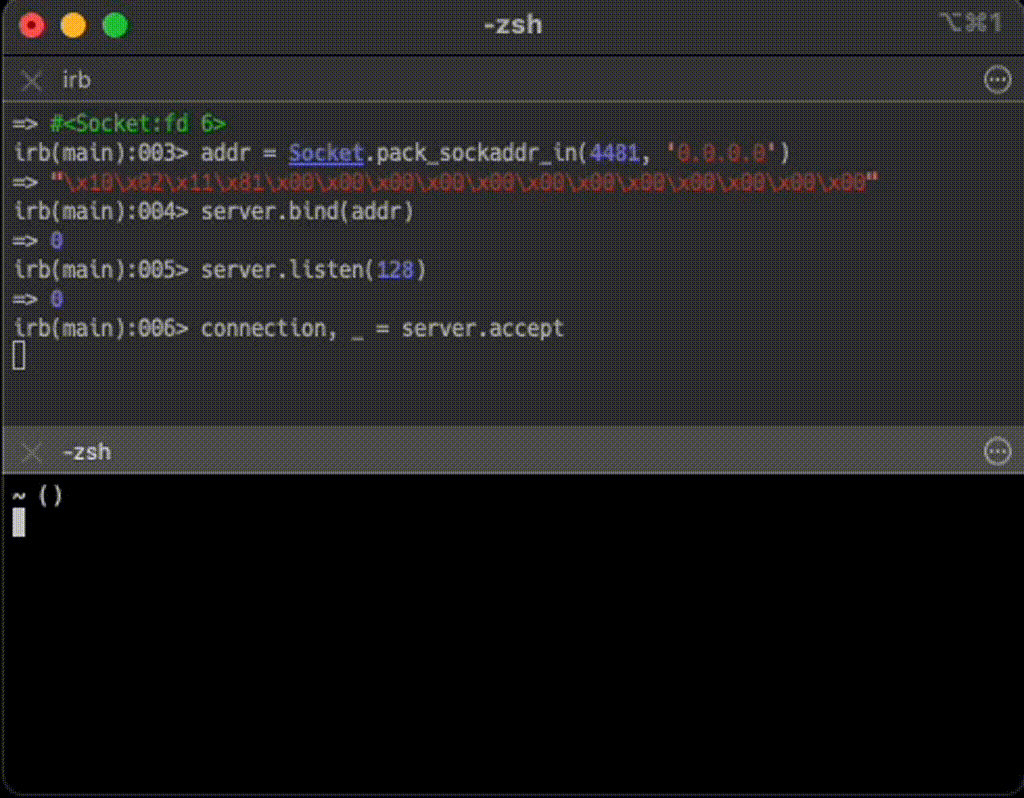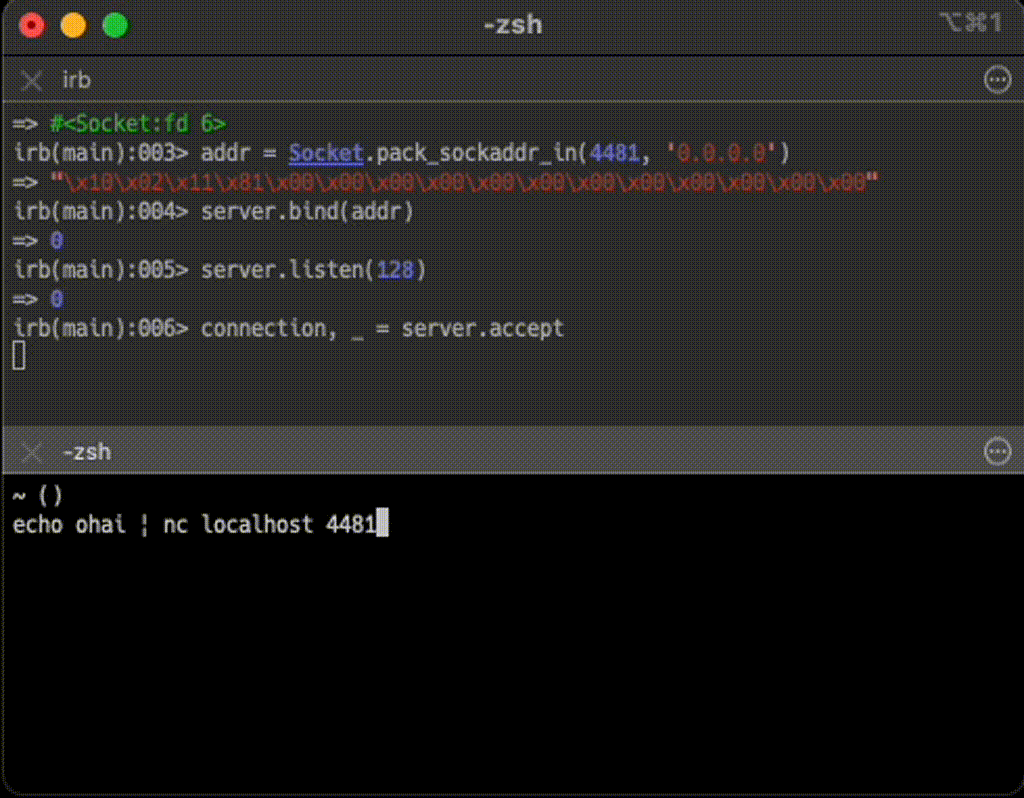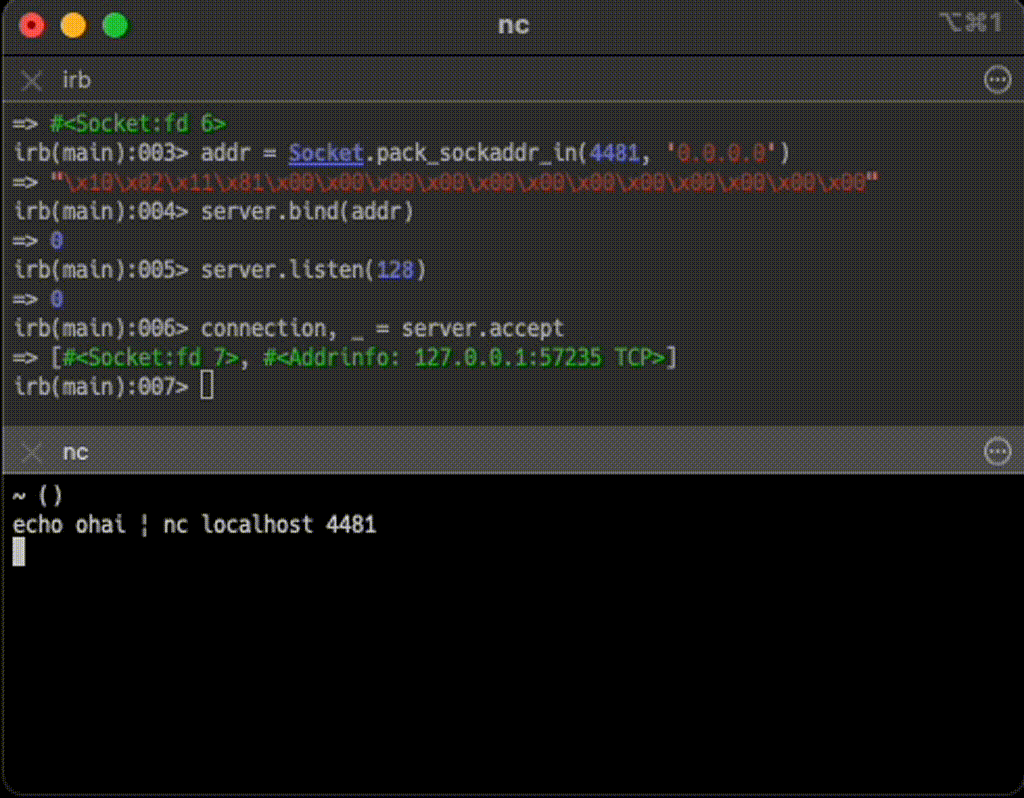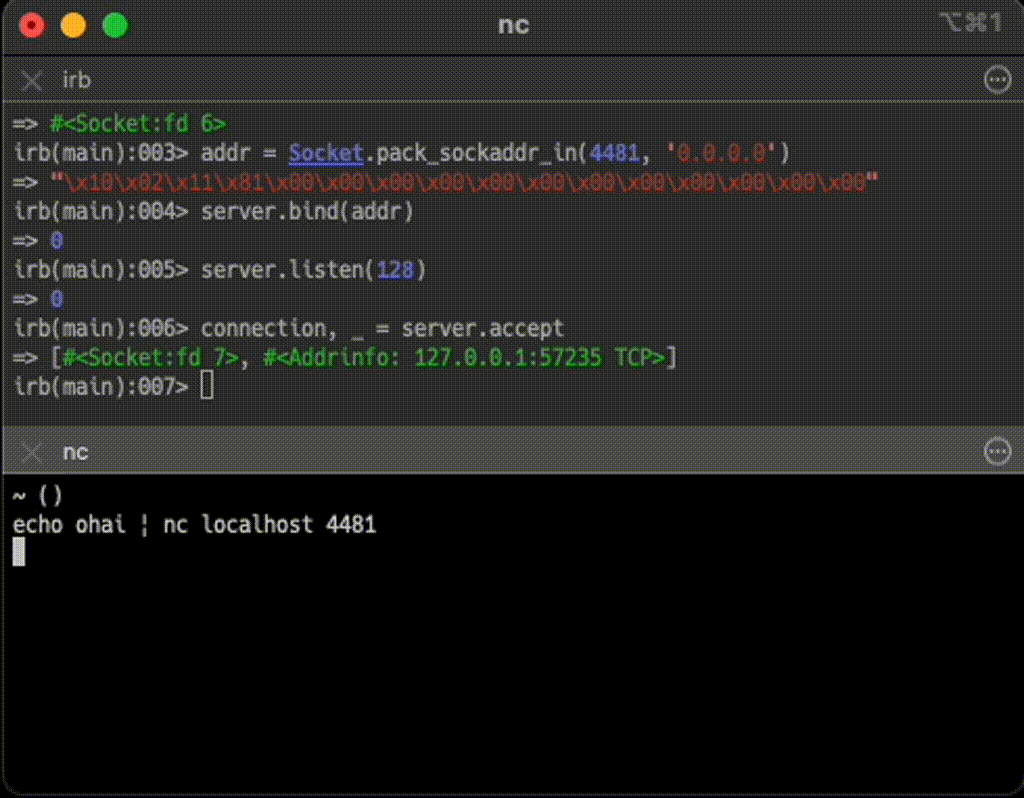
はい、確かに nc を実行したら Ruby 側のプログラムが終了した。
3.3.1 accept は処理をブロックする
accept はブロッキング呼び出しだ。呼び出されると、新しい接続を受信するまで現在のスレッドを無期限にブロックする。
3.2.1 Listen キューの所で書いていた、ブロッキングする例だ。
3.3.2 accept は配列を返す
accept メソッドは、実際にはArray オブジェクトを返却する。Array オブジェクトは2 つの要素を含んでいる。1 つ目が接続そのもので、2 つ目がAddrinfo オブジェクトだ。2 つ目の要素であるAddrinfo オブジェクトは、クライアント接続のリモートアドレスを表現している。
3.3.3 接続クラス
accept は「接続」を返す。けれど、先ほどの実行結果は、特別な「接続クラス」が存在しないことを示している。接続は、実際にはSocket クラスのインスタンスとして表現される。
大事そう。Socketクラスのインスタンスが「接続」を表現していることもあるという風にとらえた。
3.3.4 ファイルディスクリプタ
accept がSocket クラスのインスタンスを返すのはわかったが、この接続はサーバーソケットとは異なる、ファイルディスクリプタ番号(fileno)を持っている。
あ、ファイルディスクリプタ番号知ってる。なるほどUNIXプロセスで出てきたやつだ。
これは、accept がサーバーソケットとは異なる、まったく新しいSocket を返したことを示している。このSocket インスタンスは接続を表している。これは重要だ。それぞれの接続は、新しいSocket オブジェクトによって表現される。これによって、サーバーソケットはそのままの状態で、新しい接続を受け付け続けられる。
listen の結果も、accept の結果も Socket のインスタンスを返すけど、別のインスタンスであり、accept のほうは「接続」を表現しているということがわかった。
3.3.5 接続アドレス
接続オブジェクトは2 つのアドレスを持つ。ローカルアドレスとリモートアドレスだ。
接続オブジェクトのlocal_address はローカルマシン上のエンドポイントへの参照となる。接続オブジェクトのremote_address はもう一方の端のエンドポイントへの参照となる。
TCP 接続は、ローカルホスト、ローカルポート、リモートホスト、リモートポートからなる固有のグループによって定義される。これらの4 つのプロパティの組み合わせは、TCP 接続ごとに必ず一意でなくてはならない。
あるエンドポイントがローカルホスト、ローカルポートの組を開いて待ちうけているとき、まだないリモートホスト、リモートポートの組からの接続は受けつけられるけど、既に接続されているリモートホスト、リモートポートの組からの接続は(一意でなくなってしまうので)受けつけられないのか。
3.3.6 接続受付のループ
accept は1 つの接続を返す
実際のサーバーを書く場合は、だいたいが可能な限り長く接続を待機し、処理をし続けることになる。これはループを使って簡単に実現できる。
require 'socket'
# サーバーソケットを作成する
server = Socket.new(:INET, :STREAM)
addr = Socket.pack_sockaddr_in(4481, '0.0.0.0')
server.bind(addr)
server.listen(128)
# 接続を受け付ける無限ループに入り、
# 接続を処理する
loop do
connection, _ = server.accept
# 接続を処理する
connection.close
end
この基本構成はTCPコネクションを作成するプログラムでよく見るな。他の言語でもだいたいこんな感じだった。
3.4 接続のクローズ
接続を受け付けて処理を終え、サーバーが最後にするのは接続のcloseだ。これで接続の「開始ー処理ー終了」ライフサイクルが締めくくられる。
3.4.1 終了時のクローズ
なぜclose が必要なのだろうか?プログラムを終了するときには、オープンしているすべてのファイルディスクリプタ(ソケットを含む)はクローズされるはずだ。では、なぜ明示的にクローズしなければならないのだろう?これには、いくつかのもっともな理由がある。
- リソースの使用状況。もし、ソケットを使って処理をしたにも関わらず、それをクローズしない場合、使われなくなったソケットへの参照が保持されたままになる可能性がある
- オープンできるファイルの上限。これはまあ、1 つ目の理由の拡張だ。すべてのプロセスはオープンできるファイル数に制限を持っている。
ファイルを初めとする使わなくなったリソースを解放するためにクローズする。しなければ最初は平気だけれど徐々に(使っていないのに)残しているものが増えてしまって問題になるということ。
3.4.2 さまざまなクローズの仕方
ソケットは双方向通信(読み込み/書き込み)が許されている。そのため、それらのチャンネルのうちの1 つだけをクローズするということも実際には可能だ。
出力ストリームが閉じられると、ソケットのもう一方のエンドポイントにEOF が送られる
なるほど。
システム内にソケットの他のコピーが存在する場合は、ソケットは閉じられず、失ったリソースも取り戻せない。
これは、ソケットのコピーがある場合は close してもソケットは閉じられず、リソースの解放も行われないということかな。取り戻せない = OS が(まだ)回収できないというニュアンスでうけとっている。
