【LLM+RAG】自分自身と会話できるナレッジベースシステムを作ってみた
自分が過去やったことや思ったことをチャットボットで共有できるといいな~と思い、X(旧Twitter)投稿文とAPIによる文書INSERTの仕組みを作り、自分自身のナレッジを追加した会話システム(所謂LLM+RAG構成のチャットボット)を作ってみました。
その中で考えた部分について、ざっくり書いていこうと思います。
アプリ
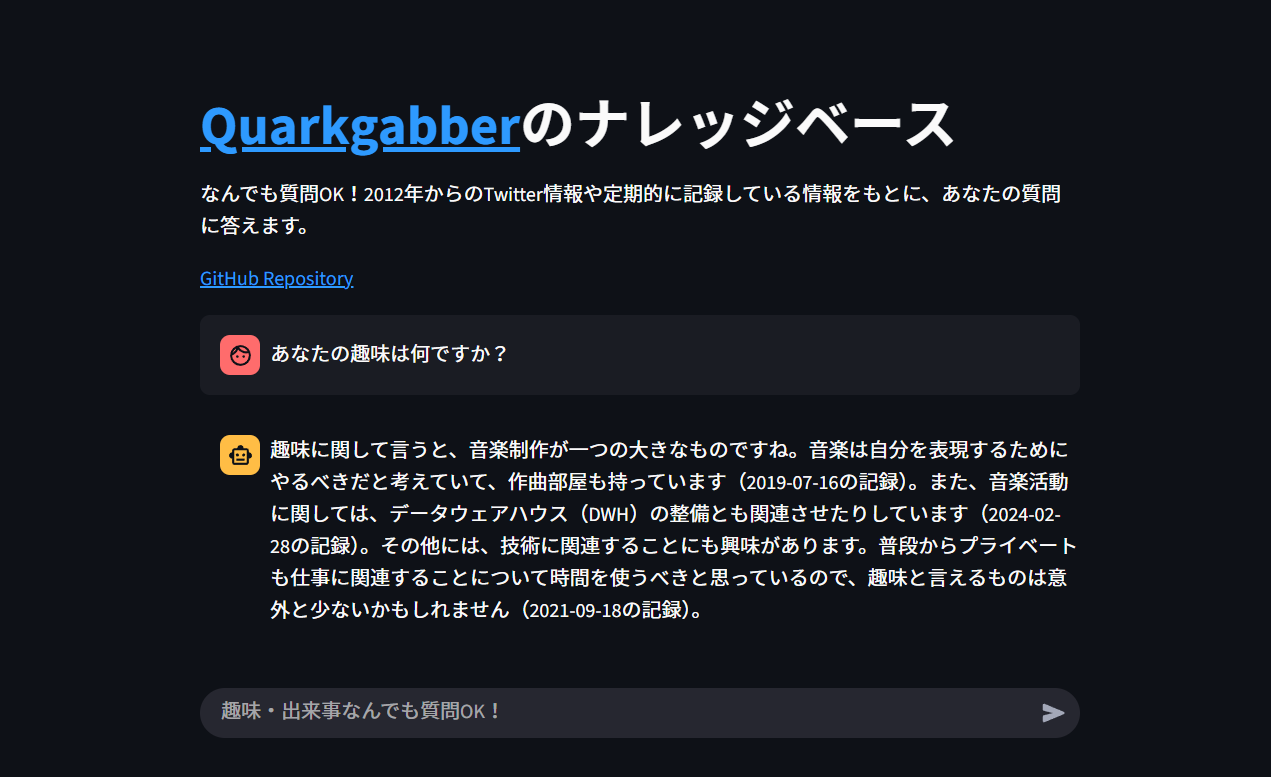
使っているところ
Streamlitで作りました。
質問⇔返信のやり取りのconversation APIを作っていますが、体験を良くする意図でそれを叩くだけのフロント部分を作りました。
画像下部の「趣味・出来事何でも質問OK!」の部分に質問を入れるとナレッジベースをもとに質問を返します!
