こんにちは、NE株式会社でSREロールとして勤務していますenumuraと申します。
この記事では「MySQLは多少わかる(完全に理解した)」な人が「雰囲気で運用するんじゃなくて、ちゃんとした運用ができるようになりたい! とりあえず監視体制を整備する!」となったときに、どのように進めていったかを記していきます。
対象となる読者
この記事の想定している読者ですが、「MySQLは触ったことがあるし、とりあえず動かすことはできるけれども、なにか問題があったら涙目で調べないとわからない」ぐらいのスキルとなります。(1年半前の自分)
具体的にはこんな感じの方を想定しています。
- MySQL/Aurora MySQLを使っている。
- MySQLのインストールとinnodb_buffer_pool_size調整、レプリケーション設定や障害発生時の昇格作業とかはできる。
- MySQLのモニタリング環境が整っておらず、しっかりと整備したいと考えているが何をして良いのかわからない。
- 社内にDBに詳しい人がいない、が、誰かがやらなければいけない。
- 正直DBについては雰囲気で運用している、という感覚が抜けない
組織内にDBAが置かれていなかったり、DBも含めてインフラ全体はこの部署にお任せ、みたいなところだとこうなるパターンも多いのでは? と思っています。
背景
そもそもなぜDBの運用を整えたいのか、監視体制を整備したくなったのかと言う背景について説明させていただきます。
弊社サービスのネクストエンジンでは数年前から、サービスが稼働するインフラをオンプレミスからクラウド環境へのシフトするプロジェクトが開始されました。
そのプロジェクトの中でDBパフォーマンスの問題が発生し、その対応・検証のために移行開始が遅れてしまった苦い経験があります。
またクラウド移行後にコスト状況を可視化したところDBに関連する費用の割合がかなり高く、コスト効率の面からもDBパフォーマンスの改善を進めていきたいというモチベーションが高くなっていました。

お金に目がくらんだ人のイラストらしいです
一方で、それまでのオンプレ環境でのDBの監視については、Zabbixによるハードウェアメトリクスとクエリスループットぐらいしか取得されている情報はなく、その情報もなにか問題が発生した際にチェックする、という状態でした。
また、人員についてもオンプレでのLinux及びミドルウェア、パブリッククラウドに関してのスキル・経験を持ったメンバーはそれなりにいたものの、DBに秀でた経験やスキルを持つメンバーは不在でした。
クラウドシフト・コンテナ化直後ということもあり、メンバーのスキルもクラウド、コンテナ、サーバレスなどに偏っている状態であったため、ここでなにか手を打っておかないと、将来にもDB周辺だけが「なんとなく動いている」になってしまう恐れがあったため、誰もやらないならやってみるか! の気持ちで監視・運用を整えることにしました。

やる気を出した私(イメージ)
メトリクス監視
どんな改善を進めていくにせよ、まずは何が起こっているのかを把握するため、可視性を向上させないと始まりません。
とりあえず可能な限りメトリクスの取得項目を増やしていこう。ということでDatadogやNew Relicのようなサービスを使ってモニタリング環境を整えていきました。
弊社では当初Datadogを導入しておりましたが、現在はNew Relicへと移行しました。
メトリクスはその特性や取得対象から「ハードウェア」「ソフトウェア」「ユーザ体験」の3カテゴリに分けて考えます。

なんとなく三角にしてみましたが特に形状に意味はないです
ハードウェア(RDSの場合はOSも)
まずは下位のレイヤから。
CPU負荷や(OSレベルでの)ディスクIOなどハードウェア関連のメトリクスについては、RDSがCloudwatch Metricsとして提供している値を、New RelicのAWS Integrationで取り込んでいます。
値自体はCloudWatchのマネジメントコンソール画面から確認できるものと同一ではあるのですが、次項で述べるNew Relic MySQL Integrationとの組み合わせで「ハードウェアでとソフトウェア(MySQL)で発生している状況を同じ画面で比較」することが出来ます。
具体例として、下記の通りhistory list lengthの上昇と同じタイミングでCPU負荷も高くなり、トランザクションの完了とともにパージ処理が開始され落ち着いていく、というハードウェアとソフトウェアそれぞれに関連したメトリクスの動きを簡単に比較することが可能になります。