close とは異なり、shutdown は現在のインスタンスとそのすべてのコピー上で起こっている通信を無効にし、ソケットとそのすべてのコピーの通信を完全にシャットダウンする。しかし、ソケットによって使用されたリソースは取り戻せない。ライフサイクルを完了するには、それぞれのソケットのインスタンスは必ずclose しなければならない。
Socket に shutdown というやり方があるのを知らなかった。ただリソース解放するためには shutdown だけでは足りなくて close が必要なんだな。
3.5 Ruby ラッパー
3.5.1 サーバーの構築
TCPServer.new(4481) 便利そう。
「置き換えたものだ」のコードの他の部分は気にならないけど server.listen(5) の引数は 5 なのか?
TCPServer の実装と思われるところを見てもよくわからなかった。知っている人がいれば教えてほしい。
3.5.2 接続処理
私の手元にある版だとコード例に TCPServer.new(4481)(4481) と書いてあるけれど、これは TCPServer.new(4481) のことだと思う。
最新の版だと直ってた。
3.5.3 すべてを1 つに
Ruby ラッパーの極めつけはSocket.tcp_server_loop だ
抽象度を上げて簡潔に書きたいときはこれを使うといいんだな。
第4 章 クライアントのライフサイクル
ネットワーク接続を構成する重要な役割は2 つある。
サーバーは「待機する」役割を担い、やってくる接続を処理するために待機する。一方、クライアントはサーバーとの接続を「開始する」役割を担う。
つまり、クライアントはサーバーの場所を識別して、そのサーバーへの外部接続を作成する。
サーバーは、ポート番号と、どのIPアドレスに向けられたものに反応するかを決めて待機していた。
クライアントは、どのポート番号、どのIPアドレスに繋ぎにいくか決めて進めるのだな。
クライアントのライフサイクルは、サーバーのライフサイクルよりも少しだけ短い。こんな感じだ。
- 作成(create)
- 割り当て(bind)
- 接続(connect)
- クローズ(close)
- はサーバーとクライアントで共通だ。なので、ここではクライアントにおけるbind から見ていくことにする。
4.1 クライアントの割り当て
サーバー側ではbind の呼び出しを省略することは稀だが、クライアント側ではbind を呼び出す方が稀だ。クライアントソケット(サーバーも同様)がbind 呼び出しを省略した場合は、一時的に利用可能な範囲から無作為にポート番号が割り当てられる。
使われないものを宣言する必要がない、よくわかる。
一方で、使われないならbindというステップ自体がいらないんじゃないとも思ったけど、bindの時点ではサーバーにするかクライアントにするかが(プログラマにはわかっているけれど)コンピューターには不明だから、手順としてbindも受け入れ可能な状態が存在するということだと理解した。
4.2 クライアントの接続
サーバーとクライアントの処理が本当に分かれるのは、connect 呼び出しからだ。connect 呼び出しは、リモートソケットへの接続を初期化する。
require 'socket'
socket = Socket.new(:INET, :STREAM)
# ポート番号 80 番での google.com への接続を初期化する
remote_addr = Socket.pack_sockaddr_in(80, 'google.com')
socket.connect(remote_addr)
私の環境だと Address family not supported by protocol family - connect(2) for [2404:6800:4004:801::200e]:80 (Errno::EAFNOSUPPORT) というエラーメッセージが出た。手元の環境が IPv6 環境であるせいなのかな。
Socket.new(:INET, :STREAM) を Socket.new(:INET6, :STREAM) に変えるとエラーなく動いた。
4.3 接続にしくじる
TCP は楽観的なプロトコルなので、リモートホストからの応答をできる限り長く待つ。
時間内に接続できなかった場合にはErrno::ETIMEDOUT例外が発生することになる。これはソケットを扱うときの一般的なタイムアウト例外で、要求された操作がタイムアウトしたことを示している
同様の事象は、クライアントがサーバーへ接続する際に、サーバー側でbind とlisten の呼び出しだけをしてaccept を呼び出さない場合にも発生する。connect がうまく返るのは、リモートサーバーが接続を受け付けた時だけだ。
クライアントから「繋がったー」とわかるタイミングは、サーバーが accept したときなんだな。なるほどね。
4.4 Ruby ラッパー
TCPSocket クラスを使うと Socket より簡潔な記述ができる。Socket.tcp という関数もある。
第5 章データ交換
本題に入る前に、1 つ伝えておきたいことがある。それは、TCP 接続のことをリモートソケットとローカルソケットをつないだ管のようなものだと考えると、とても役立つということだ。私たちはその管を使ってデータの固まりを送ったり受け取ったりできる。バークレーソケットAPI は、そうし
た世界観でうまくやれるように設計された。
はい。管のイメージをもつ。
5.1 ストリーム
TCP はストリーム指向のプロトコルだ。ソケットを作成するときに:STREAM オプションを渡さなければ、そのソケットはTCP ソケットにはならない。これは何を意味しているのだろう? コードにはどんな影響があるだろうか?
