はじめに
現代のソフトウェアシステムは、かつてないほど複雑化しています。マイクロサービスアーキテクチャの採用により、1つのアプリケーションが数十、時には数百ものサービスで構成されることも珍しくありません。
このような環境で「システムが遅い」「エラーが発生している」という問題に直面したときに原因を特定することは容易ではありません。どのサービスが原因なのか、なぜ特定の条件でのみ発生するのか、影響範囲はどこまでなのか。
これらを理解するには、システムの内部で何が起きているかを観測する性質(オブザーバビリティ)を確保することが必要です。
本記事では、この課題を解決する「オブザーバビリティ」という概念と「オブザーバビリティ」を実現するための基本的な手法、それを実現する業界標準「OpenTelemetry」について、基礎から体系的に解説します。
オブザーバビリティとは何か
システムの外部出力から、内部状態を理解・推測できる性質のことです。
オブザーバビリティを確保するためには、たとえば、テレメトリデータを活用して、外部から観測可能なデータのみから、システムの内部で何が起きているかを推測・理解するという手法があります。
テレメトリデータとは
テレメトリデータとは、システムやアプリケーションの状況を示すデータを収集・送信したものです。
テレメトリデータの中で主要となるものは以下の3つです。これは「オブザーバビリティの3つの柱」とも呼ばれます。
- メトリクス
- トレース
- ログ
メトリクス
実行時に取得されるサービスの時系列測定値のことです。例えば以下のようなものが該当します。
例1 CPU使用率:
10:00 - 45%
10:01 - 47%
10:02 - 89% ← 異常
10:03 - 92%
例2 サイトの表示速度:
10:00 - 0.12s
10:01 - 0.13s
10:02 - 1.25s ← 異常
10:03 - 1.22s
何に役立つのか
システムの健康状態を継続的に監視し、異常を素早く検知するために役立ちます。
上記の例でいえばCPU使用率が跳ね上がったとき、メトリクスがあればすぐにアラートを発して対応を開始できます。また、サイトの表示速度が遅くなった場合に他のメトリクス(例えばアクセス件数など)と組み合わせることで相関関係を発見することができます。
また、アラート以外の用途としてビジネス面で活用することも可能です。例えば、コンバージョン率や売上などのビジネスメトリクスを上記の技術メトリクスと組み合わせることで、「サイトの表示速度が1秒遅くなるごとに売上が10%下がる」といった相関関係を発見し、投資判断の根拠とすることができます。
トレース
1つのリクエストが複数のサービスを通過する様子を記録したものです。
例えばECサイトの決済を例に取ると以下のようなものです。
[ユーザーの購入ボタンクリック] 合計:2.5秒
│
├─① [Webサーバー] 0.3秒
│ └─② [ユーザ認証サービス] 0.1秒
├─③ [Backendサーバー/在庫情報の確認] 0.2秒
│ └─④ [DBから在庫情報の取得] 0.1秒
├─⑤ [Backendサーバー/決済処理] 1.8秒 ← ボトルネック!
