はじめに
先日、「Amazon Aurora から Google Cloud BigQuery へのデータ移行をTerraformを中心に実装してみた話」というタイトルで、ブログを執筆しました。
今回はその続編として、データ移行の自動化を実装しましたので、その手順をご紹介します。
実装にあたっての要件
- 1日に1回、AuroraのデータをBigQueryに移行する。この時、Auroraで取得されるシステムスナップショットを使用するものとする。
- LambdaとEventBridgeにつき、Terraformではなく、AWS Serverless Application Model (AWS SAM)を用いてデプロイするものとする。
- 商用環境とステージング環境でそれぞれ対応して作成するものとする。
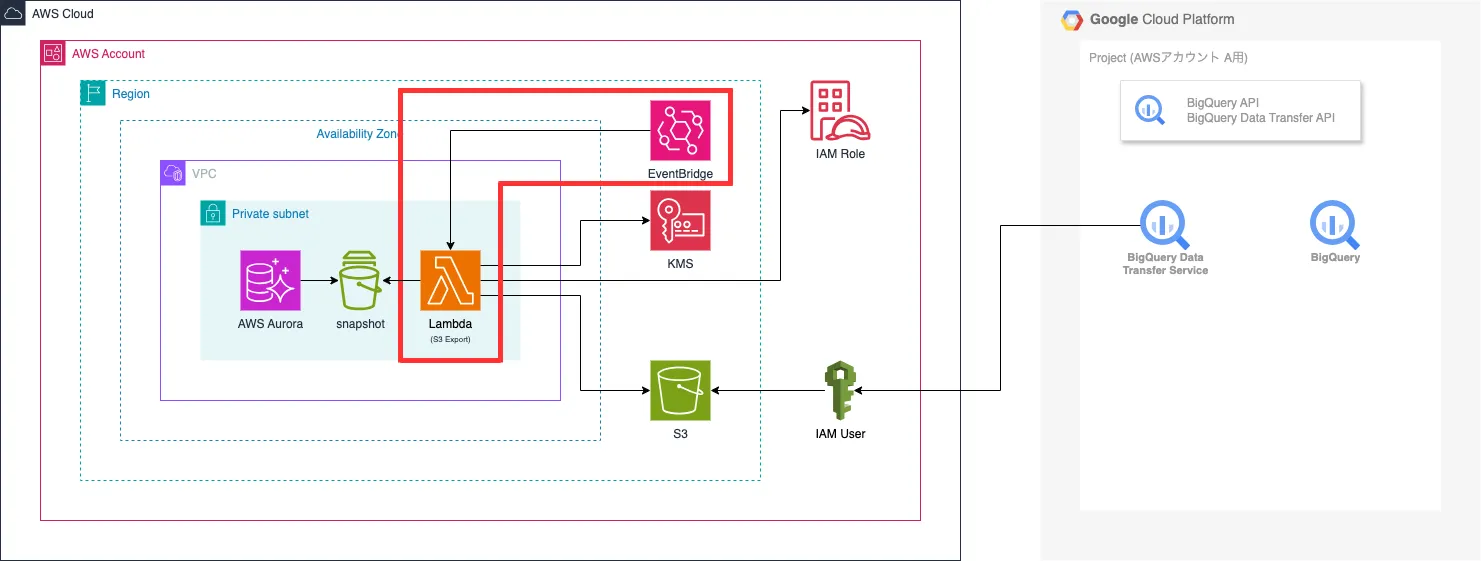
構成図
実行スケジュール
| 時間 | 項目 | 備考 |
|---|---|---|
| 01:00頃 | 【AWS】Aurora System Snapshot取得 | 容量次第だが大凡30分前後で実行可能見込み |
| 04:00頃 | 【AWS】Lambda × EventbridgeによるAurora Snapshot S3 Export実施 | 容量次第だが大凡30分前後で実行可能見込み |
| 06:00頃 | 【GoogleCloud】BigQuery Data Transfer Service起動 | 容量次第だが大凡30分前後で実行可能見込み |
AWS側
- 【今回新規作成分】Lambda (中身は後述します。)
- 【今回新規作成分】EventBridge (Lambdaのトリガー)
GoogleCloud側
- Data Transfer Service (一部パラメータ修正が発生します。)
実装手順
AWS側
handler.py
import boto3
import os
import json
from datetime import datetime
from typing import Optional, Dict
from botocore.config import Config
from botocore.exceptions import BotoCoreError, ClientError
from zoneinfo import ZoneInfo
class DateTimeEncoder(json.JSONEncoder):
"""datetime オブジェクトをJSON シリアライズ可能な形式に変換するためのカスタムエンコーダー"""
def default(self, obj):
if isinstance(obj, datetime):
return obj.isoformat()
return super().default(obj)
def create_error_response(error_message: str, status_code: int = 500) -> Dict[str, int | str]:
"""
エラーレスポンスを生成する
Args:
error_message: エラーメッセージ
status_code: HTTPステータスコード
Returns:
Dict: エラーレスポンス
"""
return {
'statusCode': status_code,
'body': json.dumps({
'error': True,
'message': error_message
}, cls=DateTimeEncoder)
}
def create_success_response(data: dict) -> Dict[str, int | str]:
"""
成功レスポンスを生成する
Args:
data: レスポンスデータ
Returns:
Dict: 成功レスポンス
"""
return {
'statusCode': 200,
'body': json.dumps({
'error': False,
'data': data
}, cls=DateTimeEncoder)
}
def validate_environment_variables() -> tuple[bool, Optional[str]]:
"""
必要な環境変数が設定されているか確認する
Returns:
tuple[bool, Optional[str]]: (検証結果, エラーメッセージ)
"""
required_vars = [
'DB_CLUSTER_IDENTIFIER',
'EXPORT_ROLE_ARN',
'S3_BUCKET_NAME',
'KMS_KEY_ID',
'ENV'
]
missing_vars = [var for var in required_vars if not os.getenv(var)]
if missing_vars:
error_message = f"Missing required environment variables: {', '.join(missing_vars)}"
return False, error_message
return True, None