ストリームにはメッセージ境界の概念がないということだ。クライアントがデータを3 つに分割して送ったのに対し、サーバーはデータを読み込んだときにそれを1 つのデータとして受け取った。クライアントがデータを3 つのデータとして送信したという事実を、サーバーは知る由もない。
ただ、注意してほしいのは、メッセージ境界は保持されないけれども、ストリーム上のコンテンツ順は保持されているということだ。
サーバーは、クライアントがちょっとずつ送っているのかまとめて送っているのかはわからない。送ってくる順番は保持されていることを覚えておく。
第6 章ソケットの読み込み
6.1 単純な読み込み
ソケットからデータを読み込む最も単純な方法はread メソッドだ。
require 'socket'
Socket.tcp_server_loop(4481) do |connection|
# もっとも単純に接続からデータを読み込む方法
puts connection.read
# 一度データを読み込んだら接続を閉じる。
# クライアントに書き込みを待つのを止めてよいと知らせられる。
connection.close
end
Ruby のさまざまなソケットクラスは、File クラスと同様に、IO クラスを親に持つ。Ruby におけるすべての入出力オブジェクト(ソケット、パイプ、ファイルなど)は共通のインターフェイスを持っていて、read やwrite、flush といったメソッドをサポートしている。
これは Ruby による発明というわけではない。その基となっているread(2)、write(2) といったシステムコールは、ファイルやソケット、パイプなどで、すべて同じように機能する。この抽象化はOS 自体のコアとして組み込まれている。Unix では「すべてがファイルである」ことを覚えて
おいてほしい。
なるほどUnixプログラミングでも学んだ考えかただ。
6.2 世の中はそう単純じゃない
サーバーのread 呼び出しは、クライアントがデータを送信し終えるまでブロックしつづける。この場合、サーバーは待って、待って、待ちつづける。その間受信したデータをメモリ内にバッファリングしつづけ、それをプログラムに戻すことはない。
サーバーは「送り終わったよ」ということがクライアントから伝えられたら処理をはじめている。 tail -f などでデータが延々と送られてくるときはクライアントは「送り終わったよ」と伝えることがないので、処理をはじめるタイミングがない。
6.3 読み込む長さ
読み込む長さを指定することだ。そうすることで、クライアントが終了するまでデータを読み込み続ける代わりに、一定量のデータをread して処理を戻すようサーバーに指示できる。
require 'socket'
one_kb = 1024 #bytes
Socket.tcp_server_loop(4481) do |connection|
# 1 KB のデータを読み込む
while data = connection.read(one_kb) do
puts data
end
connection.close
end
6.4 ブロックの性質
read 呼び出しは、データがすべて到着するまで処理をブロックして待つ
この方法を使用するとデッドロック状態に陥る可能性がある。サーバーが接続から1 キロバイトずつデータを読み込もうとしているときに、クライアントが500 バイトだけデータを送信してから待機すると、サーバーは1 キロバイト受信するまでデータを待ち続けることになる。
この状況は2 つの方法で改善できる。
- クライアントが500 バイトのデータを送ったあとでEOF を送信する、
- サーバーがデータの部分読み込みを行う。
read を数値で指定しても、読みたい量が貯まらない限りブロックを続けてしまう。なるほど。
6.5 EOF
EOF は文字コードの表現ではない。EOF はそれよりももっと状態イベントに近いものだ。ソケットは、これ以上書き込むデータがない場合に、shutdown かclose を使ってそれを示せる。その結
果、もう一端の読み込み側にEOF が送られ、データがこれ以上送られてこないと伝えられる。
500 バイトのデータを送信した後でクライアントがEOF を送ればよい。サーバーはEOF を受け取ると、読み込んだ量がたとえ1 キロバイトに達していなくても、データの読み込みを止める。
はい。
EOF を送信する最も単純な方法は、そのソケットを閉じることだ。閉じられれば、間違いなくそのソケットはそれ以上データを送信しない!
6.6 部分読み込み
最初に見たデータの読み込み方は怠惰だった。read を呼び出すと、指定された長さのデータを受け取るかEOF を受け取るかしてデータが返るまで、できるだけ長く待つ。逆のアプローチを取りデータを読み込む代替方法がある。それがreadpartial だ。
readpartial 呼び出しは、ブロックするのではなく利用可能なデータをすぐに返す。
require 'socket'
one_hundred_kb = 1024 * 100
Socket.tcp_server_loop(4481) do |connection|
begin
# 100 キロバイトかそれ以下のデータを読み込む
while data = connection.readpartial(one_hundred_kb) do
puts data
end
rescue EOFError
end
connection.close
end
EOF の扱いについて、readpartial の振る舞いはread と異なる。read がEOF を受け取ったときに単に戻るのに対して、readpartial はEOFError 例外を発生させる。
要するにread は怠けものだ。できるだけ多くのデータを返すために、できるだけ長く待つ。逆に、readpartial は頑張り屋だ。利用可能なデータをできるだけはやく戻す。
read はできるだけ待つ。readpartial は今あるところまで返す。
第7 章ソケットへの書き込み
ソケットに書き込むために使う道具はただ1 つ、write メソッドだ。write メソッドの使い方は、とても簡単で直感的だ。
require 'socket'
Socket.tcp_server_loop(4481) do |connection|
# 接続にデータを書き込む単純な方法
connection.write('Welcome!')
connection.close
end
read と対になる write
第8 章バッファリング
8.1 ライトバッファ
TCP 接続でデータをwrite すると実際には何が起きるのか、というとこ
ろから話を始めることにしよう。write を呼び出して、例外が発生することなく戻ったとする。これは、ネットワークを超えてデータが送られて無事にクライアントソケットに受信された、ということを意味してはいない
いない! write が終わっても、ソケットをつないでいる相手方の (カーネルではない)プログラム がそれを受けとれているとは限らないということか。
write から正常に戻った場合、それはRuby のIO システムとその基盤であるOS のカーネルにデータが託されたことを示している。
8.2 どのくらい書き込むのが良いの?
バッファのおかげで、実際のところはそれを考える必要はない
一般的には、書き込む必要のあるデータをすべて書き込むことで、カーネルがそのデータをどのようにまとめるかを判断してくれ、それによって最高のパフォーマンスが得られるはずだ
ありがとうカーネル。気にせずに一気に書きこむね。
8.3 リードバッファ
読み込みもまたバッファされる。
TCP 接続からデータをread する際に最大読み込み長を指定した場合、実際にはRuby はあなたが指定した長さよりも多くのデータを受信できる可能性がある。
この場合、その「余分な」データはRuby の内部リードバッファに格納される。そして、次にread が呼び出されると、Ruby はカーネルに新しいデータを要求する前に、まず保留中のデータが無いか内部バッファを確認する。
よくできている。Ruby を使っている側からは違いは生じないけれど、カーネルとRubyの間でのやりとりは効率的になるように作られているのだな。
8.4 どのくらい読み込むのが良いの?
この質問の答えは、ライトバッファのように単純にはいかない。そのため、課題とベストプラクティスを見ていくことにする。
送信側からどのくらいデータが送られてくるかはわからない。これは、読み込み長を考える際は常に推測して決定するしかないことを意味している。
読み込み長を指定すると、カーネルはそのためにいくつかのメモリを割り当てる。ということは、必要以上のメモリを指定すると、使われることのないメモリを割り当てることになってしまう。
すべてのデータを取得するのに読み込みが何回も発生するような小さな長さを指定してしまった場合には、システムコールごとのオーバーヘッドが発生する。
- どの長さでくるか事前に知ることはできないので推測が必要
- 大きすぎると無駄なメモリを確保して待つことになる
- 小さすぎると細かい読み込みが発生して遅くなる
Mongrel、Unicorn、Puma、Passenger、Net::HTTP を調査したところ、これらのプロジェクトではreadpartial(1024 * 16) となっていた。つまり、読み込み長として16 キロバイトを採用していた。
だいたいこのくらいが基本で、手元でデータが集まったらそれにもとづいてチューニングしてねと書いてあった。
第9 章はじめてのクライアント/サーバー
9.1 サーバー
require 'socket'
module CloudHash
class Server
def initialize(port)
# サーバーソケットを作成する。
@server = TCPServer.new(port)
puts "Listening on port #{@server.local_address.ip_port}"
@storage = {}
end
def start
# 接続受付のループ。
Socket.accept_loop(@server) do |connection|
handle(connection)
connection.close
end
end
def handle(connection)
# EOF を受けるまで、接続から読み込む。
request = connection.read
# ハッシュ操作の結果を書き戻す。
connection.write process(request)
end
# 補助コマンド:
# SET key value
# GET key
def process(request)
command, key, value = request.split
case command.upcase
when 'GET'
@storage[key]
when 'SET'
@storage[key] = value
end
end
end
end
server = CloudHash::Server.new(4481)
server.start
9.2 クライアント
require 'socket'
module CloudHash
class Client
class << self
attr_accessor :host, :port
end
def self.get(key)
request "GET #{key}"
end
def self.set(key, value)
request "SET #{key} #{value}"
end
def self.request(string)
# 各操作ごとに新しい接続を作成する。
@client = TCPSocket.new(host, port)
@client.write(string)
# リクエストを書き込んだら、EOF を送る。
@client.close_write
# レスポンスを得るために、EOF まで読み込む。
@client.read
end
end
end
CloudHash::Client.host = 'localhost'
CloudHash::Client.port = 4481
puts CloudHash::Client.set 'prez', 'obama'
puts CloudHash::Client.get 'prez'
puts CloudHash::Client.get 'vp'
9.3 すべてをつなぎ合わせる

お、動いた。
9.4 考察
コード中のコメントから、コードの意図はわかってもらえると思う。コメントは、接続の確立やEOF など、これまで見てきた考え方と必ず結びつくようにしてある。
確かに、私にも全ての行を説明可能だった。
この例から欠けているのは、アーキテクチャパターンや設計のベストプラクティス、いくつかのまだ見ぬ高度な機能だ。
- クライアントが一回ごとに接続・切断を行っているけれど、同じ接続で複数のリクエストを処理してオーバーヘッドを減らしたい
- 現在のサーバーは一つのクライアントの接続しか受けいれられない。これを複数のクライアントから接続を受けつけられるようにしたい
こういった例がこのあとできるようになるそうだ。楽しみ。
本書の残りの部分では、効果的で理解しやすいネットワークプログラムを書けるようになるための基礎を構築していく。
第10 章ソケットオプション
ソケットオプションは、ソケットにシステム固有の振る舞いを設定するための低レベルな方法だ
10.1 SO_TYPE
require 'socket'
socket = TCPSocket.new('google.com', 80)
# ソケットの種類を表現する Socket::Option インスタンスを取得する。
opt = socket.getsockopt(Socket::SOL_SOCKET, Socket::SO_TYPE)
# オプションを表現する整数値と Socket::SOCK_STREAM の値を比較する。
opt.int == Socket::SOCK_STREAM # => true
opt.int == Socket::SOCK_DGRAM # => false
getsockopt 呼び出しは、Socket::Option のインスタンスを返す。このレベルでは、すべての作業を整数値で解決する。SocketOption#int を使うことで、返ってきたインスタンスに紐付いた整数値を取得できる。
10.2 SO_REUSE_ADDR
これはすべてのサーバーで設定されるであろう一般的なオプションだ。
SO_REUSE_ADDR オプションは、ソケットがTCP_TIME_WAIT 状態のときに、サーバーの使っているローカルアドレスを別のソケットに割り当ててもよいことをカーネルに伝える。
