ipyleafletで時系列な地理空間データを可視化してみる
TL;DR
- 静的なデータであればfoliumでOKです。動的に変更が必要なデータの可視化はipyleafletが適します。
- ipyleafletで、一部値を変更した地理空間データを再描画したいとき、インスタンス化したipyleaflet関連クラスの属性を置き換えてください[1]。
結果サンプル
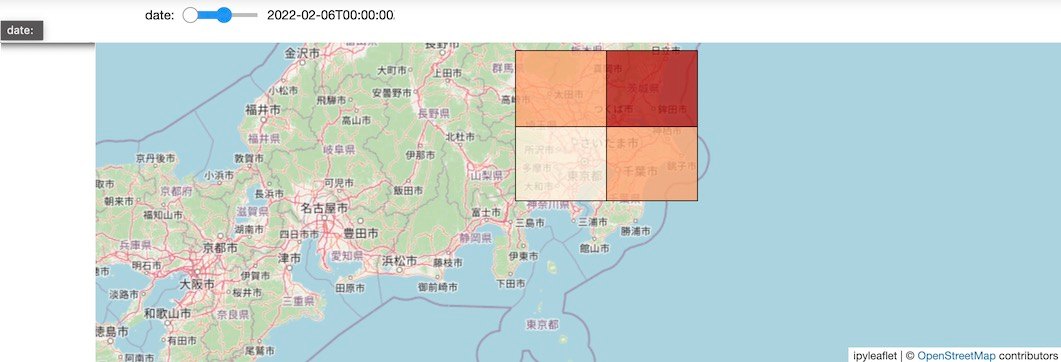
背景
地理空間データを可視化するとき、foliumやipyleafletなどのライブラリがあります。foliumは静的なデータをすぐに可視化するのに適しています。一方、時系列な地理空間データなどの複雑なデータを表現するのが構造上難しいです。ipyleafletでは動的にデータを再描画できるほか、ipywidgetsの各種UIと併用することができます[2]。
そこで、以下の流れで地理空間データを可視化してみました。
- ipywidgetsで、シークバーを動かす度にデータの期間を変更する
- 1.を受けて、pandas.DataFrameとして読み込んだデータを期間でフィルタする
- フィルタしたデータをgeojsonデータに変換する
- ipyleafletでgeojsonデータを可視化する
やること
以下のデータについて、日時情報(record_utc_date)でフィルタして階級区分図(Choropleth map)で表示することを考えてみます。
- id: ジオメトリID。1ポリゴンに対応する。同じ場所でも日時が異なると、同じジオメトリIDのデータを含むことがある。
- record_utc_date: データの記録日時(UTC, ISO8601フォーマット)
- value: データ値
- polygon_geometry: ジオメトリ情報(ポリゴン、json.loadsで読み出すとそのままgeojsonのPolygonに渡せる形式)。idに対して一意の値。
"id","record_utc_date","value","polygon_geometry"
"5339","2022-02-16T00:00:00Z",0,"[[[140,36],[140,35.33333333],[139,35.33333333],[139,36],[140,36]]]"
"5340","2022-02-06T00:00:00Z",1,"[[[141,36],[141,35.33333333],[140,35.33333333],[140,36],[141,36]]]"
"5439","2022-02-06T00:00:00Z",3,"[[[140,36.66666667],[140,36],[139,36],[139,36.66666667],[140,36.66666667]]]"
"5440","2022-02-06T00:00:00Z",4,"[[[141,36.66666667],[141,36],[140,36],[140,36.66666667],[141,36.66666667]]]"
"5339","2022-02-06T00:01:00Z",2,"[[[140,36],[140,35.33333333],[139,35.33333333],[139,36],[140,36]]]"
"5340","2022-02-06T00:01:00Z",5,"[[[141,36],[141,35.33333333],[140,35.33333333],[140,36],[141,36]]]"
"5440","2022-02-06T00:01:00Z",6,"[[[141,36.66666667],[141,36],[140,36],[140,36.66666667],[141,36.66666667]]]"
"5439","2022-02-06T00:02:00Z",7,"[[[140,36.66666667],[140,36],[139,36],[139,36.66666667],[140,36.66666667]]]"
"5440","2022-02-06T00:02:00Z",8,"[[[141,36.66666667],[141,36],[140,36],[140,36.66666667],[141,36.66666667]]]"
サンプルコード
https://github.com/Niccari/visualize-mesh-timelapse をご覧ください。
環境構築: ライブラリのインストール
