【AWS Glue】ETLジョブでファイル拡張子をtsvからparquetへ変換する際の注意点
はじめに
tsvファイルを参照元としているAthenaテーブルを、parquetファイルへ変換し新たなテーブルを作るETLジョブをGlueで作成する場合の個人的な注意点について書きました。
AWS Glue Studioだと
Source : AWS Glue Data Catalog → Target: Amazon S3

な時のシチュエーションです。
主には型変換の話になります。
設定により意図しない型になったりデータが消えたりします。
事前準備
tsvファイル作成
tsvファイルは以下の内容になっています。
tinyint_column smallint_column int_column bigint_column double_column boolean_column varchar_column string_column date_column timestamp_column
0 1 2 3 0.1 true short_text hello 2021-01-01 2021-01-01 01:23:45
1 2 3 4 1.1 false medium_text world 2021-01-02 2021-01-02 12:34:56
2 3 4 5 2.2 true another_text apple 2021-01-03 2021-01-03 01:23:45
3 4 5 6 3.3 false more_text banana 2021-01-04 2021-01-04 12:34:56
4 5 6 7 4.4 true text_here cherry 2021-01-05 2021-01-05 01:23:45
5 6 7 8 5.5 false even_more dog 2021-01-06 2021-01-06 12:34:56
6 7 8 9 6.6 true text_again elephant 2021-01-07 2021-01-07 01:23:45
7 8 9 10 7.7 false more_here frog 2021-01-08 2021-01-08 12:34:56
8 9 10 11 8.8 true texting grape 2021-01-09 2021-01-09 01:23:45
9 10 11 12 9.9 false example horse 2021-01-10 2021-01-10 12:34:56
10 11 12 13 10.1 true more_text india 2021-01-11 2021-01-11 01:23:45
11 12 13 14 11.1 false last_one jackal 2021-01-12 2021-01-12 12:34:56
