ECS (EC2起動タイプ) が永遠に起動しない場合の対処法 #初心者
概要
Amazon ECSをEC2起動タイプで起動させようとした際、デプロイ中という表示がされたままの状態が数時間続く事象が発生しました。
具体的には、以下の表示が続きました。
「<サービス名>のデプロイが進行中です。これには数分かかります。」
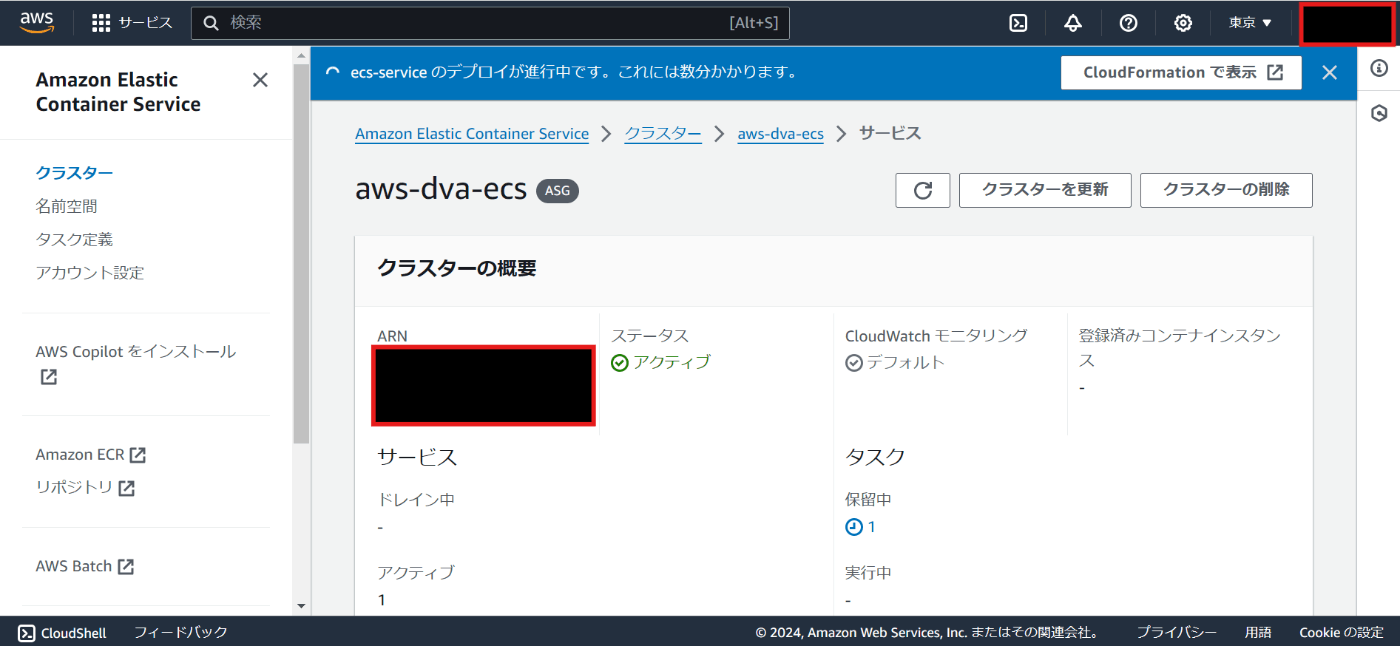
サービスを開いてタスクタブを表示すると、ずっとプロビジョニングのまま
※CloudFormationを見に行くと、 CREATE_IN_PROGRESS の表示がされたまま
数時間放置しておくと、タイムアウトのためか失敗しますが、ログも出ない。
検索しても情報が出てこないため、それなりに時間を使ってしまいました。
関連記事)タスクは起動するけどコンテナに接続できない場合:
結論
原因はEC2のリソース不足でした。
そのため、以下の設定を変える必要があります。
- ECSのタスク定義のインフラストラクチャの要件を変える
- EC2のリソースを増やす
1. ECSのタスク定義のインフラストラクチャの要件を変える
私は、こちらの方法で、今回の事象を回避しました。
- 「ECS > タスク定義 > インフラストラクチャの要件 > タスクサイズ」でCPUとメモリを小さくする
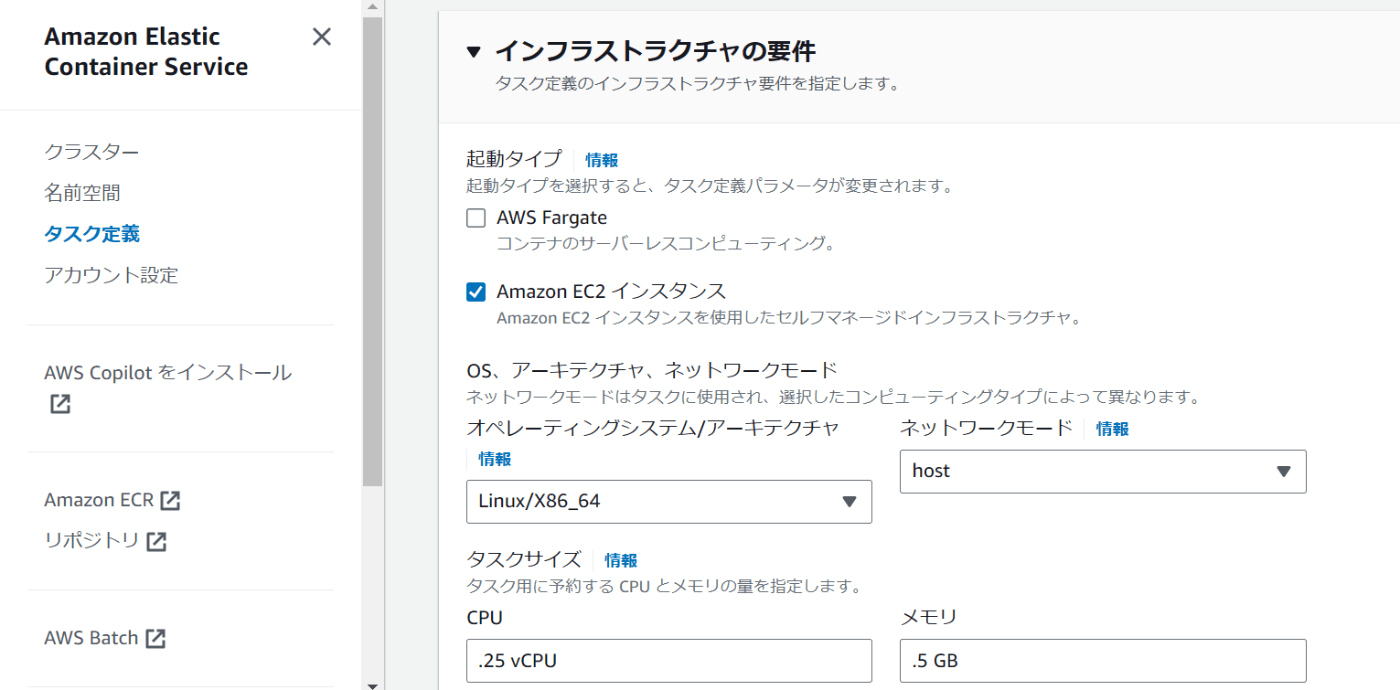
- 「ECS > タスク定義 > コンテナ > リソース割り当て制限 - (条件付き)」でCPUとメモリを小さくする

※私は、t2.micro を使っていました (1vCPU, 1GiB)
→実際に使えるリソースはもう少し小さいので、ECSのタスク定義では 0.25vCPU, 0.5GiB で設定しました。
※(2024/11/04追記)EC2起動タイプの場合、CPUは省略可能です。メモリサイズも上記の1か2の一方だけ入力すればよいです。(公式リファレンス)
2. EC2のリソースを増やす
EC2のリソースは、インスタンス数かインスタンスタイプ(CPU, メモリ量)のいずれかが足りていないので、オートスケールの設定等を設定し直します。
目的
