バグ調査メモ:issue #3 rpnコマンドを実行すると、CallApp関数でOSがダウンする(「ゼロからのOS自作入門」)
概要
書籍の「20.2 OSを守ろう(1)」のところで発生した問題の調査メモ
rpnコマンドを実行すると、CallApp関数でOSがダウンする。
リポジトリ
tag
issue
ここでの調査が終わったら整理して上記にまとめる。
現時点で判明していること
- 20.3 のTSSを実装したタイミングで、問題は解消された。
予想
- 書籍では、20.2ではうまくすり抜けてダウンしなくなるはず(書き込み対象の0xffffffffffffffffも自分でメモリ確保している)だったが、なんらかの原因でちゃんと落ちた?
- RSP=0だったとき、スタックがマイナス方向にオーバーフローして、0xffffffffffffffffに書き込むかと思いきや、そのままそのタイミングでダウンしているのではないか?
目標
- ホントにそうなのか、裏とりのため、落ちた瞬間の状態をデバッガでみたい。
とりあえずデバッグ環境整備から
M1 MacでのMikanOSのデバッグ方法は、@hideo130さんのQiita記事 M1 Macでソースコードを見ながら「ゼロからのOS自作入門」のデバッグをする。 を参考にさせていただいて、できた。多謝!
ソースをうまく読んでくれなかったけど、CLIのLLDBでは、source-mapの設定をやればうまくいった!
参考:
どうせならVSCodeでデバッグできるようにしたい。
VSCode拡張の CodeLLDBでは、launch.jsonにsourceMapを入れれば、ソース解決できるらしいけど、なんかうまくいかない。
参考:
まずはCallAppがちゃんと動いているか確認
- lldbでCallAppにブレークポイントをおいて、rpnコマンドを実行。
(lldb) b CallApp
(lldb) ni
0x10e9cf <+0>: pushq %rbp
0x10e9d0 <+1>: movq %rsp, %rbp
0x10e9d3 <+4>: pushq %rcx
0x10e9d4 <+5>: pushq %r9
0x10e9d6 <+7>: pushq %rdx
0x10e9d7 <+8>: pushq %r8
0x10e9d9 <+10>: lretq
→ 想定どおり、逆アセンブルして表示したニーモニックは、asmfunc.asm で実装したCallAppの通りになっている。
lretqの先に進むとrpnコマンドの実行コードに飛んでいるのか確認
- rpnコマンドをobjdumpコマンドで逆アセンブルする。
0000000000000060 <main>:
60: 55 push %rbp
61: 48 89 e5 mov %rsp,%rbp
64: 41 57 push %r15
66: 41 56 push %r14
68: 41 55 push %r13
6a: 41 54 push %r12
6c: 53 push %rbx
6d: 50 push %rax
6e: 49 be 00 00 00 00 00 movabs $0x0,%r14
75: 00 00 00
78: 41 c7 06 ff ff ff ff movl $0xffffffff,(%r14)
7f: 83 ff 02 cmp $0x2,%edi
82: 0f 8c fa 00 00 00 jl 182 <main+0x122>
88: 48 89 f3 mov %rsi,%rbx
8b: 89 f8 mov %edi,%eax
8d: 48 89 45 d0 mov %rax,-0x30(%rbp)
91: 41 bf 01 00 00 00 mov $0x1,%r15d
97: 49 bd 00 00 00 00 00 movabs $0x0,%r13
9e: 00 00 00
a1: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
a8: 00 00 00
ab: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
b0: 4a 8b 3c fb mov (%rbx,%r15,8),%rdi
b4: 48 be 00 00 00 00 00 movabs $0x0,%rsi
bb: 00 00 00
be: 41 ff d5 callq *%r13
c1: 85 c0 test %eax,%eax
c3: 74 4b je 110 <main+0xb0>
c5: 4a 8b 3c fb mov (%rbx,%r15,8),%rdi
c9: 48 be 00 00 00 00 00 movabs $0x0,%rsi
d0: 00 00 00
d3: 4d 89 ec mov %r13,%r12
d6: 41 ff d5 callq *%r13
d9: 85 c0 test %eax,%eax
