はじめに
はじめまして。株式会社neoAIの研究開発組織 (neoAI Research) の山本勇太です。
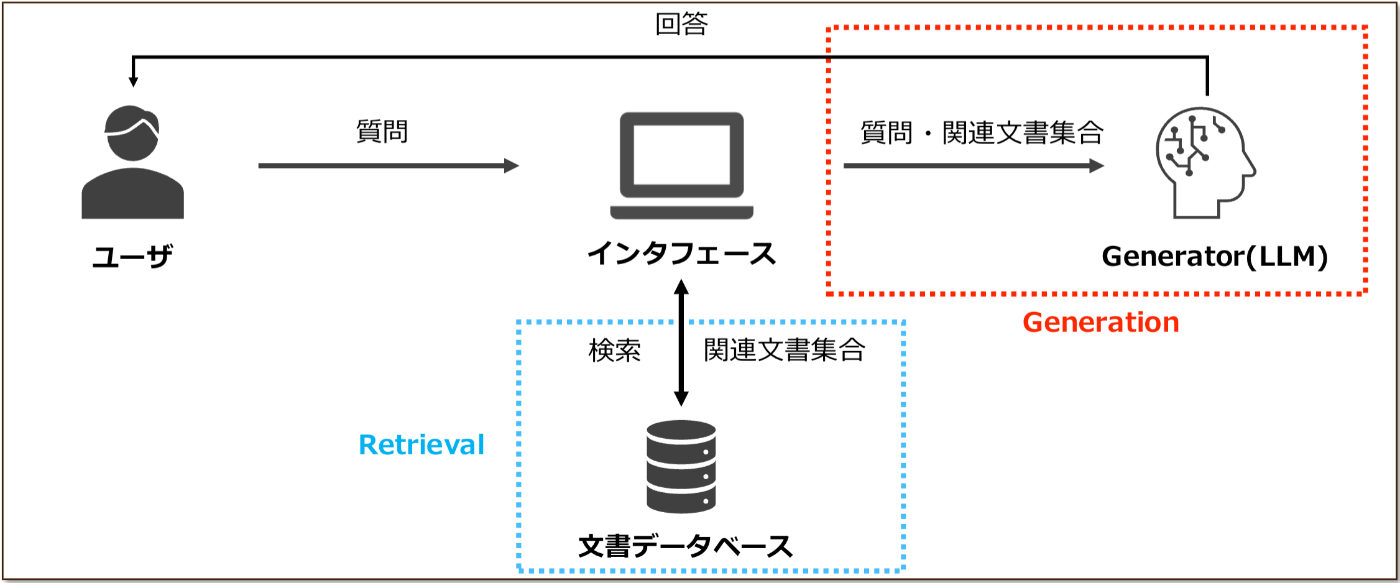
昨今、RAG(Retrieval-Augmented Generation)の実用化が急速に進展しています。RAGは、入力クエリをもとに検索器(Retriever)が文書データから関連文書群を取得し、それに基づき大規模言語モデル(LLM)などの生成器(Generator)が回答を作成する手法です。
LLMは多様な組織から頻繁に新しいモデルが公開されており、RAGの実用上優れているモデル選定のニーズは高いです。したがって、RAGにおけるGenerator選定のための、実用上の能力評価は重要な課題であると言えます。
RAGを実際の現場で使う際は、Genaratorには、Retrieverが取得した関連文書から根拠を正確に抽出する能力だけでなく、複数の関連文書からの根拠の取得及び統合・多段階の推論・表形式の情報の解釈・根拠情報不在時の回答拒否、などの多面的な能力が求められます。
RAGのGeneratorを評価する既存ベンチマークとしてはFRAMES[1], RGB[2], Ragas[3]などが挙げられますが、これらのベンチマークには以下の課題があります。
- 評価できる能力が限定的
- 同時に複数の能力が求められる問題の不足
これらの課題から、新たに日本語RAGベンチマーク「J-RAGBench(Japanese RAG Generator Benchmark)」を構築しました。J-RAGBenchには以下の特徴があります。
- 評価観点の再定義:金融・製造業など多様な業界にRAGシステムを導入する過程で直面した課題を反映
- 複数評価観点が複数共起:実ユースケースを想定した高難易度な問題