ここから先は、事象の詳細や原因、調査したことを書いていきます。
別の原因でお困りの方でも、調査したこと(=トラブルシューティングの様子)を記載するので、参考になるかもしれません。
本文
事象
概要に書いた通りで以下の表示が長時間続きました。
「<サービス名>のデプロイが進行中です。これには数分かかります。」
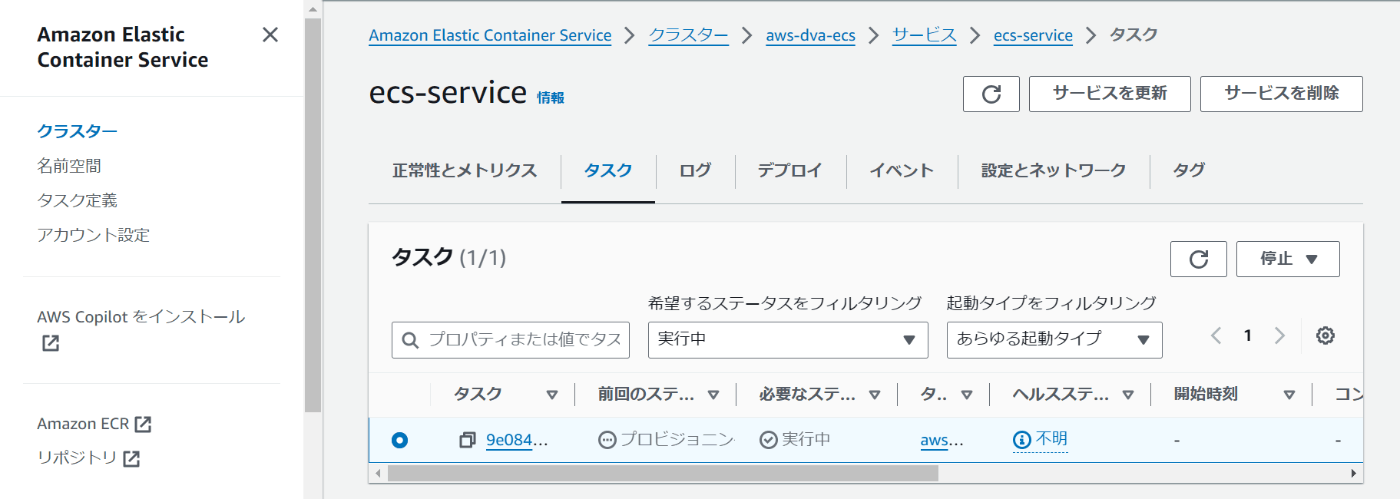
サービスを開いてタスクタブを表示すると、ずっとプロビジョニングのまま
※CloudFormationを見に行くと、 CREATE_IN_PROGRESS の表示がされたまま
また、特にログも出ていない状況でした。
原因
こちらも記載した通り、結局リソース不足です。
リソースが足りないため、タスクが実行待ち(=プロビジョニング)となってしまうようです。
- ECSさんとしては、リソースが足りないので、Auto Scalingでスケール待ち
- CloudFormationさんとしては、ECSのタスク待ちなので、ずっと
CREATE_IN_PROGRESS - 一方で、Auto Scalingには適切な設定をしていないので、スケールされることはない
ちなみに、EC2を無料枠の小さいサイズのインスタンスを使っていたのも原因でした。
トラブルシューティングの様子
以下は、原因特定のために試してみたことです:
- ローカルでdockerを実行する
- Fargateで試してみる
- sshでEC2インスタンスに接続する
ローカルでdockerを実行する
当然ですが、こちらは正常に動きました。
ただし、docker runコマンドと同じようにECSのタスク定義をしているか?は確認する価値があると思います。
→環境変数やport mappingなどが違うと正常に動かない場合があると思います
Fargateで試してみる
こちらは正常に起動しました。
※当時はダメ元だったので、驚きました。
原因が、EC2のリソース不足なので、Fargate(サーバレスでリソース管理は自動)では起動したわけです。
sshでEC2インスタンスに接続する
最終的に、トラブルシューティングとして一番確実だと思います。
前提として、AutoScalingでキーペア生成の設定が必要です。
