encoding/json v2(候補)について紹介してundefined | null | Tを表現する
EDIT2025-06-12: GOEXPERIMENTAL=jsonv2でstd入りしたので書き直しました
はじめに
以前書いたGoのstruct fieldでJSONのundefinedとnullを表現するでは、jsoniterの Extension を駆使していろいろ頑張ることでundefined | null | Tを出し分けることが実現できることを確認しました。記事中では同様に、encoding/json/v2でstdライブラリとして同様のことができるようになるかもしれないということも触れました。
先日(2023-10-05T17:14:54Z)、記事内で触れたissue commentの筆者がencoding/json/v2というタイトルのdiscussionを作りました。
このdiscussionを経て正式なproposalを出す予定とのことですので、encoding/json/v2も今すぐではないですが具体的にリリースが見えてくる段階になっているようです。
1.22でmath/rand/v2がリリースされる予定ですので、順調にいけばおそらくスタンダードライブラリで二つ目のv2になります。
この記事ではencoding/json/v2の候補版の実装を用いて、以前の記事と同じように「struct fieldだけでundefined | null | Tを表現する」ことを実現します。
やること
この記事は以下を行います。
-
encoding/json/v2のモチベーションを紹介する -
encoding/json/v2の候補実装であるgithub.com/go-json-experiment/json(以降v2と呼ばれる)の実装やAPI構造を紹介する -
v2でstruct fieldのみでundefined | null | Tを実現する
想定読者
- Go programming language で encoding/jsonの機能を十分理解している人。
-
v1で痛しかゆしな思いをした人 -
v2が待ちきれない人
背景: なぜundefined | null | Tが表現できるとよいか
今日の多くのシステムは物理的、仮想的ネットワークによって連結される複数のプログラムからなり、プログラム間でデータを交換して協調してアプリケーションを構成します。
プログラム間のデータ交換フォーマットには様々な物がありますが、JSONはその中でももっとも広く使われているものの一つです。
The Go Programming LanguageではJSONとプログラム内の値との相互変換のために普通JSONのスキーマに合わせたstructを定義し、encoding/jsonパッケージを通して変換を行います。
JSONがJavaScriptに端を発するフォーマットであり、その事情を多分に含む一方で、Goが目指す方向の違いとencoding/jsonの特定の機能の欠落が、JSONがナチュラルにもつundefined(フィールドがない), null, T(=任意の型)をGoの型、struct fieldだけで表現することを妨げてしまいます。
undefined | null | Tがfieldのみで表現できないと一部の処理が煩雑になります。もっとも典型的な例の一つはJSONでPATCHリクエストを受け付けるAPIの実装であると考えられ、現状ではmap[string]anyに一旦デコードするなどの方法でフィールドの有無を事前に検査する必要があるはずです。
encoding/json/v2ではv1で欠落していた任意の値をエンコード時にスキップする機能が追加されることとなったため、v2ではundefined | null | Tを表現することができるようになります。
encoding/json/v2
モチベーション
- discussion: encoding/json/v2
ざっくりdiscussionの中で述べられるモチベーションを列挙します。かっこ(())で囲まれた部分は私の注釈です。
v2で解決したいv1の欠点を以下の4つの観点で述べる
- Missing Functionality
-
time.Timeのフォーマットを指定できない - 特定の値をomitできない
- (e.g.
time.Timeのzero valueをomitemptyでomitしたいのにstructには決してomitemptyが機能しない)
- (e.g.
-
sliceやmapがnilであるとき空のArray([]),Object({})を出力できない -
embed以外の方法で出力結果にGo typeをinlineできないこと
-
- API deficiencies
-
io.Readerからうまくjsonをdecodeする方法がない-
json.NewDecoder(r).Decode(v)がよくされるがこれは誤りである:Decodeは1つの有効なJSON valueだけを取り出すので、末尾にゴミデータがある場合にエラーにならない。- (エラーになってほしい場合、
Decodeを呼んだ後にdec.More()がtrueを返すときエラーを返すような処理をユーザーが書く必要があります)
- (エラーになってほしい場合、
-
-
Decoder,EncoderにOptionを設定する方法があるが(SetEscapeHTMLとかDisallowUnknownFieldsとかのこと)、json.Marhsal,json.Unmarshalにはない -
json.Compact,json.Indent,json.HTMLEscapeなどがbytes.Bufferを使っていること。より柔軟な[]byte,io.Writerなどを使わないこと。- (これは私も大分不思議に思っていました。私の使い方的には困らないので別によかったのですが、
[]byteやio.Writerを使うAPIのほうが驚きは少ないですね)
- (これは私も大分不思議に思っていました。私の使い方的には困らないので別によかったのですが、
-
- Performance limitations
-
MarshalJSONメソッドが返り値の[]byteをallocateすることを強制してしまう。同様に、このsemanticsはjsonパッケージに返り値のバリデーションと、インデント付けの両方で解析を必要としてしまう。- (
MarshalJSONの返り値をjson.Compactとほぼ同一の処理にかけ、最後にIndentをつける動作になっています。)
- (
-
UnmarshalJSONメソッドが一つの完全な、かつ、末尾にデータのないJSON valueを必要とする。jsonパッケージはUnmarshalJSONを呼び出す前に1つのJSON valueが終わるまで解析する必要があり、さらにUnmarshalJSONの実装もJSON valueを解析しなおすことになる。UnmarshalJSONの呼び出しが再帰してしまうと劇的なパフォーマンス低下をもたらす。 - streaming encoder APIが存在しない:
-
Encoder.EncodeTokenproposalは通過したが、実装はされていない(#40127) -
json.Tokenはinterfaceであるため、JSON numberやstringをbox化するときにallocateしてしまう。 - 理屈上最も大きなJSON Tokenのみバッファーすればよいはずだが、
Encoder.EncodeおよびDecoder.DecodeはJSON全体をバッファーしてしまう。
-
-
- Behavioral flaws