def request_to_export_snapshot_to_s3() -> tuple[bool, Union[dict, str]]:
"""
AuroraのスナップショットをS3にエクスポートするための関数
Returns:
tuple[bool, Union[dict, str]]: (成功/失敗, レスポンスデータ/エラーメッセージ)
"""
# 環境変数のバリデーション
is_valid, error_message = validate_environment_variables()
if not is_valid:
return False, error_message
# AWS Lambdaの実行リージョンを取得
session = boto3.session.Session()
region = session.region_name
# 環境変数から設定を読み込み
cluster_id = os.getenv('DB_CLUSTER_IDENTIFIER')
role_arn = os.getenv('EXPORT_ROLE_ARN')
bucket_name = os.getenv('S3_BUCKET_NAME')
kms_key_id = os.getenv('KMS_KEY_ID')
env = os.getenv('ENV')
# RDSクライアントの初期化
client = boto3.client(
'rds',
region_name=region,
config=Config(
retries = dict(
max_attempts = 3
)
)
)
try:
# 最新のスナップショットを取得
describe_result = client.describe_db_cluster_snapshots(
DBClusterIdentifier=cluster_id
)
if 'DBClusterSnapshots' not in describe_result or not describe_result['DBClusterSnapshots']:
return False, "No snapshots found"
# スナップショットを作成時刻で降順ソート
snapshots = sorted(
describe_result['DBClusterSnapshots'],
key=lambda x: x.get('SnapshotCreateTime', datetime.min),
reverse=True
)
latest_snapshot = snapshots[0]
snapshot_arn = latest_snapshot.get('DBClusterSnapshotArn')
if not snapshot_arn:
return False, "No snapshot ARN found"
# タスクIDに環境名と日本時間での現在時刻を設定
current_time_jst = datetime.now(ZoneInfo("Asia/Tokyo"))
task_id = f"{env}-{current_time_jst.strftime('%Y%m%d')}"
# エクスポートタスクの開始
export_response = client.start_export_task(
ExportTaskIdentifier=task_id,
SourceArn=snapshot_arn,
IamRoleArn=role_arn,
KmsKeyId=kms_key_id,
S3BucketName=bucket_name,
)
print(f"Started export task with ID: {task_id}")
return True, export_response
except ClientError as e:
error_message = f"AWS API error occurred: {str(e)}"
print(error_message)
return False, error_message
except BotoCoreError as e:
error_message = f"AWS client error occurred: {str(e)}"
print(error_message)
return False, error_message
except Exception as e:
error_message = f"Unexpected error occurred: {str(e)}"
print(error_message)
return False, error_message
def handler(event, context):
"""
Lambda handler function
"""
success, result = request_to_export_snapshot_to_s3()
if success:
return create_success_response(result)
else:
return create_error_response(result)
if __name__ == "__main__":
success, result = request_to_export_snapshot_to_s3()