db: 74 63 je 140 <main+0xe0>
dd: 4a 8b 3c fb mov (%rbx,%r15,8),%rdi
e1: 48 b8 00 00 00 00 00 movabs $0x0,%rax
e8: 00 00 00
eb: ff d0 callq *%rax
ed: 49 63 16 movslq (%r14),%rdx
f0: 48 8d 4a 01 lea 0x1(%rdx),%rcx
f4: 41 89 0e mov %ecx,(%r14)
f7: 48 bf 00 00 00 00 00 movabs $0x0,%rdi
- lldbでCallAppの最後lretqに到達後、siで次に進んだあとのニーモニックをみてみる。
0xffff800000001060: pushq %rbp
0xffff800000001061: movq %rsp, %rbp
0xffff800000001064: pushq %r15
0xffff800000001066: pushq %r14
0xffff800000001068: pushq %r13
0xffff80000000106a: pushq %r12
0xffff80000000106c: pushq %rbx
0xffff80000000106d: pushq %rax
0xffff80000000106e: movabsq $-0x7fffffffd890, %r14 ; imm = 0xFFFF800000002770
0xffff800000001078: movl $0xffffffff, (%r14) ; imm = 0xFFFFFFFF
0xffff80000000107f: cmpl $0x2, %edi
0xffff800000001082: jl 0xffff800000001182
0xffff800000001088: movq %rsi, %rbx
0xffff80000000108b: movl %edi, %eax
0xffff80000000108d: movq %rax, -0x30(%rbp)
0xffff800000001091: movl $0x1, %r15d
0xffff800000001097: movabsq $-0x7fffffffee40, %r13 ; imm = 0xFFFF8000000011C0
0xffff8000000010a1: nopw %cs:(%rax,%rax)
0xffff8000000010ab: nopl (%rax,%rax)
0xffff8000000010b0: movq (%rbx,%r15,8), %rdi
0xffff8000000010b4: movabsq $-0x7ffffffffe9e, %rsi ; imm = 0xFFFF800000000162
0xffff8000000010be: callq *%r13
0xffff8000000010c1: testl %eax, %eax
0xffff8000000010c3: je 0xffff800000001110
0xffff8000000010c5: movq (%rbx,%r15,8), %rdi
0xffff8000000010c9: movabsq $-0x7ffffffffea0, %rsi ; imm = 0xFFFF800000000160
0xffff8000000010d3: movq %r13, %r12
0xffff8000000010d6: callq *%r13
0xffff8000000010d9: testl %eax, %eax
0xffff8000000010db: je 0xffff800000001140
0xffff8000000010dd: movq (%rbx,%r15,8), %rdi
0xffff8000000010e1: movabsq $-0x7fffffffee60, %rax ; imm = 0xFFFF8000000011A0
0xffff8000000010eb: callq *%rax
おお!一致している!
ちゃんとrpnコマンドの実行は走っている様子。
最後のcallq *%raxの先で動く処理でダウンする様子
上記の最後の命令callq *%raxを実行したその先の〜、以下の命令でMikanOSがダウンしている様子。
(lldb)
Process 1 stopped
* thread #1, stop reason = instruction step over
frame #0: 0xffff80000000134f
-> 0xffff80000000134f: leal -0x30(%r8), %ebp
leal命令は、演算後の代入をする
ebp = r8 - 0x30
r8 = 0x0000000000000032
となっている。rbpにCPL=0の前半のアドレスを入れることになり、落ちている?