- 不適切なJSON構文の取り扱い: 時間とともにJSONに関する標準は増えている (RFC 4627, RFC 7159, RFC 7493, RFC 8259)。一般的に言って、これらのRFCは徐々により厳密な定義になっていっているが、
encoding/jsonは新しいRFCに適合していない。デフォルトの挙動は少なくともRFC 8259に従うべきである。このRFCはinvalidなUTF-8を許さない。- (Go v1のリリース日は2012-03-28であり、RFC 7159が2014-03、, RFC 7493は2015-03, RFC 8259は2017-12です)
- Unmarshal時のGo struct fieldとJSON objectのキー名とのマッチングがでcase-insensitiveである。
- underlying typeがnon-addressableである型の
MarshalJSON/UnmarshalJSONが呼ばれない。しかし、この挙動を修正することも破壊的変更である。 -
json.Unmarshal(data, &v)のターゲット(=v)がzero valueでない時に起きるマージの挙動に一貫性がない: 例えばnon-zeroなsliceを使用した場合、Unmarshal後のsliceのlengthとcapacityの間の値はゼロ化されずにマージされる。 - 一貫しないエラー値: 現在の
encoding/jsonの返すエラーは構造化されている部分とされていない部分があり一貫しない。実際には3つのクラスのエラーが起きるはずである: 文法エラー、意味論エラー、I/Oエラー。
- 不適切なJSON構文の取り扱い: 時間とともにJSONに関する標準は増えている (RFC 4627, RFC 7159, RFC 7493, RFC 8259)。一般的に言って、これらのRFCは徐々により厳密な定義になっていっているが、
Behavioral flawsの部分は破壊的変更なしに修正できないし、jsonパッケージにオプションという形で実装することはできるが、望ましい挙動がデフォルトでないことは不幸なことである。
デフォルトの挙動を変える必要性がv2の必要性を示唆する。
(キー名とのマッチングがcase-insensitiveなのかなり驚きました。
diff_test.goを見るとjson:"name"で名前を明確に指定していたとしてもcase-insensitiveなんですね。知らなかった。すごい驚きです。
discussionでv1の問題点が包括的に述べられていて面白いので気になる方はぜひ読んでみてください)
実装
- implementation: github.com/go-json-experiment/json
この記事では実装はすべて以下のコミットの状態で確認されています。
Commit: 2e55bd4e08b08427ba10066e9617338e1f113c53
Parents: 54c864be5b8da112b1492c72087512969f2fdea4
Author: Evan Jones <ej@evanjones.ca>
Committer: GitHub <noreply@github.com>
Date: Fri Nov 03 2023 08:28:22 GMT+0900 (Japan Standard Time)
構成
以下はdiscussion上に貼られたencoding/json/v2の構造を表した図への直リンクです
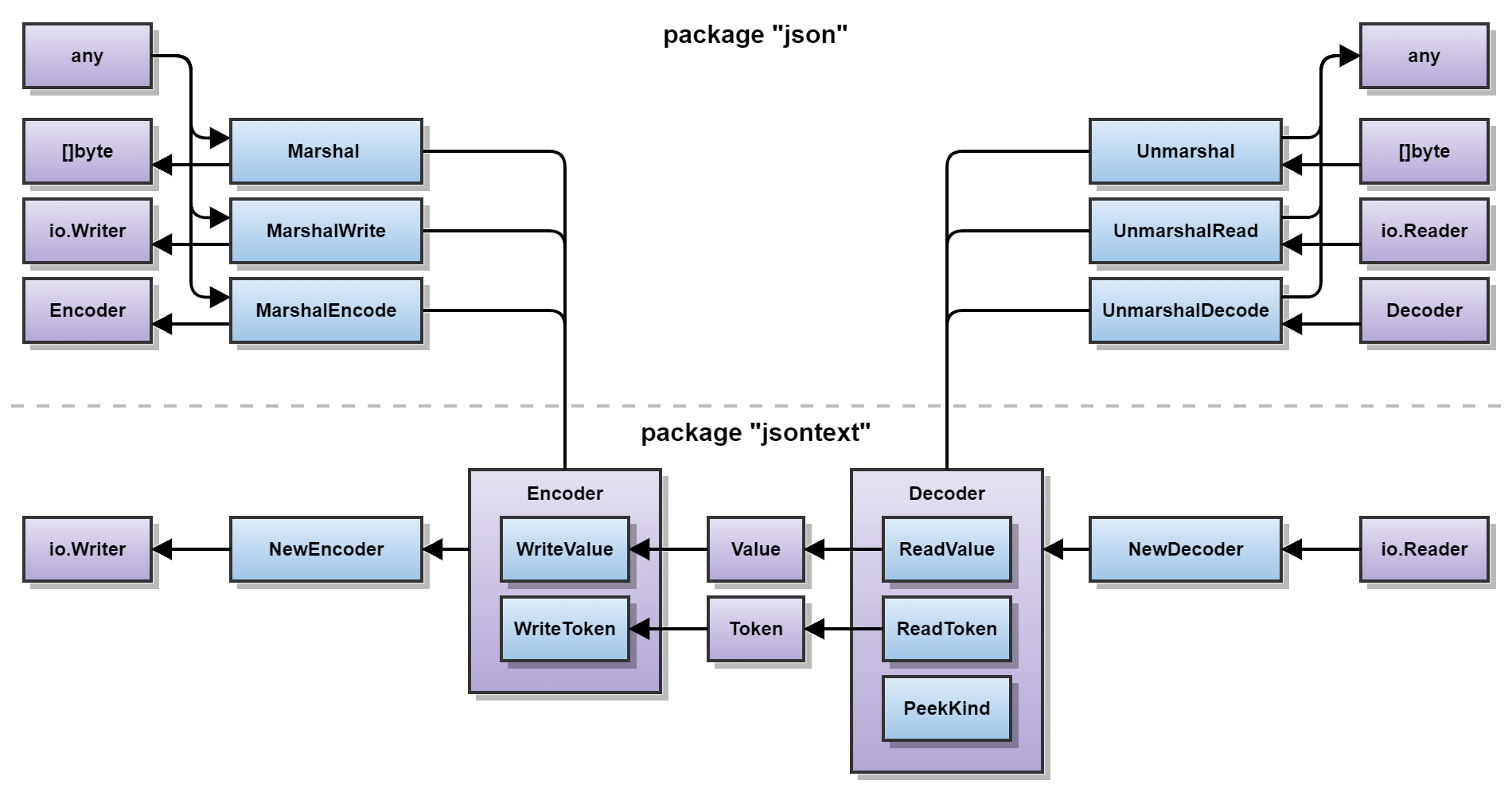
大分雰囲気が変わっています。
- jsonの文法的な変換を取り扱う
jsontextパッケージ - jsonの意味論的な変換を取り扱う
jsonパッケージ
の2つに分割されるようになり、Encoder / Decoderが中心的に取り扱われるようになりました。
jsonパッケージは従来通りreflectを通してmarshaler / unmarshalerを作成してsync.Mapにキャッシュするなどの挙動を行いますが、jsontextはjsonを[]byteやio.Reader / io.Writerから読み書きする機能のみを取り扱います。jsontextは「比較的軽量な依存ツリーであるのでTinyGo/ GopherJS / WASIのようなバイナリの肥大化が気になるアプリケーションに適している」とのことです。
Encoder / Decoderの間のやり取りはValue, Tokenとなるため、理屈上最も大きなJSON Token(長いstringとかですね)がバッファされるメモリの最大値となります。
Valueは[]byte、Tokenはstructであり、interfaceではないのでbox化によるmemory allocationは生じません。
方針
実装はdiscussionで述べられたv1のよくなかったところを改善し、v1から続くコアコンセプトである、unsafeを使わない、読みやすくセキュア、Easy to use(hard to misuse)をそのまま反映したようなものになっています。
-
time.Timeなどのフォーマットを指定できない =>json:",format:RFC3339"のようにstruct tag optionで指定できるように - 任意値をエンコード時にスキップできない =>
json:",omitzero"の追加 - 値のinline化 =>
json:",inline",json:",unknown"の追加-
inlineオプションをつけるとstructに別の型をembedしているのと同等のふるまいをします。 -
unknownもしくはinlineオプションが付いたフィールドの型がjsontext.Valueもしくはmap[string]Tの場合inline fallbackとして取り扱われるように- Go structのほかのフィールドのいずれにもマッチしないメンバーがすべてそのフィールドに格納されるようになります。
-
inline,unknownもお互いに似たようなことができますが、意味論的な違いがあります。-
DiscardUnknownMembers,RejectUnknownMembersなどのjsontext.Optionsを指定することでunknownはより柔軟な動作をします。
-
-
gopkg.in/yaml.v3はすでに似たようなオプションを有しています。v2で申し分ない相互運用性が得られます。
-
- streaming APIの不在 => Encoder / Decoderを引数に取るAPIの追加, Encoder / Decoderの再実装で本当にstreamingできるように
-
json.Tokenがinterfaceである =>jsontext.Kindはbyte,jsontext.Valueは[]byteすることで、それらを返す時にメモリがallocateされることがないように - 不適切なJSON構文の取り扱い => 新しいRFC準拠した挙動がデフォルトに
- non-addressableな型の
MarshalJSON/UnmarshalJSONが呼ばれない => reflect.ValueをembedしたaddressableValueのみを取り扱うように - エラーが一貫しない => SyntacticError, SemanticError, ioError
- モチベーションの中で述べられるI/O Errorは単純に
ioパッケージから提供されるエラーという意味で言っているっぽいですね。 -