if success:
print(f"Export task started successfully: {result}")
else:
print(f"Export task failed: {result}")
samconfig.toml
version = 0.1
[default]
[default.build.parameters]
debug = true
use_container = false
cached = true
parallel = true
[default.validate.parameters]
lint = true
[default.deploy.parameters]
capabilities = "CAPABILITY_IAM"
confirm_changeset = true
s3_bucket = "(SAMでデプロイする際にテンプレートファイルを配置するS3バケット名)"
region = "ap-northeast-1"
[default.package.parameters]
resolve_s3 = true
[default.sync.parameters]
watch = true
[default.local_start_api.parameters]
warm_containers = "EAGER"
[default.local_start_lambda.parameters]
warm_containers = "EAGER"
[prod]
[prod.global.parameters]
stack_name = "prod-aurora-snapshot-s3-exporter"
[prod.deploy.parameters]
confirm_changeset = true
s3_bucket = "(任意のS3バケット名)"
s3_prefix = "prod__aurora-snapshot-s3-exporter"
region = "ap-northeast-1"
parameter_overrides = "Env=prod"
[stg]
[stg.global.parameters]
stack_name = "stg-aurora-snapshot-s3-exporter"
[stg.deploy.parameters]
confirm_changeset = true
s3_bucket = "(SAMでデプロイする際にテンプレートファイルを配置するS3バケット名)"
s3_prefix = "stg__aurora-snapshot-s3-exporter"
region = "ap-northeast-1"
parameter_overrides = "Env=stg"
template.yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: Aurora Snapshot S3 Exporter
Parameters:
Env:
Type: String
AllowedValues:
- stg
- prod
Globals:
Function:
Runtime: python3.12
Timeout: 900
MemorySize: 512
Resources:
AuroraSnapshotS3Exporter:
Type: AWS::Serverless::Function
Properties:
FunctionName: !Sub ${Env}__aurora-snapshot-s3-exporter
CodeUri: ../../functions/
Handler: handler.handler
Environment:
Variables:
ENV: !Ref Env
DB_CLUSTER_IDENTIFIER: !If
- IsProd
- "(本番環境のAuroraクラスター識別子)"
- "(ステージング環境のAuroraクラスター識別子)"
EXPORT_ROLE_ARN: !If
- IsProd
- "arn:aws:iam::(AWSアカウントID):role/(本番環境のSnapshot S3 Exportで使用するIAMロール)"
- "arn:aws:iam::(AWSアカウントID):role/(ステージング環境のSnapshot S3 Exportで使用するIAMロール)"
S3_BUCKET_NAME: !If
- IsProd
- "(本番環境におけるSnapshot S3 Export先のS3バケット名)"
- "(ステージング環境におけるSnapshot S3 Export先のS3バケット名)"
KMS_KEY_ID: !If
- IsProd
- "(本番環境におけるKMSのID)"
- "(ステージング環境におけるKMSのID)"
Role: !If
- IsProd
- "arn:aws:iam::(AWSアカウントID):role/(本番環境のLambda実行用IAMロール)"
- "arn:aws:iam::(AWSアカウントID):role/(ステージング環境のLambda実行用IAMロール)"
VpcConfig:
SubnetIds: !If
- IsProd