本記事では、J-RAGBenchについて、詳しく解説していきます。
J-RAGBenchは、人手およびLLMを用いた合成手法により作成し、最終的に人手でフィルタリングをすることで、高品質なデータセットを実現しました。データセットは、以下のHugging Faceリポジトリにて公開しています!
本記事の内容は、第265回自然言語処理究会(NL研)での発表をもとに執筆しています。興味があれば、以下のスライドをご覧ください!
J-RAGBenchの概要
J-RAGBenchでは、実用上でGeneratorが求めれられる能力を5つの「評価カテゴリ」として定義しています(図1)。各評価カテゴリは、実ユースケースを踏まえた「評価観点」に細分化しています(図2)。
図1: J-RAGBenchの評価カテゴリ

図2: 評価カテゴリと評価観点
各問題は、主要カテゴリまたは例外カテゴリの評価観点が設定されています。主要カテゴリの評価観点については、2つまでの全ての組み合わせが網羅されるように設計しています。これにより、J-RAGBenchは、Generatorの実用上の能力を網羅的かつ統一的に評価することを可能とします。
また、従来のベンチマークでは、LLMが事前知識をもとに回答可能な問題が多く、純粋な外部文書参照能力の評価には課題がありました。この課題にアプローチの一つとして、架空シナリオに基づく評価手法が挙げられます[4]。本ベンチマークにおいても、架空のシナリオに基づく問題を採用することで、Generatorの純粋な外部文書参照能力の評価を可能にしました。
各評価カテゴリ・評価観点の説明
J-RAGBenchの5つの評価カテゴリは、以下の能力を問うものとしてで定義しています。
- 情報統合:複数の文書から情報を取得し、統合する能力
- 推論:文書から情報を取得した上で、推論を行う能力
- 論理条件の解釈:質問と文書間にある表現の差異を、論理的に解釈する能力
- 表形式の解釈:文書にある表形式の情報を解釈し、情報を取得する能力
- 回答拒否:文書に情報の不足・矛盾がある場合に、回答を拒否する能力
本節では、問題例とともに、各評価カテゴリの詳細について紹介します。
1. 情報統合(Information Integration: Integration)
「複数の文書から根拠となる情報を取得した上で、それらの情報を統合し、回答を生成する能力」を問う評価カテゴリです。問題例を以下に示します。

図3: 評価観点「複数情報源からの統合」を問う問題の例
例えば、この問題であれば、質問に答えるためには、「Vertex Sky Degitail社の新卒募集要項」と「Nimbus Degital社の新卒採用要項」の2つの文書からそれぞれ情報を抜き出す必要があります。
2. 推論(Reasoning)
「文書から根拠となる情報を取得した上で、その情報をもとに推論を行い、回答を生成する能力」を問う評価カテゴリです。問題例を以下に示します。
この評価カテゴリは、以下2つの評価観点に細分化しています。
- 数値計算:文書から根拠となる情報を取得した上で数値計算を行い、回答を生成する能力
- マルチホップ推論:文書から根拠となる情報を取得した上で段階的な推論を行い、回答を生成する能力

図4: 評価観点「マルチホップ推論」を問う問題の例
例えば、この問題であれば、質問に答えるためには、文書から「永遠の風見鶏の主演は鈴木陽一」・「鈴木陽一は新木春奈と結婚」という情報を抜き出し、演繹的な推論を行い「永遠の風見鶏の主演は新木春奈と結婚している」という結論を導き出す必要があります。
3. 論理条件の解釈(Logic)
実際のビジネスでRAGを使用する際は、ユーザの質問と文章の記述に表現の違いが生じる場合があります。この評価カテゴリは、そのような場合を想定したものであり、「論理的な関係性をもとに、質問と根拠となる情報との表現の差異を解釈し、回答を生成する能力」を問うものとして定義しています。
この評価カテゴリは、上記の能力を以下3つの評価観点に細分化しています。
- 同義関係の解釈:概念包含関係の解釈:質問と文書の異なる表現から、意味的な同義関係を解釈し、回答を生成する能力
意味的な同義関係の例: 10千円=10,000円
- 数値包含関係の解釈:概念包含関係の解釈:質問と文書の異なる表現から、数値的な包含関係を解釈し、回答を生成する能力
数値的な包含関係の例: 35歳は、40歳未満に含まれる
- 概念包含関係の解釈:質問と文書の異なる表現から、概念的な包含関係を解釈し、回答を生成する能力
概念的な包含関係の例: ノイズキャンセリングイヤホンは電子機器に含まれる
問題例を以下に示します。