io.Readerやio.Writerのcall siteを見てると(こことここ)、単純にそれらをラップして返しています。 -
*ioErrorはもちろんinterface { Unwrap() error }を実装しています。 - コードを検索すると
io.ErrUnexpectedEOFを返すところも多いので、Reader / Writerの返すエラー+io.ErrUnexpectedEOFをチェックしておけばI/O Errorを全部拾いきれますね。 - もしエラーをきちんと判別したいなら
io.Reader/io.Writerの実装で返しうるエラーを把握しておく必要があります。
- モチベーションの中で述べられるI/O Errorは単純に
Encoder / Decoder
v1ではencodeState, decodeStateというステーマシンを定義して、内部的にそれらを呼び出すことでそれらの挙動が実現されていました(json.Marshal, Encoder.Encode, json.Unmarshal, Decoder)。
v2でも同様にステートマシンを利用しますが、中身の実装そのものはだいぶ違った形相を呈しています。
jsontextパッケージで実装されるjsontext.Encoder, jsontext.Decoderはこれらをラップしたものとして定義されています。
ユーザーはjsontextの提供する高級なインターフェイスを操作してJSONをトークン単位で処理できます。
jsonパッケージはinternal packageとして定義されたexportを利用してステートマシンを取り出して利用していますね。
switch-caseを回避して直接バッファーを操作するのでそっちのほうが効率的だからでしょう。
Marshal / Unmarshal
v2ではMarshal/Unmarshalのみならず、MarshalWrite, MarshalEncode, UnmarshalRead, UnmarshalDecodeが追加され、用途に応じて使い分けられるようになりました。下記の通り、今まで通りのany -> []byteの変換、io.Writerへ直接書き込み、*jsontext.Encoderへの書き出しとそれぞれ対応しています。
Unmarshal, UnmarshalRead, UnmarshalDecodeも似たような感じなので省略。
v1ではMarshalJSON/UnmarshalJSONメソッドが呼び出しごとに[]byteの解析やallocationを必要とすることや、呼び出しごとにencodeState、decodeStateを作成することでパフォーマンス低下が起きていました。
また、(&json.Encoder{}).SetEscapeHTMLなどのoptionがMarshalJSON実装に伝搬しないことが問題でした。
v2では以下のように、MarshalJSONV2/UnmarshalJSONV2は*jsontext.Encoder/*jsontext.Decoderおよびjsontext.Optionsを受け取るデザインにすることでそれらを回避しています。
逆に、MarshalJSONV2/UnmarshalJSONV2を実装するためにはv2をimportしなければならなくなりました。
timeパッケージのimportを増やさないために、time.Timeとtime.Durationのmarshaler/unmarshalerはv2のjsonパッケージ内で行われています(arshal_time.go)
v2にはjson.MarshalFuncV2[T]およびjson.UnmarshalFuncV2[T]という、任意の型に対するMarshaler/Unmarshalerを差し替えるためのOptionを作成するための関数が提供されるため、importを増やしたくない場合には別のパッケージで作成することもできます。
ただしこれらの方法は型にMarshalJSONV2メソッドを実装するのとは異なる挙動をするため注意が必要です。
メソッドを実装した場合、ほかのstructにembedした際にそれらのメソッドがforwardされますが、time.TimeやMarshalFuncV2で差し替えられた挙動はforwardされません。
struct tag周りの挙動変更
すでにいくつか述べていますがstruct tag周りに大きな破壊的変更があります。
すべてのoptionはここを参照
詳細な挙動の変更はdiff_test.goを参照ください。
- optionの追加および挙動変更
-
omitzero: フィールドが型に対応する zero である場合、フィールドがMarshal時にスキップされる-
zero とは、
reflect.ValueOf(t).IsZero()がtrueを返すような値、もしくは型がinterface { IsZero() bool }を実装する場合、trueが返されるような値のことです。 -
time.Time{}.IsZeroがtrueを返す時フィールドをスキップしたいというような要望は多くあったのでそれに対応した実装です。
-
zero とは、
-
omitempty:omitzeroの追加に伴い、omitemptyはJSONとして empty な値をスキップするように変わりました-
epmty な値とは
null,"",{},[]のいずれかのことであり、MarshalJSONおよびMarshalJSONV2でこれらを返した場合にもskipされるようです。 -
jsontext.Value("null")とした場合でもスキップされます。 - ここに
0が含まれていないのはJSON的に0,-0,0.000などの複数のバリエーションで表現可能で定義としてあいまいなことと、0が有効な値であると思われることが多いからだそうです。(参考)
-
epmty な値とは
-
format:time.Timeや[]byteおよび[N]byteなどに任意のフォーマットを設定できます。- 今までは
time.Time{}が実装するMarshalJSONで定義されたtime.RFC3339Nano以外のフォーマットを利用したい場合はMarshalJSONを実装した新しい型を定義するほかなかったですが、v2ではstruct tagのみで設定できるようになりました。
- 今までは
-
format:emitnullを指定することで、nil sliceやnil mapがマーシャル時にnullを出力するようになります。 -
inline,unknown: モチベーションのところでも述べられていたインライン化するフィールドを指定するオプションです。map[string]anyなフィールドにinlineもしくはunknownオプションを付けておけば、structに定義されていない値はこのフィールドにすべて格納されます。
-
- single quoteでエスケープすることが許されるように
-
v1はstruct tagは単純にcomma-separatedな文字列であり、json:"'\,field\,'"のようなオプションは許されていませんでした。 - これは実際にはJSONのフィールドとしてはありえます。
-
v1ではtagの解析は以下のような実装でした。
// quoted from https://cs.opensource.google/go/go/+/refs/tags/go1.21.4:src/encoding/json/tags.go;bpv=0
// parseTag splits a struct field's json tag into its name and
// comma-separated options.