- [subnet-1q2w3e4r] ## sn-private-1
- [subnet-qawsedrf] ## sn-private-stg-1
SecurityGroupIds: !If
- IsProd
- [sg-5t6y7u8i] ## default
- [sg-tgyhujik] ## default
Events:
MySQLEvent:
Type: Schedule
Properties:
Schedule: cron(0 19 * * ? *)
Name: !Sub ${Env}__aurora-snapshot-s3-exporter
State: !If
- IsProd
- ENABLED # Prod 環境では有効
- DISABLED # STG 環境では無効
Conditions:
IsProd: !Equals [!Ref Env, "prod"]
GoogleCloud側
###############################################################################
# BigQuery Data Transfer Service
###############################################################################
resource "google_bigquery_data_transfer_config" "aws_aurora" {
for_each = local.aws_aurora_prod_tables
display_name = "(環境名)_${google_bigquery_table.aws_aurora_prod[each.key].table_id}"
location = "asia-northeast1"
data_source_id = "amazon_s3"
destination_dataset_id = "(環境名)_${each.value.dataset_name}"
service_account_name = data.google_service_account.aws_aurora.email
schedule = "every day 21:00" // (毎日AM6:00(JST))
params = {
destination_table_name_template = google_bigquery_table.aws_aurora_prod[each.key].table_id
data_path = "s3://(Aurora Snapshot S3 Exportで生成されたファイルの配置先S3バケット)/(環境名)-{run_time|\"%Y%m%d\"}/${each.value.dataset_name}/${each.value.dataset_name}.${google_bigquery_table.aws_aurora_prod[each.key].table_id}/1/*.parquet"
access_key_id = "(IAMユーザアクセスキーにおけるアクセスキー)"
file_format = "PARQUET"
write_disposition = "WRITE_TRUNCATE"
}
sensitive_params {
secret_access_key = "(IAMユーザアクセスキーにおけるシークレット)"
}
depends_on = [
google_bigquery_dataset.aws_aurora_prod
]
}
導入時に躓いたポイント
- KMSにつき、ARNではなくID指定が必要だった。
- 日次実行の際、BigQuery Data Transferにおけるdata_pathの指定で手こずった。
- ドキュメント(Amazon S3 転送のランタイム パラメータ)に記載されている内容を参考に修正しました。
- 当初、BigQuery側においてデータが重複して登録されてしまった。
- ドキュメント(クエリのスケジューリング)に記載されている内容を参考に"WRITE_TRUNCATE"を指定しました。
運用時における雑多なTips
DB側でカラム変更が発生した場合
BigQuery側において自動的にカラム変更が反映されるよう、"google_bigquery_data_transfer_config"におけるparams.write_dispositionにて"WRITE_TRUNCATE"を指定しています。
スケジュールとは別にスポットで連携したい場合
- 手動でAurora Snapshotを取得し、Lambdaではなく手動でS3 Exportを実施する。
- S3 Exportの実行結果につき、LambdaでのExportで配置されるディレクトリ
(環境名)-{実施日付)にファイルを上書き保存する。 - BigQuery Data Transfer Serviceにおいて、手動で実行する。
最後に
現在、上記内容にて一部サービスにおいてトライアル運用を行っており、概ね順調に運用できています。特に問題がなさそうであれば他サービスにおいても導入し、よりデータ分析が推進できる基盤を構築していきたいと思います。

Discussion