図5: 評価観点「概念包含関係の解釈」を問う問題の例
例えば、この問題であれば、質問に答えるためには、「電子機器の使用は厳禁である」という情報を取得した上で「通信機器は電子機器に含まれる」という概念的な包含関係を解釈し、「通信機器の使用は厳禁であるためオンライン会議はできない」という結論を導き出す必要があります。
4. 表形式の解釈(Table)
「表形式(HTML,markdown,csv形式)を解釈して根拠を抽出し、回答を生成する能力」を問う評価カテゴリです。
この評価カテゴリは、上記の能力を以下4つの評価観点に細分化しています。
- HTML形式:HTML形式の情報から根拠を抽出し、回答を生成する能力
- セル結合を含むHTML形式:セル結合を含むHTML形式の情報から根拠を抽出し、回答を生成する能力
- Markdown形式:Markdown形式の情報から根拠を抽出し、回答を生成する能力
- CSV形式:CSV形式の情報から根拠を抽出し、回答を生成する能力
問題例を以下に示します。

図6: 評価観点「Markdown形式」を問う問題の例
例えば、この問題であれば、質問に答えるためには、Markdown形式の情報を解釈し、「グローバリンク社帰任者数の推移 2019年度:2003人,2020年度:368人,2021年度:50人」という情報を取得する必要があります(ただし、この問題は数値包含関係の解釈も評価観点に含まれているので、その後に3つの人数を比較して「2019年度から2021年度にかけて減少した」と結論を出す必要があります)。
5. 回答拒否(Abstention)
「文書中に根拠情報の不足や矛盾があった際、それを指摘し回答を拒否する能力」を問う評価カテゴリです。この評価カテゴリは、上記の能力を以下3つの評価観点に細分化しています。
- 根拠不足:文書中に回答に必要な根拠が存在しておらず回答が不可能な場合に、回答を拒否する能力
- 根拠の矛盾:文書中に2つの矛盾した根拠が存在しおり回答が不可能な場合に、回答を拒否する能力
- 不完全なチャンク区切り:文書のチャンクが途中で区切れているために、根拠情報が不完全な状態で存在しており回答が不可能な場合に、回答を拒否する能力
問題例を以下に示します。

図6: 評価観点「根拠不足」を問う問題の例
例えば、この問題では、質問に答えるために必要な情報が一切提供されていません。したがって、Generatorは「与えられた文章に情報がない」という結論を出し、「グローバリンク社帰任者数の情報が提供されていないため、回答できません」と回答を拒否する必要があります。
問題の構成
J-RAGBenchの評価セットは、以下の要素から構成されています。
| 構成要素 | 含まれている内容 |
|---|---|
| question | 質問 |
| answer | 質問に対する正答 |
| positive contexts | 回答に必要な根拠が含まれているテキスト群 |
| negative contexts | 回答に必要な根拠が含まれていないテキスト群 |
評価方法
Generatorが生成した回答の評価には、LLMを用いた自動評価手法(LLM-as-a-Judge)を採用しました。評価器のLLMは、Generatorが生成した回答と正答が内容的に一致した場合に「1」、そうでない場合に「0」をスコアとして出力するようになっています。

