GKEシングルクラスタ構成で障害発生してサービス停止しちゃったのでマルチクラスタ構成にした話
GKEシングルクラスタ構成でサービスを運用していたところ、ある日突然クラスタが壊れてサービスが停止してしまいました。この記事では、障害の発生から対応までの流れ、マルチクラスタ構成の比較検討および決めてについて紹介します。
障害の発生から対応までの流れ
元のサービス構成
1つのGKEクラスタにアプリケーションをデプロイしていました。ノードプールは5つあり、ノード数は10-15台ぐらいの規模です。Ingressでロードバランサーを作成し、AWS Route53を使ってルーティングしていました。
発生した事象
GCPコンソールのGKEクラスタ一覧ページでNode数の表示が0台になりました。コントロールプレーンも死んでしまった様子で、kubectlコマンドが一切使えなくなり、GCPコンソールのGKEクラスタ詳細ページでは、以下のアラートメッセージが表示されていました。
Auto-repairing nodes in the node pool.
The values shown below will be updated once the operation finishes.
Upgrading nodes in the node pool. A single node upgrade typically takes 4-5 minutes, but may be slower (e.g., due to pod disruption budget or grace period). Learn more
0% -- 0 out of 5 nodes done
この状態が数時間以上続いており、Nodeが全滅していたので、もちろんサービスは稼働してない状況でした。
障害が発生したきっかけ
一番可能性が高いと考えているのは、コントロールプレーンのIPローテーションを行ったことです。また、きっかけが複合的なものだった可能性も考えており、コントロールプレーンの自動アップグレードかノードプールの自動アップグレードがコントロールプレーンのIPローテーションと同時に行れた可能性があり、それが原因だったかもしれません。
GCPに問い合わせて調査をしていただきましたが、結局原因はわからずという結論で終わったしまいました。
暫定対応
障害の発生したGKEクラスタを削除してから、新規にGKEクラスタを作成し、サービスをデプロイしなおしました。
恒久対応
- GKEクラスタをマルチクラスタ構成にし冗長化する
- 障害が発生した場合は、リクエストを正常なクラスタへフェイルオーバーさせる
- メンテナンスの時間枠と除外を設定し、複数のクラスタが同時に自動アップデートが行われないようにする
- 定期的に行っていたコントロールプレーンのIPローテーションを行わないようにする