以下のライブラリを使用します。上記サンプルコードでは、pipenv installによりインストールできます。
| ライブラリ名 | 役割 | 検証に使ったバージョン | 備考 |
|---|---|---|---|
| geojson | 地理空間データをgeojson形式に変換する | 2.5.0 | |
| pandas | 地理空間データの加工、フィルタリング | 1.4.1 | |
| ipyleaflet | 地理空間データを地図上に可視化する | 0.15.0 | ※ ipywidgets, jupyter-notebookはipyleafletとともにインストールされる |
| branca | ipyleafletで使うカラーマップ定義が入っている | 0.4.2 |
処理の流れ
- 必要ライブラリのインポート
- 地理空間データ読み込み
- 関数定義: 期間によるフィルタ処理
- 関数定義: フィルタしたデータをgeojson化
- 初期化: マップ表示を追加
- 初期化: 期間スライダー(シークバー)を追加
1. 必要ライブラリのインポート
import json
import pandas as pd
from geojson import Feature
from geojson import FeatureCollection
from geojson import Polygon
from ipyleaflet import Choropleth
from ipyleaflet import Map
from ipywidgets import SelectionRangeSlider
2. 地理空間データ読み込み
地理空間データを読み込み、record_utc_dateのうちユニークな日時のリストを取得します。このリストを、期間スライダーの初期化時に使用します。
df = pd.read_csv("mesh_timeseries.csv")
unique_dates = list(set(df["record_utc_date"].tolist()))
unique_dates.sort()
3. 関数定義: 期間によるフィルタ処理
読み込んだ地理空間データについて、期間でデータをフィルタする処理を定義します。
その後、ジオメトリIDごとにグルーピング+valueの平均値を集計します。record_utc_dateをbegin_dateで固定していますが、この部分は"first"や"last"などでも問題ありません(サンプルコードを作っていたときの名残です)。
def filtering_dataframe(
df: pd.DataFrame, begin_date: str, end_date: str
) -> pd.DataFrame:
df_filtered = df[
(df["record_utc_date"] >= begin_date)
& (df["record_utc_date"] <= end_date)
]
# note: "record_utc_date": "first" or "record_utc_date": "last" is okay,
# because begin_date <= record_utc_date <= end_date.
df_filtered = df_filtered.groupby(["id"], as_index=False).agg({
"record_utc_date": lambda x: begin_date,
"value": "mean",
"polygon_geometry": "first",
})
return df_filtered
4. 関数定義: フィルタしたデータをgeojson化
ipyleafletでは、地理空間データはgeojsonフォーマットであることを期待しています。そこで、geojsonパッケージのFeature, Polygonなどを使ってpd.DataFrameをFeatureCollection(geojsonフォーマット)に変換します[3]。
また、ipyleafletのChoroplethクラスでは、カラーマップ作成のために各データのIDとデータの値をdictで渡す必要があります。そこで、idとvalueのdictを作ります(以下、mappingが該当)。
def to_geojson(df: pd.DataFrame) -> tuple[FeatureCollection, dict]:
