SpreadsheetでUnpivot
概要
Google Spreadsheetのワークシート関数(lambda関数)で以下のようなピボット表を

以下のような縦持ちのデータに変換する関数を作成してみました。

コンテキスト
Excelに引き続いてGoogle Spreadsheetでもlambda関数、let関数がサポートされ、ある程度の処理はGAS(Google Apps Script)を使わなくても書ける環境が整いました。そこでPower Queryで頻出するunpivotをつくってみました。
対象読者
- xlookup,let,lambdaなどGoogle Spreadsheetワークシート関数、および名前付き関数を使いこなせる方
完成系
以下を名前付き関数として登録して使うことができます。drop関数もサポートされればより簡潔な記載にできそうです。
スプレッドシートから実際に動作している様子を見て頂くこともできます。
LAMBDA(
range,
let(
drop,LAMBDA(
range,
col_to_drop,
row_to_drop,
makeArray(
rows(range)-abs(row_to_drop),
COLUMNS(range)-abs(col_to_drop),
lambda(
r,
c,
INDEX(
range,
r+if(row_to_drop>0,row_to_drop,0),
c+if(col_to_drop>0,col_to_drop,0)
)
)
)
),
repeatCol,lambda(col,count,byCol(sequence(1,count),lambda(_,col))),
repeatRow,lambda(row,count,byRow(sequence(count),lambda(_,row))),
row_index,drop(chooseCols(range,1),0,1),
height,rows(row_index),
col_index,drop(chooseRows(range,1),1,0),
width,COLUMNS(row),
data,drop(range,1,1),
result,{
toCol(repeatRow(col_index,width)),
toCol(repeatCol(row_index,height)),
toCol(data)
},
result
)
)
使用例
unpivot関数は、Google Sheetsで表形式のデータを縦に並べたレコード形式に変換するのに役立ちます。これは、特にデータ分析やデータ整形において、データを扱いやすくするために便利です。以下に具体的な例を示し、使用方法を説明します。
例: 商品別売上データの集計
例えば、以下のような商品別の月間売上データがあるとします。
| 商品 | 1月 | 2月 | 3月 |
|---|---|---|---|
| A | 100 | 150 | 120 |
| B | 200 | 250 | 220 |
| C | 300 | 350 | 320 |
この表形式のデータを、以下のようなレコード形式に変換したいとします。
| 商品 | 月 | 売上 |
|---|---|---|
| A | 1月 | 100 |
| A | 2月 | 150 |
| A | 3月 | 120 |
| B | 1月 | 200 |
| B | 2月 | 250 |
| B | 3月 | 220 |
| C | 1月 | 300 |
| C | 2月 | 350 |
| C | 3月 | 320 |
この変換を行うために、unpivot関数を使用します。
- Google Sheetsで、上記の商品別売上データをA1:D4のセルに入力します。
- F1からH1にかけて商品、月、売上と予めヘッダーを入力しておきます。
- F2セルに、
=unpivot(A1:D4)と入力します。
すると、F1セルから始まる範囲に、上記のレコード形式のデータが表示されます。
このように、unpivot関数を使用することで、表形式のデータをレコード形式に変換することができます。このレコード形式のデータは、データのフィルタリングや集計が行いやすくなり、データ分析に役立ちます。また、他のデータベースやシステムにデータをインポートする際にも、この形式が求められることがよくあります。
実装についての解説
まずピボット表を行インデックス、列インデックス、データに分割して考えます

行インデックス、列インデックスの処理をし、最後に統合しています。
行インデックス
行インデックスはそれぞれ以下のようにデータに対応しています。
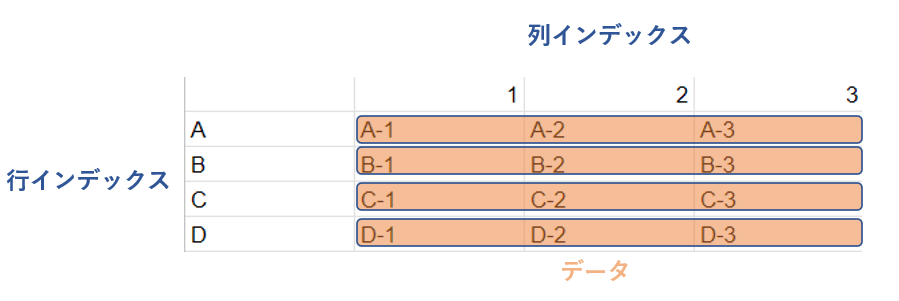
行インデックスのラベルを列インデックスの数の分だけ横に複写すればデータと行インデックスのラベルを1対1対応させることができます。