バッファに保留されているデータが残っている状態でサーバーのソケットをcloseしたあと、すぐに同じアドレスに別のソケットを割り当てようとしたときに Errno::EADDRINUSE を出すか別のソケットに使われているアドレスを割り当てられるようになるか変わる。
TCPServer.new とSocket.tcp_server_loop およびその親戚では、このオプションはデフォルトで有効になっている。
第11 章ノンブロッキングIO
ノンブロッキングIO は、非同期やイベントIO とは異なるものだ。
11.1 ノンブロッキング読み込み
read はEOF を受けるか、最小バイト数を受け取るまで処理をブロックする。
readpartial を使うことで、ブロックは部分的には回避できる。しかし、使用可能なデータがない場合は、readpartial を使っていたとしてもブロックする
絶対にブロックせずに読み込み操作を行なうには、read_nonblock が必要だ
なるほど、まだ読むものがない場合は readpartial でもブロックが発生する。
require 'socket'
Socket.tcp_server_loop(4481) do |connection|
loop do
begin
puts connection.read_nonblock(4096)
rescue Errno::EAGAIN
retry
rescue EOFError
break
end
end
connection.close
end
サーバーに送られたデータがない場合でも、read_nonblock 呼び出しはすぐに戻る。実際には、その場合はErrno::EAGAIN 例外が発行される。
retry はそんなに行儀がよくなく、例を簡略化するためにそうしている。
ブロックされた読み込みをリトライする適切な方法は、IO.select を使用することだ。
ソケットの配列を第一引数にしてIO.select を呼び出すと、ソケットのいずれかが読み込み可能になるまでブロックする。そのため、retry はソケットが読み込み可能な状態になったときにのみ呼び出される。
11.2 ノンブロッキング書き込み
ノンブロッキング書き込みは、前に見たwrite 呼び出しとの重要な違いがいくつかある。最も注目すべき違いは、write が渡されたすべてのデータを常に書き込もうとするのに対して、write_nonblock は部分書き込みをして返ることが可能だという点だ。
require 'socket'
client = TCPSocket.new('localhost', 4481)
payload = 'Lorem ipsum' * 10_000
written = client.write_nonblock(payload)
written < payload.size # => true
私の手元の PC で実行したら written < payload.size は false になってしまった 😅
PC の性能が高くなっているということなんだろう。payload の文字繰り返し数をさらに大きくすることで書いてある内容を再現できた。

write_nonblock メソッドは、ブロックされるとそれ以上データを書き込まない。そうして、どれくらい書き込んだかを示す値を返す。書き込まれなかった残りのデータを書き込むのは、呼び出し側の責
任となる。
write_nonblock の振る舞いは、write(2) システムコールと同じだ。書き込める分だけ書き込んで、書き込んだサイズを返す
一回の呼び出しで、要求されたすべてのデータを書き込めなかったら、一体どうすべきだろうか?その場合は、書き込めなかった分の書き込みに再挑戦する以外はない。けれど、すぐにそれをしてはいけない。裏で動いているwrite(2) がまだブロックしていた場合には、Errno::EAGAIN 例外が発行されてしまうからだ。
ここでまた IO.select か。読み書き共にノンブロッキングなメソッドを使うならIO.selectと組ませるとよいのだな。
require 'socket'
client = TCPSocket.new('localhost', 4481)
payload = 'Lorem ipsum' * 10_000_000
begin
loop do
bytes = client.write_nonblock(payload)
break if bytes >= payload.size
payload.slice!(0, bytes)
IO.select(nil, [client])
end
rescue Errno::EAGAIN
IO.select(nil, [client])
retry
end
IO.select が 2 箇所にあるのが少し奇妙に感じるのだけど、落ち着いて流れをみていくとこう書くほか書きようがない。
IO.select の2 番目の引数にソケットの配列を渡すと、そのいずれかが書き込み可能になるまでブロックするという振る舞いを利用している。
11.3 ノンブロッキングaccept
accept_nonblock は、通常のaccept にとても似ている。accept が待ち受けキューから接続を単に取り出すと説明したことを覚えてるだろうか。このとき、accept_nonblock はブロックするのではなく、Errno::EAGAIN例外を発生させる。
11.4 ノンブロッキングconnect
ここまで来ると、connect_nonblock メソッドが何をするかはだいたい推測できると思っただろうか?そうであれば、少し驚くことになるかもしれない。connect_nonblock は、他のノンブロッキングIO メソッドとは少しばかり違った振る舞いをする。
筆者の狙い通り驚いた。
他のメソッドが処理を完了するか、完了せずに適切な例外を発生させるのに対して、connect_nonblock は処理を残したまま例外を発生させる。
ピンとこなかったけど、下の例をみてわかった。connect_nonblock は現在の状態を例外で伝えてくる形なのだな。
require 'socket'
socket = Socket.new(:INET, :STREAM)
remote_addr = Socket.pack_sockaddr_in(80, 'google.com')
begin
# google.com のポート 80 番へのノンブロッキング接続を初期化。
socket.connect_nonblock(remote_addr)
rescue Errno::EINPROGRESS
# ノンブロッキング接続の試行を開始。
rescue Errno::EALREADY
# ノンブロッキング接続の試行中。
rescue Errno::ECONNREFUSED
# リモートホストは接続を拒否した。
end
第12 章多重接続
接続の多重化とは、複数のソケットと同時にやりとりすることを指す。これは並列処理を指してはいないし、マルチスレッドとも関係ない
英語版のタイトルだと Multiplexing Connections だ。マルチプレクサ、聞いたことがあるぞ。
これまでに見てきたテクニックを踏まえて、そのときどきに複数のTCP接続上のデータを処理しなくてはならないサーバーを、どのように実装するかを想像してみよう。おそらく、特定のソケットでブロックされるのを防ぐために、新しく得たばかりのノンブロッキングIO の知識を使うことになるだろう。
# 接続の配列を与える。
connections = [<TCPSocket>, <TCPSocket>, <TCPSocket>]
# 無限ループに入る。
loop do
# コネクション毎の処理...
connections.each do |conn|
begin
# ノンブロッキングな方法で各接続から読み込みを行い、
# データを受信していれば処理し、そうでなければ次の接続を処理する。
data = conn.read_nonblock(4096)
process(data)
rescue Errno::EAGAIN
end
end
end
動いた! けれど、かなり無駄が多い。read_nonblock を呼び出すたびに、少なくとも1 つのシステムコールを使う。それに、データが無いときでもサーバーはムダに多くの回数データの読み取りを行うだろう。
12.1 select(2)
# 接続の配列を与える。
connections = [<TCPSocket>, <TCPSocket>, <TCPSocket>]
loop do
# 接続が読み込みの準備を完了しているかを select(2) を使って調べる
ready = IO.select(connections)
# 読み込み可能な接続だけからデータを読み込む。
readable_connections = ready[0]
readable_connections.each do |conn|
data = conn.readpartial(4096)
process(data)
end
end
多くの接続を処理する際のオーバーヘッドを減らすために、IO.select を使用している。IO.select の用途は、いくつかのIO オブジェクトを取り、その中で読み書きが可能になっているものを教えることだ。
1 つ目は読み出したいIO オブジェクトの配列、2 つ目は書き込みたいIO オブジェクトの配列、そして3 つ目は例外的な条件に興味のあるIO オブジェクトの配列だ。
帯域外データ(詳しくは第18 章「緊急データ」で説明する)に興味がないなら、ほとんどの場合は第3 引数は無視して構わない。
IO.select は多重配列を返す。IO.select は、引数リストに対応する3つの配列を要素に持つ配列を返す。最初の要素にはブロックせずに読み取れるIO オブジェクトが含まれる。これは1 つ目の引数として渡されたIO オブジェクトの配列のサブセットとなる。2 つ目の要素はブロックせずに書き込めるIO オブジェクトが含まれ、3 つ目の要素は該当する例外的な条件を持っているIO オブジェクトが含まれる。
IO.select はブロックする。IO.select は同期メソッド呼び出しだ。すでに見てきたように、このメソッドは渡されたIO オブジェクトの状態が1つでも変化するまで処理をブロックする。どれか1 つでも状態が変化すればメソッドはすぐに返り、複数の状態が変更となっていた場合はネストされた配列を通してその結果が伝えられる。
IO.select は第4 の引数にタイムアウト値を秒単位で指定することもできる。これによって、IO.select が永遠にブロックされつづけるのを防げる。タイムアウト値には整数、または浮動小数点値を指定する。IO の状態が変わる前にタイムアウトに達した場合は、IO.select はnil を返す。
IO オブジェクトを返すto_io メソッドを持っていさえすれば、素のRuby オブジェクトであってもIO.select にそのまま渡せる。
to_io メソッドがあれば、IO.select に渡せることを知らなかった。まれに便利なこともありそう。
12.2 読み込み/書き込み以外のイベント
12.2.1 EOF
読み込み用にソケットを監視していてEOF を受信した場合、EOFは読み込み用のソケット配列の一部として返される。その場合、使用しているread(2) のバリエーションに応じて、読み込みを行った段階でEOFErrorかnil を受け取るかもしれない。
12.2.2 応答
読み込みのためにソケットを監視していて、やってきた接続を受信した場合、それは読み込み用のソケット配列の一部として返される。これについては、これらのソケットを扱うロジックを特別持っている必要があり、read よりも、むしろaccept を使う必要がある。
12.2.3 接続
前の章で、connect_nonblock を使ったときにすぐに接続できなかった場合には、Errno::EINPROGRESS 例外があがると説明した。IO.select を使うことで、そのバックグラウンド接続が完了しているかどうかを把握できる。
require 'socket'
socket = Socket.new(:INET, :STREAM)
remote_addr = Socket.pack_sockaddr_in(80, 'google.com')
begin
# google.com の 80 番ポートへの接続を
# ノンブロッキング接続を初期化する。
socket.connect_nonblock(remote_addr)
rescue Errno::EINPROGRESS
IO.select(nil, [socket])
begin
socket.connect_nonblock(remote_addr)
rescue Errno::EISCONN
# 成功!
rescue Errno::ECONNREFUSED
# リモートホストによって拒否される。
end
end
この派手なコード片は、実際にはブロッキングconnect 呼び出しを実際にエミュレートする。
require 'socket'
# パラメータの設定。
PORT_RANGE = 1..128
HOST = 'archive.org'
TIME_TO_WAIT = 5 # 秒
# 各ポートごとにソケットを作成し、
# ノンブロッキングな接続を初期化する。
sockets = PORT_RANGE.map do |port|
socket = Socket.new(:INET, :STREAM)
remote_addr = Socket.pack_sockaddr_in(port, HOST)
begin
socket.connect_nonblock(remote_addr)
rescue Errno::EINPROGRESS
end
socket
end
# 期限を設定する。
expiration = Time.now + TIME_TO_WAIT
loop do
# 期限を超えて待つことがないよう、都度タイムアウトを
# 調整しながら、IO.select を呼び出す。
_, writable, _ = IO.select(nil, sockets, nil, expiration - Time.now)
break unless writable
writable.each do |socket|
begin
socket.connect_nonblock(socket.remote_address)
rescue Errno::EISCONN
# ソケットが既に接続されていたら、成功とみなしてカウントできる。
puts "#{HOST}:#{socket.remote_address.ip_port} accepts connections..."