Amazon Athena のデータ型に記載されている型の一部をテストします。
これをs3://target-bucket/sample_tsv/log_date=YYYY-MM-DD/sample.tsvへアップロードします。
log_date=YYYY-MM-DDはAthenaでのHive形式のパーティションを想定しています。
変換前テーブル作成
AthenaでCREATE TABLEを実行します。
CREATE EXTERNAL TABLE IF NOT EXISTS `default`.`sample_tsv` (
`tinyint_column` TINYINT,
`smallint_column` SMALLINT,
`int_column` INT,
`bigint_column` BIGINT,
`double_column` DOUBLE,
`boolean_column` BOOLEAN,
`varchar_column` VARCHAR(255),
`string_column` STRING,
`date_column` DATE,
`timestamp_column` TIMESTAMP
)
PARTITIONED BY (
`log_date` DATE)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://target-bucket/sample_tsv/'
TBLPROPERTIES (
'serialization.null.format'='NULL',
'skip.header.line.count'='1'
)
パーティションをロードします。
MSCK REPAIR TABLE `sample_tsv`;
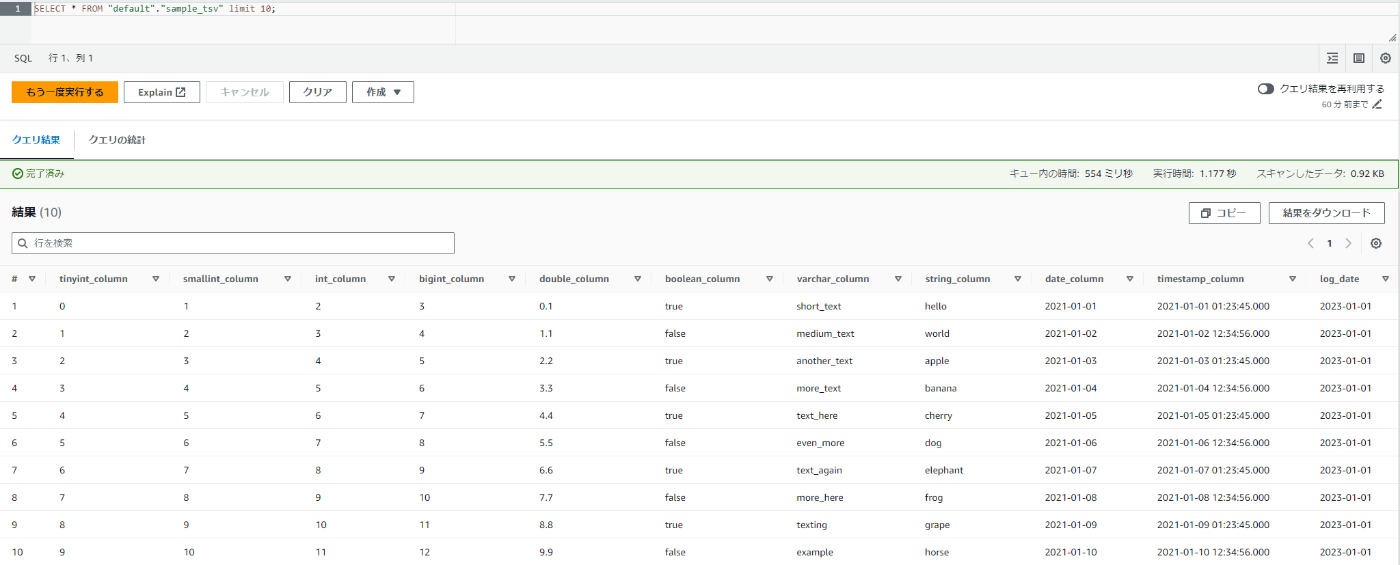
SELECT * FROM "default"."sample_tsv" limit 10;
変換前のテーブルを作ることができました。
parquetへ変換
AWS Glue Studioを使ってsample_tsvテーブルの参照元データをparquetに変換し、sample_parquetテーブルを作ります。
そのまま変換
まずはChange Schemaを用いないでそのまま変換します。(Change Schemaは下記画像の事です)
Glue Studioでは以下のような設定になります。
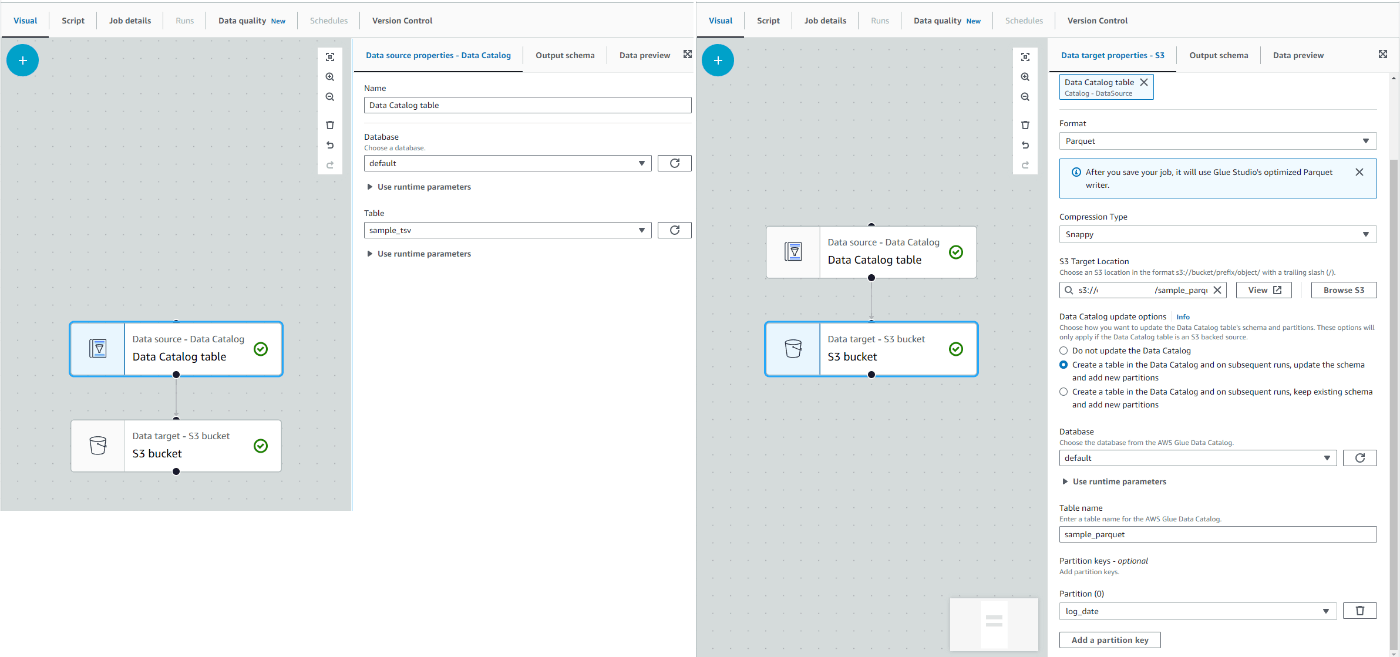
設定はdefault.sample_tsvテーブルを用いてdefault.sample_parquetテーブルを作るというシンプルな流れです。
実行してテーブルができました!