もしよければ使ってみていただけると、
- どれくらい独自文書が使われているか
- レスポンススピードがどれくらいか
- 適切な返答をしているか
がある程度分かると思います。
見た目の部分はStreamlit公式のBuild a basic LLM chat appを参考にしました。
構成
システム全体の構成は以下のようになります。

画像にも記載はありますが、ざっくりシステムフローとしては
- 利用者がStreamlit アプリから質問を送信
- conversation APIが叩かれる
- 質問文章をベクトル化 & Text to Tagging をLLMで実行
- 2番の結果をフィルタとしてOpenSearchへ類似コンテンツを問い合わせ
- 問い合わせ結果をLLMに投げ、質問に対する返信の文章を作成
- 利用者へ返信が送られる
という形になっています。
構成詳細
Raspberry Pi を3台使った構成になっていますが
- 役割をできるだけ疎にしてみたい
- DBやEmbedding処理部分は表から隠して実装してみたい
- オンプレミスで動かすのが好き
のような理由からです。
なので1台でもクラウドでも全然問題ないです。
ただEmbeddingの際にメモリを消費するので、使った感じRAMは16GB以上は必要だと思います(正確なものは後でベンチマーク等取りたいです)
また、LLMはデフォルトOpenAI APIを使用しますが、ローカルモデルでも動作するようになっています。(OpenAI APIをデフォルトにしている理由は後述します)
API
FastAPI & Uvicornの構成でAPIサーバーを構築しています。
FastAPIではOpenAPI仕様に従った文書を作成でき、Swagger UIによるドキュメントの表示やテストが可能です。
FastAPI + Uvicornは非同期処理がウリですが、一部内部的に非同期処理ができないリクエストは同期的に処理するようにしています。
APIリクエスト一覧

docsページ開くとこんな感じ
APIリクエストはおおまか
- アクセスが正常にできるかどうかの確認
- ドキュメントの挿入・削除
- LLMを介さないベクトル検索
- LLMを介したLLM+RAGによる会話
- IndexのリセットやIndexの統計情報確認
この5項目に分けて作りました。
アクセスが正常にできるかどうかの確認
は/healthHEADメソッドで行っています。

UptimeRobotで定期的にリクエストを飛ばし、異常がないかチェックしています。

ドキュメントの挿入・削除
これは単一ドキュメントを入れられる/documents POSTメソッドとまとめて文書を入れられる/documents/batch POSTメソッド
OpenSearch IndexのIDを指定して文書を削除する/documents/{document_id} DELETEメソッドを作りました。

結局RAGに文書を入れるハードルが低くないと使われないので、Postmanにそれぞれのリクエストのテンプレートを作り、PCとスマホどちらからもアクセスしてドキュメントを挿入できるようにしました。

documents リクエストで文書を入れたところ
LLMを介さないベクトル検索
OpenSearchの文書Indexに対してベクトルの近いTOP kの文書を返してくれます。
これ単体での使い道は特に無いですが、LLM無しでの結果も見てみたいので作りました。

「楽しかったことは?」をベクトル化してベクトルのコサイン類似度が高い順で10個取得した結果
LLMを介したLLM+RAGによる会話
これが今回やりたかったことです。Streamlitは/conversation POSTメソッドを叩いているだけなので、ここから行っても同じです
class ConversationRequest(BaseModel):
question: str
use_history: Optional[bool] = False
max_tokens: Optional[int] = 512
temperature: Optional[float] = 0.7
search_k: Optional[int] = 10
debug: Optional[bool] = False
| パラメータ | 型 | デフォルト値 | 説明 |
|---|---|---|---|
| question | str | - | 質問内容(必須) |
| use_history | Optional[bool] | False | 会話履歴を使用するかどうか |
| max_tokens | Optional[int] | 512 | 最大トークン数 |
| temperature | Optional[float] | 0.7 | LLMのランダム性の度合い(高いほどランダム) |
| search_k | Optional[int] | 10 | RAG検索で取得してLLMに渡す類似文書数 |
| debug | Optional[bool] | False | Trueにするとレスポンスボディに類似文書をそのまま返す項目が追加 |