マルチクラスタ構成の比較検討
達成したいこと
- あるGKEクラスタに障害が発生してもサービスを継続的に提供できるようにする
- あるGKEクラスタに障害が発生したら、自動で正常なクラスタにトラフィックを流す
冗長化構成の3つのパターン
GKEの冗長化構成のパターンは大きくわけて3つのパターンがあります。
③のパターンではLoadBalancerを管理するクラスタが壊れてしまうとサービスを提供できなくなる恐れがありました。今回は、どのGKEクラスタが壊れてもサービスを提供できる必要があるので、①と②のパターンについて比較検討しました。
| パターン | イメージ図 |
|---|---|
| ①AnthosのMultiClusterIngressを使いLoadBalancerで分散する | 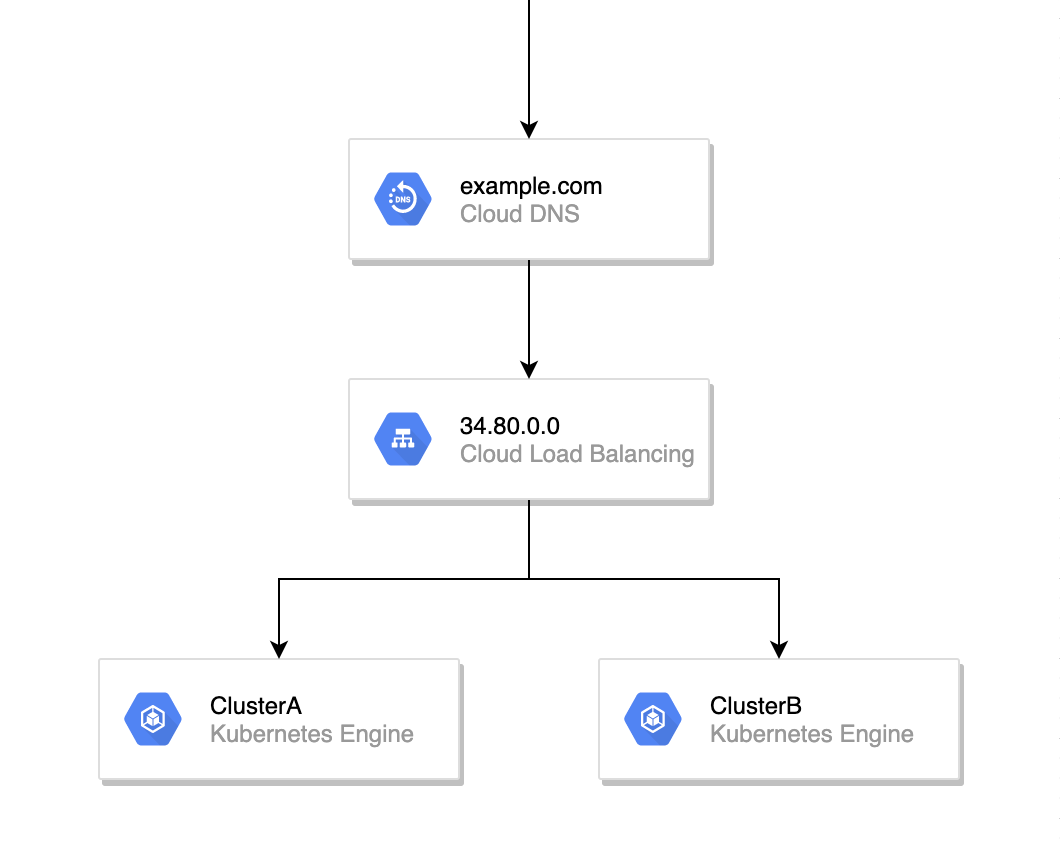 |
| ②DNSで分散する |  |
| ③MultiClusterにまたがるServiceMeshで分散する(Anthos Service Mesh) |  |
①AnthosのMultiClusterIngressを使いLoadBalancerで分散する
Anthosの概要
AnthosのMultiClusterService/MultiClusterIngressを利用すると、同一IPアドレスを利用して複数リージョンにまたがる複数のクラスタに対してリクエストを転送することができます。さらに、リクエスト元の地理情報に基づいて最適なクラスタへのルーティングを行ってくれたり、あるクラスタのサービスが正常に動作していない場合は正常に動作しているクラスタへトラフィックを流してくれます。
Anthosは従来一部サービスだけ利用したい場合にもAnthos利用料がかかっていましたが、最近料金体型が変わって個別サービスごとの従量課金制にかわったので、料金面でよりお得に利用することができます。
ここまでで、今回実現したいことが実現できそうなことがわかりました。では、具体的にAnthosのMultiClusterService/MultiClusterIngressを構築する方法について調べました。
Anthosの構成方法
まず、Anthosで利用するクラスタをフリート(旧environ)に登録する必要があります。フリートは1つのGoogleProjectにつき1つしか存在しません(参照)。そして、フリートに登録したクラスタのうち、1つのクラスタを構成クラスタとして設定します。構成クラスタにMultiClusterIngressやMultiClusterServiceをデプロイすることで、フリートに存在する他のクラスタにヘッドレスServiceを作成し、それらのサービスへロードバランシングを行ってくれます。ただし、構成クラスタとして登録できるクラスタは1つのみです(参照)