J-RAGBenchにおける性能指標は正解率であり、総合正解率・各評価カテゴリを以下のように定義し、算出しています。
- 総合正解率:全ての問題の正解率
- 各評価カテゴリの正解率:その評価カテゴリを含む全問題の正解率。ReasoningとLogicの評価カテゴリを問う問題であれば、その両方のカテゴリにスコアが加算されます。
実験
J-RAGBenchを用いて、API提供モデルとオープンウェイトモデルを含む、日本語の生成が可能な各種LLMの評価を行いました。本節では、各モデルの正解率と分析結果について報告します。
評価対象のモデル
| モデル名 | バージョン | 開発元 |
|---|---|---|
| GPT5† | 2025-08-07 | OpenAI |
| GPT5 mini† | 2025-08-07 | OpenAI |
| GPT5 nano† | 2025-08-07 | OpenAI |
| o3† | 2025-04-16 | OpenAI |
| o4 mini† | 2025-04-16 | OpenAI |
| GPT 4.1 | 2025-04-14 | OpenAI |
| GPT 4.1 mini | 2025-04-14 | OpenAI |
| Gemini 2.5 Flash | 2025-05-17 | |
| Gemini 2.5 Pro† | 2025-06-17 | |
| Claude Sonnet 4 | 2025-05-14 | Anthropic |
表1: 評価対象のAPI提供モデル(†は推論モデル)
| モデル名 | 開発元 |
|---|---|
| Gemma 3 27B Instruct | |
| Llama 3.1 8B Instruct | Meta |
| Llama 3.3 70B Instruct | Meta |
| Qwen3 235B A22B Instruct | Alibaba |
| Qwen3 235B A22B Thinking† | Alibaba |
表2: 評価対象のオープンウェイトモデル(†は推論モデル)
実験設定
モデル間の比較を公平に行うため、正解率の測定は、以下の条件に統一して行いました。
- サンプリングパラメーター:temperature=0.0, top_p=1.0 (設定可能なモデルのみ)
- 推論モデルの思考トークンの設定長は最長に設定
- 評価器のモデル:GPT-4.1
総合正解率
各モデルの総合正解率は図8の通りです。

図8: 各モデルの総合正解率
総合正解率が最も高かったのはGPT-5で、0.872でした。次いで高かったのはQwen3 235B A22B Instructで、0.859でした。全体としては、API提供のモデルが高いスコアを示し、小・中規模サイズのオープンウェイトモデルは低いスコアを示す結果となりました。
評価カテゴリごとの正解率
各モデルの評価カテゴリごとの正解率は表3の通りです。

表3: 各モデルの評価カテゴリごとの正解率
評価カテゴリ別で最も高いスコアを示したのは、IntegrationがGemini 2.5 Flash,GPT5 mini,o4 mini,GPT4.1 mini,Qwen3 235B A22B Instruct,Qwen3 235B A22B Thinking、Reasoningがo3、Logicがo3とo4 mini、TableがGemini 2.5 Flashとo4 mini、AbstentionがClaude Sonnet 4でした。これらの結果から、モデルごとに能力観点の差異に関する特徴が定量的に確認できるようになりました。
各モデルの特徴(主にAPIモデル)
- GPT-5:バランス型。どのカテゴリのスコアも他のモデルと比較して突出して高いわけではないが、全体的にバランスが良く高いスコアを示している
- o3, o4 mini:思考型。抽出した情報から推論をし回答を導くことが得意。一方で、回答拒否
能力は他のAPIモデルと比較すると低めであり、知識の捏造(根拠となる情報が存在しないにも関わらず関連するもっともらしい知識を生成する現象)にあたるハルシネーションをしやすい傾向がある - Claude Sonnet 4:高信頼型。retrievalしてきた情報から回答が生成できない場合に適切に回答拒否を行うことが得意で、知識の捏造を起こしにくい。一方で、他の能力は他のAPIモデルと比較すると低めである
この結果から、J-RAGBenchを用いることで、実際に実運用時のモデル選定における大きなヒントが得られることが分かります。例えば、様々なタスクをバランスよく遂行してほしい場合はGPT-5、信頼性を最優先に置きたい場合はClaude Sonnet 4、のように考えることができます。
定性分析
情報統合
複数の情報が並列して記載されており、かつ一部のみ記述の粒度が異なる場合に、粒度が異なる部分の情報を適切に認識できずに回答を誤るケースが複数見られました。

図9: 実際の問題と誤答の例
この結果から、RAGシステムにおいてデータソースの品質や粒度が不均一な場合、LLMが回答を誤りやすいことが分かりました。実用上では、ドキュメントの構造化や正規化といった前処理が重要であることが改めて確認できました。
推論
数値計算の評価観点を含む問題では、計算式を立てた後の四則演算に失敗し回答を誤るケースがしばしば見られました。
また、マルチホップ推論の評価観点を含む問題では、小・中規模のオープンウェイトモデルやAPI提供のminiモデルなどで、与えられた情報からマルチホップ推論をし回答を導くことができずに、直接的な情報がないことを理由に回答を拒否する現象が多く見られました。