func parseTag(tag string) (string, tagOptions) {
tag, opt, _ := strings.Cut(tag, ",")
return tag, tagOptions(opt)
}
// Contains reports whether a comma-separated list of options
// contains a particular substr flag. substr must be surrounded by a
// string boundary or commas.
func (o tagOptions) Contains(optionName string) bool {
if len(o) == 0 {
return false
}
s := string(o)
for s != "" {
var name string
name, s, _ = strings.Cut(s, ",")
if name == optionName {
return true
}
}
return false
}
v2からはoptionはsingle-quoteによってescapeしてもよいcomma-separatedな文字列という扱いになるようです。
double-quotationの代わりにsingle-quotationを使う以外はstrconv.Quoteと同じ挙動であるとコメントされています。
めちゃくちゃ読みやすい
ざっくり大雑把に読み進めていますがv1に比べてものすごい読みやすいです。
長い知見の蓄積、歴史が浅いこと、それによってコンパイラの最適化をよりあてにできるようになったこと、セキュリティーが重視されるためパフォーマンスよりも可読性が優先されていることなどが要因であると思われます。
著者らの長年の検討の結果です。
例えば以下のfoldNameではmid-stack inlinerによってinline化可能なことが述べられていますが、
#19348のこのissueコメントを見ると、mid-stack inlinerの実装時期は2019-04-09のあたりのようです。コンパイラの発達によって関数を分割してもパフォーマンスが落ちにくくなりつつあるから読みやすいコードでも大丈夫になっているのだと思います(がコンパイラには全く詳しくないので多分そうなんだろうなぐらいの感想です)
すごく読みやすいのでこれ以上実装について記事内で説明する必要性を感じなくなってきましたのでこの辺にしておきます。
使ってみる
Marshal / Unmarshal
下記のような感じです。
json.Marshal, json.Unmarshalは末尾にvariadicなoptionが引数として取るようになっていますが、それ以外の使用感は変わりません。
この実装では内部的にプールからEncoder / Decoderを取り出して再利用します。見たところv1ではdecodeStateはプールされていませんでしたのでこの時点で効率化されています。
MarshalJSONV2, UnmarshalJSONV2メソッドははEncoder / Decoderを受けとるようになったので大分感触が違います。
package main
import (
"fmt"
"time"
"github.com/go-json-experiment/json"
"github.com/go-json-experiment/json/jsontext"
)
var (
defaultTime time.Time = time.Date(2002, time.April, 23, 0, 0, 0, 0, time.UTC)
)
var _ json.MarshalerV2 = (*foo)(nil)
var _ json.UnmarshalerV2 = (*foo)(nil)
// foo is an example type which wraps time.Time.
//
// foo marshals into JSON null if f is the default time value
// 2002-04-23T00:00:00.000000000Z,
// and will be unmarshaled from null to the default.
type foo struct {
time.Time
}
func (f *foo) MarshalJSONV2(enc *jsontext.Encoder, opt jsontext.Options) error {
if f.Time.Equal(defaultTime) {
return enc.WriteToken(jsontext.Null)
}
return json.MarshalEncode(enc, f.Time, opt)
}
func (f *foo) UnmarshalJSONV2(dec *jsontext.Decoder, opt jsontext.Options) error {
// PeekKindの返り値はjsontext.Kindです。
// 'n'はnullのことです。
if dec.PeekKind() == 'n' {
// SkipValueで値を読み飛ばしておきます。
err := dec.SkipValue()
if err != nil {
return err
}
f.Time = defaultTime
return nil
}
err := json.UnmarshalDecode(dec, &f.Time, opt)
if err != nil {
return err
}
return nil
}
func main() {
for _, f := range []foo{{Time: defaultTime}, {Time: time.Now()}} {
bin, err := json.Marshal(f)
if err != nil {
panic(err)
}
fmt.Printf("%s\n", bin)
f = foo{}
err = json.Unmarshal(bin, &f)
if err != nil {
panic(err)
}
fmt.Printf("%#v\n", f)
}
}
/*
null
time.Date(2002, time.April, 23, 0, 0, 0, 0, time.UTC)
"2024-01-11T12:48:37.661204014Z"
time.Date(2024, time.January, 11, 12, 48, 37, 661204014, time.UTC)
*/
ただし注意点として、struct tagをMarshalJSONV2 / UnmarshalJSONV2メソッドに引き回す方法はありません!
このコメントでのやり取りのとおり、過去の議論の結果見送られたらしいです。
jsontext.Encoder
WriteToken、WriteValueで値を書き込みますが、内部のステートマシンが状態を覚えているので:とか,とかを手動で書き込む必要はないです。これはいいデザインですね。
UnusedBufferでencoderStateに紐づくバッファーが利用できるので、これを利用するとよいというAPIのようです。内部のコメントを見るとencoderStateのバッファーの未使用の部分をsliceで返すような実装をしていたけどやめたようなことがコメントで書かれています。もしかしたら将来的にこのメソッドは消えるかもしれませんね。
package main
import (
"bytes"
"fmt"
"strings"
"github.com/go-json-experiment/json/jsontext"
)
func main() {
buf := new(bytes.Buffer)
enc := jsontext.NewEncoder(buf, jsontext.WithIndent(" "))
for _, t := range []jsontext.Token{
jsontext.ObjectStart,
jsontext.String("foo"),
jsontext.Null,
jsontext.String("baz"),
jsontext.ObjectStart,
jsontext.String("qux"),
jsontext.Int(123),
jsontext.String("quux"),
} {
err := enc.WriteToken(t)
off := enc.OutputOffset()
depth := enc.StackDepth()
k, length := enc.StackIndex(depth)
fmt.Printf("off = %d, kind = %s, depth = %d, length = %d, err = %v\n", off, k, depth, length, err)
}
v := enc.UnusedBuffer()
v = append(v, []byte(`[`)...)
v = append(v, []byte(`{"corge":null}`)...)
v = append(v, []byte(`]`)...)