ですが、一部の型がstringになっています。
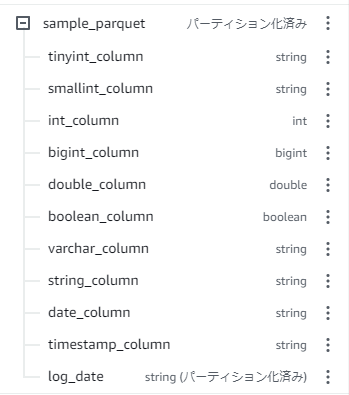
stringになってしまっている型は
- tinyint
- smallint
- varchar
- date
- timestamp
です。
ChangeSchemaを挟んで変換
一部の型が適切に変換されなかったので、Change Schemaを処理の間に挟みます。

自動でData typeの項目を埋めてくれますが、BIGINTはLONGとして入れられます。このまま実行すると型が対応していないとエラーを吐くのでBIGINTに戻します。
また、この状態で自動生成されるScriptのChange Schemaのコードを見ると
# Script generated for node Change Schema
ChangeSchema_node1694928138274 = ApplyMapping.apply(
frame=DataCatalogtable_node1,
mappings=[
("tinyint_column", "byte", "tinyint_column", "byte"),
("smallint_column", "short", "smallint_column", "short"),
("int_column", "int", "int_column", "int"),
("bigint_column", "long", "bigint_column", "bigint"),
("double_column", "double", "double_column", "double"),
("boolean_column", "boolean", "boolean_column", "boolean"),
("varchar_column", "string", "varchar_column", "varchar"),
("string_column", "string", "string_column", "string"),
("date_column", "date", "date_column", "date"),
("timestamp_column", "timestamp", "timestamp_column", "timestamp"),
("log_date", "date", "log_date", "date"),
],
transformation_ctx="ChangeSchema_node1694928138274",
)
となっています。
ソースタイプの部分はこちらから設定する必要が有るので、Edit scriptから編集します。
ソースタイプ・ターゲットタイプ共に変換前テーブル作成で実行したときのEXTERNAL CREATE TABLEの型に変更しました。
mappings=[
("tinyint_column", "tinyint", "tinyint_column", "tinyint"),