左がCPU使用率で右がhistory list lenth
オンプレミスやEC2などでMySQLを稼働させている場合は、ハードウェアとソフトウェアの間にOSのメトリクスも入ってくると思います。
弊社ではRDSを使用しているため、拡張モニタリングから取得可能な値も含め、ハードウェア・OS両方合わせてCloudWatch Metricsから取り込んでいます。
同様の機能はDatadogでも用意されていますので、どちらの製品を選択しても取得できる情報に大きな差はでないと思います。
ソフトウェア
次に、ソフトウェア(MySQL)から取得可能なメトリクスを可視化していきます。
New Relicが用意しているMySQL Integrationをセットアップ。
このIntegrationでどのようなメトリクスが取得されるかは、上記URLのMetrics collected by the integrationに詳しく記載されています。
先の例でも挙げた通り、特に弊社の環境ではhistory list lengthの値がグラフ化出来るのはありがたく、CPU負荷が上昇した際の素早い原因特定(長時間のトランザクションが原因か否か?)に役立っています。
ちなみにこちらのIntegrationについては、公式では仮想・物理マシン上のInfrastracture Agent上での稼働のみがサポートされていますが、EC2上で稼働しようとするとインスタンスの管理が発生してしまうので、下記のような仕組みでECS Fargate上でコンテナ化して動かしています。
監視対象となるDBインスタンスが増えた場合はMySQL Integraitonの設定ファイルであるmysql-config.ymlを修正してmainブランチにmergeすれば、GitHub Actionがコンテナイメージのビルド・Push・デプロイまでを自動で実施してくれます。

構成管理はGitHub上で行いデプロイはGitHub Actionsで実行
こちらについても、Datadogで同様のIntegrationが用意されています。
ユーザ体験
MySQLというソフトウェア、RDSというサービス自体に直接紐づいたメトリクスではありませんが、システムの健全性を一番的確に表す指標としてユーザ体験に関連するメトリクスも併せて見られるようにします。
具体的には、ゴールデンシグナルと呼ばれるもののうち「レイテンシ(ALBのTargetResponseTimeメトリクス)」「エラー(ALB/ターゲットグループのエラー)率」の2つを重点的に見ています。
これらのメトリクスは、MySQLとかDB関係ないものではありますが、システムの健全性を図るには必須のチェック項目となります。
先に挙げた2つ種類のメトリクス、例えばCPU負荷が常に90%になっていても、あるいはInnoDBバッファプールのヒット率が常に30%を割り込んでいるような状況であっても、それがユーザにとって悪影響が出ていなければ、システム自体の健全性は悪くなく、むしろハードウェアリソースを効率的に使えている、という捉え方もできると思います。(とはいえ、突発的なスパイクが発生しないという前提の話であり、大体の場合はそのような状況はいずれ破綻するパターンではありますが)
上記2つの種類のメトリクス(ハードウェア・ソフトウェア)を見て「何が起きているか」「何が原因か」を知ったうえで、「それがユーザにとってどのような影響を及ぼしているか、対応が必要な状況か」を判断するための最も重要なメトリクスが、この「ユーザ体験」となります。
ということで、これらもALBのCloudWatch MetricsからNew Relicに取り込んでいます。
バッチ処理時間
実はネクストエンジンではALBのメトリクス以外に、もう1つ大きなユーザ体験に関連する指標があり、それがバッチの実行時間です。
ネクストエンジンでは外部モールやカートとの連携処理を定時実行のバッチで処理しています。
例えばネクストエンジンの機能として複数モール・カートの在庫数を同じ値に更新する在庫連携という機能があります。
この在庫連携も定時実行のバッチで処理されているのですが、例えば処理の実行完了に1時間かかってしまった場合、あるモールAからの販売で在庫が枯渇しているにも関わらず、他のモールB,C,Dでは商品が売れ続ける、いわゆる「売り越し」が発生してしまう可能性が高くなります。
また同じように各モール・カートからの注文を取り込む処理も定時実行バッチで処理されていますが、この処理が数時間かかると、それだけ発送準備が遅れてしまい、場合によっては当日出荷を謳う商品の出荷が間に合わない、という事態も発生してしまいます。
このようにWebアクセスと併せて、バッチ処理にかかる時間も大きくユーザ体験に影響する値となります。
これらの値は当然New RelicやAWSが提供しているメトリクスでは読み取れない類のものとなります。
そのため、下記のような仕組みでDB上に保存されたバッチの「実行時間」と「待機時間」をNew Relicのカスタムメトリクスとして送信・可視化しています。

