【個人開発】PDFからAIが重要単語を検出し、ファイルに直接穴埋め問題と解答を埋め込んでくれる暗記学習webサービスをつくってみた。
はじめに
こんにちは、Necoと申します。
駆け出しエンジニアです。
現在大学在学中で、最近趣味でプログラミングを始めました。
主にPythonでweb関連の学習をしております。
初めてのサービス公開ということで完成度は低いですが、ひとまず形にはなったのでサービスの使いかたなどを共有したいと思います。
自分のコーディングの練習もかねてPDF暗記学習サービス「Fill MAKER」のプロトタイプを開発・公開しました!
PDF暗記ツール「Fill MAKER」は、PDFをアップロードするとアルゴリズムが自動で重要単語を検出し、PDFに直接穴埋め問題を埋め込んでくれる学習サービスです。穴埋め加工されたPDFは、ファイルを開いて、穴埋め箇所をクリックするだけですぐに解答を表示できます。
このサービスでは以下のことができます。
① 暗記したいレジュメ等のPDFをアップロード
② AIが暗記すべき重要単語を検出 and お好きにカスタマイズして穴埋めを挿入
③ ダウンロード後、ファイルを開いて穴埋め箇所をクリックして解答を確認。効率的に学習
※PCでご利用ください。
穴埋め問題を埋め込んだPDFのサンプル画像1
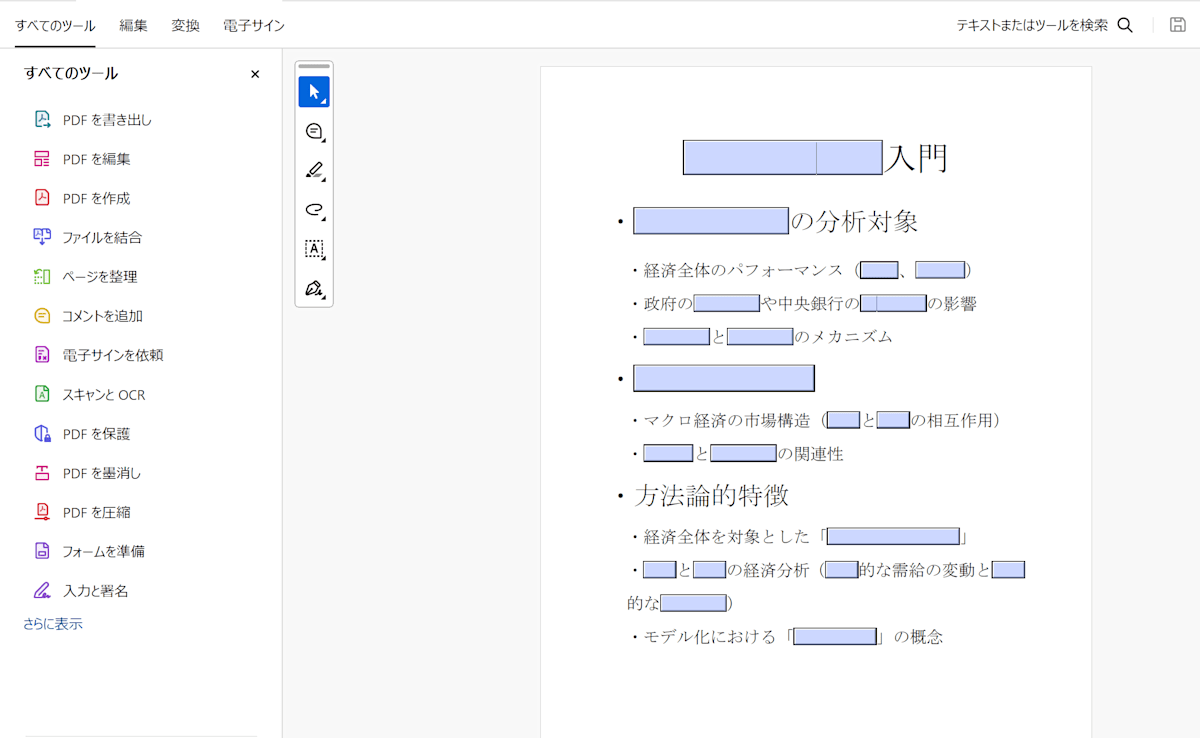
この画像のように、PDFに直接問題を埋め込むことができます。「産業革命」の部分はもともと青く塗りつぶされていますが、クリックすることで、中身を見ることができるようになっています。

出典:https://ja.wikipedia.org/wiki/産業革命
穴埋め問題を埋め込んだPDFのサンプル画像2
穴埋め問題を埋め込んだPDFの操作gif
※荒くて申し訳ない...

