Fluent Bit の Multiline Parser を使用して複数行ログを収集する
はじめに
JSON 形式でログを出力している場合はあまり気にならないかもしれませんが、テキスト形式でログを収集する場合は複数行にまたがったログの考慮が必要です。今回は Fluent Bit の Multiline Parser を使用して、複数行ログをひとつにマージする実装例を紹介します。
なお、FireLens を使用する前提です。FireLens の基本的な情報については以前公開したナレッジを参照ください。
FluentBit の処理の流れ
実装にあたり、FluentBit の処理の流れをおさらいしておきます。

いろいろ省略していますが、
- ログを受け取る
- ログに対してなんらかの処理を行う
- ログを出力する
というのが Fluent Bit の基本的な動きです。
FluentBit は[INPUT]セクションで受け取ったログに対して 1 行ずつ[FILTER]セクションの処理内容を実行していきます。複数の[FILTER]セクションを記述した場合は、コンフィグファイルの上から順番に適用される仕様となっています。
複数行にまたがるログを Fluent Bit で扱う場合は、Multiline Parser でひとつにまとめることができます。Multiline 対応を行う前にどんな処理を行なっても、2 行目以降のログを適切に処理できません。そのため[FILTER]セクションの先頭に Multiline Parser の定義を記述しましょう。
Multiline Parser の設定
基本的な処理の流れをおさらいできたら、以下の公式ドキュメントを参考にしながら Multiline Parser の設定方法を見ていきましょう。
以下のようなログを対象とします。
Dec 14 06:41:08 Exception in thread "main" java.lang.RuntimeException: Something has gone wrong, aborting!
at com.myproject.module.MyProject.badMethod(MyProject.java:22)
at com.myproject.module.MyProject.oneMoreMethod(MyProject.java:18)
at com.myproject.module.MyProject.anotherMethod(MyProject.java:14)
at com.myproject.module.MyProject.someMethod(MyProject.java:10)
at com.myproject.module.MyProject.main(MyProject.java:6)
まずは[SERVICE]セクションで使用するパーサーファイルを指定します。
[SERVICE]
flush 1
log_level info
parsers_file parsers_multiline.conf
[SERVICE]セクションで指定したファイル名でパーサーファイルを新規作成し、パーサー定義を記述します。なお、パーサー定義はメインのコンフィグファイルに直接記述できません。必ず別ファイルを作成してparsers_fileで指定しましょう。
次に、パーサーファイルに[MULTILINE_PARSER]セクションを記述します。
[MULTILINE_PARSER]
name multiline-regex-test
type regex
flush_timeout 1000
#
# Regex rules for multiline parsing
# ---------------------------------
#
# configuration hints:
#
# - first state always has the name: start_state
# - every field in the rule must be inside double quotes
#
# rules | state name | regex pattern | next state
# ------|---------------|--------------------------------------------
rule "start_state" "/^(\w{3}\s\d{2}\s\d{2}\:\d{2}\:\d{2})(.*)$/" "cont"
rule "cont" "/^\s+at.*/" "cont"
start_stateは必須です。1 行目を識別するためのログフォーマットを指定します。next stateには続く 2 行目以降で出力されるログのフォーマットを指定します。
上記は Java のスタックトレースを想定したサンプル定義ですが、2 行目以降に出現するログのフォーマットが特定できないようなケースもあります。そういう場合は以下のように 1 行目と排他になるような定義でも機能します。
[MULTILINE_PARSER]
name multiline-regex-test
type regex
flush_timeout 1000
rule "start_state" "/^(\w{3}\s\d{2}\s\d{2}\:\d{2}\:\d{2})(.*)$/" "cont"
rule "cont" "/^(?!\w{3}\s\d{2}\s\d{2}\:\d{2}\:\d{2})(.*)$/" "cont"
あとは[FILTER]セクションで対象ログに付与されたタグをひっかけて、multiline.parserに適用するパーサーを指定すれば OK です🙌
[FILTER]
name multiline
match *
multiline.key_content log
multiline.parser multiline-regex-test
最後に、FireLens を使用する場合はコンフィグファイルとパーサーファイルを Fluent Bit のコンテナイメージにコピーして使用します。
FROM public.ecr.aws/aws-observability/aws-for-fluent-bit:latest
ADD parsers_multiline.conf /parsers_multiline.conf
ADD extra.conf /extra.conf
特殊なケースの考慮
ここからは少し特殊なケースについて解説します。
Multiline と Rewrite Tag を併用する場合
[FILTER]セクションがひとつしか存在しない場合は*のような雑なワイルドカードでも問題ありませんが、Multiline と Rewrite Tag を同時に使用する場合は、少なくとも Multiline の条件に*を使用できません。どういうことかというと、Multiline と Rewrite Tag はどちらも処理したログをパイプラインの先頭に再入力する仕様があります。
Logs will be re-emitted by the multiline filter to the head of the pipeline
The way it works is defining rules that matches specific record key content against a regular expression, if a match exists, a new record with the defined Tag will be emitted, entering from the beginning of the pipeline.
