Clean Architectureを読んだまま実装してみた(TypeScript, Go)



Why?
Clean Architectureを通読してみたが、抽象論が多いのでやっぱり書いてみないとな、と思った次第。
いろいろな方のClean Architectureの記事があるものの、当方Typescripterなので馴染む言語で写経すると理解が深まるだろう。
Assumption
- フレームワーク・ライブラリ非依存。Clean Architecture の構造だけ再現するので、サーバフレームワークやORMなどは使用しない。
- 命名はClean Architectureに出てきたままを心がける。一部、原文でも表現がブレているのは都合よく拝借。
Clean Architecture Overview
Clean Architectureといえばこの図。
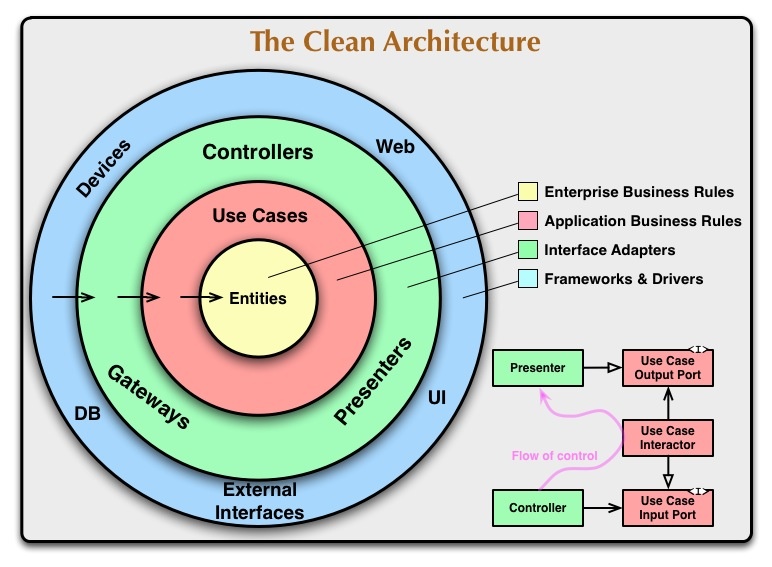
最重要エンティティであるビジネスロジックを中心に、アプリケーションロジック、インターフェースアダプター、フレームワークやDBの順で依存方向を不可逆に整理することを表している。
なぜ依存関係が重要か?ビジネスロジックは本質的にソフトウェアがどう作られているかに無関係であり、例えばデータベースがSQLからNoSQLに変更になってもビジネスロジックが影響されてはならない。依存関係を単方向にすることは、バグを減らし、保守性を高め、ソフトウェアの寿命を伸ばすことに繋がる。
OOPの設計原則であるSOLID原則にしたがってこれを実現する。
SOLID principles
SRP: Single Responsibility Principle (単一責任の原則)
コードは担う責任を単一になるようモジュール分割すること。
OCP: Open-Closed Principle (オープン・クローズドの原則)
ソフトウェアは拡張にはオープンであり、変更には閉じていること。
LSP: Liskov Substitution Principle (リスコフの置換原則)
親クラスから継承されたサブクラスたちは相互に置換可能であること。
ISP: Interface Segregation Principle (インターフェース分離の原則)
インターフェースを分離し、必要のないメソッドやプロパティに依存させないこと。
DIP: Dependency Inversion Principle (依存関係逆転の原則)
具体的な実装に依存せず、抽象インターフェースに依存することで依存関係を反転させること。
Dependency Inversion
注目すべきは、LSP(リスコフの置換原則)とDIP(依存関係逆転の原則)。所謂ポリモーフィックの仕組みを使って依存関係を反転し(Dependency Inversion)、方向を一定に保つことが肝要。
典型的な例として、Usecase層がデータを永続化したい場合、データベースへ直接アクセスすると依存方向が逆流してしまう。Interfaceを定義し、データアクセスを抽象化させることで依存関係を反転させる。
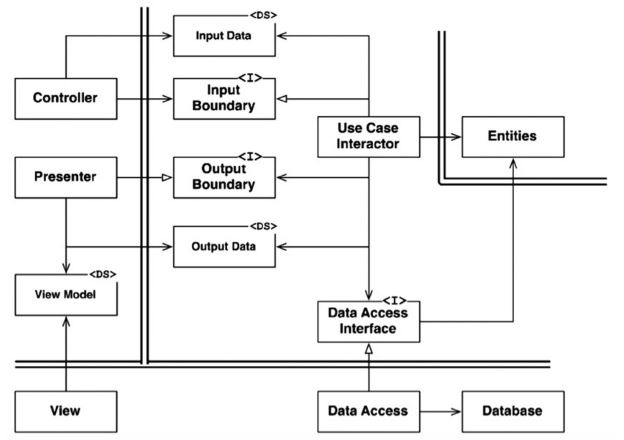
// usecaseでDataAccess Interfaceを定義
interface DataAccess {
save(x: number): void;
}
class SampleUsecase {
// 抽象インターフェースであるDataAccessに依存
private dataAccess: DataAccess;
constructor(dataAccess: DataAccess) {
this.dataAccess = dataAccess;
}
public async save(input: number): Promise<void> {
// save() の内部実装はusecaseは関与しない。
await this.dataAccess.save(input);
}
}
// gatewayでDataAccess Interfaceを実装
class SampleGateway implements DataAccess {
save() {
// Databaseへの永続化処理
}
}
class SampleController {