# note: Specify an attribute name whatever you want for id,
# except for reserved ones.
features = df[["id", "polygon_geometry"]].apply(
lambda row: Feature(
data_id=row['id'],
geometry=Polygon(json.loads(row['polygon_geometry']))
), axis=1).tolist()
feature_collection = FeatureCollection(features=features)
mapping = {}
def add_mapping(row):
mapping[row['id']] = row["value"]
df[["id", "value"]].apply(add_mapping, axis=1).tolist()
return feature_collection, mapping
def calc_new_data(
df: pd.DataFrame, begin_date: str, end_date: str
) -> tuple[FeatureCollection, dict]:
df_filtered = filtering_dataframe(df, begin_date, end_date)
return to_geojson(df_filtered)
5. 初期化: 期間スライダーを追加
ipywidgetsのSelectionRangeSliderクラスを使うことで、optionsで指定した範囲でレンジを操作できるようになります。
作成したスライダーのobserveでコールバック用の関数を指定すると、値が変わる度に同関数が呼び出されます。
この関数内で、前述のcalc_new_data関数に入力データと期間を指定すると、可視化に必要なデータが取得できます。
次節に記載の通り、データの描画にChoroplethクラスを使います。そこで、Choroplethクラスを初期化した変数layerについて、
- choro_data <- mapping
- geo_data <- feature_collection
- value_min <- min(mapping.values())
- value_max <- max(mapping.values())
を渡すとマップ上の地理空間データが再描画されます。このとき、各属性を更新する度に再描画が行われます。なお、choro_dataとgeo_dataは1対のデータなので、geo_dataとchoro_dataのどちらかだけを更新するとKeyErrorが発生することがあります。そこで、本例ではchoro_dataでKeyErrorとなった場合は処理せず、geo_data更新時でカバーするようにしています。
また、layer.choro_dataやlayer.geo_data内の一部属性のみを書き換えても再描画されません。新しいオブジェクトを作って再代入するようにしてください。
datetime_slider = SelectionRangeSlider(
description="date: ",
options=unique_dates,
index=(0, len(unique_dates)//2), # begin ~ middle
)
def update_date(change):
begin_date = min(datetime_slider.value)
end_date = max(datetime_slider.value)
feature_collection, mapping = calc_new_data(df, begin_date, end_date)
try:
layer.choro_data = mapping
# note: layer.geo_data may not have some keys at this moment, ignore them.
# It will be resolved in the next line(layer.geo_data = ...)
except KeyError:
pass
layer.geo_data = feature_collection
layer.value_max = max(mapping.values())
layer.value_min = min(mapping.values())
datetime_slider.observe(update_date, names='value')
datetime_slider
6. 初期化: マップ表示を追加
Choroplethクラスを初期化するにあたり、以下のパラメータを設定する必要があります。
- geo_data: 地理空間データのジオメトリ情報(Point, LineString, Polygon等)。geojsonフォーマットに相当
- choro_data: 各featureのidに対する値の辞書データ(例: { "205339": 4, "205340": 1 })
- key_on: geo_dataのどの属性がchoro_dataのキーに対応するか。本例ではto_geojson関数で定義した"data_id"が相当
- value_min: 可視化するデータの最小値
- value_max: 可視化するデータの最大値
そこで、必要なデータをcalc_new_data関数を使って準備します。
Choroplethを初期化後、マップを定義してadd_layerでlayerとして追加します。
feature_collection, mapping = calc_new_data(
df, min(datetime_slider.value), max(datetime_slider.value))
layer = Choropleth(
geo_data=feature_collection,
choro_data=mapping,
border_color='black',
key_on='data_id',
value_min=min(mapping.values()),
value_max=max(mapping.values()),
style={
'fillOpacity': 0.8,
}
)
# FIXME: should set center/zoom calculated from feature_collection
m = Map(center = (35.667, 139.7), zoom = 7)
m.add_layer(layer)
m
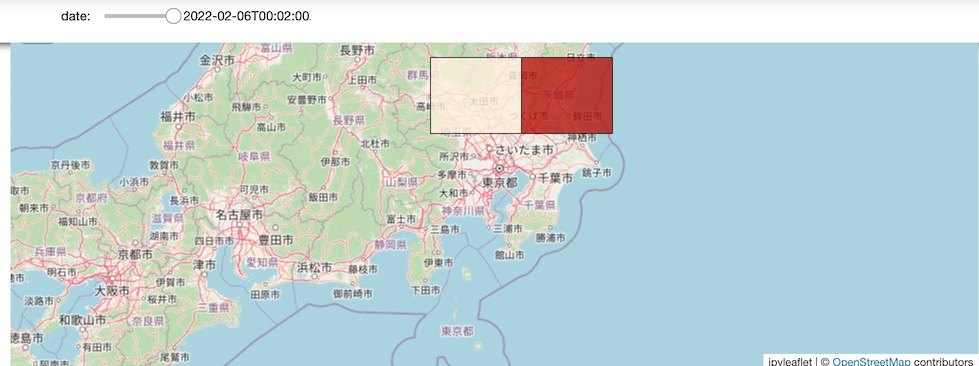
結果
以下の通りとなります。期間スライダーの値に応じて再描画されています。
Discussion