("smallint_column", "smallint", "smallint_column", "smallint"),
("int_column", "int", "int_column", "int"),
("bigint_column", "bigint", "bigint_column", "bigint"),
("double_column", "double", "double_column", "double"),
("boolean_column", "boolean", "boolean_column", "boolean"),
("varchar_column", "varchar(255)", "varchar_column", "varchar(255)"),
("string_column", "string", "string_column", "string"),
("date_column", "date", "date_column", "date"),
("timestamp_column", "timestamp", "timestamp_column", "timestamp"),
("log_date", "date", "log_date", "date"),
],
これで実行します。
型変換の部分でエラーが発生します。

正しい例
そのまま変換にてstringに変換されていた型のソースタイプを全てstringに直します。
mappings=[
("tinyint_column", "string", "tinyint_column", "tinyint"),
("smallint_column", "string", "smallint_column", "smallint"),
("int_column", "int", "int_column", "int"),
("bigint_column", "bigint", "bigint_column", "bigint"),
("double_column", "double", "double_column", "double"),
("boolean_column", "boolean", "boolean_column", "boolean"),
("varchar_column", "string", "varchar_column", "varchar(255)"),
("string_column", "string", "string_column", "string"),
("date_column", "string", "date_column", "date"),
("timestamp_column", "string", "timestamp_column", "timestamp"),
("log_date", "string", "log_date", "date"),
],
実行して成功しました!型もバッチリです。
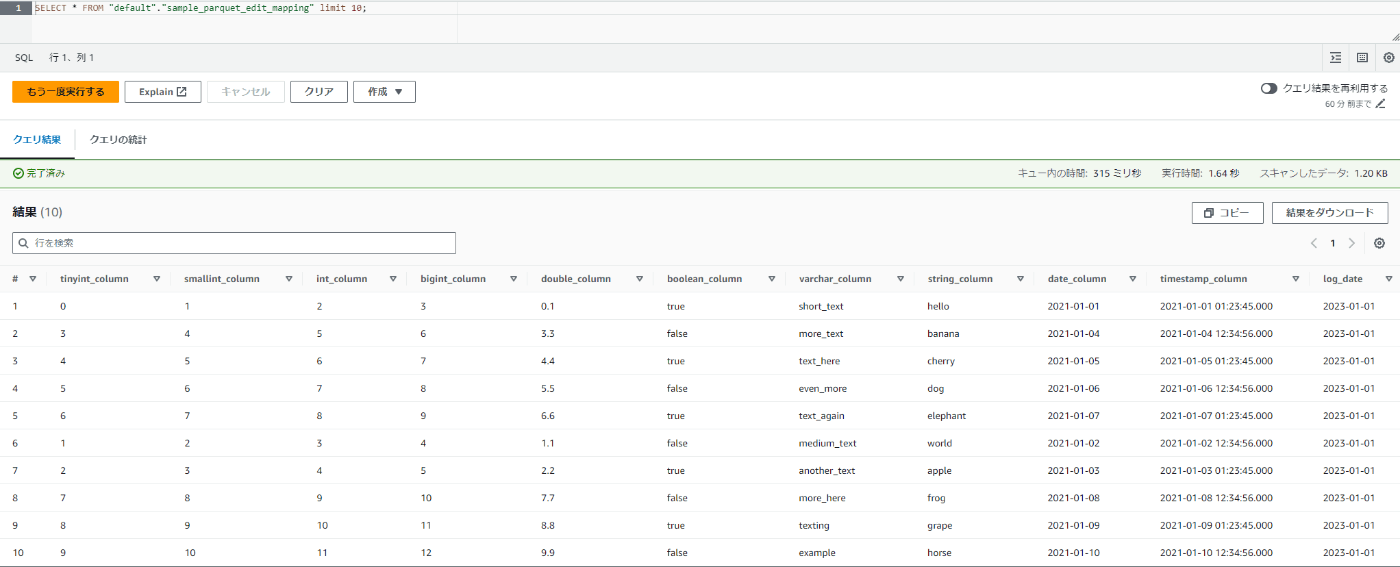