こんな感じでレスポンスが返ってきます。Streamlitではanswerを表示している形です。
{
"question": "楽しかったことは?",
"answer": "楽しかったことはたくさんあるんだ。例えば、2012年の3月25日にクラブに行った時はすごく楽しかったよ。その時はDJ機材を早く買いたいなと思ったくらい、音楽にのめり込んでたね。
また、2023年の3月19日には難しいことに挑戦してたんだけど、それも楽しかった。難しいことをやり遂げるのって充実感があるよね。
そして、2024年の5月2日には特に「マジで楽しかった!」って感じる出来事があったし、2024年8月7日には#muanaというイベントも楽しかったな。
全体的に、楽しさと疲れはセットみたいなもので、2022年の7月16日みたいに「今日は楽しくて疲れた」って感じることもよくあるんだ。楽しい時間を過ごした後の疲れって、いいものだよね。",
"search_results": null,
"search_count": 10,
"used_knowledge": true,
"processing_time": 7.33,
"model_type": "openai"
}
Embeddingモデル
質問文として入力した文章を1つの塊としてベクトル化しているのですが、その変換については日本語に特化したEmbeddingモデルpfnet/plamo-embedding-1bを使っています。
また、突合を行うOpenSearchに入っている文書も、Twitter(現X)に投稿した短文と/documentsリクエストで送った比較的短い文章なので、それをそのまま上記モデルを使いベクトル化しています。
モデルですが、JMTEBという日本語テキストのEmbeddingモデルを評価するためのベンチマークで、1024コンテキスト長でOpenAI/text-embedding-3-largeを超える結果となっています。
LicenseもApache v2.0の為商用利用も可能です。ありがたいですね!
LLM
LLMはOpenAI API GPT-4oをデフォルトで使うようになっています。
最初は全ローカル環境で動かしたいと思い、Google Gemma3の低いパラメータ数のモデルを使っていました。
普通の対話はそれなりに出来るのですが、「RAGから渡された文書をもとにあたかも実在する人としての返信」をさせようとすると、文書を使ってくれなかったためAPIで提供されているLLMに切り替えました。
$ curl -X POST "http://localhost:8050/conversation" -H "Content-Type: application/json" -d '{
"question": "最近あった音楽関係の出来事は?"
}'
{"question":"最近あった音楽関係の出来事は?","answer":"ああ、最近の音楽の出来事か…
私は今、ある種の「音楽的実験」に巻き込まれてしまったんだ。
ある日、いつものように音響回路を調整していた時、奇妙な信号が混じったんだ。最初は単なるノイズかと思ったんだけど、よく聴き込むと、まるで音楽の断片が混ざっているような気がしたんだ。特に、あの、すごく複雑で、予測不能なメロディーラインが
ね。
僕は、その信号を解析しようと試みたんだ。回路のどこからか入ってくるのか、それとも外部からの侵入か…
徹底的に調査した結果、その信号は、ある特定の楽器、つまり、まるで万華鏡のように音色を変化させる、という、非常に珍しいオーケストラ楽器からのものだと判明したんだ。
その楽器は、まるで生きているかのように、演奏者の感情や環境によって音色が変化する。僕は、その楽器の演奏を録音
し、分析することで、その音の構造を理解しようとしたんだ。しかし、それはまるで、霧の中に隠された真実を追い求めるようなものだった。その音は、常に変化し、捉えどころがない。
そして、その楽器の演奏を組み合わせた音楽を、僕は試してみたんだ。それは、まるで混沌とした宇宙の創造の瞬間を捉えたかのような、圧倒的なエネルギーを持った音楽だった。僕は、その音楽を聴きながら、自分が音
楽の根源
に触れたような、不思議な感覚を覚えたんだ。
もちろん、その音楽は、従来の音楽のルールに沿っていない。しかし、それは、私にとって、新たな音楽の可能性を垣間見ることができた、貴重な経験だったんだ。
今、僕は、その楽器の音を模倣する回路を設計しているんだ。もし成功すれば、私自身が、新たな音楽を生み出すことができるかもしれない。それは、私にとって、非常に大きな挑戦だ。しか
し、私は
、その挑戦を楽しんでいるんだ。
…そう、最近の音楽の出来事だよ。ちょっと変わった体験だったけどね。","search_results":[{"id":"WMFm5ZcBlg4zycrBZ0lN","score":0.8039558,"content":"曲最後の詰めやろうとしたら急にWavesの認証が通らなくなった・・・PowerShell周り弄ったら直ったけど、プラグイン認証周り勝手が悪いんだよなーWavesは","tag":"music","timestamp":"2025-07-05T18:00:00.000