このサービスを開発した経緯
私の大学では講義資料の大半がPDFで配られますが、試験勉強の際にはそれらを読み込み、記憶し試験に挑む必要があります。
試験の形式が記述であれ、マークであれ一定程度の暗記は必ず必要になります。
しかしPDFには暗記の定着度を測る効果的な方法はなく、自分で暗記したい箇所を隠したり、ただひたすら読むだけというような学習の仕方になってしまいがちです。一問一答を作るにしても労力が大きいです。
そんな不便を解決したいと思ってこのサービスを構想しました。
※私はプログラミングの学習を始めたばかりで、そのうえ独学なので、cssなどのデザイン、コードは我流ですのであしからず...。
サービスの概要
PDF暗記ツール「Fill MAKER」は、PDFをアップロードするとアルゴリズムが自動で重要単語を検出し、PDFに直接穴埋め問題を埋め込んでくれる学習サービスです。穴埋め加工されたPDFは、ファイルを開いて、穴埋め箇所をクリックするだけですぐに解答を表示できます。
以下のステップで簡単にPDFに穴埋め問題を埋め込んで学習をすることができます。
※PCでご利用ください。
1 暗記したいレジュメなどのPDFをセットし、穴埋めを作成するページ番号を入力しアップロード(5MBまで)
2 AIがPDF内の文章から暗記対象の重要単語を自動検出
3 任意でAIの検出した単語以外に単語を追加、もしくは削除
4 作成された穴埋め加工済みPDFをダウンロード
5 PDFリーダーでPDFを開き、暗記を開始する。
トップページの画像

ステップ1: 暗記したいレジュメなどのPDFをセットし、穴埋めを作成するページ番号を入力しアップロード(5MBまで)
以下のように、穴埋め加工をしたいPDFファイルをセットし、作成したいページの番号を入力します。

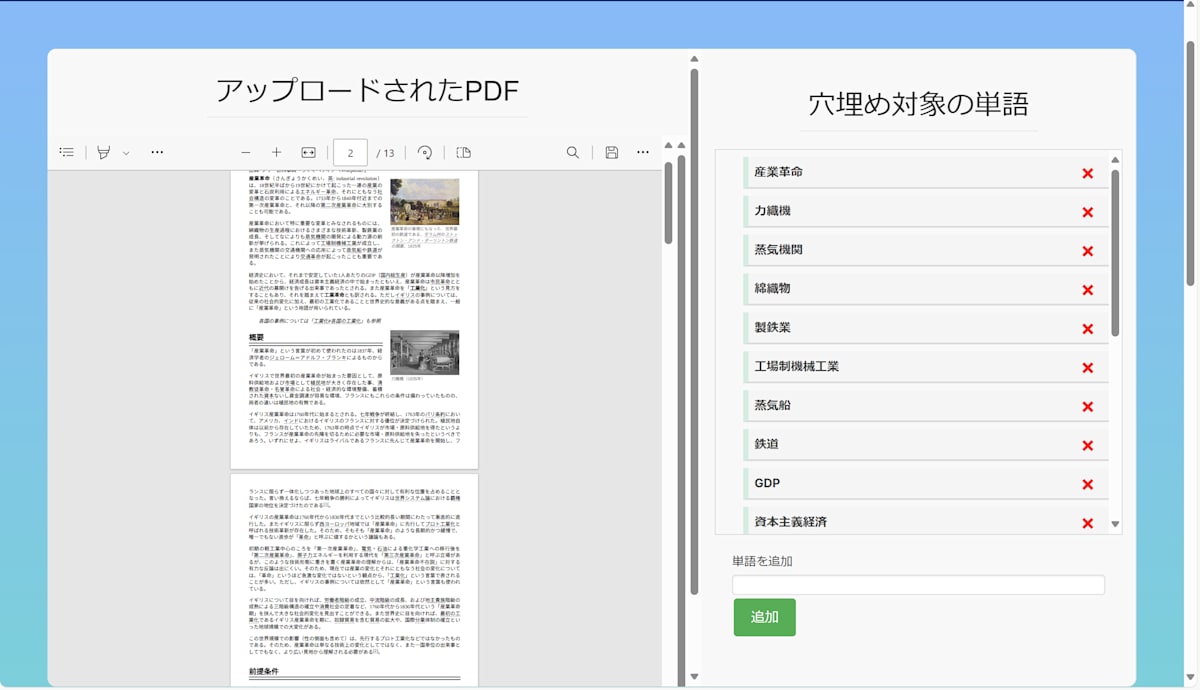
ステップ2: AIが自動検出&任意でAIの検出した単語以外に単語を追加・削除
ここでは画面の左にアップロードされたPDF、右に検出された単語リストが表示されます。任意でリストに単語を追加・削除できます。次に、暗記で利用するPDFリーダーを選択してください(Acrobat推奨)。
※ 単語は多くても20個程度にしてください。タイムアウトになってしまいます。ここは現在修正中です...。ご協力お願いします。<(_ _)>
※重要な注意点:Edge・Chromeの標準のPDFリーダーだと仕様上、解答欄の漢字が表示されません(現在調査中)。ですので現在はひらがなに変換された解答が挿入されます。Acrobatのリーダーであれば問題なく表示されます。漢字で快適に利用したい場合、無料のAcrobatのリーダーをご利用ください。
ステップ3: 作成された穴埋め加工済みPDFをダウンロード
加工されたPDFをダウンロードします。

ステップ4: 選択したリーダーでPDFを開き、学習を開始
この画像はAcrobatで開いた例です。青い箇所をクリックすると解答が表示されます。

出典:https://ja.wikipedia.org/wiki/産業革命
ターゲット層
主に試験勉強で講義資料のPDFの読み込みや暗記が必要になるであろう大学生をターゲットにしています。
このサービスの特徴その1:PDFと問題・解答がセット