実際に構成すると以下の図のようになります。構成クラスタとアプリケーションをデプロイするクラスタを完全に分離するという構成もとれましたが、インフラをなるべくシンプルにしておきたかったのでこの構成にしました。構成クラスタにデプロイしたMultiClusterIngressがロードバランサーを作成し、構成クラスタにデプロイしたMultiClusterServiceがフリートに所属するクラスタにServiceを作成してくれます。
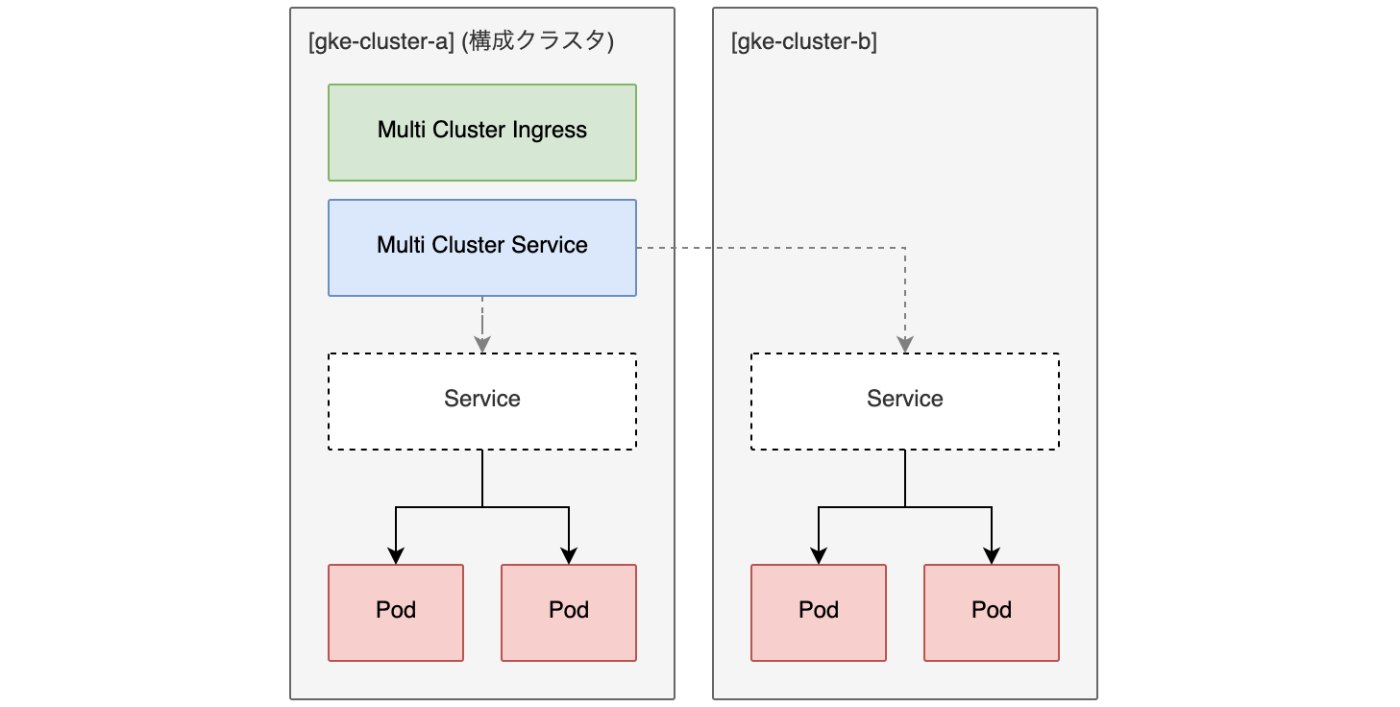
この図を見た時、構成クラスタだけ特別なリソースを作成するのはインフラ構成がより複雑になってしまうので嫌だなと思いました。
また、この構成だと構成クラスタに障害が発生してしまったときにはどうなるのでしょうか? 公式ドキュメントによると、
構成クラスタは一元的に管理する場所であるため、構成クラスタ API を使用できない場合、Ingress for Anthos リソースの作成または更新ができなくなります。ロードバランサとロードバランサによって処理されるトラフィックに対しては、構成クラスタの停止による影響はありません。
なので、サービスは継続的に提供できるが、MultiClusterIngressとMultiClusterServiceの変更ができなくなる、ということになります。
そこで、なるべくシンプル、かつ、構成クラスタに障害が発生してもすぐに別のクラスタを構成クラスタに設定できるようにするために次の構成がよいと思います。
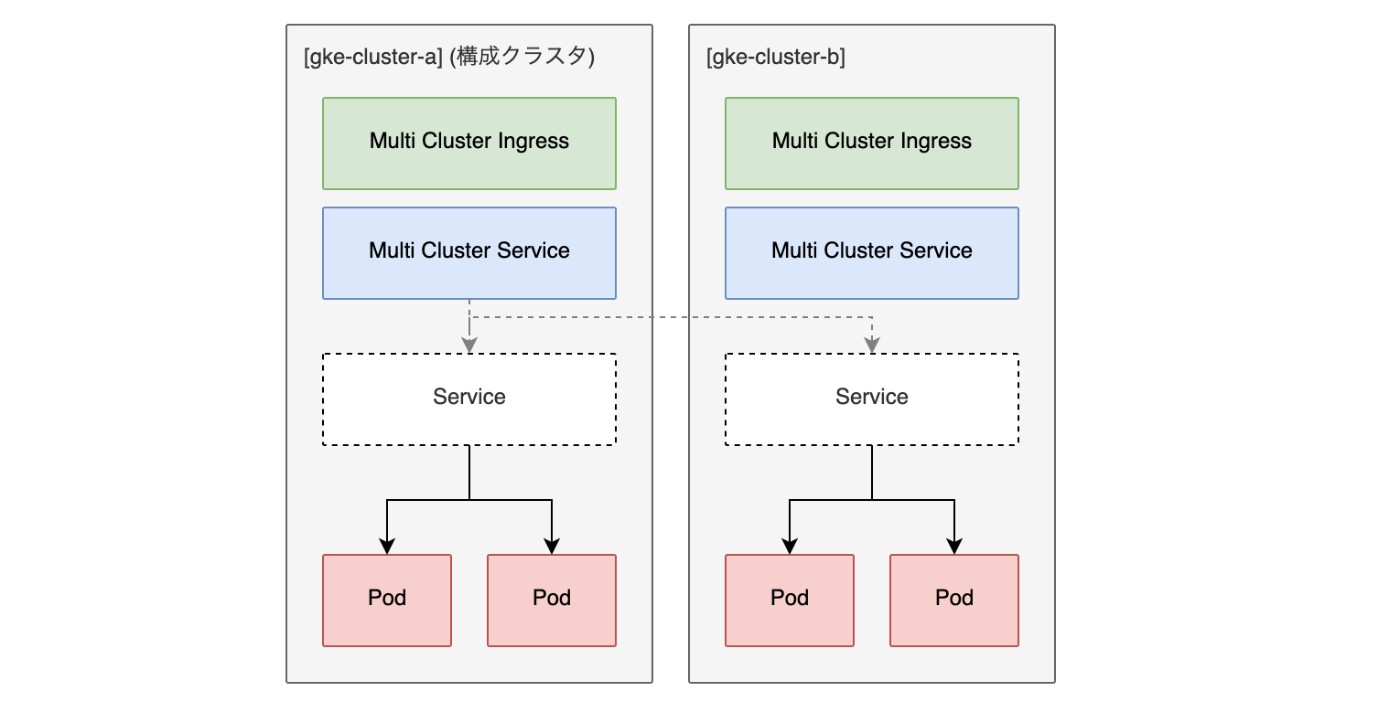
gke-cluster-bにgke-cluster-aと全く同じMultiClusterIngerssとMultiClusterServiceをデプロイしておきます。構成クラスタはMultiClusterIngerssとMultiClusterServiceを使用できる唯一のクラスタなので(参照)、gke-cluster-bにデプロイされているMultiClusterIngerssとMultiClusterServiceは実際には何の役にも立ちませんが重要です。同一のMultiClusterIngerssとMultiClusterServiceを持つ別のクラスタを構成クラスタに設定するときに影響を受けないので(参照)、構成クラスタをgke-cluster-aからgke-cluster-bにいつでも変更するこができます。 なので、もしgke-cluster-aに障害が発生してしまったら、構成クラスタをgke-cluster-bに切り替えるだけでよいのです。
Anthosのデメリット