│ └─⑥ [外部決済API] 0.5秒
└─⑦ [配送依頼] 0.2秒
何に役立つのか
複雑な分散システムにおいて、問題がどこで発生しているかを特定するために有効です。
上記の例でいえば「購入処理が遅い」という問題に対して、トレースを使えば「購入フロー全体2.5秒のうち、決済サービスの外部API呼び出しが1.8秒を占めている」というボトルネックを突き止められます。これにより、改善箇所を明確にすることができます。
また、エラーが発生した際には、そのリクエストがどのような経路を辿り、どの時点で失敗したのかを正確に把握できます。これは特に「たまにしか発生しない」問題の原因究明において力を発揮します。
ログ
システムで発生したイベントの詳細な記録です。
以下に例を挙げます。
// 正常なログ
{
"timestamp": "2024-01-15 10:30:45",
"level": "INFO",
"message": "購入完了",
"user_id": "user-123",
"order_id": "order-789",
"amount": 5000,
"items": ["商品A", "商品B"]
}
// エラーログ
{
"timestamp": "2024-01-15 10:31:20",
"level": "ERROR",
"message": "クレジットカード決済失敗",
"user_id": "user-456",
"error_code": "CARD_DECLINED",
"card_last4": "1234",
"amount": 10000,
"retry_count": 3
}
何に役立つのか
問題の根本原因を突き止め、詳細な調査を行うために役立ちます。
トラブルシューティングでは、ログに記録された詳細な情報を調べ原因を特定します。例えば「特定のユーザーだけエラーが発生する」という問題で、ログを調べた結果「ユーザー名に絵文字が含まれている場合にバリデーションエラーが発生していた」といった、予想外の原因を発見できます。
また、セキュリティの観点では、ログは不正アクセスの痕跡を追跡する証跡になります。誰が、いつ、どのデータにアクセスしたかという監査ログは、インシデント発生時の調査だけでなく、コンプライアンス要件を満たすためにも重要です。
さらに、ビジネス面で活用することも可能です。ログを分析することでユーザーの行動パターンを理解に役立ちます。例えば、ユーザーがどのような条件で検索を主に利用するのか、リリースした機能は使用されているかなどを知り、プロダクトの改善に活かすこともできます。
まとめると
| 種別 | 役割 | 利用方法 |
|---|---|---|
| メトリクス | 問題の検知 | • アラート • 相関関係把握 |
| トレース | 問題箇所の特定 | • ボトルネック特定 • フロー分析 |
| ログ | 原因分析 | • 詳細調査 • 根本原因分析 |
OpenTelemetry
OpenTelemetryは分散システムやマイクロサービスアーキテクチャにおける「オブザーバビリティ」を実現するためのオープンソースプロジェクトであり統一標準です。Java、Go、Pythonなどのプログラミング言語に対応した単一のアプリケーションプログラミングインターフェース(API)、ライブラリ、統合機能、そしてソフトウェア開発キット(SDK)を提供しています。
統一標準とは
OpenTelemetry以前は、各ベンダーや各ツールが独自の方法でテレメトリデータを収集していました。そのため、ベンダーロックインのリスクや異なるツール間でデータ形式が異なるといった問題がありました。