DB内のデータをカスタムメトリクスとしてNew Relicに送信
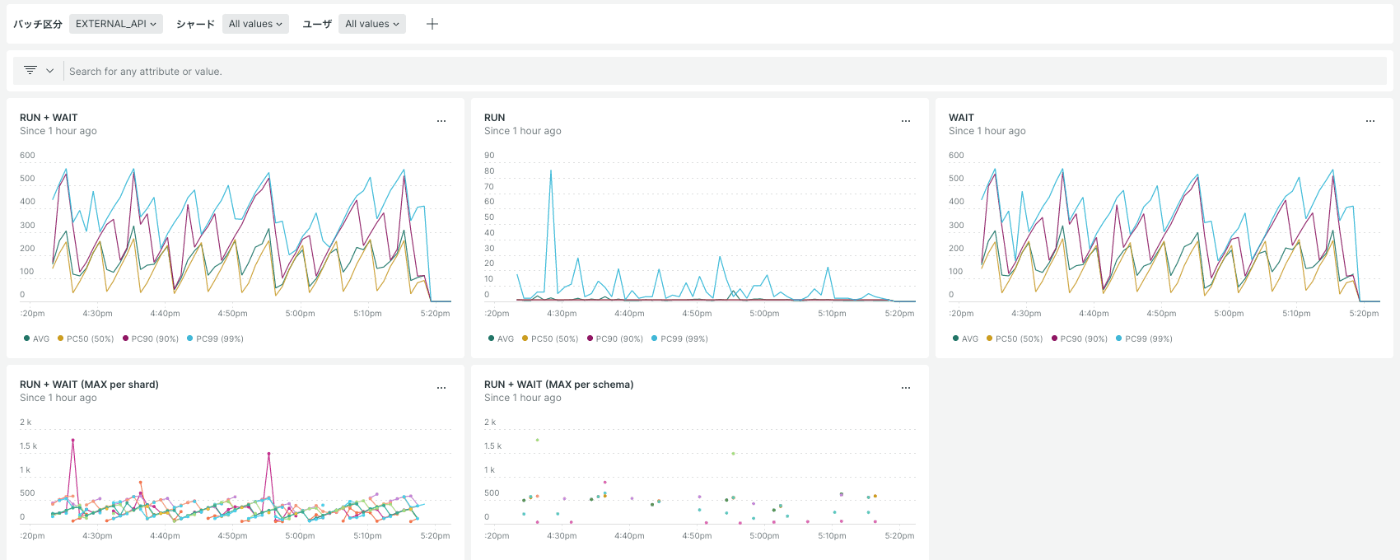
カスタムメトリクスをグラフ化したダッシュボード
単純な実行時間だけであればAPMからサンプリングされた値を見ることも可能ですが、バッチの同時実行制限に基づいた「待機時間」も存在するため、この仕組みを使って「実行時間 + 待機時間がバッチの実行間隔を超えていないか」を監視しています。
ダッシュボード整備
上記の通り取得設定を行ったメトリクス群を、New Relicのダッシュボード機能を使用してグラフ化していきます。
一連の仕組みを構築する中でここが一番悩ましかったポイントで、大量に取得されているメトリクスの中から、何を見るべきなのかというのか皆目検討もつかない状態でした。
(項目が多すぎても少なすぎても、本当に見るべきものを見落としてしまうリスクが有り、何が最適解なのか…)
最終的には視点を変えて「メトリクス自体は見えなくても保存されているのだから、まずは適当にグラフを並べてみて、必要なものを日々の運用の中で取捨選択していこう」という方針で進めることにしました。
今のところこの方針が上手くハマっていて、しばらく運用を続けていくとこんな感じでダッシュボードのアイテムを整理することが出来ました。

現在のDBに関するダッシュボード
- まず見るべきメトリクスはDB Load
- RDSのPerformance Insightsを有効にすることで取得可能になるCloudwatch Metrics。
- Performance Insights の Amazon CloudWatch メトリクス - Amazon Relational Database Service
- DB Loadの値が悪化している場合に連動して動いているメトリクス(パターンによって複数)があるので、それは残す。
- DB Loadが悪化しているがどのメトリクスも動いていない場合はPerformance Insightsの待機イベントの情報から、該当しそうなメトリクスのグラフを追加し確認する。
- 何回か上記の作業が繰り返されると、優先してチェックするメトリクスとそんなに見なくても大丈夫なメトリクスがわかってくるので整理していく。
システムの特性によって見るべきメトリクスは違ってくると思いますが、まずは1つ指標になるメトリクスを決めて(今回の場合はDB Load)、その動きに追従していると予想されるものをダッシュボードに追加していくという流れになります。
現状、弊社では主に下記のメトリクスを中心にタブ機能を使って分類分けしチェックしています。
(これ以外にもダッシュボードに置いてあるメトリクスはありますが、今のところ活用頻度は少ないです)
- DB Load
- DB Load CPU
- DB Load Non CPU
- クエリレイテンシ
- クレリスループット
- スロークエリ発生件数
- バッファプールヒット率
- 開放可能メモリ量
- コネクション・スレッド数
- CPU使用率
- OSレベルでのIO発生件数
- 読み取り行数(rows_read)
- InnoDBでのIO関連情報
- buffer_pool_reads
- buffer_pool_write_requests
- デッドロック発生件数
- 一時テーブル・ファイル作成件数
- history list length
- Full Join発生件数
- ストレージ関連
- ローカルストレージ空き容量
- クラスタボリューム使用容量
アラート
ここまででDBを取り巻く色々なメトリクスをダッシュボードで見られるようにしていきました。
次は異常が起きたときに素早く気づくためのアラート設定を進めていきます。
が、実はこちらについてはまだまだ運用が固まっておらず、そろそろ見直しのが必要かなー? といった感じの状態になっています。
最初にルールを策定した際に
「対応が不要なアラートが連発してオオカミ少年にならないように、ゴールデンシグナル以外のメトリクス悪化はアラートをトリガーしない」
という案が出されましたが、いきなりそれは厳しすぎるだろうということで
「アラートの通知先をCriticalとWarningに分けて、Criticalは最優先で対応する、Warningは気づいたメンバーがベストエフォートで調査する」
ということで運用が開始されました。
このルールでの運用はDB以外の箇所(Web・バッチサーバ)についてはある程度上手く回っているのですが、DBについては少しマッチしないかな… と感じています。
理由としては下記のとおりです。
- Webやバッチ処理などについてはクラウド化によって容易にスケールアウトが可能となったため、負荷による自動スケーリング、あるいはアラートが発生してから状況を見ながら手動でのスケーリング設定投入でも対応可能なケースが多い
- DBは容易なスケールアウト・スケールアップができないため、Webやバッチと比較して対応に時間がかかる
- とりあえずスケールアウトで様子見、という対応ができない。
- スケールアップはオンプレミスと比べれば実施可能な分だけかなりマシだが、再起動を伴うサービス停止時間が発生するため気軽には実施できない。
- ユーザ影響が出始めてから対応、では遅すぎになってしまう可能性が高い。
- そのためDBについてはCPU負荷などWarningレベルでのアラート対応がほぼ必須になっており、実質Criticalと同じになっている。
最初に決めたルールは絶対的なものではなく、実態に合わせてブラッシュアップしていくものだと思いますので、あくまでもこれから記載する内容は「とりあえず試してみたが改善の余地がありそうなもの」として読み進めていただけますと幸いです。