ここまでみるとAnthosによる構成に全く問題がないように感じたのですが、個人的に割とデメリットだなと思ったのは、フリートは1つのGoogleProjectにつき1つしか存在しない、ということです。なぜなら、上で紹介したAnthosの構成では、既存のアプリケーションに一切変更を加えずにGKEクラスタを作り直すのができなくなってしまうからです。
Anthosを利用しない場合、個人的には次のような流れで行いたいです。
-
- 既存のクラスタでサービスを稼働させ続けたまま、新しいクラスタを作成する
-
- 新しいクラスタにアプリケーションをデプロイし、新しいロードバランサーも作成する
-
-
hostsを書き換えるなどして新しいクラスタで正常に動作をするか確認する
-
-
- DNSのルーティングを切り替え、新しいクラスタへトラフィックを流す
フリートを1つのGoogleProjectで複数個作れれば、新しいフリートに新規サービスを構築しDNSルーティングを切り替えるということで上の流れを実現できますが、フリートが1つしか存在できないのでそれはできません。
では、Anthosを使ってる場合、どうやったら新規にクラスタを作成し、動作確認を行い、最後にルーティングするといったことができるようになるのか? それはMultiClusterIngressとMultiClusterServiceをごりごり変更して、新規クラスタのためのロードバランサーとサービスを作成することです。この場合、既存のアプリケーションを動かしているクラスタへの変更も行ってしまうためかなり慎重に行う必要がありますし、新しいクラスタ用のMultiClusterIngressとMultiClusterServiceを作成する必要があるのでMultiClusterIngressとMultiClusterServiceの構成がより複雑になってしまいます。
Anthosのまとめ
- メリット
- ヘルスチェックを行いフェイルオーバーしてくれるので障害が発生してもダウンタイムがほぼ発生することなくサービスを提供し続けることができる
- マルチリージョン構成にした場合は、アクセス元に地理的に近いクラスタへルーティングしてくれる
- デメリット
- 既存のアプリケーションに一切変更を加えずにGKEクラスタを作り直すのができなくなってしまう
②DNSで分散する
概要
この構成はAnthosを使った場合よりもシンプルです。まず、シングルクラスタにデプロイしているアプリケーションと全く同じものを複数台のクラスタにデプロイします。すると、クラスタの台数分のロードバランサーが作成されるので、DNSでルーティングしてあげれば完了です。
ただし、これだけでは今回実現したかった「あるGKEクラスタに障害が発生したら、自動で正常なクラスタにトラフィックを流す」ができません。そこでAWS Route53のヘルスチェックを使った構成を考えました。
AWS Route53での構成方法