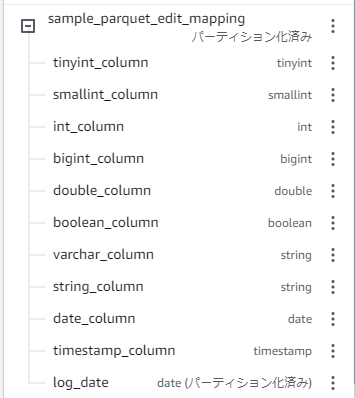
というわけで、Change Schemaを挟まずに変換した場合に型がstringになってしまうカラムに対してソースタイプをstringにすると、適切な型の状態で拡張子を変換しテーブルを作成できます。
ソースタイプを全てstringにして変換
「型を見てソースタイプをstringにするの面倒!最初から全部stringでいいんじゃない?」と思ったのでやってみます。
mappings=[
("tinyint_column", "string", "tinyint_column", "tinyint"),
("smallint_column", "string", "smallint_column", "smallint"),
("int_column", "string", "int_column", "int"),
("bigint_column", "string", "bigint_column", "bigint"),
("double_column", "string", "double_column", "double"),
("boolean_column", "string", "boolean_column", "boolean"),
("varchar_column", "string", "varchar_column", "varchar(255)"),
("string_column", "string", "string_column", "string"),
("date_column", "string", "date_column", "date"),
("timestamp_column", "string", "timestamp_column", "timestamp"),
("log_date", "string", "log_date", "date"),
],
実行自体は成功しましたが、一部カラムはデータが無くなってしまいました。
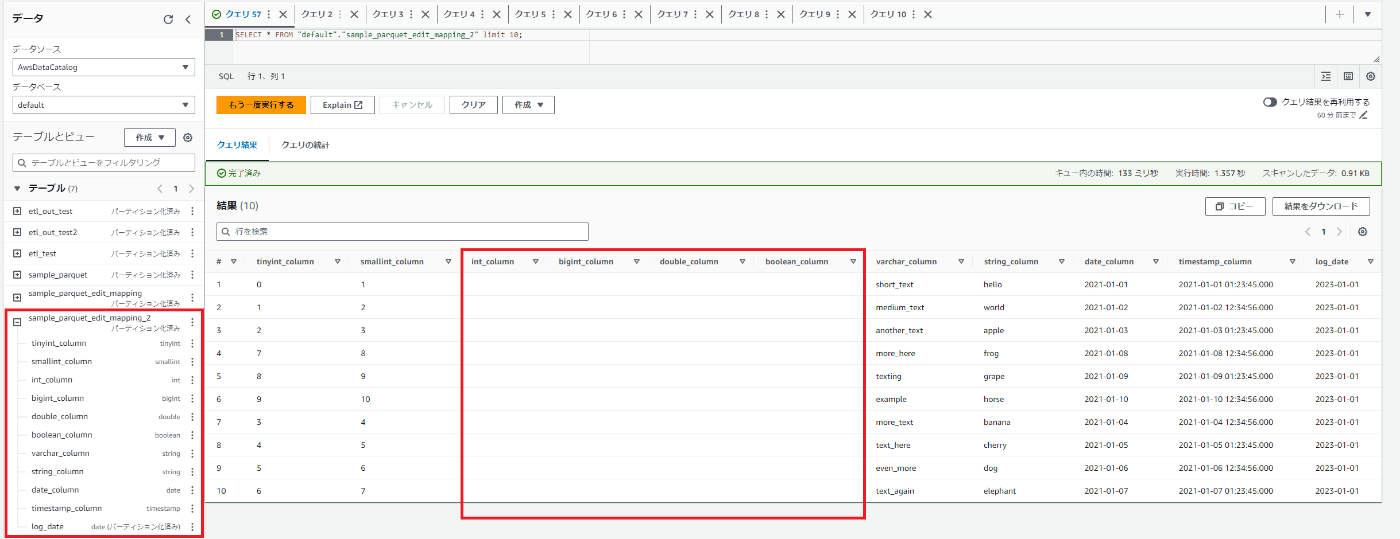
そのまま変換で変換できていた部分が見事に空になっていますね。
元データを確認してもデータが無くなっています。

まとめ
tsvファイルを参照しているAthenaテーブルを用いて、parquetへ拡張子変換し、新たなAthenaテーブルをAWS Glue ETL ジョブで作る場合は
- Change Schemaを間に挟む
- かつ、Change Schemaを間に挟まなかった場合にstringに変換されてしまう型のソースタイプを
stringにする- 今回の検証では
tinyint,smallint,varchar,date,timestamp
- 今回の検証では
- その他のソースタイプはAthenaテーブルで定義されている型を書く
- 書かないと変換後データが消える可能性あり(stringだと少なくとも消える)
Discussion