このあといろいろやって、状況整理
-
callq *%raxは、おそらくatol()を呼んでいる。外部ライブラリを呼んでしまっているので詳細よくわからない。 - 試しにr8を適当な後半アドレス0xffffffffffffffffとかにしてみたら、動いたが、その先の処理で結局ダウンする
- atol()で変換させずに固定の数字3とかにしても、同様にその先の処理で結局ダウンする
- 「その先の処理で結局ダウンする」というのは、「ni」で延々と進んでもダウンせず、「c」で続きを実行させるとダウンするので、ダウンするときの直接的な場所を調べられない。
降参して本家のソースを使わせてもらう
- 結局お手上げ状態なので降参して、本家MikanOSのosbook_day20bのソースをつかって動作させてみる。
- ビルドして実行してみたが、rpnコマンドの無限ループがちゃんと走ってOSはダウンしない
- ええ〜、、、、くやしい!
しかたないので、差分をチェックし始める
- 写経しているので、ほぼ同じソースになっているはずなのだが、とはいえやっぱり本家との結構な差がある。
- 怪しい箇所のソース・ファイルから完全一致させて、ビルド、再現確認を繰り返す...。
- 怪しいterminal.cppやtask.cpp、segment.cppとかどれもこれも、原因となる処理はつくりこんでいなくてびっくり。いくらやっても犯人がみつからない...。(つらい。連休がおわっちゃう。)
- 大幅な時間を費やして、ついに原因がlayer.cppのInitializeLayer()関数にあることが判明!
以下の1行の処理が抜けていたことが原因だった。
void InitializeLayer() {
(中略)
active_layer = new ActiveLayer{*layer_manager};
layer_task_map = new std::map<unsigned int, uint64_t>; /* !!!!! この行 !!!!! */
}
なんじゃこりゃー、なんでこんなまったく関係なさそうなところが関連しているのだ
というか、よくこの行なくても今まで動いていたな!
というわけで、めでたくこの1行の追加でこのissueは解消されてしまった。
疑問点を解消させたい
- layer_task_mapグローバル変数は、16.1でターミナルにキー入力を受け付けるために入れたもの。ターミナルインスタンスと、タスクをマッピングする変数。
- ここでいれたCPL=3で実行させる処理と関連しないように思える。
- 「これで問題発生しなくなったので、解決!」といわれてもまったく納得できない。
- 以下の疑問点を解消すべく、さらに調査することにする。
- (1).いままでlayer_task_mapをnewしなくても動作できていた理由
- (2).layer_task_mapをnewすることで、今回のCPL=3でのアプリ実行でOSがダウンしなくなった理由
- (3).20.3 でTSSを設定したら、ダウンしなくなった理由
- (4).散々やってもダウン箇所をつかまえられなかった理由
- (5).atol()の処理中にダウンした理由、修正後ダウンしなくしなくなった理由
(1).いままでlayer_task_mapをnewしなくても動作できていた理由
- lldbでnewしなかったときのlayer_task_mapを参照してみたところ、nullptr=0x0000'0000'0000'0000だった。
(lldb) p layer_task_map
(std::map<unsigned int, unsigned long, std::less<unsigned int>, std::allocator<std::pair<const unsigned int, unsigned long> > > *) $0 = nullptr
- layer_task_mapに、ターミナルのレイヤーIDとタスクIDのマッピングをinsertする処理は、TaskTerminal関数で実装されている。
void TaskTerminal(uint64_t task_id, int64_t data) {
__asm__("cli"); // 割り込みを抑止
Task& task = task_manager->CurrentTask();
Terminal* terminal = new Terminal;
layer_manager->Move(terminal->LayerID(), {100, 200});
active_layer->Activate(terminal->LayerID());
// ターミナルタスクを検索表に登録する
layer_task_map->insert(std::make_pair(terminal->LayerID(), task_id));
__asm__("sti"); // 割り込みを許可
- 上記の箇所でnullptr=0x0000'0000'0000'0000へのinsertが走ったときに、フツウなら触ってはいけないメモリ領域をつかうのでコケそうなものだが、以下の理由で今の今までずっと使えてしまったものと思われる。
- 本来UEFIが使用する領域※であるため、カーネルが使用する領域外=memory_managerの管理外であり、他の処理でつかわれることがなければ、うまく動作してしまう?