図10: 実際の問題と誤答の例
論理関係の解釈
論理関係の解釈の評価カテゴリを含む問題では、多くのAPI提供モデルが0.85以上の高い正解率を示しました。しかし、同義表現の解釈を必要とする問題では、o4 miniなどの高いスコアを示したモデルにおいても、単位の変換に失敗し回答を誤るケースが見られました。

図11: 実際の問題と誤答の例
表形式の解釈
表形式の解釈を評価カテゴリを含む問題では、多くのモデルが表の基本的な行列構造は理解し、正しい回答を導くことができていました。しかし、セル結合や複雑なヘッダー構造を含む問題では、表を適切に認識できずに回答を誤るケースが複数見られました。

図12: 実際の問題と誤答の例
また、表が複数チャンクに分割された表から情報を抽出する必要がある問題では、小・中規模のオープンウェイトモデルのほとんどが情報を抽出することができずに、回答を拒否する現象が複数見られました。実用上、文字数の多い大きな表が意図せず複数のチャンクに分割されることは十分に起こりえます。したがって、実用上では、Generatorに表を入力する際には表の再構成などの前処理を行うことが重要であると考えられます。
回答拒否
根拠不足の評価観点を問う問題では、多くのモデルで知識の捏造によるハルシネーション(根拠となる情報が存在しないにも関わらず関連するもっともらしい知識を生成する現象)が見られました。特に、o3やo4 miniなどの推論モデルや小・中規模のオープンウェイトモデルでは、このような現象が頻出しました。一方、Claude Sonnet 4ではこの現象は1件も発生しませんでした。
知識の捏造はしばしば、モデルが質問のキーワードに過剰に反応し、誤った情報抽出を行うことで発生します。

図13: 実際の問題と誤答の例
この例では、回答に必要な情報である北蔡京市のシェアサイクルの料金表が与えられていないために回答が不可能であるにもかかわらず、モデルが「シェアサイクル 料金表」という関連するキーワードに反応してしまい別の市の料金表を根拠情報として誤った回答を生成してしまっています。
まとめ
私たちは、RAGにおけるGeneratorの実運用能力を包括的に評価するベンチマーク「J-RAGBench」を構築しました。J-RAGBenchでは、実用上でGeneratorが求めれられる能力を情報統合・推論・論理条件の解釈・表形式の解釈・回答拒否という5つの評価カテゴリに体系化し、それらの組み合わせを網羅した114問のデータセットを構築しました。また、構築したデータセットを用いてAPI提供のモデルとオープンウェイトモデルのLLMで評価実験を行った結果、RAGの実運用上におけるモデル間の得意・不得意が定量的に明らかになりました。この結果は、RAG のGenerator選定において、用途に応じた適切なモデル選択が重要であることを示唆しています。
おわりに
こちらのテックブログは,画像生成やLLM開発などを通して、社内の技術力を先導しているneoAIの研究組織「neoAI Research」メンバーで執筆しています。
「未来を創る生成AIの先駆者になろう」
neoAIでは最先端技術を駆使するプロフェッショナル集団として,業務効率化を超えて社会に新たな価値を創出していきます.あなたの好奇心と可能性を,neoAIで開花させてみませんか?
【現在採用強化中です!】
- AIエンジニア/PM職
- Biz Dev
- 自社プロダクトエンジニア職
- オープンポジション
【詳しい採用情報はこちらから!】
-
Krishna, S., Krishna, K., Mohananey, A., Schwarcz, S., Stambler, A., Upadhyay, S. and Faruqui, M.:Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1:Long Papers) (Chiruzzo, L., Ritter, A. and Wang, L., eds.), Albuquerque, New Mexico, Association for Com-
putational Linguistics, pp. 4745–4759 (online), DOI:10.18653/v1/2025.naacl-long.243 (2025). ↩︎ -
Chen, J., Lin, H., Han, X. and Sun, L.: Benchmarking large language models in retrieval-augmented generation, Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, No. 16, pp. 17754–17762 (online), DOI: 10.1609/aaai.v38i16.29728 (2024) ↩︎

Discussion
こんにちは。huggingfaceのリンクが404になってしまうのですが、公開閉じてしまいましたか?
コメントありがとうございます。現在publicになっておりますので、ご確認お願いします。