Pytorch2.0でFlash Attentionを使ってみた話
こんにちは、Fusicのハンです。株式会社Fusicでは機械学習関連のPoCから開発・運用まで様々なご相談に対応してます。もし困っていることがありましたら気軽にお声かけてください。
今回はFlash Attentionを使ってみたことについて、簡単に説明しようと思います。FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awarenessで紹介されたこのAttention方法は、早くて正確なAttentionアルゴリズムを実現し、より長いSequenceでのTransformer学習を行うことができます。
この記事では、Flash Attentionの理論的なことを解析することよりは、Pytorch2.0での実装を行う際、注意すべきな部分を整理しますので、論文の内容についてはFlashAttention - Tri Dao | Stanford MLSys #67を参照することをお勧めします。
Flash Attentionとは
Flash Attentionは、長いSequenceでのTransformer学習ができるようにするという目的で提案された手法で、従来のAttention方法での以下のような問題を解決しようししています。
- 長いSequenceでの学習が難しい
- 長い処理のためにBatchSizeを減らすと学習時間が長くなる
指摘しているのは、Qeury x Key のマトリクス計算の部分で、N x N サイズの計算の際、GPUでのデータやりとりが上記の問題の原因になっていると説明しています。下の図は論文から取り出したものですが、IO Awarenessを考え、GPUとSRAM間のやり取りを加速化した内容を表しています。
Flash Attention:参照論文
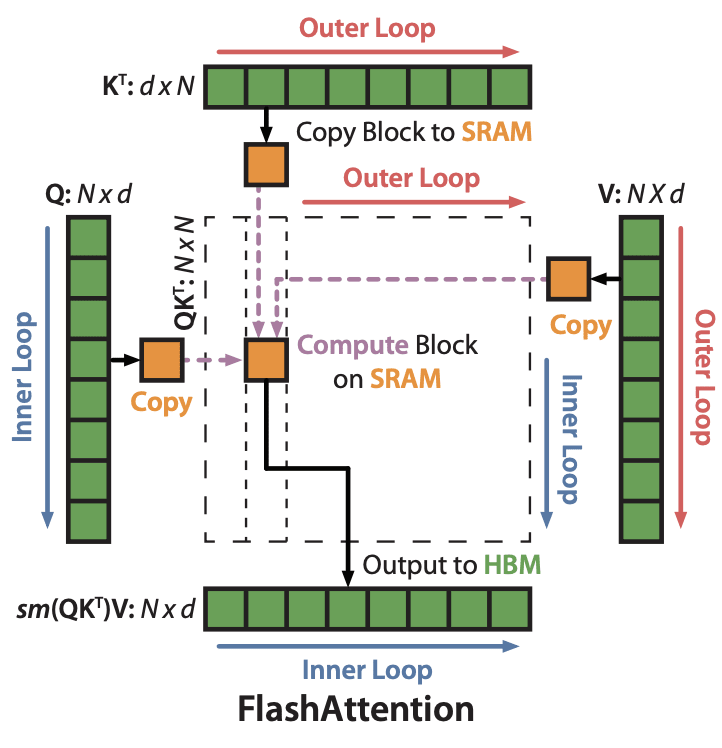
Query x KeyとValueの計算を複数のBlockに分け、SRAMに送って処理しているのがわかります。このようなTilingを通じ、既存の手法より早く(x3)、メモリ効率よく(x10~20)Attention計算ができ、16KのSequenceにも対応ができるようになったと主張しています。
下の図は、上の手法を他の形式で表したものですが、Blockの処理がより理解しやすかったので持ってきました。ご参考ください。
Blockに分けてAttentionを処理:参照動画
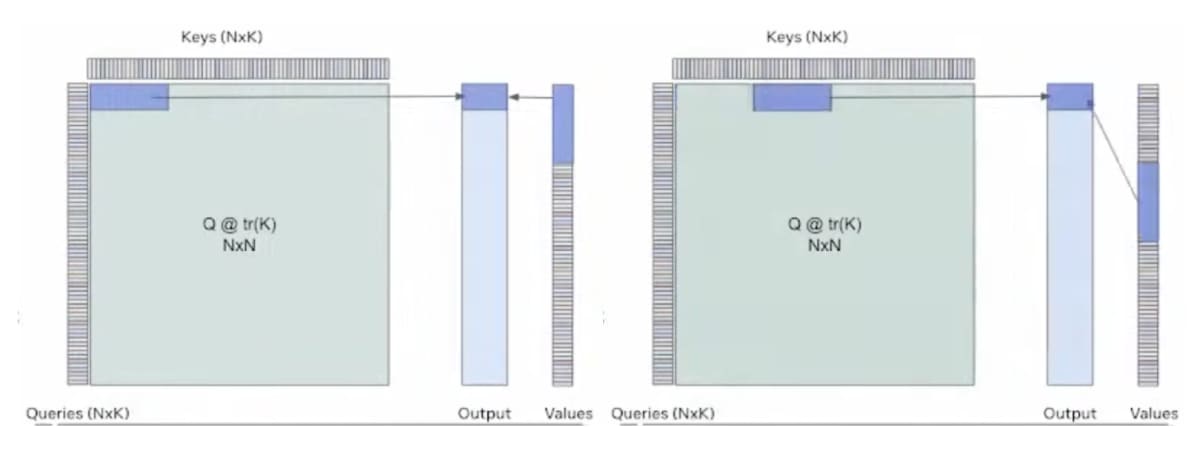
Pytorch2.0ではFlash Attentionを支援している?