※以下のように、memmapファイルの最初にEfiBootServiceCodeとして書かれている
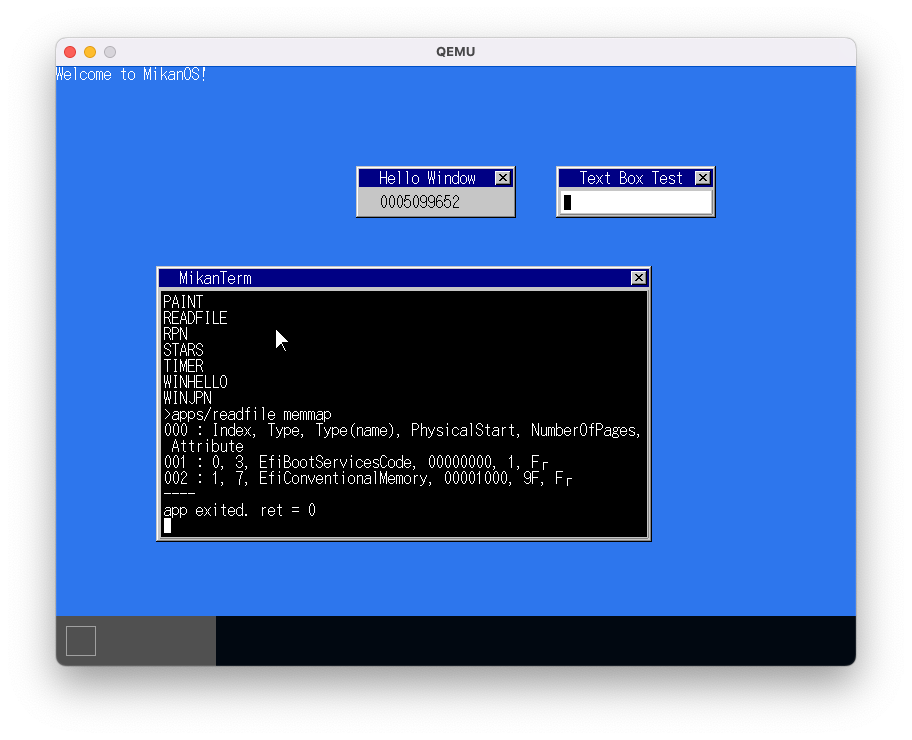
- 0x0000'0000'0000'0000は仮想アドレスなので、対応する物理フレームが書き込み可の設定でページ割当されているかはよくわからないが、使えちゃうということは多分そういうこと?
- 本来UEFIが使用する領域※であるため、カーネルが使用する領域外=memory_managerの管理外であり、他の処理でつかわれることがなければ、うまく動作してしまう?
(2).layer_task_mapをnewすることで、今回のCPL=3でのアプリ実行でOSがダウンしなくなった理由
- 上記(1)のとおり、layer_task_mapをnewすると、メモリ領域0x0000'0000'0000'0000が汚染されなくなるため。
- TSSは、TRレジスタが指すメモリ領域にあることになっているが、未設定のため、メモリ領域0x0000'0000'0000'0000がTSSということになっている。(書籍 P.468を参考)
- このTSS中にあるTSS.RSP0を、RSPレジスタ=スタック領域にする。0x0000'0000'0000'0000が汚染されていると、TSS.RSP0が変な値になり、つかってはいけない領域をスタック領域に設定してしまう。つかってはいけない領域がCPL=0の場所であれば、CPL=3から使おうとすると#GP一般保護例外でダウンする。
- 汚染されていない場合は、TSS.RSP0が0x0000'0000'0000'0000になり、書籍にかかれているようにマイナス方向にオーバーフローして、コマンドライン引数のために確保したメモリ領域0xffff'ffff'ffff'f000 〜 0xffff'ffff'ffff'ffffあたりがつかわれるので、ダウンしない。
- ちなみにちゃんとnewしたあとの、layer_task_mapは以下の場所
(std::map<unsigned int, unsigned long, std::less<unsigned int>, std::allocator<std::pair<const unsigned int, unsigned long> > > *) $0 = 0x0000000000fc8960 size=0
(3).20.3 でTSSを設定したら、ダウンしなくなった理由
- 上記(2)のとおり、TSSがちゃんと確保されたスタック領域を指すようになれば、layer_task_mapがnewされておらず0x0000'0000'0000'0000が汚染されたとしても、そもそもその汚染された場所を触ることがないため、ダウンしなくなる。
(4).散々やってもダウン箇所をつかまえられなかった理由
- CPLが下がる変更をともなう割り込み処理がおきたときに、TSSを読んでスタック領域を差し替える処理が入る(と理解している)
- ブレークポイントをIntHandlerLAPICTimer()関数においていたが、当然ながらそのときすでにTSS.RSP0を読み込んだ差し替えが走った後。つまりその前の本当にCPU割り込みが発生した直後をブレークポイントで止められないとダウン時の動きが追えない。
- よって、RSPレジスタの値が不正だと、IntHandlerLAPICTimer()関数に入る前に、不正なスタック領域への書き込みが走ってCPU例外が発生してOSがダウンしてしまうので、止められなかった。
- 以下は、修正してダウンしなくなってからIntHandlerLAPICTimer()関数にブレークポイントをおいたときの動作。ちゃんとRSPが、後半のアドレスになっている。
