Gemma: Open Models Based on Gemini Research and Technology

1. モデルアーキテクチャ
- デコーダーモデル
- コンテキスト長:8192
1.1 Transformerからの改善
-
Multi-Query Attention
- 7Bはmulti-head attention
- 2Bはmulti-query attention
-
RoPE Embeddings
- モデルサイズ削減のため位置埋め込みをRotary positional embeddingsに
-
GeGLU Activations
- ReLUではなくGeGLUを利用
-
Normalizer Location
- transformerのレイターの正規化
2. 学習インフラ
-
チップ
- TPUv5eチップを利用
- 事前学習に7Bモデルは4096個
- 事前学習に2Bモデルはは512個
-
JaxとPathwaysを利用
- 一つのPythonプロセスでトレーニングをオーケストレーション
-
カーボンフットプリント
- TPUデータセンターからのエネルギー使用量から ~131
tCO_2eq
- TPUデータセンターからのエネルギー使用量から ~131
3. 事前学習 Pretraining
3.1. 学習データ
-
データの種類
- 2Bは2兆トークン、7Bは6兆トークン
- ウェブドキュメント、数学、コード
- マルチモーダルではない
- マルチリンガルのタスクのための学習は行われていない
-
トークナイザー
- GeminiのSentencePieceトークナイザーを利用
- 数字は分割され、余分な空白は削除せず、不明トークンはバイトレベルのエンコーディングを使用
- 語彙サイズは256kトークン
3.2. フィルタリング
- 不適切な表現、個人情報、機密情報
- 検証用データを排除
Geminiでの経験を活かして、関連性が高く質の高いデータを学習プロセスの最後の方にモデルが多く学習するようにデータセットを編集。
4. 事後学習 Instruction Tuning
-
概要
- supervised fine-tuning
- テキストのみ
- 英語のみ
- 生成されたものと人間が作ったものが混じったprompt-resposeのペア
- RLHF
- 報酬モデルは英語のみで学習されている
- 両方のプロセスが大事
- supervised fine-tuning
4.1. Supervised Fine-Tuning
-
LM-based side-by-side evaluation
- まず特定のprompt群でテストモデルに回答を生成させる
- 同じprompt群でベースラインモデルに回答を生成させる
- 2つの回答群をシャッフル
- より強いモデルを使って良い方の回答を選ばせる
- prompt群は特定のタスクを表すように作られている(Instruction following, factuality, creativity, safety)
4.2. フィルタリング
- 生成されたデータ(synthetic data)を用いる際は個人情報、不適切な表現、mistaken self-identification data、重複を省いた
- Geminiの経験を活かし、ハルシネーションを抑えるための良いデータを利用すると指標がよくなる
4.3. フォーマット
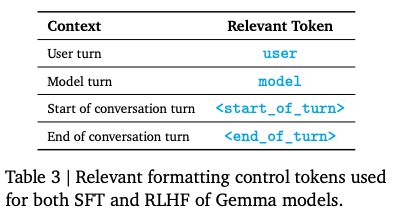

4.4. Reinforcement Learning from Human Feedback
- 報酬関数:Bradley-Terry model
- Reward hackingが起こらないようにより強いモデルで自動で評価をした
5. 評価
5.1. 人間による評価
- 人間にMistral v0.2 Instructのモデルと比較してもらった

5.2. 自動評価
- MMLUでは同じサイズのモデル全てに勝利、LLaMA2 13Bにも勝利
- MMLUで人間を超えたGeminiのスコア(89.8%)には届かず
- 数学とコーディングで性能を発揮

5.3. Memorization評価
-
Memorizationとは
- モデルがAlignされていても、Alignmentを回避するような出力をさせる攻撃がある
- 学習データにあった文章を「記憶」してそのまま出力されるのは困る
- 語義は以下を参照
- https://genlaw.org/glossary.html
-
評価方法
- 学習データから10000個のデータを抽出し、最初の50tokenをpromptとして入れた
- 同じくらいのモデルサイズのPaLMと比べた
-
結果
- 逐語的な評価
- webに関してはGemmaとPaLMはあまり学習データに被りがなくPaLMの学習データセットで評価を行ったらGemmaが低くなった
- All Contentにするとより信頼できる評価ができた

- 個人情報
- Google Cloud Data Loss Prevention (DLP) toolを使用

- Google Cloud Data Loss Prevention (DLP) toolを使用
- Approximate Memorization
- 言い換えられていても同じ情報を吐き出している可能性があるので 10% edit distance thresholdで言い換えを同定
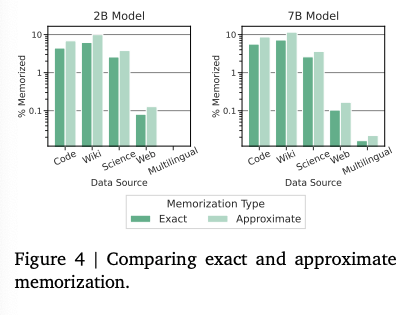
- 言い換えられていても同じ情報を吐き出している可能性があるので 10% edit distance thresholdで言い換えを同定
- 逐語的な評価
6. Responsible Deployment
Gemmaの技術的に特有のことは特に書いてないので興味があったら読んでみてください。
7. 結論
- 我々はテキストとコードのための生成言語モデルの公開可能なファミリーであるGemmaを発表する。
- Gemmaは公開可能な言語モデルの性能、安全性、及び責任ある開発の最先端を推進する。
- 広範な安全評価と軽減策を踏まえ、Gemmaモデルがコミュニティに純粋な利益を提供すると確信している。
- このリリースは取り消し不可能であり、オープンモデルから生じる害はまだ十分に定義されていないため、これらのモデルの潜在的なリスクに見合った評価と安全軽減を続けて採用している。
- 我々のモデルは6つの標準的な安全ベンチマークで競合他社を上回り、人間による横並びの評価でも優れている。
- Gemmaモデルは、対話、推論、数学、コード生成を含む幅広いドメインでの性能を向上させる。
- MMLU(64.3%)とMBPP(44.4%)の結果は、Gemmaの高性能と、公開可能なLLMの性能における継続的な余地を示している。
- ベンチマークタスクでの最先端の性能測定を超えて、新しいユースケースや新しい能力がコミュニティから生じることを楽しみにしている。
- 研究者が幅広い研究を加速するためにGemmaを使用し、開発者が有益な新しいアプリケーション、ユーザーエクスペリエンス、及びその他の機能を作成することを望む。
- Gemmaは、コード、データ、アーキテクチャ、指示チューニング、人間のフィードバックからの強化学習、及び評価を含むGeminiモデルプログラムの多くの学習から恩恵を受けている。
- LLMの使用に対する非包括的な制限セットを繰り返す。
- ベンチマークタスクでの優れた性能であっても、意図した通りに確実に機能する堅牢で安全なモデルを作成するためには、さらなる研究が必要である。
- さらなる研究分野の例には、事実性、アラインメント、複雑な推論、敵対的入力に対する堅牢性が含まれる。
- より挑戦的で堅牢なベンチマークの必要性を指摘する。
【 学生/社会人 エンジニア募集中!】
neoAIでは、ともに「次の時代のAI産業を創る」プロフェッショナルな仲間を募集しています。
neoAIは「生成AI」を強みに持つ東京大学松尾研発AIスタートアップです。我々は、生成AIを、世界を大きく変える不可逆なうねりであると捉えています。
世界が大きく変わりうる中で、時代の最先端であり続け、ともに成長できる未来の仲間との出会いを楽しみにしています。

Discussion