結論から言うと、自動的にFlash Attentionを使うような構造をしているが、どんな場合でも使用しているわけではないです。Pytorch2.0のドキュメント(BETA) IMPLEMENTING HIGH-PERFORMANCE TRANSFORMERS WITH SCALED DOT PRODUCT ATTENTION (SDPA)では、CUDAインプットに対して、以下の3つの手法から最もらしいものが選ばれ、SDPAが行われると書かれています。
- Flash Attention
- Memory-Efficient Attention
- A PyTorch implementation defined in C++
また、新たなSDPAは「torch.nn.MultiheadAttention」や「torch.nn.TransformerEncoderLayer」のも適用されていると書かれています。早速、学習中のモデルをPytorch2.0に変換し、Flash Attentionの良さを楽しもうとしていました。しかし、モデル性能の改善は感じられず、調べた結果以下のような制約に気づきました。
Flash Attentionを使うためには、
- データ形式として、ffloat16 and bfloat16を使うこと。
- Cuda Device Propertyが対象であること。
- Maskを使わないこと。(Triangular Matrixは可能)
他にも、Batch SizeやHeadの数・サイズに関する制約がありますが、詳細はAccelerated PyTorch 2 Transformersをご参考ください。
対策として、Flash AttentionのオフィシャルCodeを利用することも可能ですが、GPUの制約「Turing, Ampere, Ada, or Hopper GPUs (e.g., H100, A100, RTX 3090, T4, RTX 2080)」やHead Dimensionsの制約などは存在します。
ミニテスト
以下の3つのモデルを用いた簡単なミニテストを行ってみました。
- Pytorch2.0 Multi Head Attention
- Pytorch2.0 SDPAを用いた Custom Multi Head Attention
- Official Flash Attentionを用いた Multi Head Attention
Input形は(32, 128, 500)であり、Sequenceサイズが500、Train Stepは100にしました。
オプション無しの擬本的なAttention
Triangular Matrixや他のマスキング、Dropoutのオプションを付けずにテストしました。結果、Originalモデルより3つのモデル全部、学習速度の改善がありました。
----------------------------------------------------------
dropout_p: 0.0, attn_mask_is_none: True
----------------------------------------------------------
Original Multi Head Attention
265132.048
----------------------------------------------------------
Pytorch2.0 Multi Head Attention
102817.892
----------------------------------------------------------
Pytorch2.0 SDPAを用いた Custom Multi Head Attention
100210.796
----------------------------------------------------------
Official Flash Attentionを用いた Multi Head Attention
107506.928
----------------------------------------------------------
Dropoutオプション追加
Dropoutオプションを追加した結果では、Pytorch2.0 Multi Head Attentionを用いた手法が、Original Multi Head Attentionと同じ速度を表しました。Pytorchのコードを見た限り、Dropoutに関する制約は無さそうですが、結果的には従来の手法を使った学習を行なった感じです。
----------------------------------------------------------
dropout_p: 0.0, attn_mask_is_none: False
----------------------------------------------------------
Pytorch2.0 Multi Head Attention
249348.034
----------------------------------------------------------
Pytorch2.0 SDPAを用いた Custom Multi Head Attention
100304.358
----------------------------------------------------------
Official Flash Attentionを用いた Multi Head Attention
95603.849
----------------------------------------------------------
Maskオプション追加
Maskを作り、Attentionタスクでマスキングを行うように設定しました。Triangular Matrix(is_casual)以外のマスキングは支援して無いため、Pytorch2.0の手法ではOriginal Multi Head Attentionと同様な性能を見せました。
----------------------------------------------------------
dropout_p: 0.1, attn_mask_is_none: True
----------------------------------------------------------
Pytorch2.0 Multi Head Attention
242825.850
----------------------------------------------------------
Pytorch2.0 SDPAを用いた Custom Multi Head Attention
242832.022
----------------------------------------------------------
Official Flash Attentionを用いた Multi Head Attention
90324.201
----------------------------------------------------------
Pytorch2.0のFlash Attentionを使ってみた感想
意外と制約があり、SDPAをベースにカスタマイズする必要があると思いました。特にBatch内で異なる長さを持つデータを処理するためにはMaskが必要であり、単純にAttention関数を変換するだけでは応用できないのではないかと思いました
また、自動で「Flash Attention・Memory-Efficient Attention・Original Attention」の中で実行されるので、どのような手法が使われているかをしっかり確認しながら試す必要があると思います。
Discussion