* thread #1, stop reason = breakpoint 3.1
frame #0: 0x000000000010ee78 kernel.elf`(anonymous namespace)::IntHandlerLAPICTimer(frame=0xffff800000001180) at interrupt.cpp:83:5
80 __attribute__((interrupt))
81 void IntHandlerLAPICTimer(InterruptFrame* frame) {
82 // タイマー割り込み時の動作を呼び出す。割り込み処理の終了通知を呼び出し先でおこなう。
-> 83 LAPICTimerOnInterrupt();
84 }
85 }
86
Target 0: (kernel.elf) stopped.
(lldb) bt
* thread #1, stop reason = breakpoint 3.1
* frame #0: 0x000000000010ee78 kernel.elf`(anonymous namespace)::IntHandlerLAPICTimer(frame=0xffff800000001180) at interrupt.cpp:83:5
frame #1: 0xffff800000001180
(lldb) register read rsp
rsp = 0xfffffffffffffe80
- lldb力が足りないだけでもしかしたら、割り込み直後の命令で止める方法があるのかもしれない。
(5).atol()の処理中にダウンした理由、修正後ダウンしなくしなくなった理由
- タイマー割り込みでのコンテキストスイッチでダウンした理由は上記で説明できたが、rpnコマンドのatol()関数の処理中でもダウンするケースがあった。
(lldb)
Process 1 stopped
* thread #1, stop reason = instruction step over
frame #0: 0xffff80000000134f
-> 0xffff80000000134f: leal -0x30(%r8), %ebp
-
ここの処理は、layer_task_mapをちゃんとnewしてあげれば、ダウンしなくなった。
-
leal命令は、演算後の代入をする
ebp = r8 - 0x30
r8 = 0x0000000000000032
となっている。
ebpには、0x0000000000000002が入ることになるが、layer_task_mapをnewしないときにつかっている0x0000'0000'0000'0000に場所が近い。 -
layer_task_mapをnewすると、0x0000000000000002は未使用領域になるので、触っても良い??
-
layer_task_mapをnewしないと、0x0000000000000002はinsertしたレイヤーIDとタスクIDのstd::mapインスタンスへのポインタが入って使用中(CPL=0)になり、上記のatol関数の処理でCPL=0の領域を触ったことになってダウンした??
-
そもそもなんでこんなところ触るのだっけ、libcとかを静的リンクしてあるけどリンクオプションの
--image-base 0xffff800000000000は外部ライブラリとしてリンクしたものは関係ない?
うーん。すべての疑問が解決したわけではないけれど、ひとまずこのissueについては調査をここまでとしてまとめることにする。