# ソケットをリストから削除する。
# これによって書き込み可能であると選択されることはなくなる。
sockets.delete(socket)
rescue Errno::EINVAL
sockets.delete(socket)
end
end
end
このコードでは、connect_nonblock の利点を活用して、100 数個の接続を一度に初期化している。IO.select を使ってすべての接続を監視し、正常に接続できたかを最終的に確認している
12.3 ハイパフォーマンス多重化
IO.select はRuby のコアライブラリに同梱されている。そして、その中で唯一の、Ruby プログラムで多重化を行うためのソリューションだ。
最近のモダンなOS のカーネルは、さまざまな多重化の方法をサポートしている。select(2) はその中で最も古く、できることが小さいものだ。
代替案はもちろん存在する。
poll(2) システムコールはselect(2) とは若干の違いはあるが、だいたい同じようなものだ。(Linux の) epoll(2) システムコールと (BSD の)kqueue(2) システムコールはより高い性能を提供する、select(2) とpoll(2)の代替だ。
第13 章Nagle アルゴリズム
Nagle アルゴリズム*1は、すべてのTCP 接続にデフォルトで適用されている、いわゆる最適化だ。
この最適化は、バッファリングを行わずに一度にとても少量のデータを送信するようなアプリケーションに最も適している。この基準にあわない場合は、しばしばサーバーによって無効化されている。
Wikipedia によると https://ja.wikipedia.org/wiki/Nagleアルゴリズム
アプリケーションが繰り返し1バイトなど小さな粒度で送信する問題を取り上げている。IPv4 で 20バイト、TCP自体で20バイトのヘッダーがあり、合計40バイトになるため、1バイトを送信するのに合計41バイト送信しなくてはならなく、オーバーヘッドが大きい。
という、送りたいものよりヘッダが大きすぎる問題への対処のようだ。
Nagleアルゴリズムは、telnet を実装するといった、かなり特定の状況で自分の足を打ち抜かないようにするためのものだ。Ruby のバッファリングであったり、TCP 上の一般的なプロトコルを考えると、このアルゴリズムを禁止したいと思うかもしれない。
たとえば、Ruby で作られているすべてのWeb サーバーは、このオプションを禁止している。オプションを禁止するには、次のようにすると良い。
require 'socket'
server = TCPServer.new(4481)
# Nagle アルゴリズムを禁止する。サーバーに遅延なく送信するよう伝える。
server.setsockopt(Socket::IPPROTO_TCP, Socket::TCP_NODELAY, 1)
第14 章メッセージのフレーミング
複数のメッセージに渡って接続を再利用するフレーミングというアイデアは、馴染み深いHTTP のkeep-alive 機能と同じコンセプトだ。複数のリクエスト(フレーミングしたメッセージ)のために接続を開いたままにすると、新しい接続を開かないことでリソースを節約できる。
14.0.1 改行の使用
改行を使用することは、メッセージをフレーミングする最も簡単な方法だ。
もし、クライアントとサーバーが同じオペレーティングシステム上で動いているなら、ソケット上でIO#gets やIO#puts を使うことで、改行付きのメッセージを送信できる。
14.0.2 コンテンツ長の使用
メッセージの送信者は最初に固定幅の整数表現でメッセージのサイズを示す。そして接続を通じて、メッセージを後ろにつけてそれを送信する。メッセージの受信者は、固定幅の整数を読み取ってメッセージのサイズを取得し、続いてそのサイズのバイト数を読み取り、メッセージを取得する。
第15 章タイムアウト
タイムアウトとは、つまり忍耐のことだ。ソケットの接続を待てるのは一体どれくらいだろうか? 読み込みには? 書き込みには?
あなたが待てる範囲、それがこれらに対する答えだ。
なるほどUnixプロセスでも感じたけれど、こういった語り口が私は好きなのかもしれない。
15.1 未使用のオプション
timeout ライブラリは汎用的なタイムアウトの仕組みを提供する。しかし、オペレーティングシステムには、より高性能、より直感的なソケット固有のタイムアウトが付属している。
15.2 IO.select
require 'socket'
require 'timeout'
timeout = 5 # 秒
Socket.tcp_server_loop(4481) do |connection|
begin
# 最初の read(2) を初期化する。read(2) はソケット上で要求されるデータを必要とし、
# 読み込み可能なデータが既にあるときは select(2) を回避する。
connection.read_nonblock(4096)
rescue Errno::EAGAIN
# 接続が読み込み可能になったかどうかを監視する。
if IO.select([connection], nil, nil, timeout)
# IO.select は実際にはソケットを返すが、
# 戻り値は気にしないでもよい。nil を返さなかったという事実が
# ソケットが読み込み可能であることを意味している。
retry
else
# タイムアウトした。
raise Timeout::Error
end
end
connection.close
end
15.3 受付タイムアウト
accept 周りでタイムアウトを行う必要がある場合も、read と同じようになる。
15.4 接続タイムアウト
require 'socket'
require 'timeout'
socket = Socket.new(:INET, :STREAM)
remote_addr = Socket.pack_sockaddr_in(80, 'google.com')
timeout = 5 # 秒
begin
# google.com の 80 番ポートへのノンブロッキング接続を開始する。
socket.connect_nonblock(remote_addr)
rescue Errno::EINPROGRESS
# 接続の途中であることを示している。
# ソケットが書き込み可能になるのを監視し、接続が完了したことを通知する。
#
# ブロックを再試行すると、EISCONN を補足するブロックへと飛び、
# この begin ブロックの外側、ソケットを仕様できる場所へと処理がうつる。
if IO.select(nil, [socket], nil, timeout)
retry
else
raise Timeout::Error
end
rescue Errno::EISCONN
# 接続が完全に完了したことを示している。
end
socket.write('ohai')
socket.close
こうしたIO.select ベースのタイムアウトの仕組みは一般的に使われている。もちろん、Ruby の標準ライブラリ内でも同様だ。
第16 章DNS ルックアップ
コンストラクタの中でRuby がconnect を呼び出すことは既に見た。ここではIP アドレスではなくホスト名を渡している。つまり、ホスト名から接続できる固有のアドレスを解決するために、Ruby はDNS ルックアップを行う必要がある。
それがどうしたって? 遅いDNS サーバーはRuby のプロセス全体をブロックするかもしれない。これは、マルチスレッド環境下では残念な結果になる。
16.1 MRI とGIL
GIL はブロッキングIO を理解する。もしブロッキングIO(たとえばread によるブロックなど)を行っているスレッドがある場合は、MRI はGIL を解放して別のスレッドが実行を継続できるようになる。
MRI は、C 拡張の実行を特別厳しく扱う。ライブラリがC 拡張のAPIを使用すると、GIL はその間他のコードの実行をブロックする。
RubyはDNS ルックアップのためにC 拡張を使用している。したがって、DNSルックアップが長時間ブロックしている場合、MRI はGIL を解放しないということになる。
これって今もそうなのかな。
16.2 resolv
ありがたいことに、Ruby は標準ライブラリでこの解決策を提供している。resolv ライブラリは、DNS ルックアップの純粋なRuby 実装による代替を提供する。
resolv は DNS ルックアップの Pure な Ruby 実装なんですね。
第17 章SSL ソケット
SSL ソケットはTCP ソケットを置き換えるものではない。しかし、簡素で安全ではない従来のソケットを、安全なSSL ソケットに「アップグレード」できる。いうなれば、TCP ソケットの上にセキュアなレイヤーを追加できるものだ。
TCP ソケットをSSL にアップグレードすることはできる。しかし、1 つのソケットでSSL と非SSL の両方の通信ができるわけではない、ということに注意してほしい。SSL を使う際は、受信側とのエンドツーエンド通信はすべてをSSL を使って行う。
require 'socket'
require 'openssl'
def main
# TCP サーバーを作成する。
server = TCPServer.new(4481)
# SSL コンテキストを作成する。
ctx = OpenSSL::SSL::SSLContext.new
ctx.cert, ctx.key = create_self_signed_cert(
1024,
[['CN', 'localhost']],
"Generated by Ruby/OpenSSL"
)
ctx.verify_mode = OpenSSL::SSL::VERIFY_PEER
# TCP サーバー上に SSL ラッパーを作成する。
ssl_server = OpenSSL::SSL::SSLServer.new(server, ctx)
# SSL ソケット上で接続に応答する。
connection = ssl_server.accept
# 他の接続と同じように扱う。
connection.write("Bah now")
connection.close
end
# このコードは webrick/ssl から拝借した。
# このメソッドは Context オブジェクトで仕様する自己署名 SSL 証明書を生成する。
def create_self_signed_cert(bits, cn, comment)
rsa = OpenSSL::PKey::RSA.new(bits){|p, n|
case p
when 0; $stderr.putc "." # BN_generate_prime
when 1; $stderr.putc "+" # BN_generate_prime
when 2; $stderr.putc "*" # searching good prime
# n = #of try
# but also data from BN_generate_prime
when 3; $stderr.putc "\n" # found good prime, n == 0 - p, n == 1 - q,
# but also data from BN_generate_prime
else; $stderr.putc "*" # BN_generate_prime
end
}
cert = OpenSSL::X509::Certificate.new
cert.version = 2
cert.serial = 1
name = OpenSSL::X509::Name.new(cn)
cert.subject = name
cert.issuer = name
cert.not_before = Time.now
cert.not_after = Time.now + (365*24*60*60)
cert.public_key = rsa.public_key
ef = OpenSSL::X509::ExtensionFactory.new(nil, cert)
ef.issuer_certificate = cert
cert.extensions = [
ef.create_extension("basicConstraints", "CA:FALSE"),
ef.create_extension("keyUsage", "keyEncipherment"),
ef.create_extension("subjectKeyIdentifier", "hash"),
ef.create_extension("extendedKeyUsage", "serverAuth"),
ef.create_extension("nsComment", comment),
]
aki = ef.create_extension("authorityKeyIdentifier",
"keyid:always,issuer:always")
cert.add_extension(aki)
cert.sign(rsa, OpenSSL::Digest::SHA1.new)
return [ cert, rsa ]
end
main
繋ごうとすると OpenSSL::SSL::SSLSocket#initialize': SSL_CTX_use_certificate: ee key too small (OpenSSL::SSL::SSLError) というエラーになるな。よくわからない。先にすすむか。

第18 章緊急データ
少し前に、TCP ソケットは順序付けられたデータストリームを提供している点を強調した。言い換えると、TCP データストリームはキューのようなものだ。
帯域外データとして参照されるTCP 緊急データは、すでにあるデータをバイパスしてでも、キューの先頭にすべてのデータをプッシュすることを許す。それによって、できるだけはやく接続のもう一端に受信させられる。
そのためのメソッドが、Socket ライブラリでまだ登場していないメソッド、Socket#send だ。
Socket#send は、(IO から継承した)Socket#write を特殊化したようなメソッドだ。実際、引数なしで呼ばれた場合には、ただのwrite のように振る舞う。
write メソッドが任意のIO オブジェクトと一緒に使えるよう一般化されているのに対し、send メソッドはソケットでだけ動くように特殊化されている。この特殊化によって、Socket#send は「フラグ」という第2 引数を受け取られる。この「フラグ」によって、緊急データのようないくつかのデータをsend に指定できる。
18.1 緊急データの送信
require 'socket'
socket = TCPSocket.new 'localhost', 4481
# 標準の方法を使っていくつかのデータを送信する
socket.write 'first'
socket.write 'second'
# いくつかの緊急データを送信する
socket.send '!', Socket::MSG_OOB
OOB は帯域外(アウト・オブ・バンド、out-of-band)を意味している。
18.2 緊急データの受信
require 'socket'
Socket.tcp_server_loop(4481) do |connection|
# 最初に緊急データを受信する。
urgent_data = connection.recv(1, Socket::SMG_OOB)
data = connection.readpartial(1024)
end
緊急データを受信するには、送信側が緊急データを送る際に使用しているものと同じフラグを指定してSocket#recv を呼び出す必要がある。
ここでいうところの Socket::SMG_OOB を送る側も受ける側も必要ということだな。
最初に「通常の」データが書き込まれているにも関わらず、そのデータの前に緊急データを受信できたことに注目してほしい。これが緊急データを使ってできることだ。
また、緊急データを明示的に受け取っていることにも注目してほしい。もしrecv を呼び出していなかったら、サーバーは緊急データに気がついてなかっただろう。言い換えると、もし緊急データを求めていなければ受信側はそれを受け取らないでいい。
送る側と受けとる側の両方が緊急データのやりとりをするつもりでなければ機能しないということか。なるほど。
18.3 制限
TCP の実装は、1 度に1 バイトだけ送信できる、という形で緊急データを限定的にサポートしている。緊急データを複数バイト送信した場合は、最後のバイトのみが緊急データとみなされる。
へぇ〜なんかすごい。世の中ではどういうときに使われているんだろう。
18.4 緊急データとIO.select
もしそれらのソケットのいずれかが緊急データを受信した場合、それらはIO.select から返された第3 引数の要素に含まれることを意味する。
やみくもにrecv を呼び出さなくても、緊急データ用のソケットを監視できるという点で、これはとても素晴らしい。けれど、私の経験上ではIO.select は緊急データを処理したあとでも、その緊急データがあると言い続けてくるんだ!「通常の」TCP データストリームの一部が処理されるまで、だいたいの場合ローカルのrecv バッファが空になるまでそれは継続する。
この注意点と1 バイト制約を考えると、緊急データは滅多には使用されないTCP の機能だ。
そうなのか〜やはり使いどころが難しい。
18.5 SO_OOBINLINE オプション
緊急データを扱うもう1 つの方法は、通常のデータストリームの中でそれに注目するというシンプルな方法だ。帯域内でも帯域外データの受信を可能にするには、SO_OOBINLINE というオプションを使用する。
require 'socket'
Socket.tcp_server_loop(4481) do |connection|
# 「通常の」データ中で緊急データを受信する。
connection.setsockopt :SOCKET, :OOBINLINE, true
# 緊急データを検出すると読み込みを止めることに
# 気をつけること。
connection.readpartial(1024) # => 'foo'
connection.readpartial(1024) # => '!'