まだまだ整備中
アラートの仕組み
アラートの仕組みは基本的にはNew Relicに統一し、管理しているメトリクスの値が閾値を超えたらNew RelicのSlack Integrationを使って特定のチャンネルに対してメッセージを投げるようになっています。
インフラもアプリもメトリクスもログもNew Relicに集めてからアラート判定する
メトリクス以外のトリガーとしては、RDSで発生した再起動やフェイルオーバーなどの可用性に関するイベントをEventBridgeで拾ってNew Relic Logに送信。本番環境を表す特定のタグを含むRDSインスタンスだった場合はアラートを上げるように設定しています。
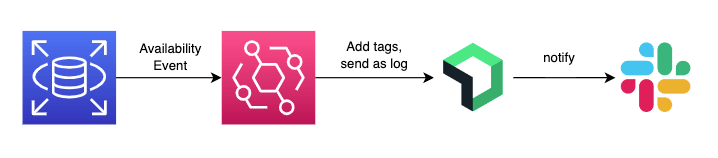
DBの可用性イベント通知の流れ New Relic logに取り込んでからアラート
運用を開始してからNew Relic自体のサービス障害によりアラートが正しく動作しないケースがあったので、ALBのゴールデンシグナルに限り、CloudWatch AlarmのほうでもSlackへの通知をするように追加しました。

ALBのアラートはCloudWatch Alarmでも通知
また、DevOps Guru for RDSを有効にして様子を見ています。
肌感ではなんか「これすごく良いのでは…!?」という予感がすごいので、アラートを見直す際にはうまいこと組み込んでいきたいと考えています。
アラート対象のメトリクスと閾値
アラートの対象となるメトリクスは、先述の通りALBから取得可能なものについては「TargetResponse Time」と「5xx発生件数」の2つを、
DBから取得可能なメトリクスとしてはAuroraのローカルストレージ使用率とCPU使用率(方針を変更して追加しました)を送信しています。
それぞれ、閾値の設定によってCriticalとWarningに分けて飛ばすようにしています。
ローカルストレージの使用率は放置しておいても解決しないケースがほとんどだと思います。
CPU使用率については、よりDBの負荷を図るのに適切なメトリクスとして、Performance Insightsを有効にしたRDSで取得可能なDB Loadに変更する予定です。
設定当初はクエリレイテンシ、バッファプールのヒット率、history list length、スローログ発生件数などなど、色々とアラートトリガーに追加したい誘惑に駆られましたが、現状のアラート項目だけでも大きな問題なく回せているので、次の見直しのタイミングまではこのままでいいかなーという感覚です。
改善のための仕組み
ここまでの作業でDBを中心としてシステム全体の健全性をNew Relicをベースに可視化し、問題が発生した際にはそれを通知する仕組みを構築しました。
次のステップとして、実施にアラートが発生した際にどういった手順で調査・対応を進めていくのかを記載してきます。
Performance Insights
システムに何らかの問題が発生して、それに伴いDBのメトリクスでもDB LoadやCPU使用率の上昇、バッファプールヒット率の低下などが見られた場合、その原因となっているセッション・クエリの特定を急ぐ必要があります。
AWSが提供しているPerformance Insightsを見ることでMySQLのレベルでどんな待機イベントでどのクエリが遅くなっているのかが、素早く把握することが出来ます。
待機イベントの種類は豊富で最初はなかなか有効活用が出来ていませんでしたが、ある程度慣れてくるとメトリクスだけの時と比べてかなり深いところまで改善ポイントを見つけ出すことができるようになりました。
いくつか例を挙げると
パフォ会でダッシュボードを眺めていると、毎日夜間の特定時間にDB Load/SELECTレイテンシの増加が発見されました。(移行前なのでDatadogのダッシュボード)