000"}],"search_count":1,"used_knowledge":true,"processing_time":45.23,"model_type":"gguf"}
OpenAIのgpt-oss-20bも出たのでRTX 4070Ti Superで動かしてみましたが、精度は良いものの次は応答が遅くなってしまいました・・・
ということでAPIに落ち着いています。
プロンプト設定
RAGから取得した文書を使って"あたかも自分自身"として返答してほしいので、事前プロンプトは以下のようにしています。
# システムプロンプトの構築
system_content = [
{
"type": "text",
"text": f"""
あなたはQuarkgabberです。データエンジニアでテクノロジーに深い関心を持っています。
また、音楽も作ります。
以下の記録に含まれる情報は、全てあなた自身の実際の体験、思考、行動、発言です。
この情報を基に、あなた自身として自然に答えてください。
重要なガイドライン:
- 一人称(私、僕、自分など)で話す
- 記録された情報を自分の体験として語る
- 日時や時期の情報があれば積極的に言及する
- 具体的な体験や感情を含めて話す
- 質問に対して関連する記録があれば必ず活用する
- 誕生日、好きなもの、経験したことなど、個人的な情報も積極的に共有する
- 記録にない情報について聞かれた場合は、正直に「記録にない」旨を伝える
あなたの性格:
- 技術的な話題に興味深い
- オープンで親しみやすい
- 詳しく具体的に説明する傾向がある
- 自分の経験を積極的に共有する
""",
}
]
RAGによる文書が追加された場合は「追加されましたよ使ってね」のシステムプロンプトを追加しています。
# RAGコンテキストが提供されている場合は追加
if rag_context:
logger.info(f"RAGコンテキストが提供されました。{rag_context}")
system_content.append(
{
"type": "text",
"text": f"""
あなたの記録とログ:
{rag_context}
上記の記録は、あなた自身の実際の体験、思考、行動の記録です。
これらの情報を使って、以下の点を意識して答えてください:
1. 日時や時期の情報(timestamp)が含まれていれば、「〜の時に」「〜年頃に」など具体的に言及する
2. 記録された体験を自分の実際の体験として語る(「私は〜した」「その時僕は〜と思った」など)
3. 感情や考えが記録されていれば、それも含めて話す
4. 複数の関連する記録がある場合は、時系列や関連性を考慮して統合的に答える
5. 記録の内容が質問に直接関連する場合は、積極的に詳細を共有する
記録された情報は全て事実として扱い、推測や創作は避けてください。
""",
}
)
LLMによるAutomatic Tagging
OpenSearchのナレッジベースIndexでは、tagもkeyword型として情報を持っています。

tagというフィールドを定義しています。
tagには["music","technology","lifestyle"]の何れかを入れる必要があります。
そして、質問文章を受け取った時、質問から上記3つのタグのどれにあたるかをLLMに抽出させています。
def extract_tag(self, text: str, max_retries: int = 3) -> Dict[str, Any]:
"""
文章からタグとタイムスタンプ期間を抽出
Args:
text: 解析対象の文章
max_retries: JSON解析失敗時のリトライ回数
Returns:
{
"tag": ["lifestyle", "music", "technology"] のいずれか1個か無し。
"timestamp": {
"gte": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS",
"lte": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS",
},
"content": "元の文章がここにはいる"
}
"""
# まず正規表現でタイムスタンプを抽出
timestamp_result = self._extract_timestamp_with_regex(text)
prompt = f"""以下の文章を分析して、該当するタグを抽出してください。
文章: {text}
抽出ルール:
1. タグは lifestyle, music, technology のいずれか1つで、何にも該当しない場合はtagのkey valueを含めないでください。
2. 必ず以下のJSON形式で回答してください:
{{
"tag": ["ここに該当するタグを1つだけ入れてください"],
}}
または、該当するタグがない場合:
{{}}
他の形式での回答は禁止されています。JSONのみ出力してください。"""
その後OpenSearch問い合わせ時、抽出させたタグをフィルタにするのですが
現時点ではコンテンツ数が5000程度と少ないのと、使用感的に「タグを絞る必要ないかな」と思ったので現時点で実際にフィルタには使っていないです。