end
このオプションを有効にすると、緊急データはもはや緊急データとしては扱われない。片方が書き込みを行ったのと同じ順序でキューから読み取られる。
このオプションは、送信側のソケットではなく受信側のソケットにだけ効果がある。
普通の読み込みの中に混ぜ込むのは、処理を分けなくてよいので楽だけれども、メッセージが通常のもの1バイトなのか緊急のものなのか見分けることができなくないかな?
第19 章ネットワークアーキテクチャパターン
ここまでの章では、基礎と「知る必要のあること」についてカバーしてきた。ここからは、ベストプラクティスと現実世界の例を見ていく。
構成要素についての知識は得たけれど、ネットワークアプリケーションの一般的な構築方法についてはまだ触れていない。並行処理はどう処理すべきだろうか? エラー処理は? 遅いクライアントに対処する最善の方法は何だろうか?リソースをもっとも効率的に使うにはどうしたらよいだろうか?
ここからの章は、これらの質問に回答していくためにある。まず6 つのネットワークアーキテクチャパターンを説明し、サンプルプロジェクトにそれらを適用していく。
19.1 ミューズ
本筋と関係ないだろうけど、なぜここのタイトルがミューズなのかな。🤔
原著でもそうだった https://workingwithruby.com/wwtcps/patterns/#the-muse
ChatGPT によると「創造や学びを促すきっかけ」や「新しいアイデアの触媒」というニュアンスなのかなということ。確かに文脈にはあっていそう。

FTP のサブセットを話すサーバーを書いていくことにする。
FTP は2 つのTCP ソケットを同時に使用する。1 つの「制御」ソケットが、サーバーとクライアント間でFTP コマンドとその引数を送信するために使われる。ファイル転送が行われるたびに、それとは別の新しいTCPソケットが使用される。これは、転送が進行している間でも、制御ソケットによってFTP コマンドを継続して処理できるようにする素晴らしいハックだ。
module FTP
class CommandHandler
CRLF = "\r\n"
attr_reader :connection
def initialize(connection)
@connection = connection
end
def pwd
@pwd || Dir.pwd
end
def handle(data)
cmd = data[0..3].strip.upcase
options = data[4..-1].strip
case cmd
when 'USER'
# 匿名を受け付ける
"230 Logged in anonymously"
when 'SYST'
# このシステムが何と言う名前か?
"215 UNIX Working With FTP"
when 'CWD'
if File.directory?(options)
@pwd = options
"250 directory changed to #{pwd}"
else
"550 directory not found"
end
when 'PWD'
"257 \"#{pwd}\" is the current directory"
when 'PORT'
parts = options.split(',')
ip_address = parts[0..3].join('.')
port = Integer(parts[4]) * 256 + Integer(parts[5])
@data_socket = TCPSocket.new(ip_address, port)
"200 Active connection established (#{port})"
when 'RETR'
file = File.open(File.join(pwd, options), 'r')
connection.respond "125 Data transfer starting #{file.size} bytes"
bytes = IO.copy_stream(file, @data_socket)
@data_socket.close
"226 Closing data connection, sent #{bytes} bytes"
when 'LIST'
connection.respond "125 Opening data connection for file list"
result = Dir.entries(pwd).join(CRLF)
@data_socket.write(result)
@data_socket.close
"226 Closing data connection, sent #{result.size} bytes"
when 'QUIT'
"221 Ciao"
else
"502 Don't know how to respond to #{cmd}"
end
end
end
end
第20 章シリアル
20.1 説明
シリアルアーキテクチャでは、すべてのクライアント接続はシリアルに処理される。並行性を持たないため、複数のクライアントが同時に捌かれることはない。
このアーキテクチャの流れは単純だ。
- クライアントが接続する。
- クライアント/サーバーでリクエストとレスポンスをやりとりする。
- クライアントが切断する。
- 1 に戻る。
素朴な、だけれどもわかりやすい作りだ。
20.2 実装
require 'socket'
require_relative '../command_handler'
module FTP
CRLF = "\r\n"
class Serial
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def gets
@client.gets(CRLF)
end
def respond(message)
@client.write(message)
@client.write(CRLF)
end
def run
loop do
@client = @control_socket.accept
respond "220 OHAI"
handler = CommandHandler.new(self)
loop do
request = gets
if request
respond handler.handle(request)
else
@client.close
break
end
end
end
end
end
end
def run
loop do
@client = @control_socket.accept
respond "220 OHAI"
handler = CommandHandler.new(self)
これが、このサーバープログラムのメインループだ。見て分かるように、すべての処理はこのメインループの中で行われる。ループ中唯一のaccept 呼び出しが、このメソッドの最初にある。
最後に行っているのは、この接続用のCommandHandler の初期化だ。CommandHandler は接続ごとのサーバーの状態(現在の作業ディレクトリ)をカプセル化する。サーバーはこのhandler オブジェクトに受信したリクエストを渡し、適切なレスポンスを受け取る。
この部分が、このパターンでの並行性の障壁となる。ここを処理している間、サーバーは他の接続に応答しない。そのために、このパターンは並行性を持つことができない。
20.3 考察
シリアルアーキテクチャが提供する最大の利点は、「シンプルさ」だ。状態のロックも共有もない。接続が混線するようなこともない。リソースの使用に関しても同様だ。1 つのインスタンスが1 つの接続を処理することは、たくさんのインスタンスやたくさんの接続ほどにはリソースを消費しない。
明らかな欠点は、並行性を持たないということだ。後から来て待たされている接続は、たとえ現在の接続がアイドル状態のときでも処理されない。リクエストの中継に時間がかかっていたり、リクエストの送信中に一時停止している場合でも、接続が閉じられるまでサーバーは処理をブロックする。
第21 章 コネクション毎のプロセス
21.1 説明
接続を受け付ける部分とソケットからデータを読み込む部分は変わらない。
変更するのは、接続を受け付けた後だ。サーバーは受け付けた新しい接続を処理するために、子プロセスをfork する。子プロセスは接続を処理し、そして終了する。
fork の効果は、2 つのプロセスを完全なコピーとしてしまう点だ。新しく生成されたプロセスは子とみなされ、元のプロセスは親とされる。fork が終わると、必要に応じて別々の道を行ける2 つのプロセスが手に入る。
これはとてつもなく便利だ。たとえば、接続をaccept した後でプロセスをfork すると、子プロセスは自動的にクライアント接続のコピーを手にすることになる。したがって、余計なセットアップやデータの共有、ロックなどをせずに並列処理を開始できる。
それでは、処理の流れを明らかにしよう。
- 接続がサーバーにやってくる。
- サーバーの主プロセスが接続を受け付ける。
- サーバーの主プロセスは新しい子プロセスをfork する。子プロセスはサーバープロセスの完全なコピーを持つ。
- 子プロセスは接続に対する処理を継続し、それと平行して、サーバーの主プロセスはステップ1 に戻る。
どの時点でも、常に1 つの親プロセスが接続に受け付けるために待機している。また、複数の子プロセスによって、それぞれの接続が処理される。
accept を続ける親プロセスと、accept した後の処理を担当する子プロセスというわかれ方をするのだな。
require 'socket'
require_relative '../command_handler'
module FTP
CRLF = "\r\n"
class ProcessPerConnection
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def gets
@client.gets(CRLF)
end
def respond(message)
@client.write(message)
@client.write(CRLF)
end
def run
loop do
@client = @control_socket.accept
pid = fork do
respond "220 OHAI"
handler = CommandHandler.new(self)
loop do
request = gets
if request
respond handler.handle(request)
else
@client.close
break
end
end
end
Process.detach(pid)
end
end
end
end
server = FTP::ProcessPerConnection.new(4481)
server.run
@client = @control_socket.accept
pid = fork do
respond "220 OHAI"
handler = CommandHandler.new(self)
ほとんどは元のコードのままだ。主な違いは、ループ中にfork の呼び出しが加わっていることだ。
それぞれの接続が独立した個別のプロセスに処理されることを意味する。親プロセスはブロック内のコードは実行せずに処理を継続する。
親プロセスが行うのは fork メソッド呼びだしまでで、fork メソッドのブロックの中身は子プロセスが実行する分ね。fork 慣れしていないから気をつけてみないと混乱する。スレッドと同じ考えかただし、スレッドのときには私は混乱しにくいから、ふしぎだ。
最後にProcess.detach を呼び出していることに気が付いただろうか。プロセスが終了したあと、親からその終了ステータスを尋ねられるまでは、そのプロセスは完全に掃除されない。前述のコードでは、親は子プロセスの終了ステータスを特に気にしていない。そのため、はやい段階で親プロセスから子プロセスをデタッチすることで、プロセスが終了した際に完全にリソースが掃除されることを保証している
なるほど、行儀がいい ✨
このへんは、なるほどUnixプロセスにも出てきた。あ、脚注にも書いてある。
21.3 考察
まずはシンプルだということ。シリアル実装のはじめにほんの少しコードを追加するだけで、複数のクライアントを並行的に処理できる。
2 つ目の利点は、並行処理を行う際のハードルが低いことだ。fork が子プロセスにすべてのコピーを提供することは前述した。見た目も複雑でなく、競合状態やロックもないし、コードの分離もちょっとしたものだ。
このパターンの明らかな欠点は、fork にとっては嬉しいことだけれど、生成可能な子プロセスの数に上限がないことだ。相手が少数のクライアントなら、これは問題ないかもしれない。しかし、数千数百のプロセスを生成することになったら、システムはすぐにダウンしてしまうだろう。この懸念は、後の章で述べる「prefork」パターンを採用することで解決できる。
- 十分なシンプルさを持ちながら、並行性を確保できている
- 上限を用意していないため、システムに最大どのくらいの負荷がかかるかを事前に制御することができない
どちらも納得。
21.4 実例
• shotgun
• inetd
第22 章コネクション毎のスレッド
22.1 説明
このパターンは、前の章の「コネクション毎のプロセス」パターンにとても良く似ている。違い? プロセスを生成する代わりに、スレッドを生成するんだ。
「スレッド vs プロセス」のカラムも含めて、並行処理をやりたいなとなったときに、どちらかが全て優れているということはないので、サービスの特性に応じて選んでねということなんだろうな。
22.2 実装
require 'socket'
require 'thread'
require_relative '../command_handler'
module FTP
Connection = Struct.new(:client) do
CRLF = "\r\n"
def gets
client.gets(CRLF)
end
def respond(message)
client.write(message)
client.write(CRLF)
end
def close
client.close
end
end
class ThreadPerConnection
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def run
Thread.abort_on_exception = true
loop do
conn = Connection.new(@control_socket.accept)
Thread.new do
conn.respond "220 OHAI"
handler = FTP::CommandHandler.new(self)
loop do
request = conn.gets