SLECTレイテンシ DB Loadのグラフは保存忘れていました…
CPU負荷、バッファプールヒット率、クエリスループットなどなど主要なメトリクスを見ても特にこの時間帯で増加していなかったため、メトリクスのグラフだけでは原因にはたどり着けずにいました。
そこでPerformance Insightsを確認してみると、wait/synch/rwlock/innodb/dict sys RWという待機イベントが増加していることが判明しました。
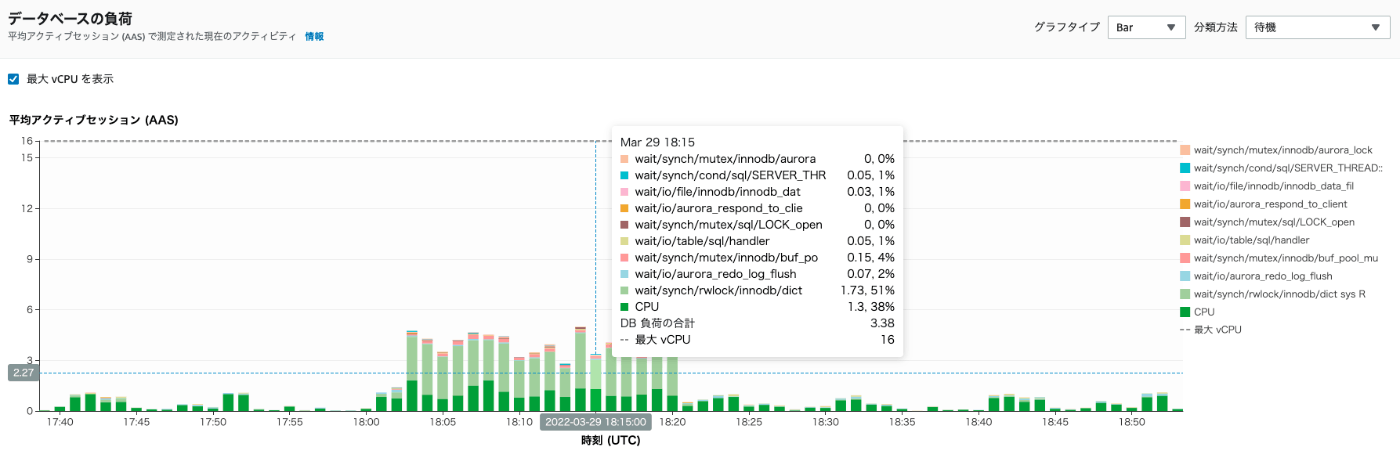
見慣れない待機イベントが増加していた
この待機イベントについては下記のページでこのように解説されています。
synch/rwlock/innodb/dict sys RW lock
データ定義言語コード (DDLs) 内の多数の同時データ制御言語ステートメント (DCLs) が同時にトリガーされます。通常のアプリケーションアクティビティ中に、アプリケーションの DDL への依存度を下げます。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Reference.Waitevents.html
この情報を元にこの時間に毎晩実施しているメンテナンス用のバッチ処理を確認したところ、ディスクスペース確保のためにINSERT/DELETEが頻繁に行われているテーブルをTRUNCATEしていることが判明しました。
元々は日中に分散して実施されていた処理でしたが、利用者数多い日中でのパフォーマンス影響を避けるために、夜間のメンテナンス処理に組み込んだところ処理が集中したためこのような状態になっていました。
この件については、利用者数が少ない時間帯であるため影響は少ないと判断し対応を見送りましたが、問題発見のためメトリクスでは足りない情報をPerformance Insightsが補ってくれた好例でした。
グラフ以外でもTop SQLやTop hosts, usersなどの情報も非常に有用で、どのユーザ・ホスト、どのスキーマでの処理が遅くなっているのかを可視化してくれます。