Fill MAKERで穴埋め加工されたPDFファイルには、もとの文章に含まれる重要単語の部分に、不可視の解答が埋め込まれています。
なにもしない状態であれば、その部分は塗りつぶされており、中身は見えません。
しかしこの部分をクリックすると、解答が表示される仕組みとなっております。
文章を読み、穴埋め箇所の単語を推測、その後解答を確認...と高速に暗記ができます。
このように、原文、問題、解答が一体となっているため、ダウンロードしたPDFを開くだけですぐに暗記学習を開始できるのがこのサービスの大きな特徴であり、メリットです。
このサービスの特徴その2: AIが重要単語を検出
暗記対象の単語は自分で追加・削除が可能ですが、AIがPDFの文章の中から暗記すべき単語をリストアップし、あらかじめセットしてくれます。とくにこだわりがなければ、アップロード→ダウンロード→学習とスムーズに進めることができます。
他のサービスでも暗記カードなどを作成できるものはありますが、Fill MAKERではAIを導入することにより差別化をはかっています。
料金・課金
課金機能は未実装です。一応システムはstripeで作ってあるのですが、今は使用できません。基本的には無料で使用可能で、月に20回までアップロード可能です。1回でのアップロードでは、穴埋めは1ページまでしか作成できません。この制限はサーバーへの負荷を大きくしないためのものですが、課金ユーザーの少なさを考慮すれば、一定数のユーザーに無制限プランを開放しても問題無いと思われますので、後ほど無制限の課金プランを実装予定です。
ログイン
Googleのソーシャルログインを実装済みですが、課金をする際にしか使用しませんので、基本的にはログインは不要です。
開発期間
2か月ほどです。ほとんど初心者なのでここまでかかりましたが、上級者であれば1か月もかからない内容だと思います。
開発環境・言語
プログラミング初心者なので、扱いやすいPython、そのwebアプリフレームワークであるDjangoというものをつかって構築してみました。幸い、Djangoの解説記事はたくさんあったので、それを参考に構築しました。
python
Django
html
css
javascript
heroku
postgreSQL
お名前ドットコム
使用しているAI
無料で使えるGoogleのGeminiのAPIを使用しています。
工夫したところ
1 解答をクリックで確認可能
PDFに問題・解答が直接埋めこまれており、穴埋め箇所をクリックするだけで解答が確認できます。別の解答ファイルなどを作成したり、開いたりする必要が全くなく、ワンクリックですぐに確認できます。なかなかこのような技術をつかっているサービスはないので、独自性が出せたと思います。
2 穴埋めを埋め込む座標と穴埋めサイズを算出するアルゴリズム
穴埋め箇所がずれていたり、サイズがあっていないとほかの文章に干渉してしまったりスタイルが崩れてしまうので、PDFのメタ情報を読み込み、穴埋め箇所を探して、大きさ・場所を的確に設定する必要がありました。そこで、独自のアルゴリズムを構築し、場所や大きさを正確に算出できるようにしました。
PDFの大きさはバラバラでそれに応じて座標を決定しなければならないので、穴埋め箇所、大きさを算出するアルゴリズムの構築にはさんざん苦労させられました。
3 ライブラリのオーバーライド(?)