そこで、データモデルやAPI仕様を標準化し、その標準仕様に則っているサービスであれば主に設定変更のみで、異なる分析ツールやバックエンドサービスへ切り替えることができるように生まれたのがOpenTelemetryです。
そのため、OpenTelemetryでは一度アプリケーションを計装(インストルメンテーション)すれば、そのテレメトリデータをDatadog、New Relic、Jaeger、AWS X-Ray、Google Cloud Traceなど、OpenTelemetryに対応した任意のツールでの分析が可能となっています。
これにより、企業は特定ベンダーに縛られることなく、ニーズに応じて最適な監視・分析ツールを選択することを可能となりました。
マイクロサービス アーキテクチャと分散トレース
マイクロサービス アーキテクチャ
マイクロサービス アーキテクチャ(マイクロサービス)は小さく独立したサービスを組み合わせることで大規模なアプリケーションを構築するソフトウェア開発手法の一つです。各サービスは独立し、APIを介して相互に連携します。
オブザーバビリティ文脈において、このマイクロサービスアーキテクチャは以下の課題を抱えています。
- サービス間の依存関係や影響範囲が不明
- トレース情報が途切れてしまう(非同期処理やレガシーサービスで欠落)
- 特定サービスにおけるトレース情報の欠如
そこで重要になってくるのが、リクエストが複数のサービスを通過する様子を追跡する「分散トレース」という技術です。
分散トレース
分散トレースは、1つのユーザーリクエストが複数のマイクロサービスを通過する際の経路と各サービスでの処理時間を記録・可視化する技術です。
例えば、ECサイトで商品を購入する際、以下のような流れを辿ります。
[ユーザー] → [API Gateway] → [認証サービス] → [商品サービス] → [決済サービス] → [配送サービス]
このとき、この一連の処理がどのように実行され、どこで時間がかかっているのか、どこでエラーが発生したのかを正確に把握し、パフォーマンスのボトルネックや障害の原因を迅速に特定することを可能にするものが分散トレースです。
トレースとスパン
分散トレースは「トレース」と「スパン」という2つの基本概念で構成されています。
トレースとスパンに関する詳細はこちらをご参照ください。
トレース
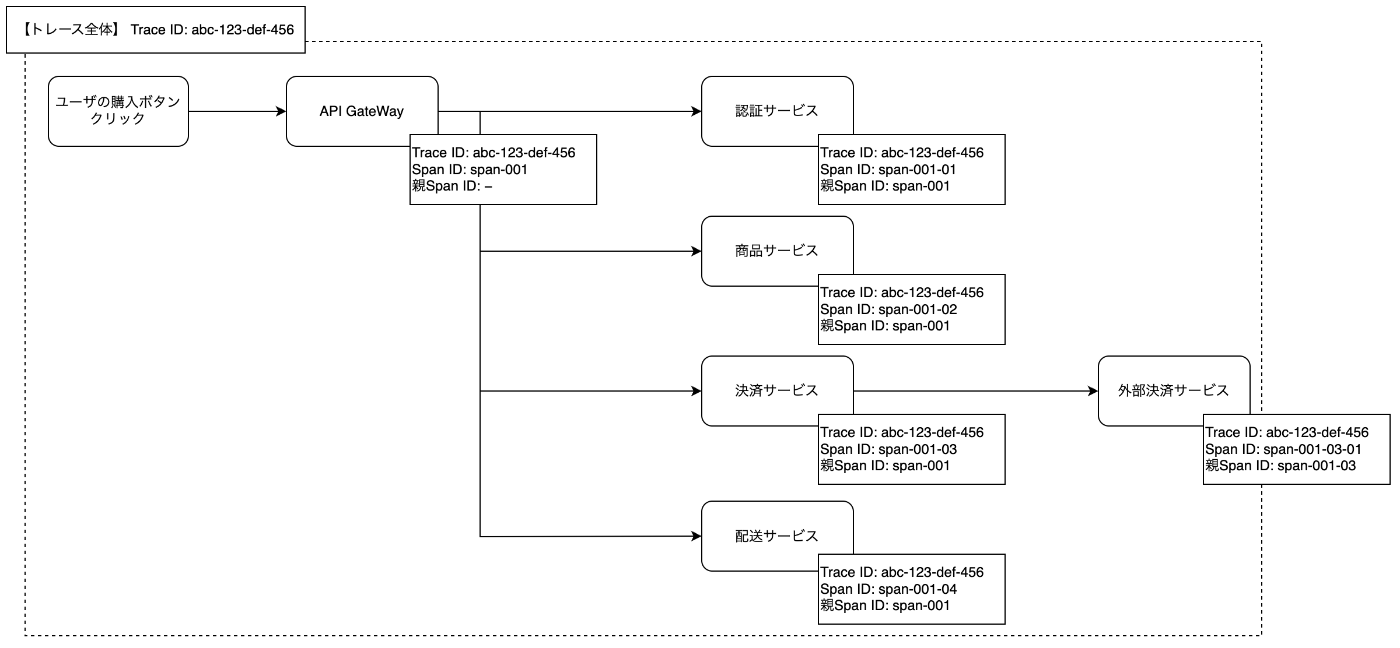
1つのリクエスト全体の処理を表す単位です。ユーザーが購入ボタンをクリックしてから、注文完了までの一連の処理全体が1つのトレースとなります。各トレースは一意のTrace IDで識別されます。
スパン
トレース内の個々の処理単位を表します。例えば上記のECサイトの例では「認証サービスでの認証処理」「決済サービスでの決済処理」など、各サービスでの個別の処理がそれぞれ1つのスパンになります。
各スパンは以下の情報を持ちます。この親子関係により、処理の階層構造が形成され、リクエスト全体のフローが可視化されます。
- Span ID(スパンの識別子)
- 親Span ID(呼び出し元のスパン)
- 開始時刻と終了時刻
- 属性(サービス名、処理内容など)
上記の関係性を図示すると以下のような形です。
コンテキスト伝搬
上記に示した通り分散トレースが機能するためには異なるサービス間の相関関係を構築する必要があります。そのためにはTrace IDやSpan IDといった情報をサービス間で受け渡す必要があります。この仕組みをコンテキスト伝搬と呼びます。