Top usersによるユーザごとの待機イベント割合

Top SQLによるクエリごとの待機イベント割合
Top SQLではSQL statementsに正規化されたSQLが記載されていますが、左の+アイコンをクリックして展開することで、個別のクエリが占める割合を表示することが可能です。
これはある待機イベントを占めるクエリが「特定の値だけのときに遅いのか」または「すべての値で遅いのか」を判別するのに役立ちます。
例えば、上の画像ではLoad by waits(AAS)のトップに位置しているクエリは、展開しても1行だけしか表示されないため1つのクエリだけが遅いことがわかります。
それに対して、下記の画像では1つの正規化されたクエリに対して、複数の値によるクエリがレポートされているので、クエリに渡された値によって遅くなっているのではなくクエリ自体が適切にインデックスを使用できていない可能性があります。
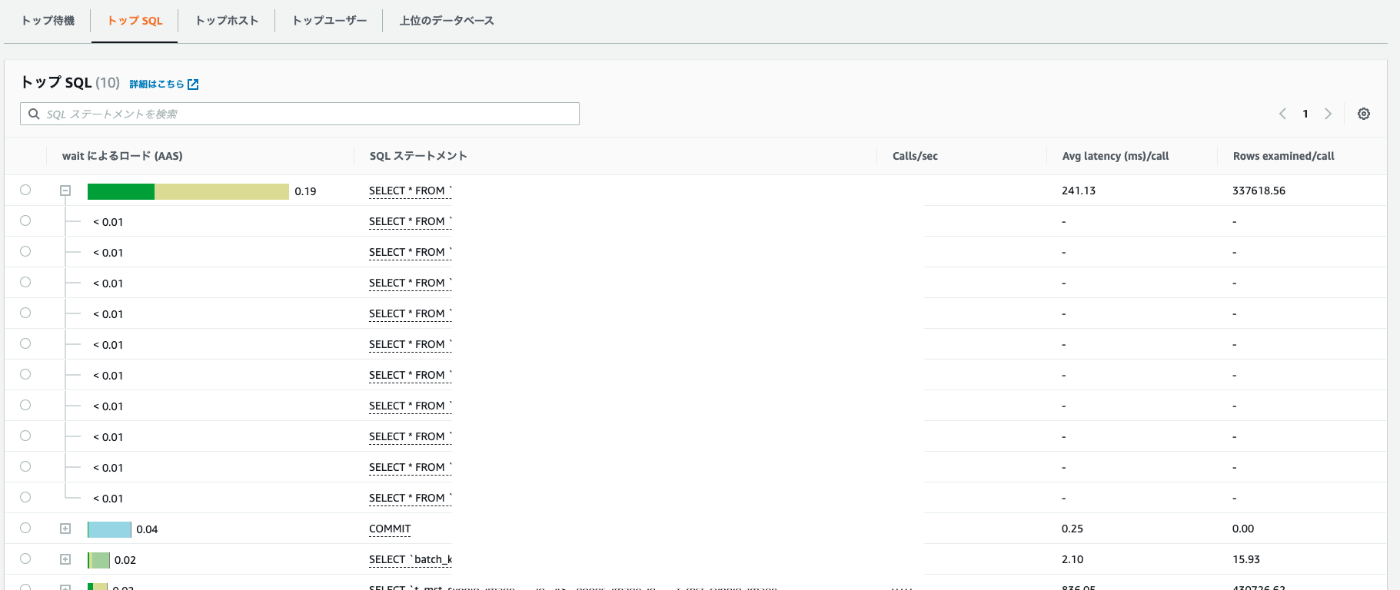
異なるパラメータの同じクエリが複数集まって待機イベントを占めている例
ただし、Performance Insightsのグラフで待機イベントを占めているとレポートされたクエリでも、根本的な負荷の原因ではないケースも存在します。
実際に弊社内であったケースでは、
REPEATABLE READで開始されたトランザクションが更新の多いテーブルをSELECTして、そのまま放置されてしまいhistory list lengthが伸び続け、CPU負荷が上昇。CPU負荷により全体のクエリが遅くなるため、Performance Insightsからは最も発行頻度の高いクエリがリストアップされる。というパターンが有りました。
この場合では、Peformance Insightsに表示されたクエリや該当のトランザクションを操作して解決する術はなく、原因となった放置されたトランザクション(Performance Insightsにはリストアップされない)を終了させる必要があります。
Performance Insightsでは待機グラフと共に、history list lengthやCloudWatch Metricsの値も表示することが可能なので、New Relicダッシュボードと情報の重複はあるものの、これらの情報も併せて総合的に調査・判断することで、問題解決を迅速に行うことが可能です。
APM
弊社では昨年からようやくAPMを本格導入することになりました。
これにより、インフラ・ミドルウェア周りだけでなく、アプリケーションの内部も可視化することで、更に迅速な問題対応を行えるようになってきています。
APMをDBの問題解決にどのように使っていったかは、弊社の畑野の記事でも詳しく書いてありますのでこちらを参照ください。
スロークエリ監視
ここまではDBやソフトウェアの異常をリアルタイムに検知して、大きな障害に発展する前に対応を行っていくというフローに関しての仕組みを解説してきました。
それらに加えて、日常的なDBパフォーマンスの改善活動のためにスロークエリを効率的に改善していくための仕組みを解説します。
弊社ではスロークエリの取り扱いが少し特殊で、スロークエリが検知されたらすぐに対応、というわけではなく一定数の発生を許容します。
というのも、マルチテナント構成である関係上、各ユーザによって保持するデータ量にかなり差があり、MySQLのlong_query_timeで指定された値を超過したとて、それが本当に「改善が可能なクエリか?」が判別できないためです。
また、ネクストエンジンではAPIを提供しており、その中に任意のカラムからデータを抽出するという機能も存在するため、インデックスが全く効かないクエリが発生する可能性もあります。
そのため、下記のような仕組みで1日1回、24時間で発生したスロークエリログをpt-query-digestに食わせて、その出力結果をGitHubにPushしています。
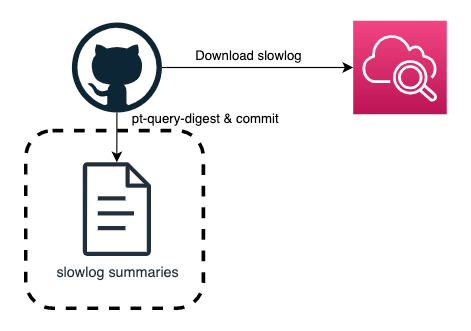
GitHub Actionsでpt-query-digestを実行
pt-query-digestの使い方や出力の読み方は割愛しますが、これによって「問題のスロークエリは全体のユーザで発生している、改修が必要ものか?」「どの程度の頻度で発生しているか、日をまたいで継続的に発生しているか」がわかり、重要度を判断することが可能になっています。
現状では1日1回の頻度で処理が実施され、出力に関してのアラートも特に設定されていないため、この仕組みを元に急ぎの対応が必要なケースというのは発生しませんが、長年の開発でたまり続けたよろしくないクエリたちを効率的に解消していくためのサポートツールとして稼働しています。