_ = enc.WriteValue(v)
_ = enc.WriteToken(jsontext.ObjectEnd)
_ = enc.WriteToken(jsontext.ObjectEnd)
fmt.Println(buf.String())
depth := enc.StackDepth()
fmt.Printf("depth = %d\n", depth)
/*
off = 1, kind = {, depth = 1, length = 0, err = <nil>
off = 11, kind = {, depth = 1, length = 1, err = <nil>
off = 17, kind = {, depth = 1, length = 2, err = <nil>
off = 28, kind = {, depth = 1, length = 3, err = <nil>
off = 31, kind = {, depth = 2, length = 0, err = <nil>
off = 45, kind = {, depth = 2, length = 1, err = <nil>
off = 50, kind = {, depth = 2, length = 2, err = <nil>
off = 66, kind = {, depth = 2, length = 3, err = <nil>
{
"foo": null,
"baz": {
"qux": 123,
"quux": [
{
"corge": null
}
]
}
}
depth = 0
*/
}
jsontext.Decoder
jsontext.DecoderではPeekKindで値を消費せずにjsontext.Kindを取得し、ReadToken, ReadValueで値を読み込めます。
jsonをparseするときに面倒な「今objectがいくつネストしているか」というのがStackDepthで取得できます。
package main
import (
"fmt"
"strings"
"github.com/go-json-experiment/json/jsontext"
)
func main() {
dec := jsontext.NewDecoder(strings.NewReader(`{"foo":"bar", "baz":{"qux":123, "quux":[{"corge":null}]}}`))
var (
t jsontext.Token
err error
)
for err == nil {
off := dec.InputOffset()
kind := dec.PeekKind()
t, err = dec.ReadToken()
depth := dec.StackDepth()
_, length := dec.StackIndex(depth)
pointer := dec.StackPointer()
fmt.Printf("off = %d, kind = %s, token = %s, depth = %d, length = %d, pointer = %s, err = %v\n", off, kind, t, depth, length, pointer, err)
}
/*
off = 0, kind = {, token = {, depth = 1, length = 0, pointer = , err = <nil>
off = 1, kind = string, token = foo, depth = 1, length = 1, pointer = /foo, err = <nil>
off = 6, kind = string, token = bar, depth = 1, length = 2, pointer = /foo, err = <nil>
off = 12, kind = string, token = baz, depth = 1, length = 3, pointer = /baz, err = <nil>
off = 19, kind = {, token = {, depth = 2, length = 0, pointer = /baz, err = <nil>
off = 21, kind = string, token = qux, depth = 2, length = 1, pointer = /baz/qux, err = <nil>
off = 26, kind = number, token = 123, depth = 2, length = 2, pointer = /baz/qux, err = <nil>
off = 30, kind = string, token = quux, depth = 2, length = 3, pointer = /baz/quux, err = <nil>
off = 38, kind = [, token = [, depth = 3, length = 0, pointer = /baz/quux, err = <nil>
off = 40, kind = {, token = {, depth = 4, length = 0, pointer = /baz/quux/0, err = <nil>
off = 41, kind = string, token = corge, depth = 4, length = 1, pointer = /baz/quux/0/corge, err = <nil>
off = 48, kind = null, token = null, depth = 4, length = 2, pointer = /baz/quux/0/corge, err = <nil>
off = 53, kind = }, token = }, depth = 3, length = 1, pointer = /baz/quux/0, err = <nil>
off = 54, kind = ], token = ], depth = 2, length = 4, pointer = /baz/quux, err = <nil>
off = 55, kind = }, token = }, depth = 1, length = 4, pointer = /baz, err = <nil>
off = 56, kind = }, token = }, depth = 0, index = <invalid json.Kind: '\x00'>, length = 1, pointer = , err = <nil>
off = 57, kind = <invalid json.Kind: '\x00'>, token = <invalid json.Token>, depth = 0, index = <invalid json.Kind: '\x00'>, length = 1, pointer = , err = EOF
*/
}
StackPointerでJSON Pointer (RFC 6901)が取得できます。
これはJSON全体をデコードせずにJSON Pointer一致する任意の値まで読み飛ばすのに使うんでしょうか?
以下のようにすればJSON Pointerに一致するまで読み飛ばすことができますね。
UnmarshalJSONV2がdecを受けとることができる以外はおおむねv1似たような使用感だと思います。
package main
import (
"bytes"
"errors"
"fmt"
"io"
"strconv"
"strings"
"github.com/go-json-experiment/json"
"github.com/go-json-experiment/json/jsontext"
)
func readJsonAt(data io.Reader, pointer string, read func(dec *jsontext.Decoder) error) (err error) {
i := strings.LastIndex(pointer, "/")
var idx int64 = -1
if i > 0 && strings.IndexFunc(pointer[i+1:], func(r rune) bool { return '0' <= r && r <= '9' }) >= 0 {
idx, err = strconv.ParseInt(pointer[i+1:], 10, 64)
if err == nil {
pointer = pointer[:i]
} else {
// I'm not really super sure this could happen.