コンテキスト伝搬では以下のようなHTTPヘッダーで情報が伝達されます。

上記はW3C Trace Context標準に準拠した形式で以下の情報が含まれます。
- version:現在のW3C Trace Context仕様のバージョンです。現在は00です。
- trace-id:システム全体の分散トレースを一意に識別するために使用されます。16バイトの配列として表されます。すべてのバイトがゼロ(00000000000000000000000000000000)の場合は無効な値と見なされます。
- parent-id:現在のスパンIDです。次のサービスにとっての親スパンIDです。これは8バイトの配列として表されます。すべてのバイトがゼロ(0000000000000000)の場合は無効な値と見なされます。
- trace-flags:8ビットのフィールドで、トレースの振る舞いを制御します。現在はSampled Flagのみが定義されており意味は以下のとおりです。
- 00:トレースを記録しない
- 01:トレースを記録する
セマンティック規約
ここまで分散トレースによるリクエストの追跡方法とコンテキスト伝搬による情報の受け渡し方法を説明しました。これにより、「どのサービスを経由したか」「どこで時間がかかったか」は分かるようになりました。
しかし、有用なオブザーバビリティを実現するには以下のような詳細な情報が必要です。
- HTTPリクエストのメソッド
- データベースへのクエリ
- どのユーザーが実行したのか
etc…
これらの情報を記録する際、各サービスが独自の属性名を使うと、せっかく収集したデータが活用できません。そこでOpenTelemetryではさまざまな種類の操作やデータに対する共通の名前を指定するセマンティック規約を定義しています。
いくつか代表的なものを以下に示します。
{
"http.request.method": "POST",
"http.request.body.size": 1024,
"http.route": "/api/users/{id}",
"http.response.status_code": 200,
"url.full": "https://api.example.com/users/123",
"url.scheme": "https",
"server.address": "api.example.com",
"server.port": 443
}
Name: db.client.connection.count
Unit: {connection}
Type: UpDownCounter
Attributes:
- state: "idle" | "used"
- pool.name: "primary"
OpenTelemetry Protocol
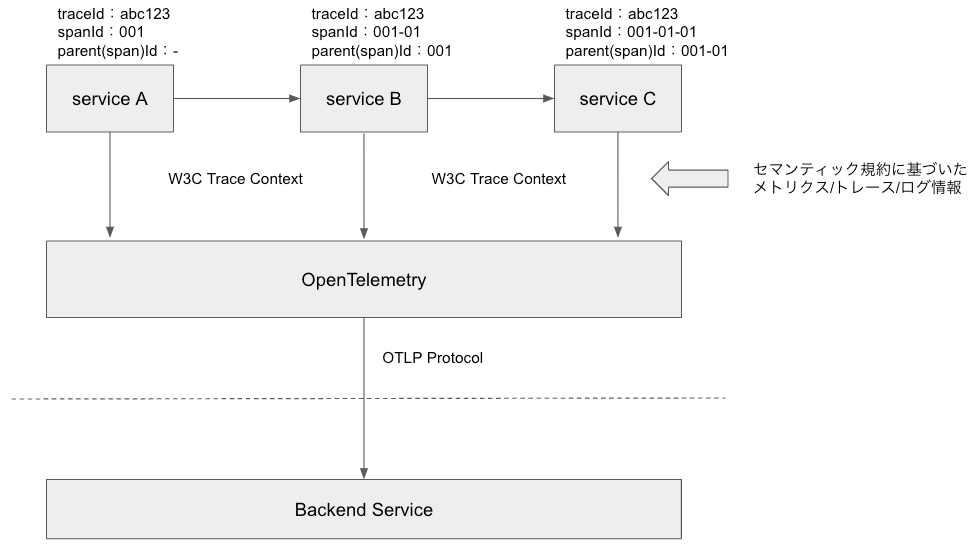
ここまで、トレース情報の流れとデータ収集について説明しました。あとは収集したテレメトリデータを送信する必要があります。どのように送信するかを定義するのがOpenTelemetry Protocol(OTLP)です。
OpenTelemetry Protocol(OTLP)とは
OTLPはテレメトリデータ(メトリクス、トレース、ログ)を送信するための標準プロトコルです。このプロトコルによりOpenTelemetryで収集したデータを対応する任意のバックエンドに送信できます。
