【個人開発】英字ニュースから単語の出現回数を調べた話
1.はじめに
皆さん、英語勉強していますか?
最近では様々なドキュメントが翻訳されたり自動翻訳ツールが充実してきたりと便利な世の中になっていますが、まだまだ英語が必要になる場面も多いです。
私も英語の必要性を感じてTOEICの勉強を始めました。そこそこ基礎が完成できたと考え、少し背伸びして英字ニュースを読んでみたりしました。
しかし1ヶ月くらいニュースを読んだところ、あることに気づきました。
「単語、全然わからん」と。
TOEICと実際に使用されている単語は少なからずズレているようです。今だにTOEIC頻出単語であるwheelbarrow(手押し車)やcanopy(天蓋)を英字新聞で見たことがありません。
それでは、英字ニュースでの頻出単語にはどのようなものがあるのでしょうか。気になったので英字ニュースに使用されている単語の出現頻度を解析してデータベースに入れるツールを作成しました。
2.作ったもの
自動で英字ニュースサイトをスクレイピングし、単語毎の出現回数をデータベースに入れるバッチを作成しました。
日毎やサイト毎に単語の出現数を格納しているため、様々な用途の分析に使用することができます。
下記は2023/9/18のBBCトップニュース記事の単語出現頻度top3を取得した時の例です。

3. 全体図
全体の構成図は下記の通りです。
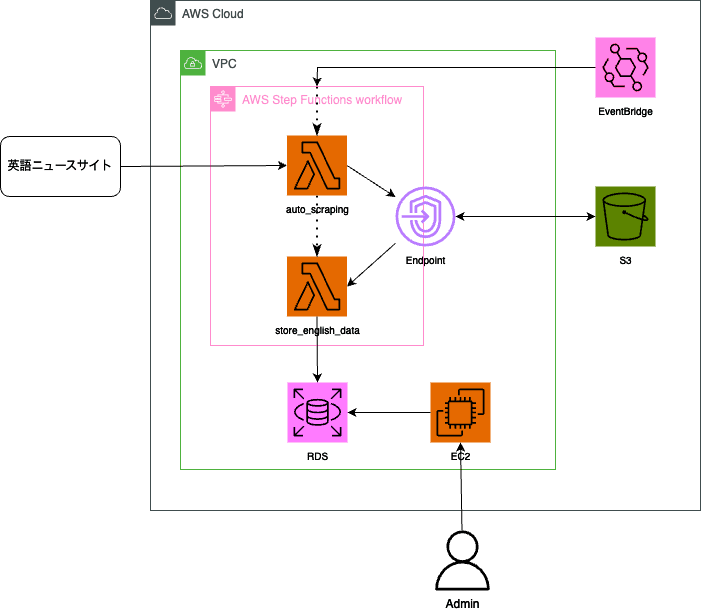
バッチはLambda(Python3.9,3.11)で作成しています。外部英語ニュースサイトのrssから最新記事を取得し一時的に保存するバッチと、その一時保存した記事を元に単語出現数を解析するバッチの2つあります。
それぞれのバッチの実行順序は必ず決まっているため、StepFunctionで1つのステートマシンにまとめました。また、1日1回実行して欲しいのでEventBridgeで定期実行化しています。
英字ニュースサイトから取得したデータは、記事の本文だけを抽出したファイルをS3に一時的に配置しています。バックアップ等で再度実行する際などに外部サイトへの負荷を減らす目的があります。
集計データはRDS(MySQL)に格納され、半永久的に保管されます。記事データは定期的に削除しています。
現在、集計データの確認API等を用意していません。管理者のみEC2からRDSに接続を行ってデータを確認できるようにしています。
4. 使用技術
全体図で説明できなかった箇所やつまづいた部分を解説します。
4.1 Lambda(Python3.9,3.11)
外部英語ニュースサイトのrssから最新記事を取得するバッチ、記事を解析するバッチをLambdaで作成しました。
最新記事を取得するバッチはPython3.11、記事を解析するバッチはPython3.9で動作しています。
採用理由
Lambdaは実行時のみ課金される仕様となっています。今回のバッチはそれぞれ1日1回しか起動しないので、コストを抑えられる点が魅力的でした。
また、責任範囲がコードのみという点も素晴らしいです。実行サーバーの意識をしなくて良いという点もスピーディーに開発をしたい点にマッチしていると感じました。
Lambdaを採用する際の注意点として、実行時間は15分以内やメモリは10GBまでという制約がある点に注意してください。今回の2つのバッチはメモリ128MBで十分に収まりますし、実行時間も90秒以内で完了しているので問題ありませんでした。
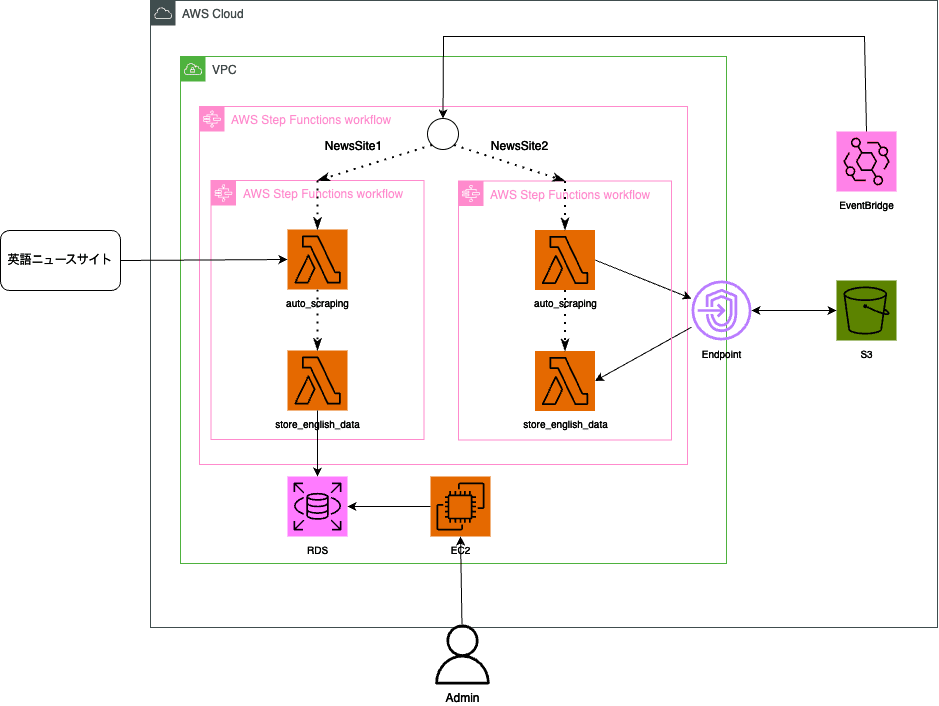
今後、データの収集範囲を広げた場合の影響範囲についても考える必要があります。現在の作りでは引数にデータ取得元を指定しているため、さらに上位のStepFunctionを作成してもいいかもしれません。下記は今後の構成案の全体図です。
Python 3.9を使用する理由
繰り返しになりますが、最新記事を取得するバッチはPython3.11、記事を解析するバッチはPython3.9とバージョンが異なっています。これは記事解析バッチで使用しているNumpyモジュールが原因です。
NumPyモジュールを含むLambdaバッチをランタイムPython3.11で実行したところ、下記の依存関係エラーが発生します。
エラー文
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': Unable to import required dependencies:
numpy:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions failed. This error can happen for
many reasons, often due to issues with your setup or how NumPy was
installed.
We have compiled some common reasons and troubleshooting tips at:
Please note and check the following:
- The Python version is: Python3.11 from "/var/lang/bin/python3.11"
- The NumPy version is: "1.25.2"
and make sure that they are the versions you expect.
Please carefully study the documentation linked above for further help.
Original error was: No module named 'numpy.core._multiarray_umath'
Traceback (most recent call last):
[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': Unable to import required dependencies: numpy: IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE! Importing the numpy C-extensions failed. This error can happen for many reasons, often due to issues with your setup or how NumPy was installed. We have compiled some common reasons and troubleshooting tips at: https://numpy.org/devdocs/user/troubleshooting-importerror.html Please note and check the following: * The Python version is: Python3.11 from "/var/lang/bin/python3.11" * The NumPy version is: "1.25.2" and make sure that they are the versions you expect. Please carefully study the documentation linked above for further help. Original error was: No module named 'numpy.core._multiarray_umath' Traceback (most recent call last):
Numpyのバージョンは1.25.2を使用しているようですが、公式ドキュメントではPython3.11は対応していると記載されています。
バージョンの問題では無さそうです。
NumPy 1.25.0 リリース
2023年1月17日 – Numpy 1.25.0 がリリースされました。 今回のリリースの目玉機能は次のとおりです。
...(中略)
このリリースでサポートされている Python のバージョンは3.3.9 - 3.11 です。
https://numpy.org/ja/news/ より引用
pomblue’s blogさんの記事によると、どうやらローカルでLambdaのzipファイルを作成したのが悪さしているようです。
そこでLambda用のDocker imageをpullし、その環境内でzipを作成したところ動作しました。
$ cd /to_lambda_function_path/
$ docker run -it -v $(pwd):/var/task amazon/aws-sam-cli-build-image-python3.9:latest