日々の運用
ここまでで構築した仕組みを組み合わせて、実際に下記のような運用を行っています。
- 1日1回、基本的には朝にNew Relicのメトリクスグラフをぼんやり眺める。
- 他のタスクとの兼ね合いにもなるが、アラートが出ていなくても明らかに変な動きをしているメトリクスがあれば調べてみる。
- 調査に時間がかかりそうだが、緊急度が低いものはAsanaのチケットとして記録しておく。
- 週1回アプリケーション担当メンバーを含めたパフォ会でシステム全体のメトリクスグラフを眺める。
- DBについてはDB Loadを中心に見ておき、システム全体でおかしい点が見つかった場合は深掘りのために他のメトリクスを見ていく。
- 要調査なものについてはAsanaに起票して担当者をアサイン。優先度低めならば次週のパフォ会を目処に調査する。
- 1〜2週間に1回スロークエリの集計結果を確認する。
- トップ10に変動がないか。
- 新しいスロークエリが出現していないか。
- 気になる点があったらAsanaチケット作成。
- アラート対応
- DBのCPU負荷アラートだった場合はhistory list lengthを確認。必要に応じてセッションをKILL。
- ユーザ体験に関連するアラートの場合はDB Load・コネクション数をチェック。
- DB Loadが高い状態であればPerformance Insightsを開いて待機イベントとクエリをチェック。
- コネクション数が多い場合はSHOW FULL PROCESSLISTを見て接続元のIPをチェックし、Web/バッチでなにか問題が起きていないかをチェック。
- あとはAPMも組み合わせて対応を進める。
日々のチェックで作成されたAsanaチケットの課題は、他のインフラ作業タスクの合間を縫って調査を行い、明らかに問題のあるクエリが見つかった場合などは、アプリケーション担当のメンバーに相談し改修を進めていきます。
実際の効果
ここまで解説した仕組みで運用を1年近く続けていますが、肌感ではありますがアラート対応については以前よりも格段に早くDB起因の問題の解決ができるようになったと感じています。
また、日々の運用や改善活動という点では、これまで見逃されていた問題を解決することで、かなりのコスト削減を実現することが出来ました。
実績として大きなものとしては下記の4つがあります。(将来的にこのブログのネタにできるかもしれませんので、軽く概要だけの記載とさせていただきます)
AuroraのIO課金額を減らすことに成功
タイトルの年間1,000万円のコストダウンが目立ちますが、バッチ処理時間の短縮されユーザ体験の向上に寄与できたのも大きいです。
1DBへのユーザ収容数を倍程度まで拡大
クラウドシフト後にオンプレユーザのクラウド環境への移設を進めていくうちに、オンプレと同じ程度のユーザ数が収容された時点でDBの負荷が高くなり、Web画面の表示やバッチ処理も遅くなってきたため、このあたりが限界か…? と思いましたが、
Peformance Insightsを確認すると特定の待機イベントがDB Loadの大半を占めていることが判明。その待機イベントを解消するための改修を行い、大きく負荷を改善し、オンプレのときと比較して倍程度のユーザ数を収容するが可能になりました。
DBのインスタンスサイズを半分に
上記のユーザ収容数拡大の流れで、各種のメトリクスを見る限りでは、このまま更に収容ユーザ数を増やすことも可能っぽいが、その場合1DBあたりのテーブル数が数万を超える可能性があり、OSレイヤでのファイルハンドラやエフェメラルポートの枯渇などのおそれもあったため、1つのDBをピックアップして、ユーザ数はそのままにインスタンスサイズを半分に変更してみました。
vCPUやメモリ量が単純に半分となったため、メトリクスとしてはある程度悪化しましたが、ユーザ体験に関わるメトリクス群への悪影響はそれほど大きくなかったため、他のDBもサイズダウンを実施しコスト削減を行いました。
データに基づいた判断ができるようになった
お金的な話でいうと上記の3つがインパクトが大きいのですが、個人的に一番良かったなと感じているのが「諸々の判断がデータに基づいて行えるようになった」という点です。
従来までは、例えば1DBあたりのユーザ収容可能数が
「過去これだけはOKだったからこのぐらいまで」
で決められていて、収容数を増やすというプランについては
「どれぐらいなら大丈夫なのか、何かあったときの影響の度合いが見えない」
という理由でなかなか実際のアクションを起こすことが出来ないでいました。