idx = -1
}
}
fmt.Printf("pointer = %s, last idx = %d\n", pointer, idx)
dec := jsontext.NewDecoder(data)
for {
_, err = dec.ReadToken()
if errors.Is(err, io.EOF) {
break
}
if err != nil {
return err
}
p := dec.StackPointer()
fmt.Printf("current pointer = %s\n", p)
if pointer == p {
if idx >= 0 {
// skip '['
_, err = dec.ReadToken()
if err != nil {
return err
}
for ; idx > 0; idx-- {
err := dec.SkipValue()
if err != nil {
return err
}
}
}
return read(dec)
}
}
return nil
}
func main() {
jsonBuf := []byte(`{"yay":"yay","nay":[{"boo":"boo"},{"bobo":"bobo"}],"foo":{"bar":{"baz":"baz"}}}`)
type gibberish struct {
Boo string `json:"boo"`
Bobo string `json:"bobo"`
Baz string `json:"baz"`
}
for _, pointer := range []string{"/foo/bar", "/nay/0", "/nay/1"} {
var gib gibberish
found := false
err := readJsonAt(
bytes.NewBuffer(jsonBuf),
pointer,
func(dec *jsontext.Decoder) error {
found = true
return json.UnmarshalDecode(dec, &gib)
},
)
fmt.Printf("decoded = %#v, found = %t, err = %v\n", gib, found, err)
}
}
/*
pointer = /foo/bar, last idx = -1
current pointer =
current pointer = /yay
current pointer = /yay
current pointer = /nay
current pointer = /nay
current pointer = /nay/0
current pointer = /nay/0/boo
current pointer = /nay/0/boo
current pointer = /nay/0
current pointer = /nay/1
current pointer = /nay/1/bobo
current pointer = /nay/1/bobo
current pointer = /nay/1
current pointer = /nay
current pointer = /foo
current pointer = /foo
current pointer = /foo/bar
decoded = main.gibberish{Boo:"", Bobo:"", Baz:"baz"}, found = true, err = <nil>
pointer = /nay, last idx = 0
current pointer =
current pointer = /yay
current pointer = /yay
current pointer = /nay
decoded = main.gibberish{Boo:"boo", Bobo:"", Baz:""}, found = true, err = <nil>
pointer = /nay, last idx = 1
current pointer =
current pointer = /yay
current pointer = /yay
current pointer = /nay
decoded = main.gibberish{Boo:"", Bobo:"bobo", Baz:""}, found = true, err = <nil>
*/
v2でundefined | null | Tを表現する
そろそろ本題へと移ります。
冒頭で述べた通り、v2ならstdの範疇でundefined | null | Tが表現可能になります。
omitzeroを使う
omitzeroオプションが追加されたため、interface { IsZero() bool }を実装し、IsZeroメソッド内でIsUndefined呼び出せばundefined時にフィールドのスキップができます。
まず前回の記事と同様にoption[T]を定義し、option[option[T]]によってundefined | null | Tを表現可能な型とします。
package main
import (
"fmt"
"github.com/go-json-experiment/json" // github.com/go-json-experiment/json v0.0.0-20231102232822-2e55bd4e08b0
"github.com/go-json-experiment/json/jsontext"
)
type opt[V any] struct {
valid bool
v V
}
type und[V any] struct {
opt opt[opt[V]]
}
初期関数
func Undefined[V any]() und[V] {
return und[V]{}
}
func Null[V any]() und[V] {
return und[V]{
opt: opt[opt[V]]{
valid: true,
},
}
}
func Defined[V any](v V) und[V] {
return und[V]{
opt: opt[opt[V]]{
valid: true,
v: opt[V]{
valid: true,
v: v,
},
},
}
}
外側のoptionに値がない時undefined,内側のoptionに値がない時nullとします。
func (u *und[V]) IsUndefined() bool {
return !u.opt.valid
}
func (u *und[V]) IsNull() bool {
return !u.IsUndefined() && !u.opt.v.valid
}
MarshalJSONV2 / UnmarshalJSONV2を以下のように実装し、
func (u *und[V]) Value() V {
if u.IsUndefined() || u.IsNull() {
var zero V
return zero
}
return u.opt.v.v
}
var _ json.MarshalerV2 = (*und[any])(nil)
func (u *und[V]) MarshalJSONV2(enc *jsontext.Encoder, opt json.Options) error {
if u.IsUndefined() || u.IsNull() {
return enc.WriteToken(jsontext.Null)
}
return json.MarshalEncode(enc, u.Value(), opt)
}
var _ json.UnmarshalerV2 = (*und[any])(nil)
func (u *und[V]) UnmarshalJSONV2(dec *jsontext.Decoder, opt json.Options) error {
var v V
if dec.PeekKind() == 'n' {
err := dec.SkipValue()
if err != nil {
return err
}
u.opt.valid = true
u.opt.v.valid = false
u.opt.v.v = v
return nil
}
err := json.UnmarshalDecode(dec, &v)
if err != nil {
return err
}
u.opt.valid = true
u.opt.v.valid = true
u.opt.v.v = v
return nil
}
omitzeroにスキップしてもらうため、IsZeroを実装します。
func (u *und[V]) IsZero() bool {
return u.IsUndefined()
}
und[T]のフィールドにomitzeroがあればundefinedであるときスキップされます。
func main() {
type some struct {
Foo und[string] `json:",omitzero"`
Bar string
}
for _, v := range []und[string]{
Defined[string]("foo"),
Defined[string](""),
Null[string](),
Undefined[string](),
} {
bin, err := json.Marshal(some{Foo: v, Bar: "bar"})
fmt.Printf("bin = %s, err = %+#v\n", bin, err)
var decoded some
err = json.Unmarshal(bin, &decoded)
fmt.Printf("value = %v, undefined = %t, null = %t, err = %+#v\n", decoded.Foo.Value(), decoded.Foo.IsUndefined(), decoded.Foo.IsNull(), err)
}
}
/*
bin = {"Foo":"foo","Bar":"bar"}, err = <nil>
value = foo, undefined = false, null = false, err = <nil>
bin = {"Foo":"","Bar":"bar"}, err = <nil>
value = , undefined = false, null = false, err = <nil>
bin = {"Foo":null,"Bar":"bar"}, err = <nil>
value = , undefined = false, null = true, err = <nil>
bin = {"Bar":"bar"}, err = <nil>
value = , undefined = true, null = false, err = <nil>
*/
簡単ですね!
ただしこれだとomitzeroオプションをフィールドごとに設定する必要があり、struct fieldだけで表現できてはいません。
*struct fieldだけで*undefined | null | Tを表現する
struct fieldだけでundefined | null | Tを実現するためにもう少し工夫してみます。
方針
v2には以下のように特定の型のMarshaler, Unmarshalerを差し替えるoptionがありますので、こちらを利用すれば任意のmarshaler/unmarshalerに差し替えが可能です。
marshaller := json.MarshalFuncV2[T](func(e *jsontext.Encoder, s T, o json.Options) error {
// ...snip...
})
out, err := json.Marshal(v, json.WithMarshalers(marshaller))
これを利用することを前提として、ぱっと思いつく実装方針は
- 内部的なロジックを取り出して一部のフィールドのomitzeroが有効になるように変更する
- 型からmarshaler/unmarshalerを組む
-
reflect.StructOfを利用してstruct tagにjson:",omitzero"オプションを追加した型をランタイムで作成し、json.MarshalEncodeにそれを渡す。
ロジックを取り出す
結論から言うとこの方法は難しそうなので諦めます。
v2のフィールドスキップの挙動は以下の行で実装されています
当然ではありますが部分的にロジックを取り出せるようにはなっていませんので、特定のinterfaceを実装するときstructField.omitzero = trueにするというようなことはできません。
//go:linknameで関数を呼び出せても難しそう
型からmarshaler/unmarshalerを組む
これはarshal.goが行う手間をまるきり再現することになるのでやりません!