Multiline / Rewrite Tag はログを受け取ると、そのログが自分自身で処理した結果戻ってきたものかどうかを判定し、該当する場合は処理をスキップします。これは無限ループしないようにするための処理ですが、同じように先頭から再処理を行うプラグインが複数あるとそれがうまく機能せず、お手玉状態になってしまうということのようです。
分かりにくいと思うので以下の図で示します。③のあとに②に戻ってしまうイメージです。
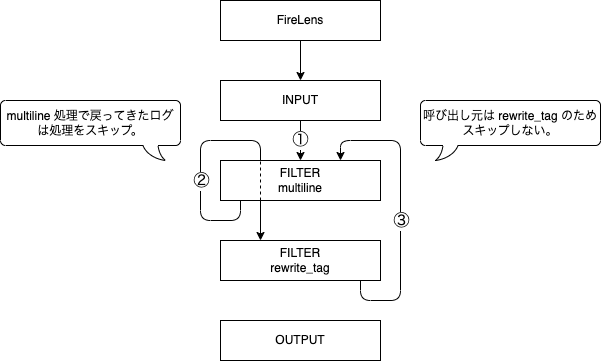
そのため Multiline と Rewrite Tag を併用する場合は、 Rewrite Tag で変更した後のタグが Multiline の条件に一致しないよう注意しましょう。
複数の Multiline Parser 使用する場合
FireLens は Fluent Bit で収集したログに{container name}-firelens-{task ID}というタグを付与する仕様のため、あるコンテナ上で生成されたログには必ず同じタグが設定されます。
例えば Java アプリケーションを実行するコンテナがあったとして、Java が出力するログと Tomcat が出力するログではフォーマットが異なるはずです。それらに別々の Multiline Parser を適用する場合は、Fluent Bit プラグインの挙動を理解していないとうまくいきません。
今回は例として Java と Python の実行環境をひとつのコンテナにまとめる前提(そんな構成ないと思うけど)で、それぞれのスタックトレースを取得することを検討します。さらに、Rewrite Tag を使用してそれぞれのログに異なるタグを付与してみましょう。
サンプルログは適当にこちらから拝借します。
2019-08-14 14:51:22,299 ERROR [http-nio-8080-exec-8] classOne: Index out of range
java.lang.StringIndexOutOfBoundsException: String index out of range: 18
at java.lang.String.charAt(String.java:658)
at com.example.app.loggingApp.classOne.getResult(classOne.java:15)
at com.example.app.loggingApp.AppController.tester(AppController.java:27)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.springframework.web.method.support.InvocableHandlerMethod.doInvoke(InvocableHandlerMethod.java:190)
at org.springframework.web.method.support.InvocableHandlerMethod.invokeForRequest(InvocableHandlerMethod.java:138)
2019-08-01 18:58:05,898 ERROR:Exception on main handler
Traceback (most recent call last):
File "python-logger.py", line 9, in make_log
return word[13]
IndexError: string index out of range
1 点目の注意点として、複数の Multiline Parser を使用する場合は、multiline.parserにカンマ区切りで複数のパーサー定義を記述します。
[FILTER]
Name multiline
Match container-firelens-*
multiline.key_content log
multiline.parser multiline-regex-java, multiline-regex-python
以下のように複数の[FILTER]セクションを記載するのは間違いで、Multiline と Rewrite Tag を併用する場合で説明したのと同じ理由で無限ループに突入し、Multiline 処理が終わらないためログが出力されなくなってしまいます。
[FILTER]
Name multiline
Match container-firelens-*
multiline.key_content log
multiline.parser multiline-regex-java
[FILTER]
Name multiline
Match container-firelens-*
multiline.key_content log
multiline.parser multiline-regex-python
パーサーファイルは以下のような設定になります。
[MULTILINE_PARSER]
name multiline-regex-java
type regex
flush_timeout 1000