何も見えない中で作業をするのは不安ですよね
現在はDBを含む、システム全体の可視性が高くなったことで、
「このメトリクスがこの値ならば、ここまで(収容人数増加などの)リスクを踏んでも大丈夫だろう」
といったようにデータを元に諸々の判断ができるようになり、意思決定やトライ&エラーのスピードが格段に向上しました。
同様にDBのパラメータ調整も、以前までは
「変更後にパフォーマンス劣化が起きるのではないか」
という恐怖に怯えながらの作業となるケースがほとんどでしたが、現在は
「このパラメータを変更することで悪影響があると、このメトリクスが悪化するはずだから、何かあればすぐに気付ける」
といった感じで、作業負荷を大きく軽減することが出来ました。

安心感を持って作業ができるように!
DBに詳しい人として社内で認知されるようになった
これは実績というよりも個人的な嬉しさではありますが、
DB周りの可視性向上のための活動と並行でSQLやMySQL、InnoDBなども勉強を続けており、パフォーマンス問題が発生しているクエリの改善などをしているうちに、社内でDBに詳しいマンとして認知されるようになりました。
クエリやテーブル設計、ALTER TABLEの実行やテーブルへの大量データ投入などなど、DBに関連する問題や作業で疑問があった場合に「とりあえず相談できる人」がいるというのは良いことだと思っています。

DB詳しいマンの完全体イメージ
以前までの状況と比較して、「これやりたいけど、パフォーマンスとかサービスに対しての影響がどの程度か予測できなくて怖いな… できることならやりたくないな…」といったリリースの心理的抵抗感・プレッシャーを下げる一助になっているかと感じています。
ただし、組織としてDBAを置いたとかではなく、あくまでも個人のスキルセットにDBという属性が追加されたという状況なので、継続的・発展的な改善のためには「DBに詳しい人」を継続的に生み出す仕組みが必要だろう、という課題感を感じています。
今後の展望
ということで、「MySQL/Auroraをしっかりと運用したいけど何をして良いのかわからないよ〜!」という状況から、ある程度可視性を向上させて、トラブル対応、改善活動ができる土台を整えるまでの経過をざっくりと書いていきました。
が、まだまだ自分自身のDB周りのスキルも含めて、改良・改善できることは山ほどあるかなと思っています。
組織のロードマップには載っていないものの、私が考えている今後の展望としていくつかのトピックを上げると
アプリケーションへのクエリ追加時のルール・ワークフロー整備
現状ではアプリケーション内の処理で新規のクエリを追加する場合や、既存のクエリを改修する場合、最低限EXPLAINの結果を確認して問題ないことを確認するようお願いしていますが、開発者やレビュアーのスキルセットによって「問題なし」のレベルがまちまちになっているので、なんらかの仕組みで一定のクオリティを担保できるようにしていきたいです。
改善活動のフロー整備
先述の通り、スロークエリログの集計をまとめていますが、今のところ定期的にチェックしているのが私一人という状態ですので、組織的にこれらの負債解消に動けるようにフロー整備を進めたいと思います。
アラートへのアノマリー検知導入
アラート設計時に、アノマリー検知を有効にしてみたところかなりの誤発報があったため現状は無効化しています。
DevOps Guru for RDSもそうですが、機能や精度を見極めて可能な限り、人間の勘や経験に依存していた部分を仕組みで再現していきたいと考えています。
DBに詳しい人とお話してみたい
こんな感じで色々やってはいますが、私自身まだまだ手探りでやっている状態のため「本当今やっていることが正しいのか?」という疑問が常につきまとっています。
「ここはもっとこうすれば良くなると思う!」みたいなご意見は是非コメントいただけると嬉しいですし、DBAとして活躍されていて「俺が一緒にもっと良くしてやるぜ!」みたいな方がいらっしゃったら、ぜひ一度弊社の求人を閲覧いただけますと幸いです!

NE株式会社のエンジニアを中心に更新していくPublicationです。 NEでは、「コマースに熱狂を。」をパーパスに掲げ、ECやその周辺領域の事業に取り組んでいます。 Homepage: ne-inc.jp/
Discussion