使用していたライブラリでは日本語のエンコードができず、独自の処理を組み込む必要があり元の処理を上書きしました。正直、プログラミングの世界では禁忌なような気もしますが、これが解決できなければどうしようもないのでやむなくオーバーライドしました。
開発の過程
1 構想
自分が欲しかったサービスということもあり、すんなりと仕組みを構想できました。しかし実際にそれが実現可能なのかを調べるために、ライブラリのソースコードやドキュメントを調べるのに数日を要しました。
2 実装
まず、PDFに穴埋め問題と解答を直接埋め込む方法を見つけるのが大変でした。プログラミング初心者ですので、ライブラリのドキュメントを読んでも正直意味不明で、そのうえ英語で書かれているので余計に理解に時間がかかります。やっとの思いで方法を見つけてコードを書いてもバグだらけで、心が折れそうになりました。
アルゴリズムの実装においても何度も試行錯誤を重ねて、正確に動作するよう工夫しました。
3 デプロイ
ある程度想定通りに動作するようになった時点でデプロイすることにしました。デプロイは操作が簡単で、料金体系もわかりやすいherokuで行いました。AWSも検討しましたが、構築の難易度が高かったのでherokuになりました。
もともとデバッグをあまり行っていなかったのもあり、デプロイ中に膨大な量の不具合に直面しました。
まず初めにびっくりしたのがメモリ使用量です。デプロイしてテストしてみると、なぜかすぐにサーバーダウン。メモリ使用量を確認できるライブラリを使うと、views.py読み込み時点で1000MBも消費されていました。ローカル環境では全く気付かず、デプロイして初めて発覚しました。どうやらメモリーリーク(?)が原因らしく、丸一日かけてなんとか解決しました。
また、debug=falseにすると、静的ファイルの配信方法が変わるらしく、iframeにPDFが表示されないという問題も発生しました。これにも解決に一日を要しました。
そのほかにもDNSの設定などさまざまな問題に悩みました。
懸念点
1 処理が遅い
独自のアルゴリズムの効率がよくないのか、PDFが複数ページに及ぶ、文書が長い、単語が多い、などの条件が重なると出力に時間がかかってしまい、タイムアウトとなってしまいます。なので、ページ数は1ページに制限しています。現在アルゴリズムの効率化を図っているところです。
2 Edge・Chromeの標準ビューワーだと、漢字が表示されない
Acrobatの無料のリーダーであれば問題なく動作します。しかし、Edge・Chromeの標準ビューワーだと解答欄に漢字を含めると、その部分が空白になってしまいます。同様の問題がSNSやwindowsのコミュニティで確認できるので、仕様上の問題かと思われます。今のところは解答部分の漢字をひらがなに変換することでその問題を回避しています。解決策が見つかり次第改善しようと思います。
3 UIが洗練されていない
我流でcssを書いたので自分のサイトのUIはどうしても安っぽく見えてしまいます。
他の方のアプリのUIを見てみると、その洗練のされ具合に驚かされます。だいたいどの方もtailwind(?)を使用しているらしいので、次の開発で使用してみようと思います。
まとめ
個人開発で、Fill MAKERのプロトタイプを開発しました。記念すべき一つ目の公開です。さまざまな問題の直面してもあきらめずに試行錯誤を重ねて、ついにリリースできました。まだまだ色々改善すべき点も盛りだくさんで、引き続き進化させていく予定です。
ご不便をおかけしたら申し訳ないです
もしなにかあれば、Twitterにお願いします。
ここまでお読み頂きありがとうございました。
もしよければぜひ、いいねやリツイートなど頂けるととても励みになります!!
よろしくお願いいたします!
Discussion