# python3 -m pip install --target ./package numpy
# cd ./package
# zip -r ../my_deployment_package.zip .
# zip ../my_deployment_package.zip ../lambda_function.py
現在、Lambda用のDocker imageはPython3.9までしか無いようなので、仕方なくランタイムもPython3.9にしているという状況です。
Beautifulsoup4でxmlパーサーが使えない
またまた外部ライブラリ周りで詰まりました。
最新記事を取得するバッチでは、スクレイピングを用いて記事の内容を取得する必要があります。その際にBeautifulsoup4というライブラリを使用したのですが、デフォルトではhtmlファイルのパーサーだけしか含まれていません。今回はxmlファイルのパースが必要だったため、lxmlパッケージをインストールして実行しました。
すると、下記のエラーが発生しました。lxmlパッケージはLambdaにアップロードするzipファイルに含めているにも関わらずです。
Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
BeautifulSoup のエラー "Couldn't find a tree builder" の原因と対処法 を参考にさせていただきましたが、こちらでも解決しませんでした。
どうしようもなかったので、根本的な解決にはなりませんが別ライブラリを使用しました。同じ部分で詰まる方がいるかもしれないので、この件に関して記事を作成しました。
大文字小文字変換の速度比較
記事を解析するバッチでは、単語ごとに集計して出現回数をカウントします。この際、文頭にある大文字アルファベットが含まれる単語を全て小文字に変換する必要があります。
変換方法として、下記の2種類のアプローチが考えられます。
- 全ての文字列に小文字化を適用する
- 小文字チェックを行い、違ったものの文字列のみ小文字化を実行する
検証した結果、手法1の片っ端から小文字化を適用する方が早いことがわかりました。検証内容に関しては下記の記事にまとめています。
4.2 RDS(mysql)
記事の出現回数を格納するためのデータベースです。スクレイピングした記事はS3に配置しているため、データベースには入れていません。
採用理由
データベースの選定でまず決めなくてはならないのは、リレーショナルデータベースかNoSQLのどちらを選択するかだと思います。今回はデータの容量がそこまで多くないことや、個人開発であるためスケーリングをそこまで意識しなくて良いという点を考えリレーショナルデータベースを採用することにしました。
RDBにはMySQLを使用することにしました。採用理由はAmazon RDSにMySQLがサポートしているという理由もありますが、使い慣れているという点が大きいです。750時間/月の無料枠がついてきていることも嬉しいポイントです。
無料利用枠は、1 か月あたり 750 インスタンス時間までとなっています。また、1 か月につき 20 GB のデータベースストレージ、1,000万 I/O、20 GB のバックアップストレージも無料で使用可能です。
https://aws.amazon.com/jp/rds/free/faqs/
セキュリティグループのインバウンドルールを編集
RDSインスタンスを立ち上げて、適当なEC2インスタンスから接続を試みようとしたところ応答がありませんでした。
$ mysql -u admin -p -h <hostname>
Enter password:
********
# 返答がない...
インバウンドルールを編集しなくては繋がらないのを失念していました。下記の記事を参考に設定したところ、無事つながりました。画像つきで解説していただいている点が非常にわかりやすいです。
4.3 StepFunctions
StepFunctionsで2つのLambdaのワークフローを作成しました。
採用理由
最新記事を取得するバッチ、記事を解析するバッチの2つのLambdaバッチは実行順序があります。最新記事バッチが必ず終了した際に次のバッチを呼ぶ(失敗時には次のバッチを実行しない)ワークフローを作成したかったため、簡単にAWSリソースをワークフロー化できるStepFunctionsを採用しました。
各リソースをGUIで組み合わせて、簡単にワークフローを作成できる点は大きなメリットだと思います。しかし、後述するパラメータの制御が非常に難解だったのが想定外でした...
入出力パラメータの設定が難解
私の理解度の問題によるところが大きいとは思いますが、かなり初見殺しな仕様となっています。例を挙げるとキリがありませんが、何個か紹介します。
-
InputPath,OutputPathは入力値ではなくフィルターである- 項目名を見ると入出力パラメータを設定するものかと思っていました。名前を
InputFilter等にして欲しい気持ちもあります...
- 項目名を見ると入出力パラメータを設定するものかと思っていました。名前を
-
Parametersを設定すると前のステートの値は全て消える- このパラメーターが無いと前ステートの値がそのまま入力になります
- あった場合は
Parametersの値で上書きします - 前ステートの値が必要であれば、
$.hogeのように記載する必要があります
- コンソール上でStepFunctionsの実行結果を見た際のステート入出力は加工前のもの
- ここが一番混乱しました
- コンソールに表示されている値から
Parameters,InputPathの加工が行われたものがステートマシンに入力されます - 実際にステートに入ったパラメータを確認はステート側で出力するしかないようです
この辺の仕様について、Classmethodさんのブログで非常にわかりやすく説明されています。これから初めてステートマシンを作成される方は一読されることを強くお勧めします。
4.4 EventBridge
イベントパターンにマッチする際に対象のリソースを実行するサービスです。
採用理由
1日1回StepFunctionsを自動実行したいためです。コンソール上であっという間に設定できたので、つまづいたポイント等も特にありません。
4.5 その他
他にも色々と細かい点で詰まったりしています。そういうものはスクラップにまとめているので、もしお時間ある方は下記のスクラップも見ていただけると嬉しいです。
5.今後やりたいこと
今回作成したものはあくまでデータの収集部分のみなので、実際にデータを活かせる基盤を作っていきたいと考えています。
APIを作成し、頻出記事が一覧で表示されるWebページを作成するのも面白いかもしれません。難易度は高いですが英単語から品詞名と日本語訳を取得できたら英語学習がさらに捗りそうです。
Discussion