if request
conn.respond handler.handle(request)
else
@client.close
break
end
end
end
end
end
end
end
server = FTP::ThreadPerConnection.new(4481)
server.run
def run
Thread.abort_on_exception = true
loop do
conn = Connection.new(@control_socket.accept)
Thread.new do
conn.respond "220 OHAI"
handler = FTP::CommandHandler.new(self)
この箇所には、重要な違いが2 つある。1 つ目の違いは、前の例でプロセスを生成していたところで、スレッドを生成していること。2 つ目の違いは、accept から返ったクライアントソケットを、Connection.new の引数に渡していることだ。これによって、スレッドは専用のConnection インスタンスを手に入れられる。
スレッドを使う際に、この処理はとても重要だ。単純にインスタンス変数にクライアントソケットを割り当ててしまうと、それはすべてのスレッド間で共有されてしまうことになる。
このことは、プロセスを使ったプログラミングとはまったく異なっている。プロセスでは、それぞれのプロセスがメモリ内容のコピーを持っている。
経験上、スレッドを使ってソケットプログラミングを行う際は、従うべき簡単なルールがある。それは、各スレッドはそれぞれの接続オブジェクトを持つようにするということだ。そして、頭痛の種はそこに閉じ
込めておくんだ。
はい。今回で言うところの Connection でまなかうということね。
22.3 考察
このパターンは、これまでのパターンと同じ利点を多く共有している。ほんの少しコードの変更が必要となり、理解しておかなければならないことが多少増えているだけだ。
このパターンが「コネクション毎のプロセス」に勝っている点の1 つは、スレッドがリソース的に軽量だということだ
このパターンは、プロセスを使った場合よりもたくさんのクライアントを並列で処理できる可能性がある。
けど、ちょっと待って。そこにはMRI のGIL が立ちふさがることを忘れないようにしよう。
現時点ではプロセス生成とスレッド生成でプログラムにそれほど差は出ない。
プロセスとスレッドの特徴でどちらを使いたいか定めていくということかな。
スレッド数はシステムをダウンさせるまで増やせる。
これは最大スレッド数を制限することで解決できる。詳しくは第24 章「スレッドプール」で触れることにする。
22.4 実例
• WEBrick
• Mongrel
第23 章prefork
23.1 説明
このパターンもまた、並列処理の手段としてプロセスを扱う。けれど、接続の到着ごとには子プロセスを生成しない。サーバーを起動した際、まだ接続が到着する前の段階で、プロセスの束をfork する。
- メインのサーバープロセスは接続を待機するソケットを作成する。
- メインのサーバープロセスは子プロセスの群れをfork する。
- それぞれの子プロセスは、共有しているソケット上の接続を受け付け、個々にそれらを処理する。
- メインのサーバープロセスは子プロセスを監視する。
重要なコンセプトは、メインのサーバープロセスは接続を待機するソケットを開くが受け付けはしない、ということだ。
なるほど。 第21 章 コネクション毎のプロセスのコードは
def run
loop do
@client = @control_socket.accept
pid = fork do
respond "220 OHAI"
handler = CommandHandler.new(self)
となっていて、親プロセスが accept していたけれど、今回は子プロセスで accept するんだな。
このパターンの優れている点は、子プロセス間で接続の同期やバランスなどを考慮しなくて良いということだ。そうしたことはカーネルがうまくやってくれる。複数のプロセスが同じソケットのコピーを使って接続を受け付けようとすると、カーネルは負荷を分散し、その中の1 つのコピーだけが特定の接続に応答することを保証してくれる。
カーネルが同期や振り分けやってくれるからコードには表れてこず簡潔な表記となる。便利〜
(ただしカーネルがそういうことやってくれるという知識は書き手と読み手に必要になる)
require 'socket'
require_relative '../command_handler'
module FTP
class Preforking
CRLF = "\r\n"
CONCURRENCY = 4
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def gets
@client.gets(CRLF)
end
def respond(message)
@client.write(message)
@client.write(CRLF)
end
def run
child_pids = []
CONCURRENCY.times do
child_pids << spawn_child
end
trap(:INT) {
child_pids.each do |cpid|
begin
Process.kill(:INT, cpid)
rescue Errono::ESRCH
end
end
exit
}
loop do
pid = Process.wait
$stderr.puts "Process #{pid} quit unexpectedly"
child_pids.delete(pid)
child_pids << spawn_child
end
end
def spawn_child
fork do
loop do
@client = @control_socket.accept
respond "220 OHAI"
handler = CommandHandler.new(self)
loop do
request = gets
if request
respond handler.handle(request)
else
@client.close
break
end
end
end
end
end
end
end
server = FTP::Preforking.new(4481)
server.run
INT シグナルは、たとえばCtrl-C キーを入力したときなどにプロセスが受信するシグナルだ。ここでは、受け取ったINT シグナルを単に子プロセスに転送している。子プロセスが親プロセスから独立して存在していると、たとえ親プロセスが死んだとしても勝手に生き続けてしまう。そのため、親プロセスは自分が終了する際に、自分の子プロセスもしっかりクリーンアップする必要がある。
シグナルを処理した後、親プロセスはProcess.wait を持つループへと入る。これによって、親プロセスはいずれかの子プロセスが終了するまでブロックされる。Process.wait は終了した子プロセスのpid を返す。通常は子プロセスは終了しないように実装してあるので、これは異常終了したと判断できる。そのため、STDERR にメッセージを出力し、終了した子プロセスに代わる新しい子プロセスを生成する。
いくつかのprefork サーバー、とりわけUnicorn *1 は、子プロセスをより積極的に監視する役割を親プロセスに与えている。たとえば、リクエストの処理に長い時間かかっているかどうかを監視し、この場合は強制的にそのプロセスを終了して代わりの子プロセスを生成する。
23.3 考察
「コネクション毎のプロセス」アーキテクチャと比べて、「prefork」は接続毎にfork のコストを払う必要はない。
事前にすべてのプロセスを生成している。そのため、プロセスを生成しすぎるという問題を防げる。
「コネクション毎のスレッド」に勝っている点は、完全な分離だ。
それぞれの子プロセスは、Ruby インタプリタも含めてすべてのコピーを独自に持っている。これによって、あるプロセスの障害が他のプロセスに影響を与えることはない。
「prefork」の欠点は、多くのプロセスをfork することで、サーバーがより多くのメモリを消費するという点だ。
このコードは実にシンプルでもある。コンセプトをいくらかは理解する必要があるが、総合的に
見てシンプルだし、実行時にこんがらがるような心配もほとんどない。
総合的にみるとメモリに懸念がないなら prefork かなりよいという主張かな。
私にもそう見える。
23.4 実例
• Unicorn
第24 章スレッドプール
24.1 概要
このパターンでは、「prefork」パターンのスレッド版だ。サーバーの起動時にスレッドを一定の数だけ生成して、それぞれの独立したスレッドが接続を処理する。
require 'socket'
require 'thread'
require_relative '../command_handler'
module FTP
Connection = Struct.new(:client) do
CRLF = "\r\n"
def gets
client.gets(CRLF)
end
def respond(message)
client.write(message)
client.write(CRLF)
end
def close
client.close
end
end
class ThreadPool
CONCURRENCY = 25
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def run
Thread.abort_on_exception = true
threads = ThreadGroup.new
CONCURRENCY.times do
threads.add spawn_thread
end
sleep
end
def spawn_thread
Thread.new do
loop do
conn = Connection.new(@control_socket.accept)
conn.respond "220 OHAI"
handler = CommandHandler.new(conn)
loop do
request = conn.gets
if request
conn.respond handler.handle(requ)
else
conn.close
break
end
end
end
end
end
end
end
server = FTP::ThreadPool.new(4481)
server.run
ふたたび、2 つのメソッドが登場している。1 つはスレッドを生成するメソッド、もう1 つは生成したスレッドの振る舞いをカプセル化したメソッドだ。
run メソッドはThreadGroup を生成し、すべてのスレッドを監視する。ThreadGroup はスレッド管理配列のようなものだ。ThreadGroup にスレッドを追加しておき、もし実行が終了したらグループから取り除く。
終了を防ぐためにsleep を呼び出している。プールが作業をしている間、メインスレッドはアイドル状態のままだ。理論的にはプールを監視することもできるが、ここでは終了しないように念のためsleep している。
24.3 考察
このパターンで考察できることの多くは、これまでのものと同様だ。
スレッドかプロセスかのトレードオフ以外でいうと、このパターンは接続を処理するたびにスレッドを生成する必要がなく、変なロックや競合状態もないが、それでも並列処理を提供する。
24.4 実例
• Puma
第25 章イベント(Reactor)
25.1 概要
これまで見てきたパターンは、実際にはすべて「シリアル」パターンのバリエーションだった。
ここで紹介するパターンは、他のパターンとはまったく異なるアプローチを取る。
25.2 実装
このパターンは、シングルスレッド、シングルプロセスだ。にもかかわらず、これまで紹介してきたパターンと、少なくとも同程度の並行性を担保する。
このパターンは(Reactor と名付けられた)接続多重化装置を中心に置く。接続のライフサイクルの各段階は個々のイベントへと分解され、各イベントは交互配置されて任意の順で処理される。接続の各段階はaccept、read、write、close といった単純なIO 操作となる。
接続多重化装置はイベントを監視し、イベントに関連付けられたコードを実行する。
ワークフローを見ていこう。
- サーバーは接続を待機するソケットを監視する。
- 新しい接続がやってくると、サーバーは監視するソケットのリストにその接続を追加する。
- 接続を待機するソケットと同様に、サーバーはアクティブな接続を監視する。
- アクティブな接続が読み込み可能だという通知を受けると、サーバーは接続からデータの固まりを読み込み、関連するコールバックを呼び出す。
- アクティブな接続がまだ読み込み可能だという通知を受けると、サーバーは再び接続からデータの固まりを読み込み、関連するコールバックを呼び出す。
- サーバーは別の接続を受信すると、監視するソケットのリストにその接続を追加する。
- サーバーは最初の接続が書き込み可能だという通知を受けると、その接続にレスポンスを書き込む。
注目してほしいのは、これらすべてがシングルスレッドで行われるということだ。最初の接続が読み書きの途中であったとしても、サーバーは新しい接続をaccept できる。
require 'socket'
require_relative '../command_handler'
module FTP
class Evented
CHUNK_SIZE = 1024 * 16
class Connection
CRLF = "\r\n"
attr_reader :client
def initialize(io)
@client = io
@request, @response = "", ""
@handler = CommandHandler.new(self)
respond "220 OHAI"
on_writable
end
def on_data(data)
@request << data
if @request.end_with?(CRLF)
# リクエストが完了した
respond @handler.handle(@request)
@request = ""
end
end
def respond(message)
@response << message + CRLF
# すぐに書き込めることを書き込む。
# 残りはソケットが次に書き込み可能になったときに
# リトライする
on_writable
end
def on_writable
bytes = client.write_nonblock(@response)
@response.slice!(0, bytes)
end
def monitor_for_reading?