ランタイムで型を作る
この方向で行くことにします。
reflect.StructOfを利用するとランタイムで型を生成できるので、struct tagを差し替えた型を作成し、元の型から生成した型へ変換をかけてからデフォルトのjson.MarshalEncodeの挙動を呼び出すだけで機能を実現できます。
reflect.StructFieldのTagフィールドをいじくるだけなので案外簡単そうです。
ランタイムで型を作って、json.MarshalFuncV2を呼び出す
struct tagだけ差し替えた型を作成する
Goのstructは別の型をembedできたり、embedした型が再帰できたりと、reflectを使った型の変換は簡単そうで厄介なのですが、struct tagをいじるだけならば以下のようなコードで十分です。
特定の型以下には進むことを避けたいのでskipできる仕組みも整えておきましょう。
package faketagencoder
import "reflect"
type Skipper func(reflect.Type) bool
type TagMutator func(reflect.StructField) reflect.StructTag
func MutateTag(
rt reflect.Type,
skipAdvancing Skipper,
mutateTag TagMutator,
) reflect.Type {
fields := make([]reflect.StructField, rt.NumField())
for i := 0; i < rt.NumField(); i++ {
field := rt.Field(i)
typ := field.Type
if !skipAdvancing(typ) {
if typ.Kind() == reflect.Struct {
typ = MutateTag(typ, skipAdvancing, mutateTag)
} else if typ.Kind() == reflect.Pointer {
elem := typ.Elem()
if elem.Kind() == reflect.Struct {
elem = MutateTag(elem, skipAdvancing, mutateTag)
typ = reflect.PointerTo(elem)
}
}
}
fields[i] = reflect.StructField{
Name: field.Name,
PkgPath: field.PkgPath,
Type: typ,
Tag: mutateTag(field),
Offset: field.Offset,
Index: field.Index,
Anonymous: field.Anonymous,
}
}
return reflect.StructOf(fields)
}
十分ですとか書いておいてなんですが、多分この実装では再帰のある型だとstack overflowしますね。
sync.Poolに型をキャッシュするようにしてすでに作成済みの型はキャッシュから引き出すようにするとかそういった処理が必要ですがこのコードは実用するつもりがないのでまあこのままでいいでしょう。
json.MarshalerV1 / json.MmarshalerV2を実装する型の下まで進んでいく必要はないので必要なSkipperはこんなもんでしょうか。
func SkipImplementor(rt reflect.Type) Skipper {
return func(t reflect.Type) bool {
return t.Implements(rt) ||
(t.Kind() == reflect.Pointer && t.Elem().Implements(rt)) ||
reflect.PointerTo(t).Implements(rt)
}
}
func SkipNot(s Skipper) Skipper {
return func(t reflect.Type) bool {
return !s(t)
}
}
func CombineSkipper(skippers ...Skipper) Skipper {
return func(t reflect.Type) bool {
for _, skipper := range skippers {
if skipper(t) {
return true
}
}
return false
}
}
struct tagにoptionを追加する
前回の記事のこの部分でreflect.StructTagを引数にomitemptyがなければ追加するという処理を書きましたが、
前述のとおりv2はstruct tag optionがsingle-quotationでエスケープされた文字列や、format:RFC3339のように:で区切りの文字列を許すように拡張されたそれに合わせた処理が必要です。
package faketagencoder
// This file uses modified Go programming language standard library.
// So keep it credited.
//
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
//
// Modified parts are governed by a license that is described in ./LICENSE.
import (
"errors"
"fmt"
"io"
"reflect"
"strconv"
"strings"
"unicode"
"unicode/utf8"
)
var (
ErrUnpairedKey = errors.New("unpaired key")
)
type Tag struct {
Key string
Value string
}
func (t Tag) Flatten() string {
return t.Key + ":" + strconv.Quote(t.Value)
}
func StructTagOf(tags []Tag) reflect.StructTag {
var buf strings.Builder
for _, tag := range tags {
buf.Write([]byte(tag.Flatten()))
buf.WriteByte(' ')
}
out := buf.String()
if len(out) > 0 {
out = out[:len(out)-1]
}
return reflect.StructTag(out)
}
struct tagの解析器は前回と同じなので省略
func ParseStructTag(tag reflect.StructTag) ([]Tag, error) {
var out []Tag
for tag != "" {
// Skip leading space.
i := 0
for i < len(tag) && tag[i] == ' ' {
i++
}
tag = tag[i:]
if tag == "" {
break
}
// Scan to colon. A space, a quote or a control character is a syntax error.
// Strictly speaking, control chars include the range [0x7f, 0x9f], not just
// [0x00, 0x1f], but in practice, we ignore the multi-byte control characters
// as it is simpler to inspect the tag's bytes than the tag's runes.
i = 0
for i < len(tag) && tag[i] > ' ' && tag[i] != ':' && tag[i] != '"' && tag[i] != 0x7f {
i++
}
if i == 0 || i+1 >= len(tag) || tag[i] != ':' || tag[i+1] != '"' {
return nil, fmt.Errorf("%w: input has no paired value, rest = %s", ErrUnpairedKey, string(tag))
}
name := string(tag[:i])
tag = tag[i+1:]
// Scan quoted string to find value.
i = 1
for i < len(tag) && tag[i] != '"' {
if tag[i] == '\\' {
i++
}
i++
}
if i >= len(tag) {
return nil, fmt.Errorf("%w: name = %s has no paired value, rest = %s", ErrUnpairedKey, name, string(tag))
}
quotedValue := string(tag[:i+1])
tag = tag[i+1:]
value, err := strconv.Unquote(quotedValue)
if err != nil {
return nil, err
}
out = append(out, Tag{Key: name, Value: value})
}
return out, nil
}
// AddTagOption returns a new StructTag which has value added for tag.
// It assumes tag options are formatted as `tag:"name,opt,opt"` style.
// The names, and opts are allowed to be quoted by single quotation marks.
func AddTagOption(t reflect.StructTag, tag string, option string) (reflect.StructTag, error) {
tags, err := ParseStructTag(t)
if err != nil {
return "", err
}
hasTag := false
for i := 0; i < len(tags); i++ {
if tags[i].Key != tag {
continue
}
hasTag = true
hasValue := false
value := tags[i].Value
// first, skip name.