プロトコルとして以下に示すgRPC/HTTP (Binary/Protobuf)/HTTP (JSON)の3つが定義されています。
| 観点 | OTLP/gRPC | OTLP/HTTP (Binary/Protobuf) | OTLP/HTTP (JSON) |
|---|---|---|---|
| プロトコル | gRPC (HTTP/2) | HTTP/1.0, HTTP/1.1, HTTP/2 | HTTP/1.0, HTTP/1.1, HTTP/2 |
| データ形式 | Protocol Buffers (バイナリ) | Protocol Buffers (バイナリ) | JSON (テキスト) |
| デフォルトポート | 4317 | 4318 | 4318 |
| メリット | • 最高の効率性 • 双方向ストリーミング • 組み込みの再試行機能 • 接続の多重化 • 最小のネットワークオーバーヘッド • gzipによる圧縮サポート |
• HTTP/1.1対応で高い互換性 • プロキシ/ロードバランサー親和性 • ファイアウォール通過が容易 • Protocol Buffersによる効率性維持 • gzipによる圧縮サポート |
• 人間が読める形式 • デバッグが容易 • curlなど標準ツールでテスト可能 • あらゆる環境で動作 • ログ出力で内容確認可能 • 実装が最も簡単 |
| デメリット | • HTTP/2サポートが必要 • 一部のプロキシで問題 • ファイアウォール設定が必要な場合あり • デバッグが困難(バイナリ) |
• gRPCよりわずかにオーバーヘッドが大きい • ストリーミング非対応 • デバッグが困難(バイナリ) |
• データサイズが大きい(約2倍) • パース処理のCPU負荷が高い • ネットワーク帯域を多く消費 • 大規模環境では非効率 |
| 利用シーン |
本番環境(推奨) • 高トラフィック環境 • マイクロサービス間通信 • クラウドネイティブ環境 • レイテンシーが重要な場合 |
制約のある本番環境 • HTTP/2が使えない環境 • 企業プロキシ経由 • レガシーインフラとの統合 • ロードバランサー必須環境 |
開発・テスト環境 • ローカル開発 • デバッグ・トラブルシューティング • プロトタイピング • 低トラフィック環境 • 教育・学習目的 |
まとめると
OpenTelemetryは従来のベンダーロックインのリスクや異なるツール間でデータ形式が異なるといった問題を解決することを目的とし標準化を行うオープンソースプロジェクトです。データ収集だけでなくバックエンドへのデータ送信ついても標準化を行っています。
データ送信の流れをまとめると以下の形になります。
おわりに
本記事では、オブザーバビリティの基本概念とOpenTelemetryの仕組みについて解説しました。
オブザーバビリティの実現には、メトリクス・トレース・ログの3つのテレメトリデータを適切に収集し、相関させることが重要です。OpenTelemetryは、これらのデータを統一的に扱い、ベンダーに依存しない形で送信することを可能にする強力なフレームワークです。
特にマイクロサービスアーキテクチャにおいては分散トレースとコンテキスト伝播により複雑に絡み合ったサービス間の処理を可視化し問題の迅速な特定と解決を実現します。
次回はOpenTelemetryの実装方法について具体的なコード例とともに解説します。導入方法から実際の計測など実践的な内容をお届けする予定です。
参考

Discussion