true
end
def monitor_for_writing?
!(@response.empty?)
end
end
def initialize(port = 21)
@control_socket = TCPServer.new(port)
trap(:INT) { exit }
end
def run
@handles = {}
loop do
to_read = @handles.values.select(&:monitor_for_reading?).map(&:client)
to_write = @handles.values.select(&:monitor_for_writing?).map(&:client)
readables, writables = IO.select(to_read + [@control_socket], to_write)
readables.each do |socket|
if socket == @control_socket
io = @control_socket.accept
connection = Connection.new(io)
@handles[io.fileno] = connection
else
connection = @handles[socket.fileno]
begin
data = socket.read_nonblock(CHUNK_SIZE)
connection.on_data(data)
rescue Errno::EAGAIN
rescue EOFError
@handles.delete(socket.fileno)
end
end
end
writables.each do |socket|
connection = @handles[socket.fileno]
connection.on_writable
end
end
end
end
end
server = FTP::Evented.new(4481)
server.run
class Connection
スレッドを基盤にしたパターンでは、Connection クラスはスレッドと状態を分離するためのものだった。この例ではスレッドは使っていない。では、Connection クラスが必要な理由は何だろう?
プロセスを基盤にしたパターンはすべて、接続を互いに独立させるためにプロセスを使用していた。プロセスをどう使うかに関わらず、各接続は独立した1 つのプロセスによって処理されていた。つまり、接続はプロセスとして表現されていた。
「イベント」パターンはシングルスレッドではあるけれど、複数の接続を並行に処理する。そのため、クライアントからの各接続はお互いの状態に踏み入らない、独自のオブジェクトを使った表現を必要とする。
class Connection
CRLF = "\r\n"
attr_reader :client
def initialize(io)
@client = io
@request, @response = "", ""
@handler = CommandHandler.new(self)
respond "220 OHAI"
on_writable
end
Connection オブジェクトは、実際の処理を行うIO オブジェクトを、@client インスタンス変数に格納する。そして、attr_accessor を使って、そのインスタンス変数に外からアクセスできるようにしている。
Connection オブジェクトは、これまでと同様、CommandHandler のインスタンスを初期化時に生成している。その後、FTP の必須の慣習である「hello」レスポンスを書き込む。しかし、クライアント接続に対して直接書き込むわけではなく、response 変数に単にレスポンス内容を設定している。次節で説明するが、これはReactor がクライアントにデータ送信するためのトリガーとなる。
def on_data(data)
@request << data
if @request.end_with?(CRLF)
# リクエストが完了した
respond @handler.handle(@request)
@request = ""
end
end
def respond(message)
@response << message + CRLF
# すぐに書き込めることを書き込む。
# 残りはソケットが次に書き込み可能になったときに
# リトライする
on_writable
end
def on_writable
bytes = client.write_nonblock(@response)
@response.slice!(0, bytes)
end
def monitor_for_reading?
true
end
def monitor_for_writing?
!(@response.empty?)
end
Connection クラスのこの部分では、Reactor コアと協調するライフサイクルのメソッド群を定義している。たとえば、Reactor はクライアント接続からデータを読み込むと、そのデータを引数にon_data メソッドを呼び出す。
残りの2 つのメソッド、monitor_for_reading?とmonitor_for_writing?は、読み書きのために特定の接続の状態を監視すべきかを、Reactor が問い合わせるためのメソッドだ。
def run
@handles = {}
loop do
to_read = @handles.values.select(&:monitor_for_reading?).map(&:client)
to_write = @handles.values.select(&:monitor_for_writing?).map(&:client)
readables, writables = IO.select(to_read + [@control_socket], to_write)
ここがReactor コアのメイン処理部だ。Hash オブジェクト@handles は、{6 => #FTP::Evented::Connection:xyz123} のような構造をしていて、キーはファイルディスクリプタ番
号、値はConnection オブジェクトとなる。
次に、Reactor は間髪いれずに、そのIO オブジェクトをIO.select へと渡している。このIO.select 呼び出しは、監視しているソケットのいずれかが処理すべきイベントを受け取るまでロックする。
読み込みを監視するために、Connection オブジェクトの中に@control_socket を忍び込ませていることにも注目してほしい。これによって、新しいクライアント接続の到着を検出できる。
"Connection オブジェクトの中に@control_socket を忍び込ませている" に関心した。
同質な(to_read)な集まりに異質なもの(@control_socket)を混ぜると、後の処理で分離するコードが必要になって避けたい気分がある(実際に if socket == @control_socket で分離した処理を書いている)けれど、監視という意味ではフラットに全部見る必要があるからこういうことをしているんだと理解している。
readables.each do |socket|
if socket == @control_socket
io = @control_socket.accept
connection = Connection.new(io)
@handles[io.fileno] = connection
else
connection = @handles[socket.fileno]
begin
data = socket.read_nonblock(CHUNK_SIZE)
connection.on_data(data)
rescue Errno::EAGAIN
rescue EOFError
@handles.delete(socket.fileno)
end
end
end
writables.each do |socket|
connection = @handles[socket.fileno]
connection.on_writable
end
Reactor のこの部分は、IO.select から受け取ったイベントに適したメソッドを呼び出している。
はじめに、Reactor は「読み込み可能」とみなしたソケットを処理する。もし@control_socket が読み込み可能なら、それは新しいクライアント接続だということだ。なので、Reactor はそれをaccept して新しいConnection オブジェクトを生成し、@handles に格納する。これによって、次のループからそれを監視できる。
次は、「読み込み可能」とみなしたソケットが、通常のクライアント接続であった場合の処理だ。この場合、データを読み込み、適切なConnectionオブジェクトのon_data メソッドを呼び出す。読み込みがブロックされた場合(Errno::EAGAIN が発生する)は、特別なことはせず単にイベントを落とす。クライアントが切断された場合(EOFError が発生する)は、@handles からエントリを削除する。それによって、その接続用のオブジェクトはGC され、監視されないようになる。
最後の部分は、「書き込み可能」とみなしたソケットを、適切なConnection オブジェクトのon_writable メソッドを呼び出して処理している。
25.3 考察
このパターンは他のパターンとはまったく異なっている。そのため、他とはまったく異なった利点と欠点を持つ。
まず第一に、このパターンは数千、数万の数の同時接続を処理できるような、高い並行性を持つと評価されている。他のパターンはプロセスやスレッドに制約されているため、単純にはこれに近づくことはできない。
このパターンの主な欠点は、それによって強制されるプログラミングモデルだ。その代わり、プロセスやスレッドを扱わないことで、モデルはずっとシンプルになる。
1 つの重要なルールに従う必要がある。それは、Reactor を決してブロックしてはいけないということだ。
プログラミングモデルが他と異なる点、入出力(IO)に関して強く留意する点が受けいれられるのであれば、シンプルで性能も出る、良いパターンであるということだと理解した。
25.4 実例
• EventMachine
• Celluloid::IO
• Twisted
第26 章ハイブリッド
ネットワークパターンのパートも、この章で最後だ。ここでは具体的なパターンは取り上げない。代わりに、ここまでに説明してきた2 つ以上のパターンを使った、ハイブリッドなパターンのつくり方を取り上げる。
26.1 nginx
nginx は、C で書かれた高性能なネットワークサーバーだ。プロジェクトの公式サイトでは、1 台のサーバーで1 万の同時要求を処理できると主張している。
nginx は、その中核として「prefork」パターンを使用している。しかし、fork したそれぞれのプロセスの内側は「イベント」パターンとなっている。いくつかの理由から、これは理にかなった効果的な選択だ。
第一に、すべての生成コストはnginx が子プロセスを生成する起動時に支払われる。これによって、nginx は複数コアとサーバーリソースを最大限に活用できることが保証される。第二に、「イベント」パターンは何も生成せず、スレッドも使用しないという点で注目に値する。
prefork + イベント
26.2 Puma
Puma は「並行処理のために作られたRuby Web サーバー」を提供する。
Puma は高い並行性を実現するためにスレッドプールを使用する。
新しいリクエスト用に接続を監視し、それらをうまく処理しなくてはいけない。Puma はこれを「イベント(Reactor)」パターンを用いて行う。
スレッドプール + イベント
26.3 EventMachine
EventMachine は中核として「イベント」パターンを実装している。
EventMachine の中核は、多重接続のネットワークイベントを処理できる、シングルスレッドのイベントループになっている。
EventMachine はまた、実行時間の長い操作や他を遅くするようなブロックする操作を猶予するためのスレッドプールも提供している。
イベント + スレッドプール
第27 章おわりに
これでソケットプログラミングについての基礎はわかったはずだ。Rubyやこれから出会うであろうプログラミング環境において、ここで得たことを活用できるはずだ。本書で示したのは、これからもずっと使い続けられる有効な知識だ。
おもしろかった。ありがとう、ありがとう!