rule "start_state" "/^(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}) (\S+) (\[\S+\]) (.*)$/" "cont"
rule "cont" "/^(?!(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}))(.*)$/" "cont"
[MULTILINE_PARSER]
name multiline-regex-python
type regex
flush_timeout 1000
rule "start_state" "/^(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}) (\S+)\:(.*)$/" "cont"
rule "cont" "/^(?!(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}))(.*)$/" "cont"
multiline-regex-javaとmultiline-regex-pythonのcontルールに注目してください。
Fluent Bit は受け取ったログを 1 行ずつ順番に処理していきます。contルールにマッチするログを受け取っている限り、直前のログにマージする挙動をとります。これにより、例えば Java ログの後に Python ログを受け取った場合に、そのログがmultiline-regex-javaのcontルールにマッチしてしまうと Java ログの 2 行目以降としてマージされてしまいます。
こちらも少しでも伝わるように図にしてみました。結局わかりにくいですけど😇
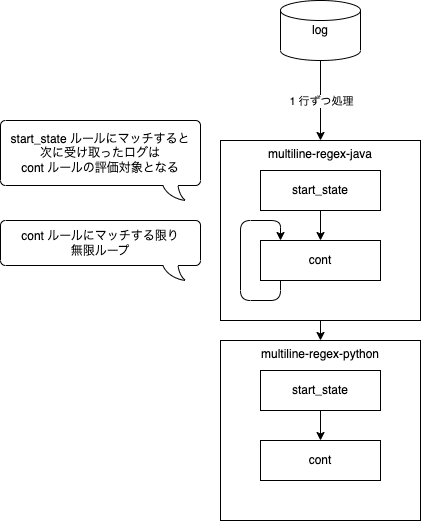
Multiline 対応から抜け出して新規のログイベントとして処理させるには、Python ログの 1 行目はmultiline-regex-javaのcontルールにマッチしてはいけません。逆のパターンも同様です。
そのため、この実装例では各 Multiline Parserのcontルールに Java と Python 両方のログの 1 行目を表すログフォーマットにマッチしない正規表現を定義しています(両方のログが同じ形式のタイムスタンプ(yyyy-MM-dd HH:mm:ss,fff)で始まるため、それを否定する正規表現を設定しています)。
この場合のコンフィグファイルは以下のような内容になります。
[SERVICE]
Flush 1
Log_Level info
Parsers_File parsers_multiline.conf
[FILTER]
Name multiline
Match container-firelens-*
multiline.key_content log
multiline.parser multiline-regex-java, multiline-regex-python
[FILTER]
Name rewrite_tag
Match container-firelens-*
Rule $log "^(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}) (\S+) (\[\S+\]) (.*)$" java false
[FILTER]
Name rewrite_tag
Match container-firelens-*
Rule $log "^(\d{4}\-[0-9]{2}-[0-9]{2} [0-9]{2}\:[0-9]{2}\:[0-9]{2}\,[0-9]{3}) (\S+)\:(.*)$" python false
multi-config を使用する場合
いつの間にか multi-config という機能がサポートされていました。initタグがついた特殊なコンテナイメージを使用することで、S3 に保管したカスタム設定ファイルを読み込むことができます。さらにカスタム設定ファイルがパーサーファイルの場合は@INCLUDEせずに-Rオプションで読み込んでくれるみたいです。便利ですね👍
これまで S3 上のカスタム設定ファイルを読み込む機能は、コンテナ実行環境が Fargate の場合は利用できませんでした。みなさん待望の機能ではないでしょうか。
ただし、2023/8 時点では[MULTILINE_PARSER]セクションをパーサーファイルとして扱ってくれないバグがあるようです。Multiline Parser を使用する場合は注意しましょう。
おわりに
Multiline 対応は運用性を考慮するとほぼ必須と言って良いとほど重要な設計要素です。
ただし、Multiline 対応を行うことで必然的にエラーログのサイズが大きくなります。Fluent Bit を含む多くのログコレクターは小さなサイズのデータを効率的に処理することに長けています。大きいサイズのデータを扱う場合はバッファーサイズのチューニングが必要となる点に留意しましょう。
今期は業務で Fluent Bit を扱うことが多かったです。今後も少しずつナレッジを共有していきたいと思います👍
Discussion