まず、シングルクラスタにデプロイしているアプリケーションと全く同じものを複数台のクラスタにデプロイします。クラスタの台数分のロードバランサーが作成されるので、それらに対する AWS Route53のヘルスチェックを作成します。
次にレコードの作成をします。DNSフェイルオーバーか複数値回答ルーティングのどちらでもよいです。複数のクラスタのうち、稼働系と待機系を分けたい場合はDNSフェイルオーバーにし、ランダムに分散させたい場合は複数値回答ルーティングを利用します。
重要なのはTTLをなるべく短くしておくことです。なぜなら、DNSはキャッシュされてしまうからです。障害発生時にヘルスチェックが失敗し、数十秒後にはDNSの回答から異常なIPアドレスが返ってこなくなります。しかし、DNSキャッシュを持っている場合、そのキャッシュが無効になり再度DNSに問い合わせが来るまでは異常なIPアドレスへの接続をしてしまいます。
この構成では、AWS Route53のヘルスチェックが失敗した場合、成功しているロードバランサーへのIPアドレスを回答してくれるので、あるクラスタに障害が発生した場合に自動で正常なクラスタにトラフィックを流すことができます
DNSで分散のデメリット
DNSキャッシュを持ってるユーザーは、異常が発生した場合にダウンタイムが数分〜数十分ほど発生してしまうことです。
DNSで分散のまとめ
- メリット
- インフラの構成がAnthosに比べてシンプル
- デメリット
- 異常が発生した場合にダウンタイムが数分〜数十分ほど発生してしまう
今回選んだ構成と決め手
以上のことから、今回僕は②DNSで分散するパターンでマルチクラスタを構築することにしました。
まず、①AnthosのMultiClusterIngressを使いLoadBalancerで分散するパターンでも②DNSで分散するパターンでも、今回達成したことを実現することができます。あとはメリット、デメリット、僕のチーム状況を比べました。今回の選択に至ったポイントは以下です
- インフラの構成をなるべくシンプルにしておきたかった
- 異常が発生した場合にダウンタイムの数分〜数十分を許容できた
- 対応完了までが早い
- 必要になったら将来的に
①AnthosのMultiClusterIngressを使いLoadBalancerで分散するにすればよい
インフラの構成をなるべくシンプルにしておきたかった
僕のいるチームではフロントバックエンド合わせてエンジニア10人ほどでインフラ専属の担当者がいません。なので、インフラ構成を複雑にすること、また、みんなが理解しておく必要のある技術を導入することに抵抗がありました。