そのためにrepeatColという関数を作ります。
lambda(col,count,byCol(sequence(1,count),lambda(_,col)))
sequence(行数,列数)という関数は連番を作ることができます。これをつかって行インデックスを横に並べます。
列インデックス
列インデックスはそれぞれ以下のようにデータに対応しています。

さきほどと同じ要領でrepeatRowという関数を作ります。
lambda(row,count,byRow(sequence(count),lambda(_,row)))
行インデックス、列インデックス、データを組み合わせる
repeatColとrepeatRowを組み合わせると以下のようなデータを作ることができます。

列インデックス、行インデックス、データをそれぞれ縦1列にした上で並べれば完成です。縦1列に並べるためにはtoCol関数を使います。これらを並べるにはHSTACK関数を使います。
列インデックス
HSTACK(
toCol(lambda(col,count,byCol(sequence(1,count),lambda(_,col)))(col_index,cols(row_index))
),
toCol(lambda(row,count,byRow(sequence(count),lambda(_,row)))(row_index,cols(col_index))
),
toCol(data)
)
行インデックス・列インデックス・データを切り出す
上記までで完成でも良いのですが、せっかくですので範囲全体を指定すれば、行インデックス・列インデックス・データを自動的に取り出すようにしたいと思います。行インデックスは一番左の列を選択した上で一番上の行を削除します。列の選択はchoosecols関数を使います。指定した行数を削除するにはdrop関数を使います、と言いたいところですがExcelには存在するDrop関数がSpreadsheetにはまだありません。そこでmakearrayという指定した行数・列数の配列を作る関数を使って自作します。
LAMBDA(
range,
col_to_drop,
row_to_drop,
makeArray(
rows(range)-abs(row_to_drop),
COLUMNS(range)-abs(col_to_drop),
lambda(
r,
c,
INDEX(
range,
r+if(row_to_drop>0,row_to_drop,0),
c+if(col_to_drop>0,col_to_drop,0)
)
)
)
)
ちなみにdropという名前で名前付き関数として登録しようとするとエラーが出ます。将来的には実装されるのでしょう。自作のdrop関数を使うと行インデックスの取り出しは以下のようになります。全体の範囲はrangeとします。
drop(chooseCols(range,1),0,1)
列インデックスはchooserowを使って1行目を取り出し先頭を削除しましょう。以下となります。
drop(chooseRows(range,1),1,0)
データは1行目と1列目を削除します。
drop(range,1,1)
全体の統合
全体をまとめて一つの関数にします。let関数が登場する前はネストが深くなったり、処理が入り組んだりして分かりにくくなりがちでしたが、let関数により変数を扱えるようになり、処理が追いやすくなりました。全体を組み合わせた結果は最初に提示したものと同じですが再掲します。
スプレッドシートから実際に動作している様子を見て頂くこともできます。
LAMBDA(
range,
let(
drop,LAMBDA(
range,
col_to_drop,
row_to_drop,
makeArray(
rows(range)-abs(row_to_drop),
COLUMNS(range)-abs(col_to_drop),
lambda(
r,
c,
INDEX(
range,
r+if(row_to_drop>0,row_to_drop,0),
c+if(col_to_drop>0,col_to_drop,0)
)
)
)
),
repeatCol,lambda(col,count,byCol(sequence(1,count),lambda(_,col))),
repeatRow,lambda(row,count,byRow(sequence(count),lambda(_,row))),
row_index,drop(chooseCols(range,1),0,1),
height,rows(row_index),
col_index,drop(chooseRows(range,1),1,0),
width,COLUMNS(row),
data,drop(range,1,1),
result,{
toCol(repeatRow(col_index,width)),
toCol(repeatCol(row_index,height)),
toCol(data)
},
result
)
)
最後に
始めて技術記事を書きました。簡単な関数のつもりでしたが、きちんと説明するのは難しいですね。
Discussion
試しに作成してみましたが「LAMBDA 関数の後には実際の値を含む呼び出しを続けて指定する必要があります。」とエラーとなりうまくいきませんでした。
大変お手数なのですが、実際に動作しているスプレッドシートを共有していただくことは可能でしょうか?
ご指摘ありがとうございます。Googleシートでの名前付き関数の登録は少しクセがあるので、動作例も載せた方が良さそうですね。本文中に追記させていただきました。
勝手なお願いにも関わらず、早速の対応ありがとうございます!!!
大変助かりました。