private gateway: SampleGateway;
constructor(gateway: SampleGateway) {
this.gateway = gateway;
}
async save(value: number) {
// DataAccessの実装であるgatewayを注入(Depedency Injenction)
const usecase = new SampleUsecase(this.gateway);
await usecase.save(value);
}
};
// gatewayのインスタンス化とControllerへの依存性注入。
const gateway = new SampleGateway(this.database);
const controller = new SampleController(gateway);
controller.save(100);
Output
作ったものは以下。ついでにGoでも書いてみた。
基本的な文法のみを使い、フレームワーク・ライブラリ非依存のプレーンなコードなため、プロジェクトの初期コードとして使い道がありそう。
Question?
書いてみて疑問が残った。DataAccessの実装はどこになるか?原文には以下のようにある。
ユースケースインタラクターとデータベースの間にあるのが「データベースゲートウェイ」である。このゲートウェイは、アプリケーションがデータベースに対して実行する作成・読み取り・更新・削除のメソッドを含んだポリモーフィックインターフェイスである。(中略)
ユースケース層のレイヤーでSQLの使用を許可しなかったことを思い出してほしい。その代わり、ゲートウェイにメソッドを用意して使うようにした。ゲートウェイはデータベースのレイヤーにあるクラスで実装する。
円の概念図を見るとGatewayはUsecaseの外側だが、「ゲートウェイはデータベースのレイヤーにあるクラスで実装する」とある。また、Gatewayが抽象インターフェイスであるならば、DataAccessインターフェイスとふたつの永続化インターフェースが存在することになりはしないだろうか?
今回は疑問はありつつもGateway層でDataAccessの実装をする設計にしてみた。そうなると、SQLなりで永続化をするならば、ORMなどのライブラリに依存することになり、依存方向が維持できない点も引っかかる。インターフェースアダプター層がユースケースとライブラリを繋ぐレイヤーであれば、それぞれのAPI呼び出す必然性があると考えて今のところ許容している。
Discussion
私も気になったので、今の自分の考えを書いてみます。
厳密にやろうとするとORMのようなライブラリがインフラ層(一番外側)でそれを使ってCURDした結果をentityに変換して返す部分がゲートウェイ層になると思います。
で特定のORMに沿ったインターフェースを定義せざるをえないので、依存関係を逆転させにくいし、メリットがない気がしています。
実際にはGateway(私はDB関係はレポジトリという名前を使っています)にORMライブラリをインポートして、呼び出していて、DBのエンティティからCAの一番内側のエンティティに変換するようなコードとし、1層で2層の役割を担う形で書くことが多いです。
そうですね。ここで原則に拘りすぎるとかけるコストの割に冗長で理解しづらい構成になってしまうと感じました。
訳書の問題かと思い、Unble Bobのオリジナルブログを読んでみましたが、SQL自体をInterface Adapters層で書くのは間違いなさそうですし、その時点でDatabase(ORM含む)に依存するのは避けられないので著者の説く「インターフェースアダプター層」はそういう役割なんだと解釈しました。
ありがとうございます。あまりボブおじさんのブログ読んだことなかったので理解深まりました!
4層にこだわる必要がないとはいえ、実際にディレクトリ構成考えると迷いますよね。
個人的には内側の2層(UseCaseとEntity)とその外側で論理的な部分と外界で分けるのが大事なのかなと感じています。
仰る通りで、原文にも同様の記載があります。このコンセプトはヘキサゴナルアーキテクチャもオニオンアーキテクチャも本質的に差はなく、ソフトウェア設計の一つのパラダイムなんでしょうね。