if len(value) > 0 && !strings.HasPrefix(value, ",") {
n := len(value) - len(strings.TrimLeftFunc(value, func(r rune) bool {
return !strings.ContainsRune(",\\'\"`", r) // reserve comma, backslash, and quotes
}))
if n == 0 {
_, n, err = readTagOption(value)
if err != nil {
return "", err
}
}
value = value[n:]
}
for len(value) > 0 {
if value[0] != ',' {
return "", fmt.Errorf("malformed option, %s", tags[i].Value)
} else {
value = value[1:]
if len(value) == 0 {
return "", fmt.Errorf("malformed option, %s", tags[i].Value)
}
}
opt, n, err := readTagOption(value)
if err != nil {
return "", err
}
value = value[n:]
if len(value) > 0 && value[0] == ':' {
if strings.HasPrefix(option, opt+":") {
hasValue = true
break
}
value = value[len(":"):]
_, n, err := readTagOption(value)
if err != nil {
return "", err
}
value = value[n:]
}
if option == opt {
hasValue = true
break
}
}
if !hasValue {
if !strings.HasPrefix(option, ",") {
tags[i].Value += ","
}
tags[i].Value += option
}
break
}
if !hasTag {
tags = append(tags, Tag{Key: tag, Value: option})
}
return StructTagOf(tags), nil
}
func readTagOption(s string) (opt string, n int, err error) {
if len(s) == 0 {
return "", 0, io.ErrUnexpectedEOF
}
switch r, _ := utf8.DecodeRuneInString(s); {
case r == '_' || unicode.IsLetter(r): // Go ident
n = len(s) - len(strings.TrimLeftFunc(s, func(r rune) bool {
return r == '_' || unicode.IsLetter(r) || unicode.IsNumber(r)
}))
return s[:n], n, nil
case r == '\'': // escaped
return unescape(s)
default:
return "", 0, fmt.Errorf("invalid character: %s", s)
}
}
func unescape(s string) (unescaped string, n int, err error) {
i := 0
if s[0] == '\'' {
i = 1
}
escaping := false
escaped := []byte{'"'}
for i < len(s) {
r, rn := utf8.DecodeRuneInString(s[i:])
switch {
case escaping:
if r == '\'' {
escaped = escaped[:len(escaped)-1]
}
escaping = false
case r == '\\':
escaping = true
case r == '"':
escaped = append(escaped, '\\')
case r == '\'':
escaped = append(escaped, '"')
i += 1
out, err := strconv.Unquote(string(escaped))
if err != nil {
return "", 0, fmt.Errorf("invalid escaped string: string must be escaped by single quotes, input = %s", s)
}
return out, i, nil
}
escaped = append(escaped, s[n:][:rn]...)
i += rn
}
return "", 0, fmt.Errorf("invalid escaped string: single-quoted string missing terminating single-quote: %s", s)
}
上記のAddTagOptionを利用することでreflect.StructFieldが特定のinterface(今回の場合interface { IsUndefined() bool })を実装するときだけ、struct tagにオプションを追加する処理が実現できます。
func AddOption(tag string, opt string, ignoreIf func(t reflect.Type) bool) TagMutator {
return func(sf reflect.StructField) reflect.StructTag {
if ignoreIf(sf.Type) {
return sf.Tag
}
added, err := AddTagOption(sf.Tag, tag, opt)
if err != nil {
// downstream may return same error
return sf.Tag
}
return added
}
}
json.MarshalFuncV2でエンコーダーを差し替えて呼び出す
以下のように呼び出します。
実際にomitzeroがstruct tagに追記されて、フィールドのスキップが起こることが確認できました。
今回のような簡単なケースでは以下のコードでも意図通りに動作しますが、気付いていないだけでたくさんのエッジケースが存在するんだろうと思います。
よほどのことがない限りomitzeroを手書きで追加していくほうが好ましいと思われます。
package main
import (
"fmt"
"reflect"
"github.com/go-json-experiment/json" // github.com/go-json-experiment/json v0.0.0-20231102232822-2e55bd4e08b0
"github.com/go-json-experiment/json/jsontext"
"github.com/ngicks/faketagencoder"
)
// 省略
type Undefinedable interface {
IsUndefined() bool
}
var (
undefinedableType = reflect.TypeOf((*Undefinedable)(nil)).Elem()
jsonV1Marshaller = reflect.TypeOf((*json.MarshalerV1)(nil)).Elem()
jsonV2Marshaller = reflect.TypeOf((*json.MarshalerV2)(nil)).Elem()
)
// めちゃざっくり実装なので動かないケースたくさんありそうです
func setExported(l, r reflect.Value) {
for i := 0; i < l.NumField(); i++ {
fl := l.Field(i)
fr := r.Field(i)
if fl.Type() == fr.Type() {
fl.Set(fr)
} else {
setExported(fl, fr)
}
}
}
func main() {
type Nested struct {
Nah und[string] `json:"nah"`
Yay int `json:"yay"`
}
type some struct {
Foo und[string] `json:"foo"`
Bar string `json:"bar"`
Baz Nested `json:"baz"`
Nested
}
mutated := faketagencoder.MutateTag(
reflect.TypeOf(some{}),
faketagencoder.CombineSkipper(
faketagencoder.SkipImplementor(jsonV1Marshaller),
faketagencoder.SkipImplementor(jsonV2Marshaller),
),
faketagencoder.AddOption(`json`, `,omitzero`, faketagencoder.SkipNot(faketagencoder.SkipImplementor(undefinedableType))),
)
fmt.Printf("mutated type = %+v\n", mutated)
/*
mutated type = struct { Foo main.und[string] "json:\"foo,omitzero\""; Bar string "json:\"bar\""; Baz struct { Nah main.und[string] "json:\"nah,omitzero\""; Yay int "json:\"yay\"" } "json:\"baz\""; Nested struct { Nah main.und[string] "json:\"nah,omitzero\""; Yay int "json:\"yay\"" } }
*/
marshaller := json.MarshalFuncV2[some](func(e *jsontext.Encoder, s some, o json.Options) error {
rv := reflect.ValueOf(s)
v := reflect.New(mutated).Elem()
setExported(v, rv)
return json.MarshalEncode(e, v.Interface(), o)
})
for _, v := range []some{
{},
{
Foo: Defined("foo"),
Bar: "bar",
Baz: Nested{
Nah: Defined("nah"),
Yay: 20,
},
Nested: Nested{
Nah: Defined("nah"),
Yay: -231,
},
},
} {
out, err := json.Marshal(v, json.WithMarshalers(marshaller), jsontext.WithIndent(" "))
if err != nil {
panic(err)
}
fmt.Printf("%s\n", out)
}
/*
{
"bar": "",
"baz": {
"yay": 0
},
"yay": 0
}
{
"foo": "foo",
"bar": "bar",
"baz": {
"nah": "nah",
"yay": 20
},
"nah": "nah",
"yay": -231
}
*/
}
おわりに
この記事ではv2のモチベーション、API、部分的な実装とv1との差異について紹介し、undefined | null | Tがv2によって実現可能なことをしましました。
さらに、*struct fieldだけで*undefined | null | Tを実現するためにv2のoptionについて少し探索しました。
このコメント曰くproposalになる前にdiscussionを受けたAPIの変更とv1との互換性レイヤーを実装するとのことなので、
v2がこのまま実装されるわけでもなさそうですし、すぐリリースということでもなさそうです。
しかし洗練されたAPI、内部実装、より厳格なデフォルト挙動などstd入りするのが非常に楽しみなライブラリです。
Discussion