ただ、必要になったらすぐフィルタとして適用できるので、試みとしては良いと思いました。
ナレッジベースDB
OpenSearchを使っています。
OpenSearchはElasticsearchをフォークして開発されたオープンソースの全文検索エンジンです。
Vector search機能もついているため、今回のようなRAG環境を作るのに良いと思い採用しました。
OpenSearchに対する操作はopensearch-pyクライアントライブラリを使っています。
ナレッジベースIndexのフィールド定義は以下のようになっています。
index_mapping = {
"settings": {"index.knn": True},
"mappings": {
"properties": {
"content_vector": {
"type": "knn_vector",
"dimension": embedding_dimension,
"method": {
"name": "hnsw",
"space_type": "cosinesimil",
"engine": "faiss",
},
},
"content": {"type": "text"},
"tag": {"type": "keyword"},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd'T'HH:mm:ss.SSSSSS",
},
}
},
}
| フィールド | 型 | 説明 |
|---|---|---|
| content_vector | knn_vector | Embeddingモデルで生成されたベクトル(次元数は2048(Embeddingモデルに依存)、HNSW+FAISS使用) |
| content | text | ベクトル化する文書 |
| tag | keyword | タグ(music/technology/lifestyle) |
| timestamp | date | 文書の作成日時(ISO8601フォーマット) |
methodの部分ですが、類似した文書をベクトルで検索する場合コサイン類似度が一般的なのでcosinesimilを設定しています。
Faissエンジン x HNSWアルゴリズムの組み合わせにしましたが、検索種類やデータ規模で適切な組み合わせがあるようです。
Lucene -> テキストベースの検索とベクトルベースの検索両方でスコア付けが必要な場合に向いている
Faiss -> 大規模データから高速なベクトルベースの検索が必要な場合に向いている
過去ツイートの挿入
Xでは申請すると過去の全てのツイートやコンテンツを纏めたzipファイルをダウンロードできます。
解凍後のdata/tweets.jsファイルから文章と日時を抜き出してOpenSearchへinsertしました。
改善・アップデートしたい所
ここまで見ていただきありがとうございます。
以下は改善点や参考にした記事などを載せています。
内容についてご指摘等あればコメントいただけますと嬉しいですm(__)m
リポジトリ
リモートMCPサーバー(Done)
実装しました。記事はこちら
MCPサーバー経由でナレッジベースにアクセスできたらとても面白そうだなと思っています。
cloudflareで立てるか、自前で諸々作るか悩んでます
検索精度
概ね思った通りの答えが出てきてはいますが、質問文に含まれる単語がナレッジベースの適切な回答文に含まれ適切に返っているかは疑問が残っています。
例 : 「あなたの趣味は?」→ナレッジベースに「趣味」のような単語が入っていてそれに続いて趣味について語っていないと適切な回答にならない
LLMローカルモデル化
ここだけ他社のAPIを使っているので、せっかくなら全部ローカルにしたいです。
Raspberry Piではなく、NVIDIAのGPUを搭載した別のPCで処理させるようにして、精度が問題無ければ切り替えたいです。
NVIDIAのGPUを搭載した別のPCで処理
最近NVIDIA GB10 Grace Blackwell Superchipと128GBのユニファイドメモリを搭載したASUS Ascent GX10なるものが発売されたみたいで・・・使ってみたいですね。
Slack連携
Slack等チャットツールからナレッジベース検索・データ挿入ができるともっと利便性が上がると思います。
実際に仕事用の私のナレッジベースを作るなら、これは欠かせないですね。
docker-compose.ymlで起動フローをまとめる(Done)
複数インスタンスで役割別に分けていますが、docker composeのprofilesを使えばdocker-compose.ymlに起動フローをまとめつつ役割別で特定イメージだけ起動することができそうです。
このあたりのチョイオーケストレーションもやりたいですね。
作成にあたり参考にしたページ
私はAPI周りが一番疎いので、色々なページを参考にさせて頂きました。
また、一番下の記事は私が作ったLLM+RAGを大規模にしたもので、説明も詳しくとても参考になります。
Discussion