Rで論文を書く実践的なテクニック集 (tinytable編)
kableExtra, gt から tinytable の時代へ
近年, Rで表を作成するためのパッケージとして kableExtra と gt が人気を集めてきました. 私は kableExtra を使って論文(gt を使ってスライド (revealjs) で表を作成しており, 以前行ったRワークショップやZennでの解説記事でもkableExtraを念頭においておりました.
しかし, 2024年4月現在, tinytableが従来のパッケージと比べ軽くて使いやすく, 今後のスタンダードになっていくと確信しており, 以前書いた記事を更新する必要があると考えました. この記事では, tinytable を使って論文に必要な表を作成する方法を紹介します.
tinytable とは?
tinytable は, Vincent Arel-Bundock (modelsummaryのメンテナー) によって開発されたミニマル(zero-dependency, baseRのみを使用)でありながら強力な表を作成するためのパッケージです. modelsummary パッケージとシームレスに連携するように設計されており, Rで行えるほとんどの推定方法に対応しています. Rで回帰表を作成する場合, 現在はmodelsummaryが最有力候補であり, そのバックエンドに採用されていることからも, tinytable が今後の主流になることは間違いありません.
tinytable の基本
library(dplyr)
library(tidyr)
library(tinytable)
ここでは私がワークショップ内で用いた the Madrid traffic accident datasetを用います. このデータセットは, 2019年から2023年までのマドリード市内で発生した交通事故に関する情報を含んでおり, 事故の種類, 事故の日時, 事故の場所, 事故の原因, 事故に関わった人の属性, 事故の結果などが含まれています. データのダウンロードやクリーニングに関してはリンクのコードを参照してください.
dir_post <- here::here("blog/2024/04/29/")
data <- arrow::read_parquet(file.path(dir_post, "data", "cleaned.parquet")) |>
mutate(is_died = injury8 == "Died within 24 hours",
is_hospitalized = injury8 %in% c("Hospitalization after 24 hours",
"Hospitalization within 24 hours",
"Died within 24 hours"))
まず, 事故に関わった人の人数と天候に関するクロス集計表を作成します.
tab_count <- data |>
filter(!is.na(weather), !is.na(gender)) |>
summarize(n = n(), .by = c(year, gender, weather)) |>
pivot_wider(names_from = c(gender, year), values_from = n) |>
arrange(weather) |>
select(weather, starts_with("Men"), starts_with("Women"))
tab_count
# A tibble: 6 × 11
weather Men_2019 Men_2020 Men_2021 Men_2022 Men_2023 Women_2019 Women_2020
<fct> <int> <int> <int> <int> <int> <int> <int>
1 sunny 24399 14969 19208 20679 22451 11971 6958
2 cloud 1159 1190 1325 2082 2011 555 554
3 soft rain 2126 1198 1281 1930 1224 1068 542
4 hard rain 386 202 386 527 317 222 96
5 snow 2 2 124 5 NA NA NA
6 hail 11 5 6 4 3 3 3
# ℹ 3 more variables: Women_2021 <int>, Women_2022 <int>, Women_2023 <int>
tinytable は tt() 関数を使って表を作成します.
tt_count <- tab_count |>
`colnames<-`(c("", rep(2019:2023, 2))) |>
tt() |>
group_tt(i = list("Good Weather" = 1, "Bad Weather" = 3),
j = list("Men" = 2:6, "Women" = 7:11)) |>
style_tt(i = c(1, 4), bold = TRUE) |>
format_tt(replace = "-")
tt_count |>
theme_tt("tabular") |>
save_tt(file.path(dir_post, "tex", "table_count.tex"),
overwrite = TRUE)

ポイントは
-
group_tt()で行と列を (\LaTeX multirowやmulticolumnのように) グループ化 -
style_tt()で行を太字や斜体に -
format_tt()でセルを数値やパーセンテージに変換.replace引数でNAのセルを指定した文字に置き換えられます -
tt()関数では (kableExtraのcol.names引数のように) 列名を変更できないので,colnames<-()を使う. 詳しくは#194の議論を参照してください - 表を plain な表 (つまり
\begin{table}と\end{table}がない) として保存するには,theme_tt("tabular")を使います
LaTeXの表をQuartoのHTML記事にSVG形式で挿入する小技
英語版のQuarto記事では, tinytableオブジェクトをSVG形式の図に変換できます.
1. tinytableオブジェクトをPDFファイルとして保存する.
tt_count |>
save_tt(file.path(dir_post, "img", "table_count.pdf"),
overwrite = TRUE)
tinytable::save_tt()はとてもパワフルな関数で, ファイルの拡張子によって出力形式を変更できます. 拡張子が.pdf の場合, tinytexパッケージを使って1つのPDFファイルとしてコンパイルします.