ちなみに、Session Managerを使う方法もありますが、別のAMIを使う必要がありそうで諦めました(ECS用のAMIを使用しているため)
EC2上で試したことは以下の通りです。
-
docker pullしてdocker runする- →正常起動しました。やっていることはローカル実行と同じなので、当然かもです。
-
sudo systemctl status ecsでecsエージェントを確認する- →特に問題なし
- ちなみに再起動も試しました(
sudo systemctl stop ecs→sudo systemctl start ecs)
-
sudo cat /var/log/ecs/ecs-agent.logでecsエージェントのログを確認する- →エラーログ(以下)を発見した。と思ったらlevelはinfo。その後、自動でバージョンアップされていたようで関係なし。
level=info time=2024-08-18T10:31:41Z msg="Unable to get Docker client for version 1.17: Error response from daemon: client version 1.17 is too old. Minimum supported API version is 1.24, please upgrade
- →chatgpt曰く「WebSocket接続が頻繁に切断され、再接続されている」→特に関係なかったよう。
- →結論、特に問題なし。
- →エラーログ(以下)を発見した。と思ったらlevelはinfo。その後、自動でバージョンアップされていたようで関係なし。
-
curl http://localhost:51678/v1/tasksで実行中のタスクを表示- →レスポンスは空白でタスクがなかった→ここで問題に気付く
- →chatgptにも聞きつつ、タスクがそもそも実行されていない(=プロビジョニング)になっていること・リソース不足が原因であることを特定
まとめ
リソース不足には注意。
ちなみに、(初心者とはいえ)半日程度トラブルシューティングに要してしまった。
Discussion