インフラ構成が複雑になれば、実装ミスによる障害発生の確率も高くなりますし、開発や修正のペースも下がってしまいます。Anthosについては今回の検証で僕がいろいろ調べ動作検証を行なっていたので僕は理解したのですが、僕以外の誰もAnthosを知っている人はいません。なので、Anthosを導入する場合それ相応のコストをかけなければ僕以外の人でもメンテできるようにはなりません。もちろん将来的にはそうすべきだと思うのですが、サービスのフェーズ的にまだそこにコストをかける段階ではないと判断しました。
異常が発生した場合にダウンタイムの数分〜数十分を許容できた
当然、障害発生時にもダウンタイムが生じないに越したことはないですが、ダウンタイムが発生した場合にダウンする時間と障害発生によるダウンタイムが発生する可能性を考慮したときに許容するという判断をしました。
ダウンタイムが発生した場合にダウンする時間は、数分~数十分の見込みですが、仮にこれだけの時間サービスが停止したとしても月で見たときのサービスの稼働率99.5%以上を達成することはできます。僕らのサービスのSLOが99.5%なので、計算上はそれに到達できる見込みです。
そして、障害発生によるダウンタイムが発生する可能性は極めて低いと考えています。なぜなら、開発期間を含めて2年ほどクラスタを稼働させていましたが一度も発生したことがないし、Googleのサポートの方とやりとりをしましたが他で同じことが起きてる事例など参考できる情報もないとのことでしたし、今回の障害が発生したきっかけで一番可能性が高いコントロールプレーンのIPローテーションをやめたからです。
また、サービスのフェーズ的にもまだこのレアケースにコストを支払う段階ではないという理由もあります。
最後に
まとめ
GKEをシングルクラスタ構成で運用していたら原因不明の障害が発生したので、マルチクラスタ構成にして冗長化しました。突然片方のクラスタが壊れてもサービスを提供し続けられるマルチクラスタ構成のパターンは①AnthosのMultiClusterIngressを使いLoadBalancerで分散するか②DNSで分散するの2つあります。①AnthosのMultiClusterIngressを使いLoadBalancerで分散するの方が機能的に優れているがインフラ構成が複雑で、②DNSで分散するは障害発生時にDNSキャッシュによるダウンタイムが発生してしまうがインフラ構成をシンプルに保てます。そこで、僕らのチーム規模とサービスのフェーズ的に、②DNSで分散するという構成を選択しました。
他社事例
ちょうどGoogleのOpen Cloud Summitが開催されており、特にAnthosについてたくさん発表されていました。その中で特に僕らのシチュエーションに近く参考になったのがOpen Cloud Summitでの日本新聞社でのAnthos導入事例です。この記事とは違う結論に至っていますが、実際にAnthosを導入してマルチクラスタ構成にした事例として勉強になりました。
Discussion