2. PDFファイルをSVGファイルに変換する.
```{bash}
#!/bin/bash
pdf2svg img/table_count.pdf img/table_count.svg
```
modelsummary
library(modelsummary)
library(fixest)
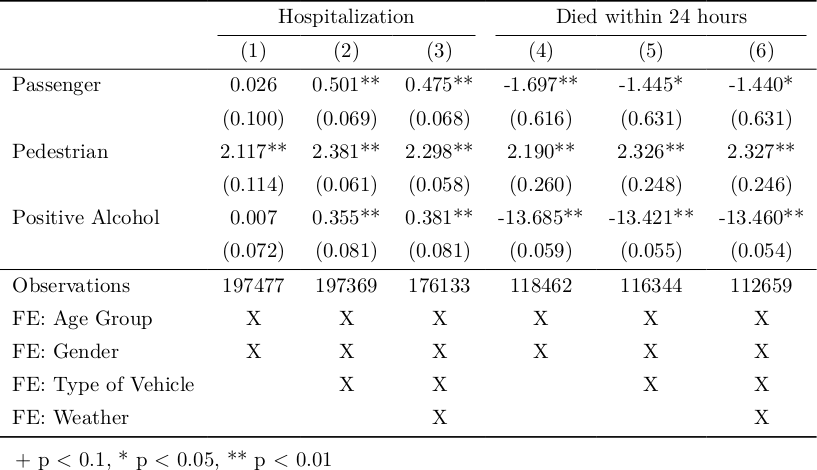
tinytableはそもそもmodelsummaryと連携するために開発されたパッケージです. そのため, modelsummaryを使って回帰分析の結果を表にすることができます. modelsummaryのversion 2.0.0以降では, tinytableがデフォルトの表作成パッケージになっています. 例えば, 以下のような6つのロジット回帰モデルを推定したとします.
setFixest_fml(..ctrl = ~ type_person + positive_alcohol + positive_drug |
age_c + gender)
models <- list(
"(1)" = feglm(xpd(is_hospitalized ~ ..ctrl),
family = binomial(logit), data = data),
"(2)" = feglm(xpd(is_hospitalized ~ ..ctrl + type_vehicle),
family = binomial(logit), data = data),
"(3)" = feglm(xpd(is_hospitalized ~ ..ctrl + type_vehicle + weather),
family = binomial(logit), data = data),
"(4)" = feglm(xpd(is_died ~ ..ctrl),
family = binomial(logit), data = data),
"(5)" = feglm(xpd(is_died ~ ..ctrl + type_vehicle),
family = binomial(logit), data = data),
"(6)" = feglm(xpd(is_died ~ ..ctrl + type_vehicle + weather),
family = binomial(logit), data = data)
)
modelsummary(models)
デフォルトで以下のような表が作成されます.

論文で使える形にするために, 以下のようにカスタマイズします.
cm <- c(
"type_personPassenger" = "Passenger",
"type_personPedestrian" = "Pedestrian",
"positive_alcoholTRUE" = "Positive Alcohol"
)
gm <- tibble(
raw = c("nobs", "FE: age_c", "FE: gender",
"FE: type_vehicle", "FE: weather"),
clean = c("Observations", "FE: Age Group", "FE: Gender",
"FE: Type of Vehicle", "FE: Weather"),
fmt = c(0, 0, 0, 0, 0)
)
tt_reg <- modelsummary(models,
stars = c("+" = .1, "*" = .05, "**" = .01),
coef_map = cm,
gof_map = gm) |>
group_tt(j = list("Hospitalization" = 2:4,
"Died within 24 hours" = 5:7))
tt_reg |>
theme_tt("tabular") |>
save_tt(file.path(dir_post, "tex", "table_reg.tex"),
overwrite = TRUE)
-
coef_mapで係数の名前を変更します -
gof_mapで統計量 (goodness-of-fit) を選択し, 名前を変更します -
modelsummary関数はtinytableオブジェクトを返すので,tinytableの関数 (group_tt()やstyle_tt()) を使って表を整えることができます
おわりに
この記事では, tinytable を使って論文に必要な表を作成する方法を紹介しました. 試しに使っていく過程で, tinytable が kableExtra や gt と比べて以下の理由で使いやすいと感じました.
-
kableExtraやgtのほとんどの機能をカバーしている.multirowやmulticolumn, セルのハイライト, セルのフォーマット, 数式の表示などができる - HTML や LaTeX だけでなく, PDF (
tinytexを用いて) や Typst にもエクスポートできる -
kableExtraやgtよりもコンパイルが速い. これはtinytableが baseR のみを使用している小さなパッケージであるためだと思います
みなさまの研究の一助となれば幸いです🥂
Discussion